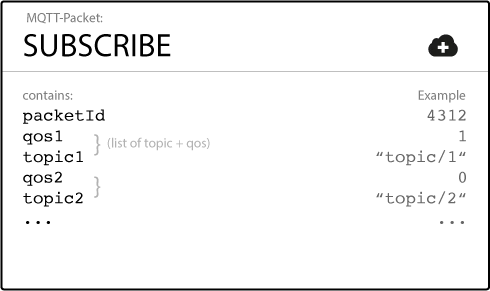OkHttp 是一个由 Square 公司开发的、功能强大且高效的 HTTP 客户端库,广泛用于 Java 和 Android 应用中进行网络请求。它被认为是 Android 生态系统中进行网络通信的首选库,许多其他高级网络库(如 Retrofit)都是基于 OkHttp 构建的。
之前的网络请求 OkHttp 通过其高效的连接管理、强大的拦截器机制和对现代 HTTP 协议的支持,极大地简化了 Android 网络通信的开发。OkHttp出来之后,可以说是迅速抢占了大部分市场,在之后,更是成为了Android应用网络请求的标准范例。
我记得刚开始学习Android时,使用的还是原生的 HttpURLConnection 。在使用 HttpURLConnection 的时候,我们需要 手动管理连接、输入输出流、设置请求头、处理响应 等。这一过程繁琐且容易出错,特别是在处理复杂的网络请求时。
public class HttpUtil {
public static String sendGetRequest ( String url ) {
HttpURLConnection connection = null ;
BufferedReader reader = null ;
String result = null ;
try {
// 打开连接
URL requestUrl = new URL ( url );
connection = ( HttpURLConnection ) requestUrl . openConnection ();
connection . setRequestMethod ( "GET" );
connection . setConnectTimeout ( 5000 );
connection . setReadTimeout ( 5000 );
// 读取响应
reader = new BufferedReader ( new InputStreamReader ( connection . getInputStream ()));
StringBuilder response = new StringBuilder ();
String line ;
while (( line = reader . readLine ()) != null ) {
response . append ( line );
}
result = response . toString ();
} catch ( IOException e ) {
e . printStackTrace ();
} finally {
// 关闭连接和流
if ( reader != null ) {
try {
reader . close ();
} catch ( IOException e ) {
e . printStackTrace ();
}
}
}
return result ;
}
}
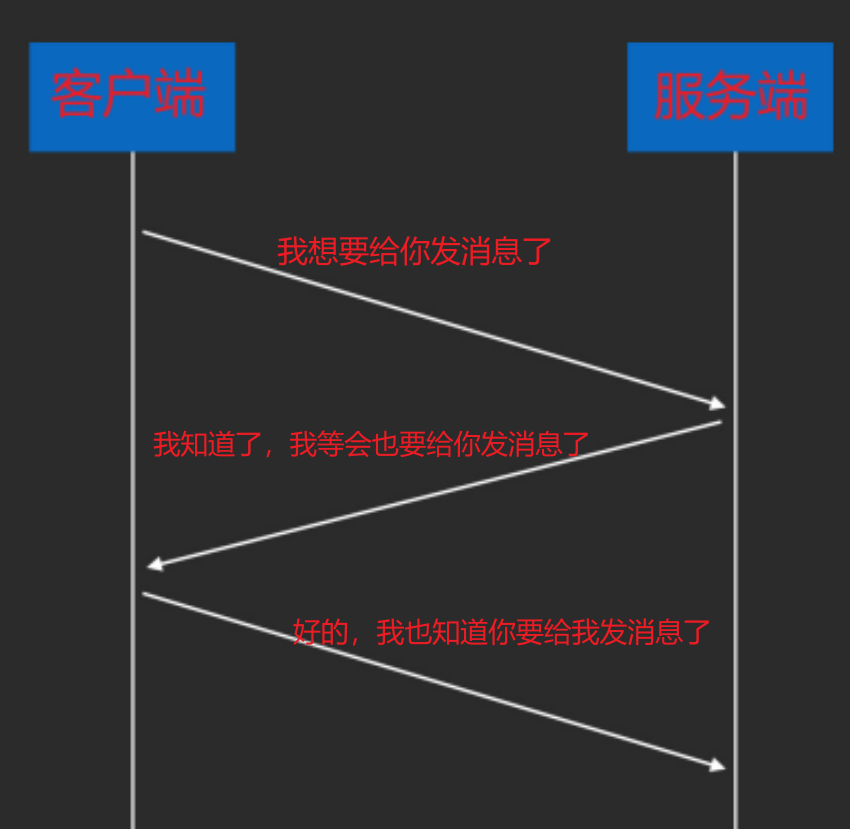
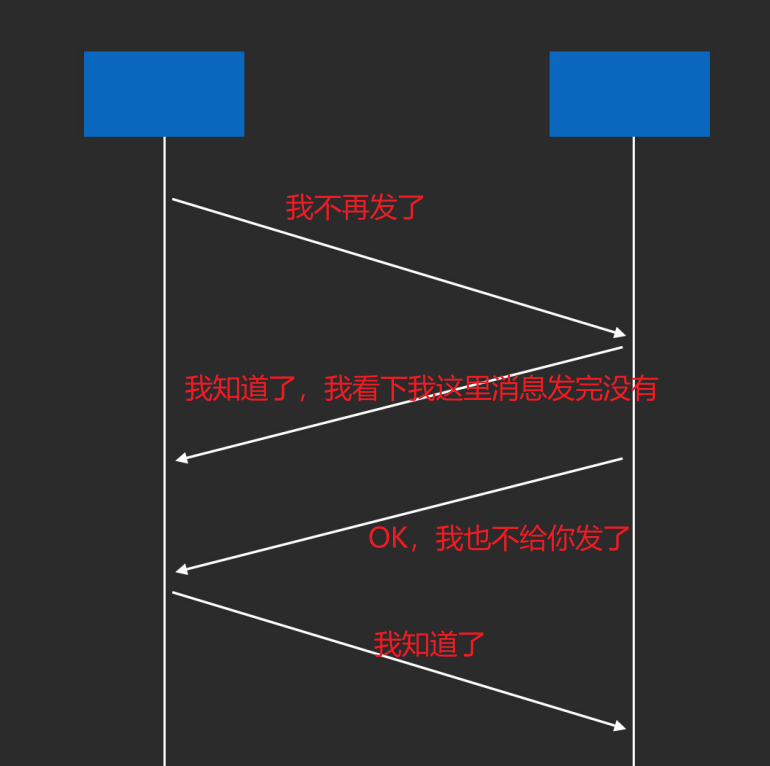
一次完整的网络请求流程 在安卓应用中完成一次 HTTP 请求与响应的完整流程,会涉及多个网络分层,下面按照 TCP/IP 四层模型,结合 OSI 模型对应层次来详细介绍各层在请求和响应阶段完成的工作。
请求过程 应用层 ,开发者使用 HTTP 客户端构建 HTTP 请求,指定请求方法(GET、POST 等)、URL、请求头和请求体等信息。按照 HTTP 规范组织请求数据,生成符合格式的 HTTP 请求报文,之后将请求报文传递给传输层。传输层 ,首先建立连接,客户端和服务器通过三次握手建立 TCP 连接。客户端发送 SYN 报文,服务器返回 SYN + ACK 报文,客户端再发送 ACK 报文完成连接建立。连接连理之后,将应用层的 HTTP 请求报文分割成合适大小的报文段,并为每个报文段添加 TCP 首部(包含源端口、目标端口、序列号等信息)。通过序列号和确认应答机制保证数据可靠传输,若发送的报文段未收到确认应答,会进行重传。网络层 ,基于 IP 协议,将传输层的 TCP 报文段封装成 IP 数据报,添加 IP 首部(包含源 IP 地址和目标 IP 地址),根据目标 IP 地址进行路由选择,确定数据报从客户端到服务器的传输路径。将目标 IP 地址解析为对应的 MAC 地址,以便数据在链路层传输。数据链路层 ,将网络层的 IP 数据报封装成帧,添加帧首部(包含源 MAC 地址和目标 MAC 地址)和帧尾部(包含校验信息)。控制设备对物理介质的访问,避免数据冲突。例如,以太网使用 CSMA/CD(载波监听多路访问/冲突检测)协议。通过物理介质(如 Wi-Fi、移动网络)将帧发送到下一个节点。物理层 ,信号转换,将数据链路层的二进制数据转换为物理信号(如电信号、光信号),通过物理介质进行传输。响应过程 物理层 ,在接收端,将物理信号转换为二进制数据,传递给数据链路层。数据链路层 ,接收物理层传来的帧,检查帧的校验信息,若校验正确,则去掉帧首部和帧尾部,将 IP 数据报传递给网络层。网络层 ,接收数据链路层传来的 IP 数据报,检查 IP 首部信息,若目标 IP 地址是本机,则去掉 IP 首部,将 TCP 报文段传递给传输层。ICMP 协议,在网络出现错误(如网络不可达、超时等)时,发送错误报告和控制消息。传输层 ,接收TCP的响应报文段,对报文段进行排序和重组。向服务器发送确认应答,告知服务器数据已成功接收。数据传输完成后,客户端和服务器通过四次挥手断开 TCP 连接。应用层 ,接收传输层传来的 HTTP 响应报文,解析响应状态码、响应头和响应体。从 HTTP 客户端获取解析后的响应数据,根据业务逻辑进行处理。OkHttp设计理念和核心特性 OkHttp 的设计目标是让 HTTP 网络请求 更快、更稳定、更易用 ,并且提供丰富的可配置性。
高效的网络传输 连接池 (Connection Pooling) 设计。OkHttp 维护一个连接池,对同一主机的多个请求可以 复用已建立的 TCP 连接 。这大大减少了连接建立和断开的开销,尤其是在进行大量小请求时,能显著提高性能。
OkHttp 完全支持 HTTP/2协议 。HTTP/2 允许多个请求和响应在单个 TCP 连接上进行 多路复用 ,解决了 HTTP/1.x 中队头阻塞(Head-of-Line Blocking)的问题,进一步提高了并发性和效率。
OkHttp 默认支持透明的 GZIP 压缩。当服务器返回 GZIP 压缩的数据时,OkHttp 会自动解压,减少了传输的数据量,节省了带宽。
OkHttp 支持响应缓存,可以将服务器返回的响应缓存到本地磁盘。对于重复的请求,如果缓存有效,OkHttp 可以直接从缓存中读取数据,而无需再次进行网络请求,从而加速响应并减少网络流量。
OkHttp 还能够通过拦截器自动处理常见的网络问题,如连接失败的重试和 HTTP 重定向 (3xx 状态码)。这使得网络请求更加健壮。
简洁易用的 API 链式构建器 (Builder Pattern) 的设计:OkHttp 使用构建器模式来配置 OkHttpClient 和 Request 对象,使得 API 调用非常流畅和直观。
OkHttpClient client = new OkHttpClient . Builder ()
. connectTimeout ( 10 , TimeUnit . SECONDS )
. readTimeout ( 30 , TimeUnit . SECONDS )
. addInterceptor ( new LoggingInterceptor ())
. build ();
Request request = new Request . Builder ()
. url ( "https://api.example.com/data" )
. header ( "User-Agent" , "OkHttp Demo" )
. get () // GET, POST, PUT, DELETE, PATCH
. build ();
OkHttp 同时支持同步和异步请求。
同步请求 :通过 client.newCall(request).execute() 方法执行,会阻塞当前线程直到收到响应。注意:在 Android 主线程中严禁执行同步网络请求,会引发 ANR (Application Not Responding)! 异步请求 :通过 client.newCall(request).enqueue(callback) 方法执行,请求在后台线程进行,结果通过回调接口 Callback 返回到指定线程(通常是主线程)。强大的可扩展性:拦截器 (Interceptors) Interceptors 拦截器是 OkHttp 最强大的特性之一,它基于责任链设计模式。你可以在请求发送前和响应接收后插入自定义的逻辑。
主要在以下方面应用:
日志记录 (Logging) :打印请求和响应的详细信息,方便调试。身份验证 (Authentication) :自动添加认证头,如 OAuth token。离线缓存 (Offline Caching) :在没有网络时从缓存中获取数据。重试机制 (Retry Logic) :自定义失败请求的重试策略。参数添加/修改 :统一添加公共参数或修改请求头。数据压缩/加密 :对请求或响应数据进行额外的处理。拦截器主要分为两种:
应用拦截器 (Application Interceptors) :通过 addInterceptor() 添加。它们运行在网络请求之前,并且在重定向、缓存和重试操作之间只调用一次。适用于应用级别的逻辑。网络拦截器 (Network Interceptors) :通过 addNetworkInterceptor() 添加。它们直接操作网络请求,可以观察到底层的网络连接、重定向和重试。适用于监控网络行为或底层协议的修改。与 Okio 的紧密集成 OkHttp 的底层 I/O 操作是基于 Okio 库实现的。Okio 提供了高效的 Buffer (分段缓冲区) 和 Source/Sink (读写流) 抽象,使得 OkHttp 在处理数据流时能够避免不必要的内存拷贝,从而提高了性能。
安全性 OkHttp 原生支持 HTTPS,并可以配置自定义的 SSLSocketFactory 和 HostnameVerifier 来进行证书信任和主机名验证。
证书固定 (Certificate Pinning)特性,允许开发者指定信任的服务器证书,防止中间人攻击。即使根证书被篡改,也能识别出伪造的服务器。
WebSocket 支持 OkHttp 不仅支持传统的 HTTP/HTTPS 请求,还提供了对 WebSocket 的完整支持,用于实现双向、持久的通信。
OkHttp 的架构概览 一个典型的 OkHttp 请求流程通常涉及以下几个关键组件:
OkHttpClientHTTP 请求的执行者。它是线程安全的。
val client = OkHttpClient . Builder (). xxx . build ()
由上述调用方式,我们便可以猜出,这里使用了 构建者模式 去配置默认的参数,所以直接去看 OkHttpClient.Builder 支持的参数即可。
需要注意的是,在使用过程中,对于 OkHttpClient 我们还是应该缓存下来或者使用单例模式以便后续复用,因为其相对而言还是比较重,可以充分利用连接池和其他资源。
Request指客户端发送到服务器的 HTTP请求。在 OkHttp 中,可以使用 Request 对象来构建请求,然后使用 OkHttpClient 对象来发送请求。
通常情况下,一个请求包括了 请求头、请求方法、请求路径、请求参数、url地址 等信息。主要是用来请求服务器返回某些资源,如网页、图片、数据等。
val request = Request . Builder ()
. url ( "https://api.example.com/data" ) // 请求的 URL
. header ( "User-Agent" , "OkHttp Demo" ) // 添加请求头
. get () // HTTP 方法,这里 是 GET
. build () // 构建请求对象
Call and Response当我们使用 OkHttpClient.newCall() 方法时,实际是创建了一个新的 RealCall 对象,它代表了一个准备好执行的 HTTP 请求。用于 应用层与网络层之间的桥梁,用于处理连接、请求、响应以及流 ,其默认构造函数中需要传递 okhttpClient 对象以及 request 。Call 可以同步执行 (execute()) 或异步执行 (enqueue())。
Response是服务器返回的HTTP响应,包含状态码、响应头和响应体。我们从中可以获取服务器返回的数据。
同步执行 调用 execute() 方法开始发起同步请求,该方法内部会将当前的 call 加入我们 Dispatcher 分发器内部的 runningSyncCalls 队列中取,等待被执行。接着调用 getResponseWithInterceptorChain() ,使用拦截器获取本次请求响应的内容,这也即我们接下来要关注的步骤。
异步执行 当我们调用 RealCall.enqueue() 执行异步请求时,会先将本次请求加入 Dispather.readyAsyncCalls 队列中等待执行,如果当前请求是 webSocket 请求,则查找与当前请求是同一个 host 的请求,如果存在一致的请求,则复用先前的请求。
接下来调用 promoteAndExecute() 将所有符合条件可以请求的 Call 从等待队列中添加到 可请求队列 中,再遍历该请求队列,将其添加到 线程池 中去执行。当我们将任务添加到线程池后,当任务被执行时,即触发 run() 方法的调用。该方法中会去调用 getResponseWithInterceptorChain() 从而使用拦截器链获取服务器响应,从而完成本次请求。请求成功后则调用我们开始时的 callback对象的 onResponse() 方法,异常(即失败时)则调用 onFailure() 方法。
Interceptor 链请求在发送到网络之前,会依次经过一系列的拦截器处理。这些拦截器可以修改请求、处理缓存、记录日志等。响应返回时,也会逆序经过拦截器链。
val client = OkHttpClient . Builder ()
. addInterceptor { chain -> // 添加一个简单的日志拦截器
val request = chain . request ()
println ( "Sending request: ${request.url}" )
val response = chain . proceed ( request )
println ( "Received response for: ${response.request.url} with code: ${response.code}" )
response
}
. build ()
ConnectionPool连接池,用于管理 TCP 连接的复用。维护一个连接的缓存池,当请求相同主机的资源时,可以重复使用已建立的连接,从而减少连接建立和销毁的开销。
DispatcherDispatcher 是一个线程安全的类,用于管理异步请求的执行。它维护了一个请求队列和一个线程池,用于执行请求。
Dispatcher 中的主要方法有:
enqueue(RealCall call) :将一个 RealCall 对象添加到请求队列中。promoteAndExecute() :从请求队列中取出符合条件的 Call 对象,并将其添加到线程池中执行。cancelAll() :取消所有的请求。finished(RealCall call) :当一个请求完成时,调用该方法。runningCallsCount() :获取当前正在执行的请求数量。责任链模式 责任链模式(Chain of Responsibility)是一种处理请求的模式,它让多个处理器都有机会处理该请求,直到其中某个处理成功为止。责任链模式把多个处理器串成链,然后让请求在链上传递。
上述逻辑如下:
当 getResponseWithInterceptorChain() 方法内部最终调用 RealInterceptorChain.proceed() 时,内部传入了一个默认的index ,这个 index 就代表了当前要调用的 拦截器item ,并在方法内部每次创建一个新的 RealInterceptorChain 链,index+1,再调用当前拦截器 intercept() 方法时,然后将下一个链传入;
最开始调用的是用户自定义的 普通拦截器,如果上述我们添加了一个 CustomLogInterceptor 的拦截器,当获取 response 时,我们需要调用 Interceptor.Chain.proceed() ,而此时的 chain 正是下一个拦截器对应的 RealInterceptorChain;
上述流程里,index从0开始,以此类推,一直到链条末尾,即 拦截器集合长度-1处;
当遇到最后一个拦截器 CallServerInterceptor 时,此时因为已经是最后一个拦截器,链条肯定要结束了,所以其内部肯定也不会调用 proceed() 方法。
相应的,为什么我们在前面说 它 是真正执行与服务器建立实际通讯的拦截器?
因为这个里会获取与服务器通讯的 response ,即最初响应结果,然后将其返回上一个拦截器,即我们的网络拦截器,再接着又向上返回,最终返回到我们的普通拦截器处,从而完成整个链路的路由。
常用拦截器 RetryAndFollowUpInterceptor 这是 OkHttp 中的一个拦截器,用于处理 HTTP 重定向和重试。当服务器返回一个 3xx 状态码时,该拦截器会根据服务器的指示进行重定向。如果服务器返回一个 4xx 或 5xx 状态码,该拦截器会根据配置的重试策略进行重试。即用于 请求失败 的 重试 工作以及 重定向 的后续请求工作,同时还会对 连接 做一些初始化工作。
BridgeInterceptor 这是 客户端和服务器 之间的沟通 桥梁 ,负责将用户构建的请求转换为服务器需要的请求。比如添加 content-type、cookie 等,再将服务器返回的 response 做一些处理,转换为客户端所需要的 response,比如移除 Content-Encoding 等。
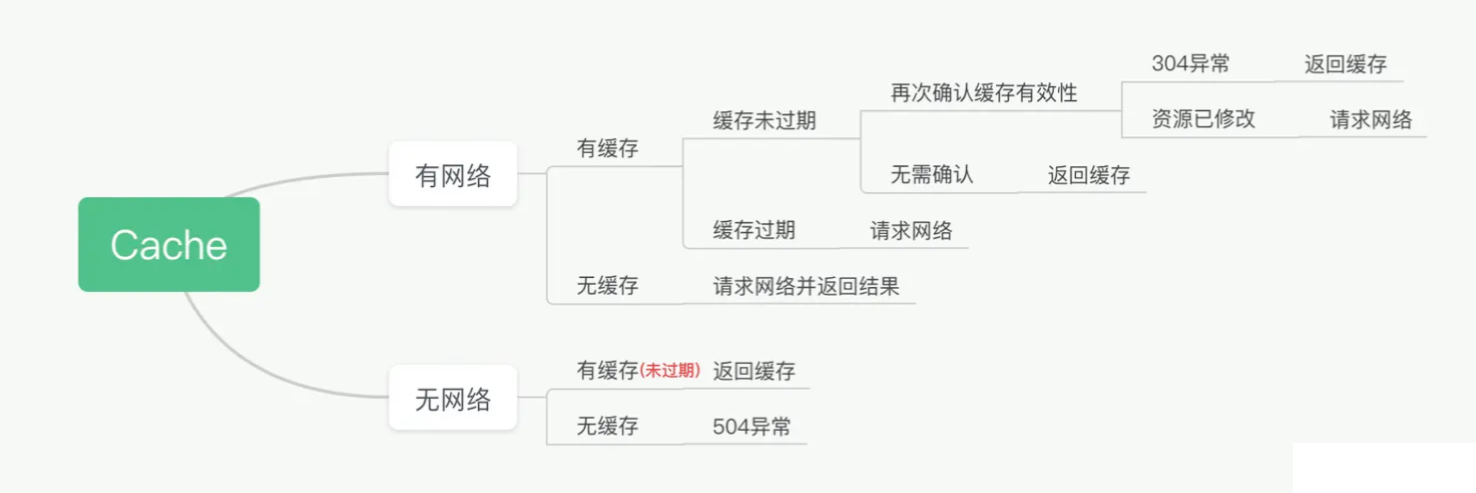
CacheInterceptor 管理缓存相关,比如 读取缓存、写入缓存 等。开发者可以通过 OkHttpClient.cache() 方法来配置缓存,在底层的实现处,缓存拦截器通过 CacheStrategy 来判断是使用网络还是缓存来构建 response。具体的 cache 策略采用的是 DiskLruCache 。
具体如下:
ConnectInterceptor 负责 建立连接、发送请求、接收响应 等。在底层的实现处,连接拦截器通过 StreamAllocation 来管理连接的复用,通过 RealConnection 来管理连接的生命周期。
CallServerInterceptor 负责 发送请求、接收响应 等。在底层的实现处,调用服务器拦截器通过 HttpCodec 来管理连接的读写流,通过 RealConnection 来管理连接的生命周期。
示例用法(Kotlin) import okhttp3.OkHttpClient
import okhttp3.Request
import okhttp3.Callback
import okhttp3.Response
import java.io.IOException
import java.util.concurrent.TimeUnit
fun main () {
// 1. 创建 OkHttpClient 实例
val client = OkHttpClient . Builder ()
. connectTimeout ( 10 , TimeUnit . SECONDS ) // 连接超时
. readTimeout ( 30 , TimeUnit . SECONDS ) // 读取超时
. addInterceptor { chain -> // 添加一个简单的日志拦截器
val request = chain . request ()
println ( "Sending request: ${request.url}" )
val response = chain . proceed ( request )
println ( "Received response for: ${response.request.url} with code: ${response.code}" )
response
}
. build ()
// 2. 构建 Request 对象
val request = Request . Builder ()
. url ( "https://api.github.com/users/octocat" ) // 请求的 URL
. get () // HTTP 方法,这里是 GET
. header ( "User-Agent" , "OkHttp-Example/1.0" ) // 添加请求头
. build ()
// 3. 执行异步请求
client . newCall ( request ). enqueue ( object : Callback {
override fun onFailure ( call : okhttp3 . Call , e : IOException ) {
println ( "Request failed: ${e.message}" )
e . printStackTrace ()
}
override fun onResponse ( call : okhttp3 . Call , response : Response ) {
response . use { // 确保响应体被关闭
if (! response . isSuccessful ) {
println ( "Request failed with code: ${response.code}" )
return
}
val responseBody = response . body ?. string ()
println ( "Response Body: $responseBody" )
}
}
})
// 为了让主线程不立即退出,给异步请求一些时间
Thread . sleep ( 5000 )
}
在 Android 中使用 OkHttp:
虽然上述示例是通用的 Kotlin 代码,但在 Android 应用中,你需要注意以下几点:
权限 :在 AndroidManifest.xml 中添加 INTERNET 权限。异步处理 :务必在后台线程执行网络请求。如果使用同步 execute() 方法,必须在 Thread、AsyncTask (不推荐)、ExecutorService 或 Kotlin 协程 (Dispatchers.IO) 中调用。使用 enqueue() 方法则会将回调放到线程池中执行,你可以利用 Handler 或协程将结果切换回主线程更新 UI。单例模式 :推荐将 OkHttpClient 创建为单例,并在整个应用中复用,以最大化连接池的效益。与 Retrofit 结合 :对于更复杂的 RESTful API 交互,通常会将 OkHttp 与 Retrofit 结合使用。Retrofit 提供了一个声明式的 API 来定义网络请求,并利用 OkHttp 作为底层的 HTTP 引擎。Okio部分 Okio 是 Square 公司(也是 OkHttp 的开发者)开源的一个 I/O 库,它旨在补充和改进 Java 平台原生的 java.io 和 java.nio API ,使其在处理数据访问、存储和处理时更易用、更高效。Okio 的设计理念可以用以下几个核心点来概括。
1. 统一和简化 I/O API Java 原生的 java.io 和 java.nio 在处理流式数据时,API 有些复杂和零散。例如,InputStream 和 OutputStream 是基于字节的,而 Reader 和 Writer 是基于字符的,它们的错误处理和缓冲区管理方式各不相同。java.nio 虽然提供了非阻塞 I/O,但使用起来更繁琐,需要手动管理 ByteBuffer。
为此,Okio 引入了两个核心接口:
Source (源):InputStream。Sink (槽):OutputStream。这两个接口提供了一个统一的、直观的 API 来处理字节流,无论数据是来自文件、网络还是内存。
例如,使用 Okio 的 Source 和 Sink 接口,从电脑上读取一个文件的流程如下:
// 1. 创建一个文件输入流
File file = new File ( "path/to/file" );
FileInputStream fis = new FileInputStream ( file );
// 2. 将文件输入流包装为 Okio 的 Source
Source source = Okio . source ( fis );
// 3. 读取数据
try ( BufferedSource bufferedSource = Okio . buffer ( source )) {
String data = bufferedSource . readUtf8 (); // 读取 UTF-8 编码的字符串
System . out . println ( "File content: " + data );
} catch ( IOException e ) {
e . printStackTrace ();
} finally {
// 4. 确保资源被关闭
source . close ();
}
// 5. 关闭文件输入流
fis . close ();
2. 强大的缓冲区 (Buffer) 在传统的 Java I/O 中,频繁的小读写操作会导致大量的系统调用和内存分配,性能较低。开发者需要手动管理 byte[] 缓冲区,容易出错。
Okio 的解决方案:
Buffer 类:ByteArrayOutputStream 但更高效。
分段缓冲区: Buffer 不是一个连续的 byte[],而是由一个双向链表 连接的多个小段 (Segment) 组成。每个 Segment 是一个固定大小的 byte[]。这种设计带来了显著的优势:
避免内存拷贝: 当数据从一个 Source 读入 Buffer,或者从 Buffer 写入 Sink 时,通常只需要在 Segment 之间进行引用传递,而不是复制整个字节数组。这大大减少了内存拷贝,提升了性能。
高效的数据追加和移除: 链表结构使得在 Buffer 的头部或尾部添加/移除数据非常高效,而不需要移动整个数组。
内存池(内部机制): Segment 可以被回收并重复利用,减少了垃圾回收的压力,尤其是在频繁进行 I/O 操作的场景下。
3. 可组合性和可扩展性 传统的 I/O 操作往往是线性的,很难在中间插入额外的处理逻辑(如压缩、加密、哈希)。
Okio 的解决方案:
装饰器模式: Okio 的 Source 和 Sink 设计允许你轻松地将它们包装(decorate)起来,形成一个处理链。例如,你可以将一个 GzipSource 包装在一个文件 Source 上,或者将一个 HashingSink 包装在一个网络 Sink 上。
// 读取一个经过 Gzip 压缩的文件
Source fileSource = Okio . source ( new File ( "compressed.gz" ));
Source gzipSource = new GzipSource ( fileSource );
BufferedSource bufferedSource = Okio . buffer ( gzipSource );
String data = bufferedSource . readUtf8 ();
// 写入数据并计算 SHA-256 校验和
Sink fileSink = Okio . sink ( new File ( "output.txt" ));
HashingSink hashingSink = HashingSink . sha256 ( fileSink );
BufferedSink bufferedSink = Okio . buffer ( hashingSink );
bufferedSink . writeUtf8 ( "Hello, Okio!" );
bufferedSink . close ();
ByteString hash = hashingSink . hash ();
这种设计使得 I/O 转换(如压缩、加密、编码解码、哈希)变得非常模块化和可插拔。
4. 易于测试 由于 Buffer 和 Source/Sink 是纯 Java/Kotlin 对象,它们可以在没有任何文件系统或网络依赖的情况下进行单元测试。这使得 I/O 相关的业务逻辑更容易测试。
总结 Okio 的核心设计理念可以归结为:提供一个更强大、更高效、更易用的 I/O 抽象层,以解决 Java 原生 java.io 和 java.nio 的痛点。 它通过引入 Buffer(分段缓冲区)、Source 和 Sink 的统一接口以及强大的装饰器模式,实现了高性能、可组合、易于测试的 I/O 操作。它的目标是让开发者能够更专注于业务逻辑,而不是底层繁琐的 I/O 细节和性能优化。
加密 对称加密 对称加密是指使用相同的密钥进行加密和解密的加密算法。在对称加密中,发送方和接收方使用相同的密钥进行加密和解密操作,因此加密和解密的过程都是基于同一个密钥。
常见的对称加密算法包括:
DES(Data Encryption Standard):一种对称加密算法,由IBM公司于1975年提出。 AES(Advanced Encryption Standard):一种对称加密算法,由美国国家标准与技术研究所(NIST)于2001年提出。 3DES(Triple DES):一种对称加密算法,由IBM公司于1978年提出。 RC4(Rivest Cipher 4):一种流加密算法,由Ron Rivest于1987年提出。 对称加密的优点是加密和解密的速度快,适用于对大量数据进行加密的场景。然而,对称加密的缺点是密钥的分发和管理比较复杂,需要确保密钥的安全性。
破解思路: 拿到⼀组或多组原⽂-密⽂对,设法找到⼀个密钥,这个密钥可以将这些原⽂-密⽂对中的原⽂加密为密⽂,以及将密⽂解密为原⽂的组合,即为成功破解。
反破解: ⼀种优秀的对称加密算法的标准是,让破解者找不到⽐穷举法(暴⼒破解法)更有效的破解⼿段,并且穷举法的破解时间⾜够⻓(例如数千年)。
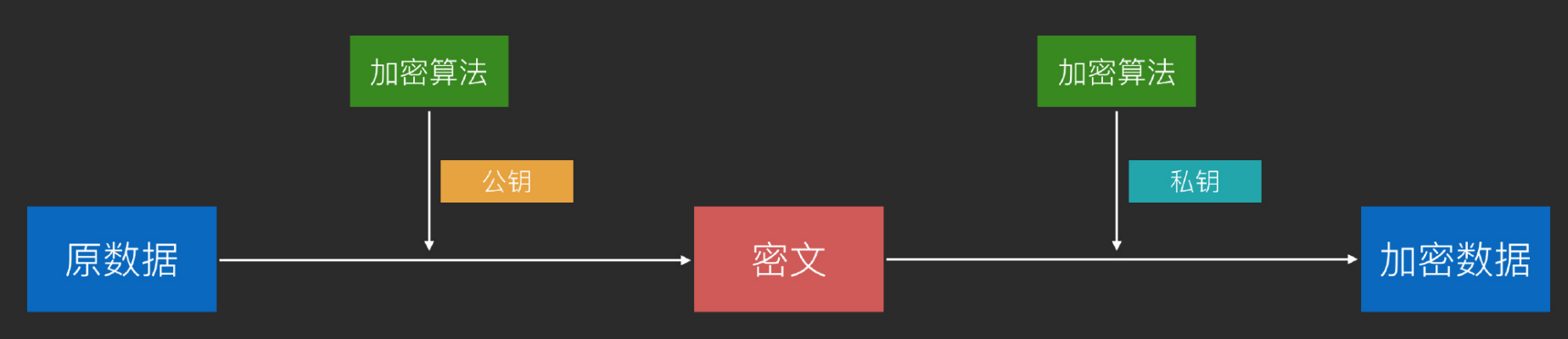
非对称加密 非对称加密是指使用不同的密钥进行加密和解密的加密算法。在非对称加密中,发送方和接收方使用不同的密钥进行加密和解密操作,因此加密和解密的过程都是基于不同的密钥。
原理:使用公钥对数据加密得到密文,使用私钥对数据解密得到原数据。⾮对称加密使⽤的是复杂的数学技巧,在古典密码学中没有对应的原型。
常见的非对称加密算法包括:
RSA(Rivest-Shamir-Adleman):一种非对称加密算法,由Ron Rivest、Adi Shamir和Leonard Adleman于1977年提出。 ECC(Elliptic Curve Cryptography):一种非对称加密算法,由Koblitz在1985年提出。
用同样的算法,不同密钥再算一遍,就得到原数据。
举例:
规定以下字符:0123456789 需要发110 加密算法:对一个字符都进行加法运算 加密密钥,4 密文:554 解密密钥:6 还原数据:11 11 10,溢出后,只保留后一位,就还原了110
其实由此可以知道,非对称加密最关键的点: 溢出
对称加密的难点:无法用安全高效的方式将加密的密钥给到对方,而非对称加密则无需担心这个问题。
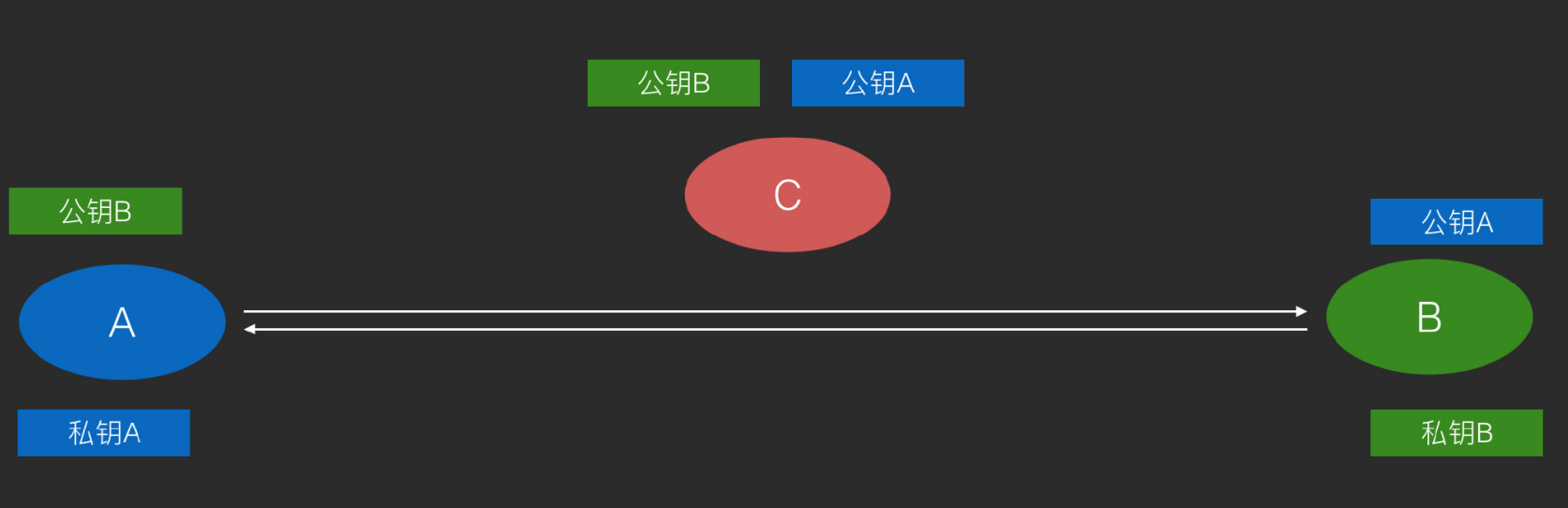
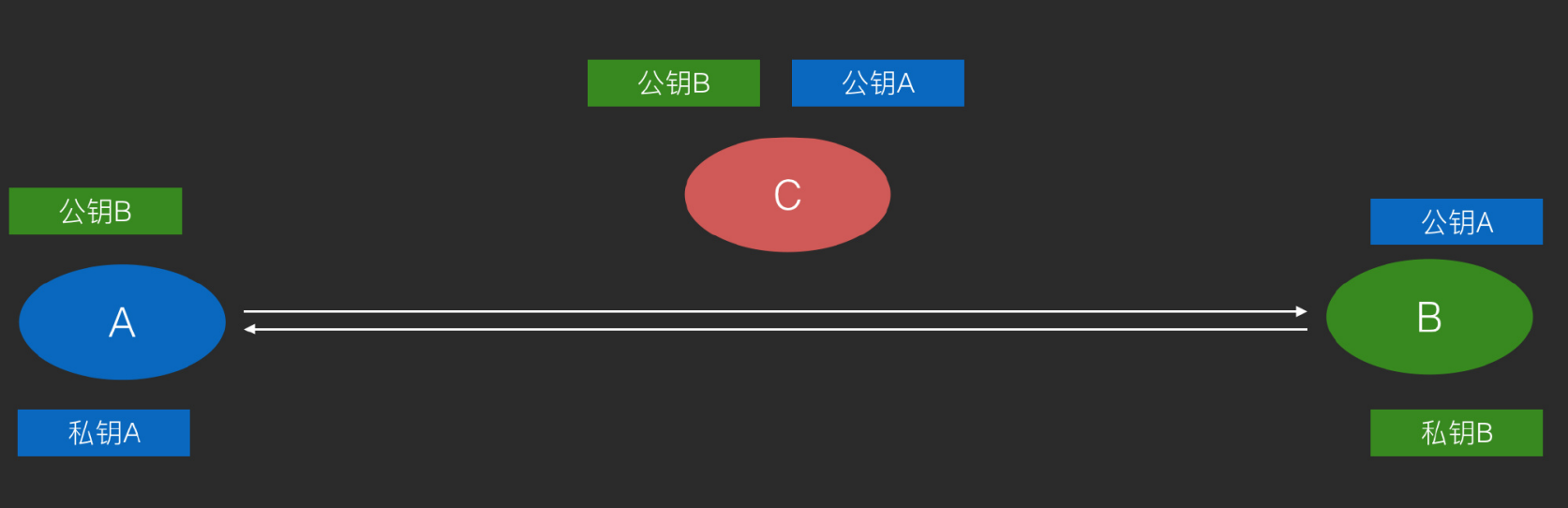
非对称加密的示意图:公钥可以在网络上公开,而私钥一定要掌握在自己手里。A要给B发消息,首先用A的公钥来进行加密,密文发给B后,B使用自己的私钥来解密密文。在这个过程中,就算C能看到密文,却无法拿到私钥B来解密密文。
以上是公钥加密,私钥来解,即私钥解公钥。
问:公钥可以解私钥吗?
可以的。即私钥X, 公钥Y,原数据data, 密文secret,加密算法为algorithm。 非对称加密符合以下过程:
data*algorithm*Y = secret
secret*algorithm*X = data即data*algorithm*Y*algorithm*X = data
"*algorithm*Y*algorithm*X " 这一段其实就相当于还原了数据。
即使用私钥加密公钥解密也是可行的。
但是,公钥和私钥的位置是不可以互换的。因为公钥是可以被计算出来的。比如比特币的公钥就是拿私钥算出来的。还比如RSA加密算法,它的公钥关键部分都是一样的。
非对称加密的优点是密钥的分发和管理相对简单,适用于对少量数据进行加密的场景。然而,非对称加密的缺点是加密和解密的速度相对较慢,不适用于对大量数据进行加密的场景。
破解思路 和对称加密不同之处在于,⾮对称加密的公钥很容易获得,因此制造原⽂-密⽂对是没有困难的事。所以,⾮对称加密的关键只在于,如何找到⼀个正确的私钥,可以解密所有经过公钥加密过的密⽂。找到这样的私钥即为成功破解。由于⾮对称加密的⾃身特性,怎样通过公钥来推断出私钥通常是⼀种思路(例如 RSA),但往往最佳⼿段依然是穷举法,只是和对称加密破解的区别在于,对称加密破解是不断尝试⾃⼰的新密钥是否可以将自己拿到的原⽂-密⽂对进⾏加密和解密,⽽⾮对称加密是不断尝试⾃⼰的新私钥是否和公钥互相可解。
反破解 和对称加密⼀样,⾮对称加密算法优秀的标准同样在于,让破解者找不到⽐穷举法更有效的破解⼿段,并且穷举法的破解时间⾜够⻓。
混合加密 混合加密是指使用对称加密和非对称加密相结合的加密算法。在混合加密中,发送方和接收方使用不同的密钥进行加密和解密操作,因此加密和解密的过程都是基于不同的密钥。 常见的混合加密算法包括:
SSL/TLS:一种基于非对称加密和对称加密相结合的加密算法,由Netscape公司于1995年提出。 混合加密的优点是加密和解密的速度相对较快,适用于对大量数据进行加密的场景。然而,混合加密的缺点是密钥的分发和管理比较复杂,需要确保密钥的安全性。
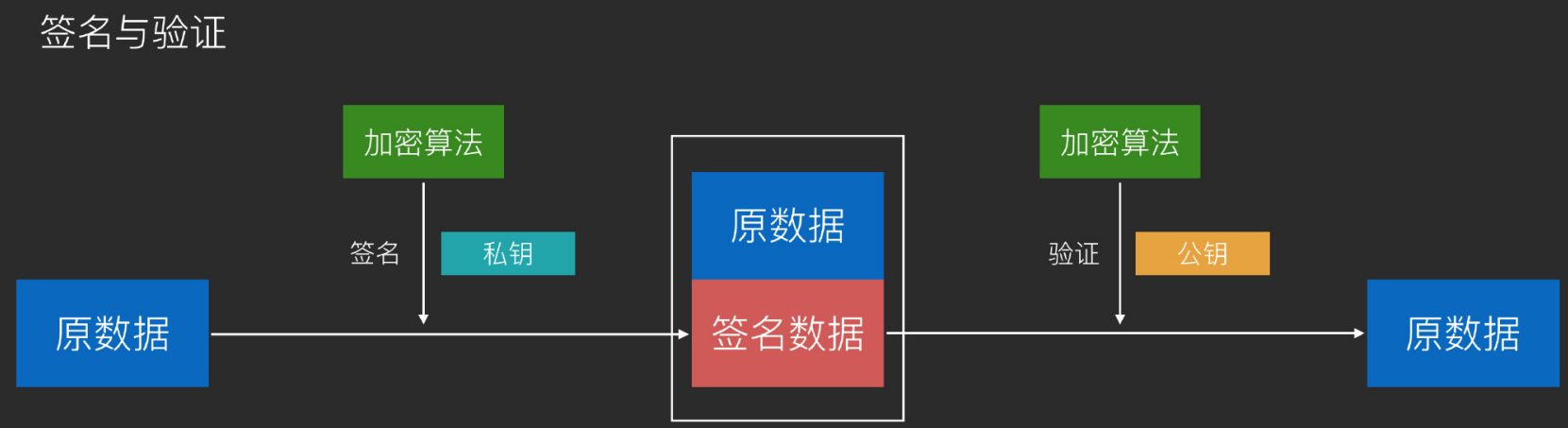
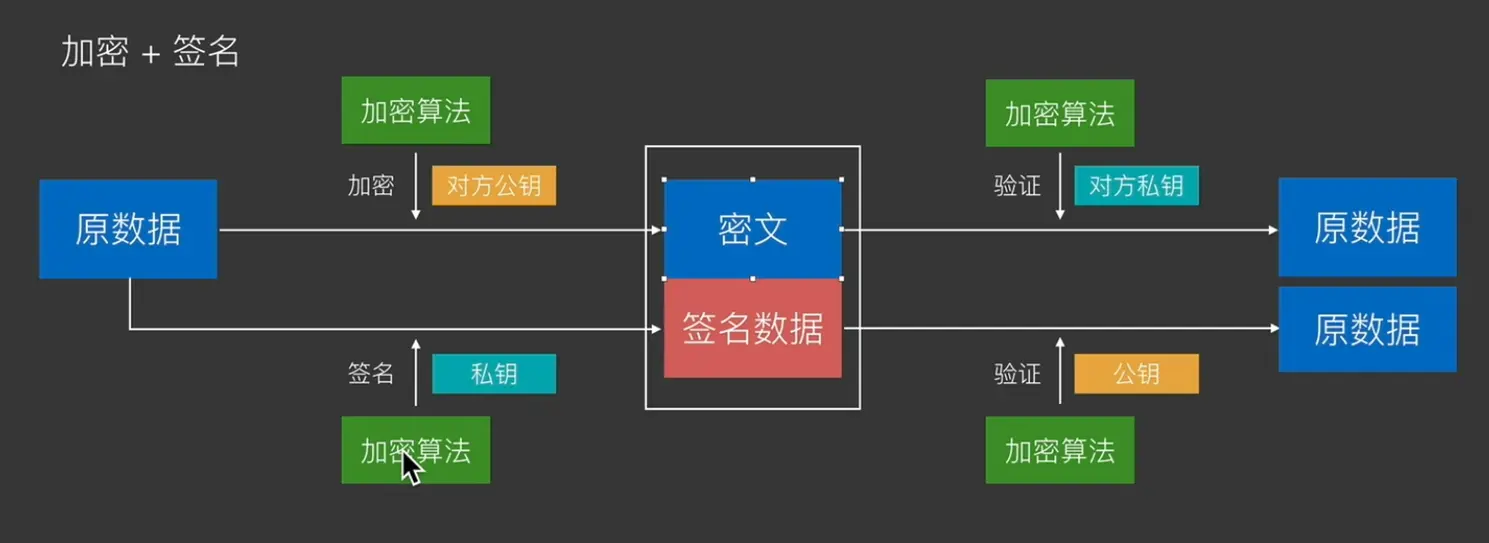
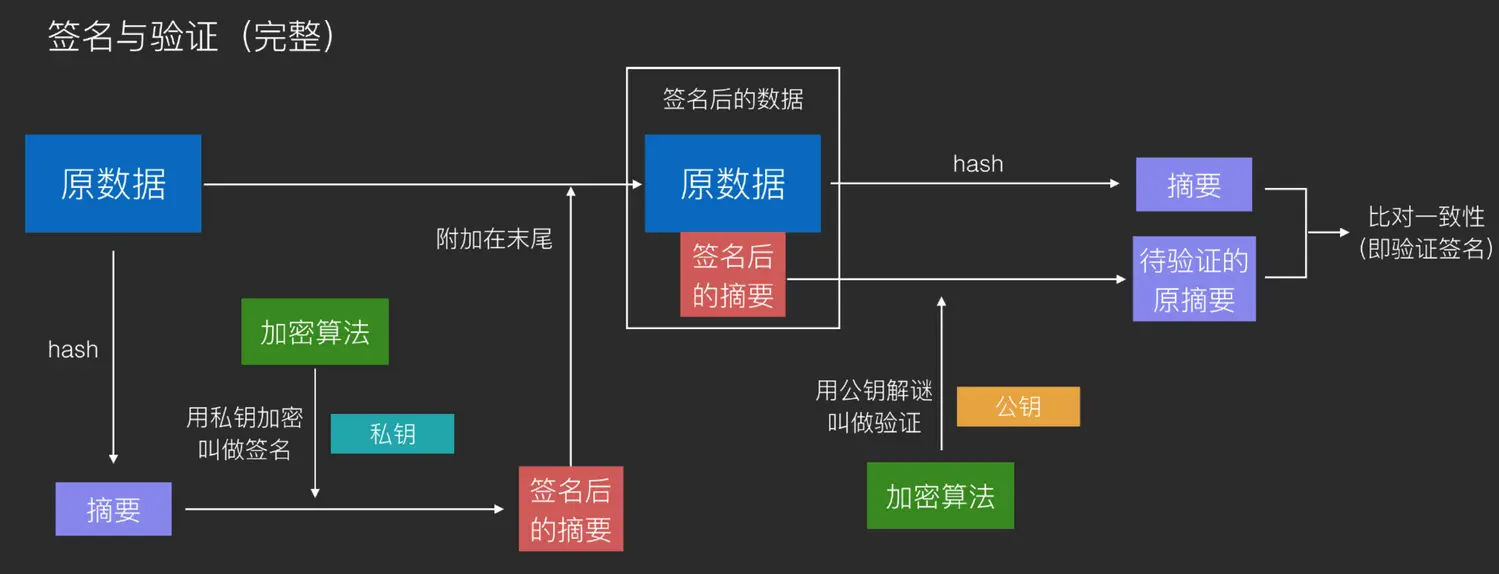
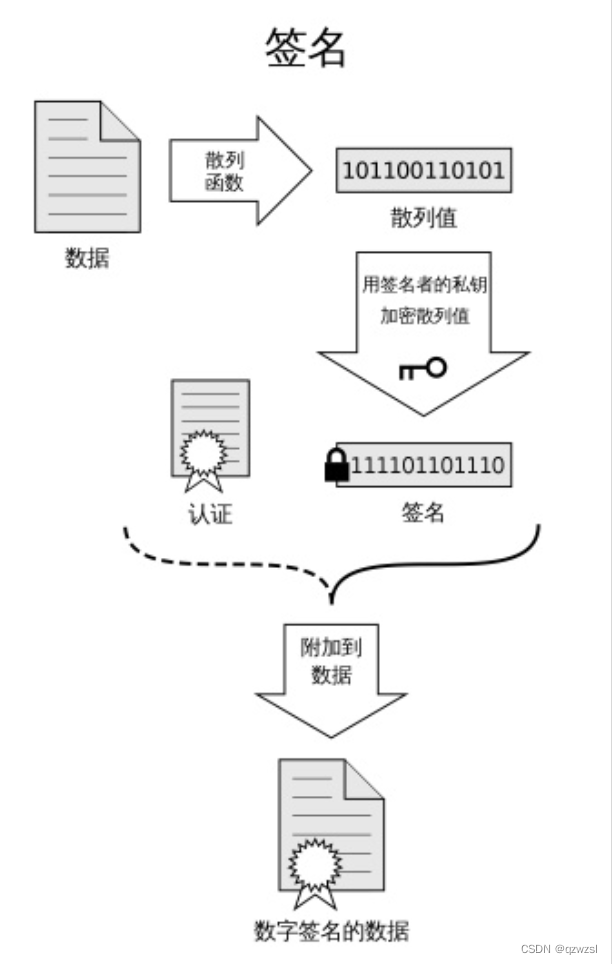
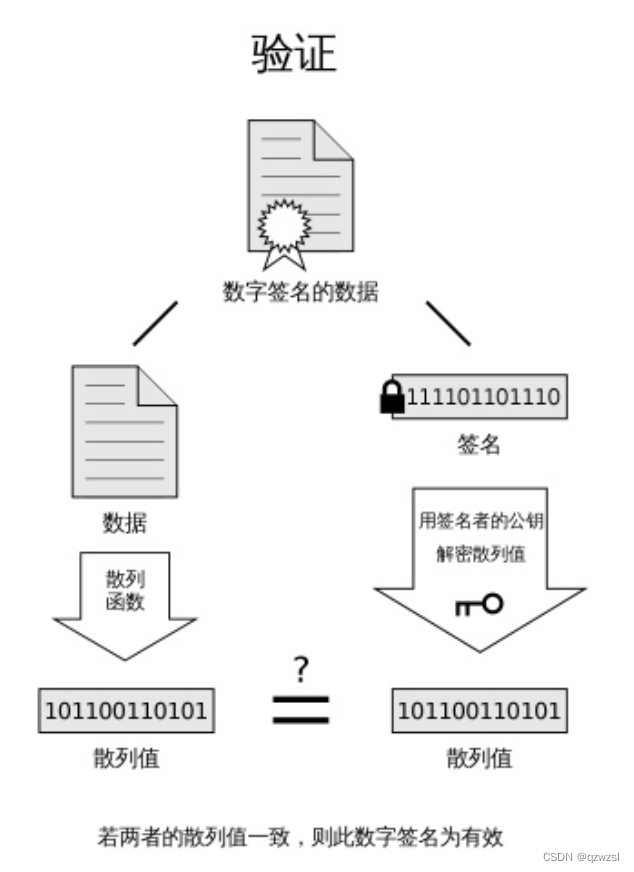
签名与验证 签名:用于让任何人都知道这个内容确实是来自我的。用自己的私钥来加密,那么任何人去用对应的公钥来解密,都可以得到原数据。加密后的那个密文只有我造得出来,只有我造的加密数据可以用我的公钥解密出原数据,就可以证明这个东西是属于我的。
往往会把原数据与签名数据一起放出,让其他节点可以用公钥去解密对比。
加密+签名 用两方的公钥私钥配合,可以制造签了名的加密数据。
防伪造 坏人C用B的公钥来制造加密假数据,B拿到后,用自己的私钥一解密也可以得到正常的数据。
用上面的签名+加密的方式就可以避免这种伪造的情况。
A使用B的公钥发消息,同时用A的私钥签名,那么B拿到消息后,用A的公钥去验证,用自己的私钥来解密数据。就可以确切的知道这个数据是来自A的。而中间的C既看不懂,也无法伪造与篡改。
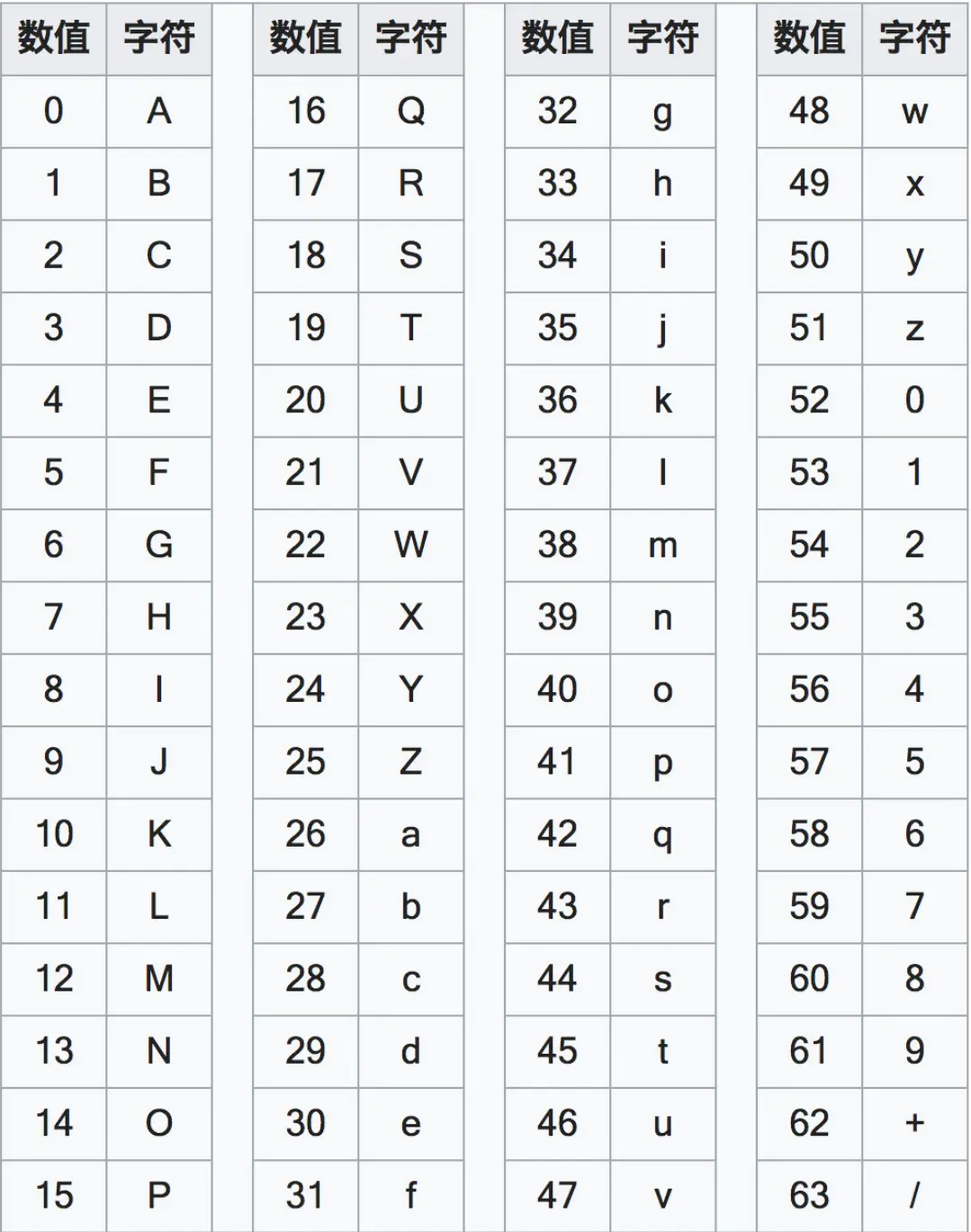
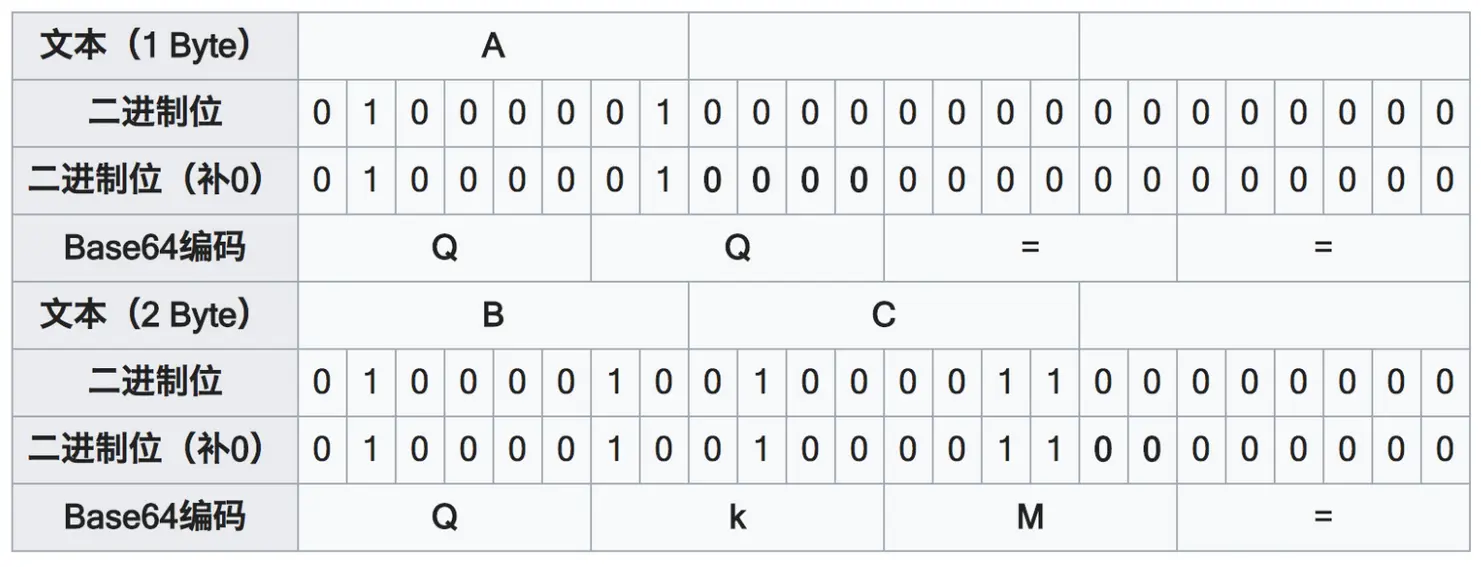
编码 Base64 Base64是一种基于64个可打印字符来表示二进制数据的表示方法。它通常用于在URL、Cookie、HTML等文本数据中传输二进制数据。
什么是二进制数据? ⼴义:所有计算机数据都是⼆进制数据 狭义:⾮⽂本数据即⼆进制数据(图片,视频,,,) 文本数据:字符串
码表
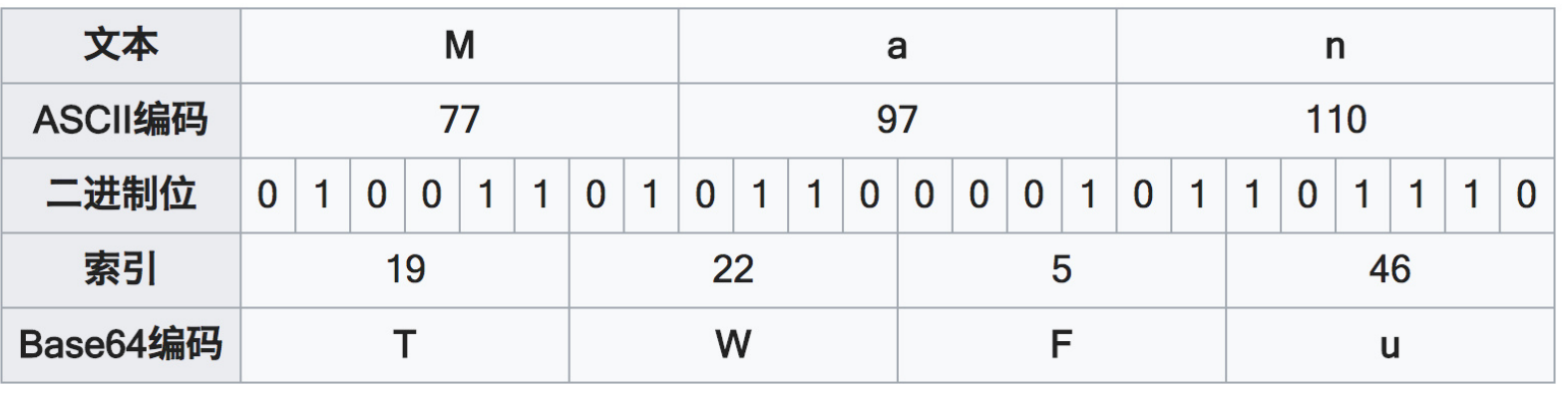
例如将字符串”Man”进行Base64编码:
转换后的位数不是6的整数时,会对末尾进行补0:
在Java中,可以使用java.util.Base64类来进行Base64编码和解码。
import java.util.Base64 ;
public class Base64Example {
public static void main ( String [] args ) {
String originalString = "Hello, World!" ;
byte [] originalBytes = originalString . getBytes ();
}
}
缺点:
因为⾃身的原理(6 位变 8 位),因此每次 Base64 编码之后,数据都会增⼤约 1/3,所以会影响存储和传输性能。
为了性能,那为什么不用八位对八位进行编码呢? 八位对八位需要256个字符,现在没有那么多字符可以来制作编码集。
用途
将⼆进制数据扩充了储存和传输途径(例如可以把数据保存到⽂本⽂件、可以通过聊天对话框或 短信形式发送⼆进制数据、可以在 URL 中加⼊简单的⼆进制数据) 普通的字符串在经过 Base64 编码后的结果会变得⾁眼不可读,因此可以适⽤于⼀定条件下的防 偷窥(较少⽤) 问:Base加密传输图片可以更安全高效吗? Base64无任何加密效果,只是重新编了个码;他把数据变长了1/3,也不算高效。
变种:Base58 把Base64去掉了几个字符(看起来容易混淆的字符): ⽐特币使⽤的编码⽅式,去掉了 Base64 中的数字 “0”,字⺟⼤写 “O”,字⺟⼤写 “I”,和字⺟⼩写 “l”,以及 “+” 和 “/” 符号,⽤于⽐特币地址的表示。因为这些虚拟货币的地址,很大可能会被手抄,去掉容易混淆的几个字符。而➕和/去掉是为了便于双击复制。
变种:URL encoding 在 URL 的字符串中,对⼀些不⽤于特殊⽤途的保留字符,使⽤百分号 “%” 为前缀进⾏单ᇿ编码,以避免出现解析错误。比如中文等字符。
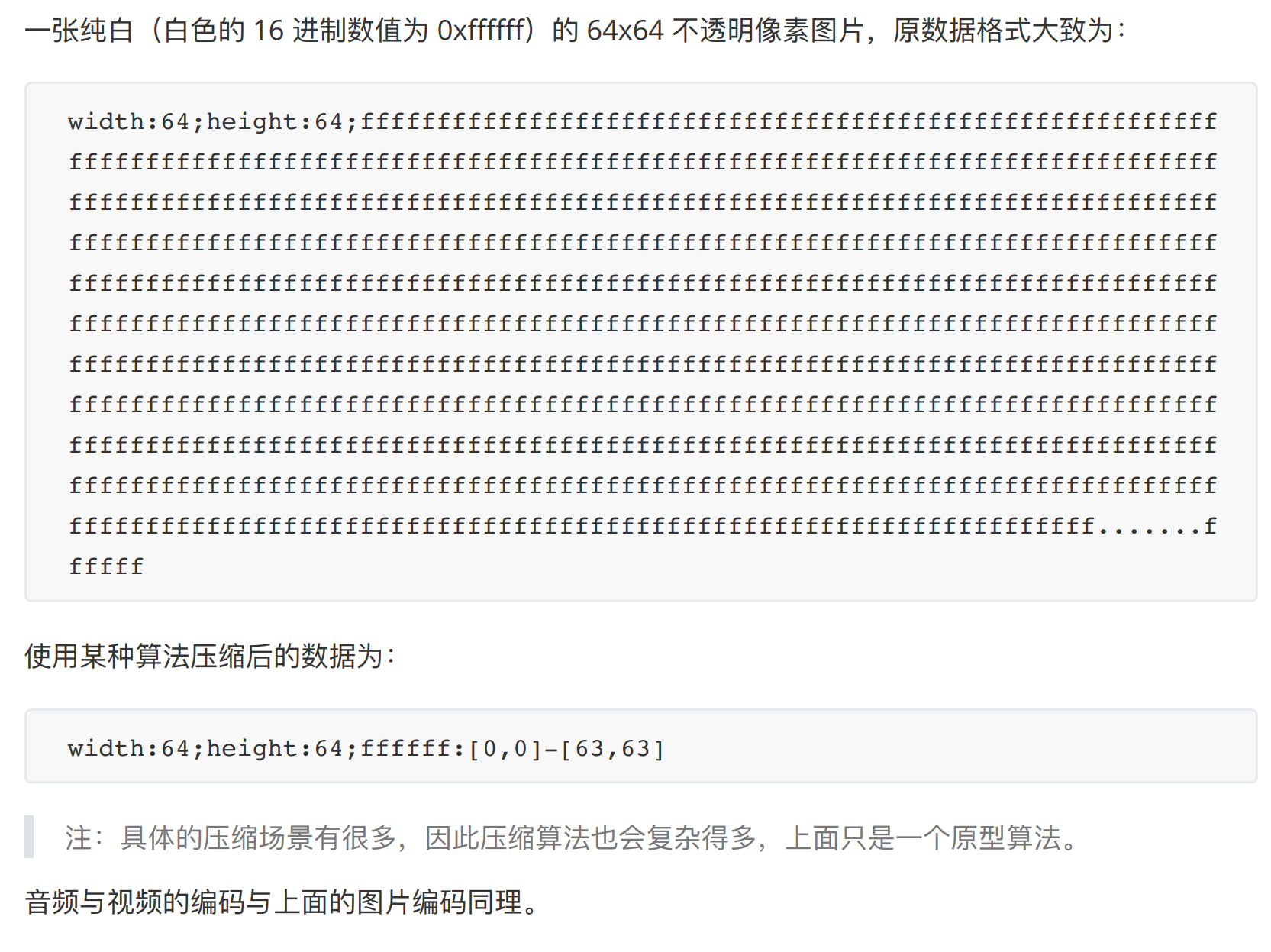
压缩与解压缩 压缩:将数据使⽤更具有存储优势的编码算法进⾏编码。 解压缩:将压缩数据解码还原成原来的形式,以⽅便使⽤。
常见压缩算法:DEFLATE, JPEG, MP3
压缩是编码吗?是的
例如:
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaabbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
使用某种压缩算法处理之后:
图片与音视频的编解码 含义:将图像、⾳频、视频数据通过编码来转换成存档形式(编码),以及从存档形式转换回来(解码)。 目的:方便存储和压缩媒体数据
一张图片的压缩举例:
目前的图片压缩算法,google的Webp比JPEG和PNG更优。
Hash 含义:把任意数据转换成指定⼤⼩范围(通常很⼩,例如 256 字节以内)的数据。
就是从元数据里抽离出特征值,作为Hash值。
例如:把每个学院都编号,001, 002, 003,,,这就是一个Hash的过程。
作用:相当于从数据中提出摘要信息,因此最主要⽤途是数字指纹
经典算法:MD5(容易破解,已经遗弃)、SHA1、SHA256
好的算法需要碰撞率低,即重复率。
实际用途:
数据完整性验证,原数据与现有数据hash值对比。 快速查找:hashCode()和HashMap()。 重写了equals,同时也要重写HashCode。 class HashDemo {
int age ;
String name ;
public boolean equals ( Object obj ) {
age == obj . age &&
name . equals ( obj . name );
}
public long hashCode () {
return age * 100 + name . length ();
}
}
为什么要重写HashCode()?
使用HashMap时,对于HashMap里的元素,有元素要进来时,比较这个元素key的HashCode和现存地址里的key的HashCode,如果不同就添加,如果相同就替换原元素的value。 HashCode没有写好时,发生碰撞时,会把原来那个元素的value给替换掉。 即重写HashCode是为了使用HashMap时不会出错,在equals不相等时,需要HashCode也不相等。
可以用于隐私保护,在储存用户密码时,不可以保存明文,而是将用户密码Hash一次,再存储。数据泄露时因为Hash不可逆,所以仍然不能获取关键数据。
破解:彩虹表,将常用密码与Hash值一一对应,反推出 加盐:做数据Hash时,提前在数据里加入其他的salt,这个盐是不可以泄露的。例如,在密码末尾加333,变成zhukai333,再进行Hash,那彩虹表也会失效。 注意:Hash不属于编码,也不属于加密,它是单向的不可逆转的。
用法举例:联系非对称加密,对数据签名时,会先进行Hash,大幅缩小数据体量,然后再对这个Hash值进行签名。
字符集 含义:⼀个由整数向现实世界中的⽂字符号的 Map 分支: • ASCII:128 个字符,1 字节 • ISO-8859-1:对 ASCII 进⾏扩充,1 字节 • Unicode:13 万个字符,多字节 • UTF-8:Unicode 的编码分⽀ • UTF-16 :Unicode 的编码分⽀ • GBK / GB2312 / GB18030:中国⾃研标准,多字节,字符集 + 编码
WebSocket 是一种在单个 TCP 连接上进行全双工通信的协议。它在 Web 应用中提供了一种持久连接,允许客户端和服务器之间进行实时、双向 的数据传输,而无需像传统的 HTTP 请求那样每次通信都建立新的连接 。这使得 WebSocket 非常适合需要低延迟和高吞吐量的应用,如在线游戏、实时聊天、协作工具、股票行情更新和物联网数据传输等。
核心特性 全双工通信 同时主动发送数据 ,无需等待请求-响应模式,适合实时交互场景(如聊天、游戏、股票行情推送)。
低延迟与高效性 建立连接后,数据帧直接传输 ,省去 HTTP 请求的头部开销(如 Cookie、User-Agent 等重复字段)。 相比 HTTP 轮询(频繁建立/断开连接),WebSocket 维持长连接,减少延迟和资源消耗。 基于 TCP 的可靠传输 为什么需要 WebSocket? 在 WebSocket 出现之前,Web 浏览器和服务器之间的实时通信主要依赖于以下几种技术:
轮询 (Polling) : 客户端定时向服务器发送 HTTP 请求,询问是否有新的数据。这种方式效率低下,会产生大量不必要的请求,并增加服务器负载。长轮询 (Long Polling) : 客户端发送一个 HTTP 请求,服务器保持连接打开,直到有新数据可用或超时。数据发送后,连接关闭,客户端立即发起新的请求。这种方式比轮询有所改进,但仍然是单向的,并且每次数据传输后都需要重新建立连接,依然存在延迟和开销。Comet (Streaming) : 服务器长时间保持 HTTP 连接打开,并不断向客户端发送数据。客户端收到数据后,连接保持打开。虽然实现了单向实时,但仍然是基于 HTTP 请求-响应模式的变种,而且客户端难以向服务器发送实时数据。Flash Sockets/Java Applets : 这些技术需要浏览器插件,兼容性差,且逐渐被淘汰。WebSocket 的出现正是为了解决这些问题,提供一种原生、高效的双向通信机制。
二、协议分层与握手过程 1. 握手阶段(HTTP 升级) WebSocket 连接的建立始于一个特殊的 HTTP 握手 。客户端向服务器发送一个特殊的 HTTP 请求,请求升级到 WebSocket 协议 。
客户端请求示例:
GET /chat HTTP / 1.1
Host : server.example.com
Upgrade : websocket
Connection : Upgrade
Sec-WebSocket-Key : dGhlIHNhbXBsZSBub24gY2U=
Origin : http://example.com
Sec-WebSocket-Version : 13
服务器响应示例:
HTTP / 1.1 101 Switching Protocols
Upgrade : websocket
Connection : Upgrade
Sec-WebSocket-Accept : s3pPLMBiTxaQ9GUfnjUMzdzbCYg=
握手过程的关键点:
Upgrade: websocket 和 Connection: Upgrade:Sec-WebSocket-Key:Sec-WebSocket-Accept。Sec-WebSocket-Version:Sec-WebSocket-Accept:Sec-WebSocket-Key 计算得出的,客户端会验证这个值,确保握手成功。一旦握手成功,HTTP 连接就会“升级”为 WebSocket 连接,此后所有通信都将使用 WebSocket 协议定义的帧格式,不再是 HTTP 请求/响应模式。
2. 数据传输阶段 (Data Transfer) 握手成功后,客户端和服务器之间就可以通过这个持久的 TCP 连接进行双向、全双工的数据传输。数据以 帧 (Frames) 的形式发送,而不是像 HTTP 那样以完整的消息发送。
数据帧格式 WebSocket 数据帧每个帧包含以下字段(简化版):
字段 作用 FIN 标识是否为消息的最后一帧(1 bit) Opcode 帧类型(4 bits):如 0x1 文本、0x2 二进制、0x8 关闭连接等 Mask 是否对负载数据掩码(1 bit,客户端必须设为 1) Payload Length 负载长度(7/16/64 bits,动态扩展) Masking Key 掩码密钥(4 bytes,客户端生成) Payload Data 实际数据(可能被掩码处理)
掩码机制 :客户端发送的数据必须掩码,服务器发送的数据不能掩码,防止缓存代理干扰。
WebSocket 帧的特点:
轻量级: WebSocket 帧头非常小,通常只有几字节,这减少了协议开销。支持多种数据类型: 可以传输文本数据 (UTF-8 编码) 和二进制数据。分片 (Fragmentation): 大的数据可以被分成多个帧进行传输,接收方再将其重组。这对于处理大型文件或需要分批发送的数据非常有用。掩码 (Masking): 从客户端发送到服务器的数据帧必须进行掩码处理,以防止中间代理服务器缓存响应(因为 WebSocket 帧可能看起来像有效的 HTTP 请求)。服务器发送给客户端的数据不需要掩码。心跳机制 (Ping/Pong): WebSocket 内置了 PING 和 PONG 帧,用于客户端和服务器之间发送心跳包,检测连接是否仍然活跃,类似于 MQTT 的 Keep Alive 机制。如果一端发送 PING 帧,另一端必须回复 PONG 帧。3. 连接生命周期管理 关闭连接 Opcode=0x8 的帧,携带 2 字节的状态码(如 1000 正常关闭)。对方需回复相同帧确认关闭。
心跳机制(Ping/Pong)
客户端或服务器可发送 Opcode=0x9 的 Ping 帧探测连接活性。 对方需回复 Opcode=0xA 的 Pong 帧,超时未响应则视为连接断开。 安全性 WebSocket 协议支持加密通信,即 WebSocket Secure (WSS) 。WSS 连接通过 TLS/SSL 进行加密,类似于 HTTPS。这意味着数据在传输过程中是加密的,可以防止窃听和篡改。
ws://:wss://:WebSocket 的应用场景 基于WebSocket上述工作特点,常见的应用领域有下面这些:
实时聊天应用: 即时消息的发送和接收。在线游戏: 多人游戏的实时玩家状态同步和交互。股票行情、金融数据推送: 实时股价、市场数据更新。协作工具: 多个用户同时编辑文档、共享屏幕等。物联网 (IoT): 设备与服务器之间的小型、频繁数据交换。实时通知和报警: 服务器向客户端推送即时通知。在线白板/绘图应用: 实时共享用户绘图操作。Android平台进行WebSocket连接开发 在 Android 端进行 WebSocket 开发非常常见,特别是在需要实时数据传输的应用中,比如聊天、实时通知或物联网仪表盘。我们可以基于okhttp库的功能来实现。
OkHttp 是 Square 公司开发的一个流行的 HTTP 和 WebSocket 客户端。它功能强大、易于使用,并且是 Android 开发中最推荐的网络库之一。
dependencies {
implementation 'com.squareup.okhttp3:okhttp:4.12.0'
}
基本开发步骤 创建 OkHttpClient 实例: 通常,你会在应用中创建一个单例 OkHttpClient 实例。
OkHttpClient client = new OkHttpClient ();
创建 WebSocketRequest: 构建一个 Request 对象,指定 WebSocket 服务器的 URL。
String webSocketUrl = "ws://echo.websocket.org" ; // 替换为你的 WebSocket 服务器地址
Request request = new Request . Builder (). url ( webSocketUrl ). build ();
实现 WebSocketListener: 创建一个实现 WebSocketListener 接口的类,用于处理 WebSocket 事件(打开、关闭、接收消息、失败等)。
public class MyWebSocketListener extends WebSocketListener {
private static final int NORMAL_CLOSURE_STATUS = 1000 ;
@Override
public void onOpen ( @NonNull WebSocket webSocket , @NonNull Response response ) {
super . onOpen ( webSocket , response );
// 连接成功建立时调用
System . out . println ( "WebSocket Connected!" );
// 连接成功后可以发送消息
webSocket . send ( "Hello from Android!" );
// 也可以发送二进制数据
// webSocket.send(ByteString.decodeHex("deadbeef"));
}
@Override
public void onMessage ( @NonNull WebSocket webSocket , @NonNull String text ) {
super . onMessage ( webSocket , text );
// 接收到文本消息时调用
System . out . println ( "Receiving Text: " + text );
}
@Override
public void onMessage ( @NonNull WebSocket webSocket , @NonNull ByteString bytes ) {
super . onMessage ( webSocket , bytes );
// 接收到二进制消息时调用
System . out . println ( "Receiving Bytes: " + bytes . hex ());
}
@Override
public void onClosing ( @NonNull WebSocket webSocket , int code , @NonNull String reason ) {
super . onClosing ( webSocket , code , reason );
// WebSocket 即将关闭时调用
System . out . println ( "Closing: " + code + " / " + reason );
webSocket . close ( NORMAL_CLOSURE_STATUS , null ); // 告知服务器正常关闭
}
@Override
public void onFailure ( @NonNull WebSocket webSocket , @NonNull Throwable t , @Nullable Response response ) {
super . onFailure ( webSocket , t , response );
// 连接失败时调用,例如网络问题、握手失败等
System . err . println ( "Error: " + t . getMessage ());
if ( response != null ) {
System . err . println ( "Error Response: " + response . code () + " " + response . message ());
}
}
@Override
public void onClosed ( @NonNull WebSocket webSocket , int code , @NonNull String reason ) {
super . onClosed ( webSocket , code , reason );
// WebSocket 完全关闭时调用
System . out . println ( "WebSocket Closed: " + code + " / " + reason );
}
}
建立 WebSocket 连接: 在你的 Activity 或 Service 中,创建 MyWebSocketListener 实例,并通过 OkHttpClient 发起连接。
public class MyActivity extends AppCompatActivity {
private WebSocket webSocket ;
private OkHttpClient client ;
@Override
protected void onCreate ( Bundle savedInstanceState ) {
super . onCreate ( savedInstanceState );
setContentView ( R . layout . activity_main );
client = new OkHttpClient (); // 初始化一次,最好作为单例
String webSocketUrl = "ws://echo.websocket.org" ; // 公共测试 WebSocket 服务器
Request request = new Request . Builder (). url ( webSocketUrl ). build ();
MyWebSocketListener listener = new MyWebSocketListener ();
webSocket = client . newWebSocket ( request , listener ); // 发起连接
// 示例:可以在连接建立后发送消息,但在实际应用中通常在 onOpen 回调中发送
// webSocket.send("Hello World!");
}
@Override
protected void onDestroy () {
super . onDestroy ();
if ( webSocket != null ) {
webSocket . close ( MyWebSocketListener . NORMAL_CLOSURE_STATUS , "Goodbye!" ); // 在 Activity 销毁时关闭连接
}
if ( client != null ) {
client . dispatcher (). executorService (). shutdown (); // 关闭 OkHttpClient 的线程池
}
}
// 可以添加一个方法来发送消息
public void sendMessage ( String message ) {
if ( webSocket != null ) {
webSocket . send ( message );
}
}
}
注意事项 权限: 确保在 AndroidManifest.xml 中添加网络权限:<uses-permission android:name= "android.permission.INTERNET" />
线程: OkHttp 的 WebSocket 回调是在其内部的线程池中执行的。如果你需要在这些回调中更新 UI,请确保切换到主线程(例如使用 runOnUiThread() 或 Handler)。生命周期管理: 妥善管理 WebSocket 连接的生命周期。在 Activity/Fragment 销毁时关闭连接,避免内存泄漏或不必要的网络活动。对于需要后台持久连接的应用,应该考虑使用 Android Service 来管理 WebSocket 连接。重连机制: 生产环境中,你需要实现一套健壮的重连机制。当 onFailure 或 onClosed 被调用时,根据错误类型和网络状态进行指数退避或其他策略的重连尝试。心跳/Keep Alive: WebSocket 协议自带 PING/PONG 帧,OkHttp 会自动处理这部分。但如果你服务器有特殊的超时设置,可能需要调整 OkHttp 的 readTimeout 或自己实现更精细的心跳逻辑(通常不需要)。安全性 (WSS): 如果你的服务器使用 wss:// (WebSocket Secure),OkHttp 会自动处理 SSL/TLS 加密。确保你的服务器证书是可信的,或者配置 OkHttpClient 来信任自签名证书(生产环境不推荐)。背景 MQTT是一个客户端服务端架构的发布/订阅模式的消息传输协议。它的设计思想是轻巧、开放、简单、规范,易于实现。这些特点使得它对很多场景来说都是很好的选择,特别是对于受限的环境如机器与机器的通信(M2M)以及物联网环境(IoT)。 ——MQTT协议规范中文版
MQTT协议最初版本是在1999年建立的。该协议的发明人是的Andy Stanford-Clark和Arlen Nipper。
MQTT 的诞生,是在一个利用卫星通讯监控输油管道的项目。
所以它最初是面对 低带宽、高延迟或不可靠的网络 而设计的。虽然历经几十年的更新和变化,以上这些特点仍然是MQTT协议的核心特点。但是与最初不同的是,MQTT协议已经从嵌入式系统应用拓展到开放的物联网(IoT)领域。
版本 MQTT协议有三个版本,分别是:
MQTT v3.1 MQTT v3.1.1 MQTT v5.0 目前客户端很多主流的MQTT库都是基于MQTT v3.1.1版本。而且后续的5.0是完全兼容3.1.1版本的,所以优先学习这个3.1.1版本。
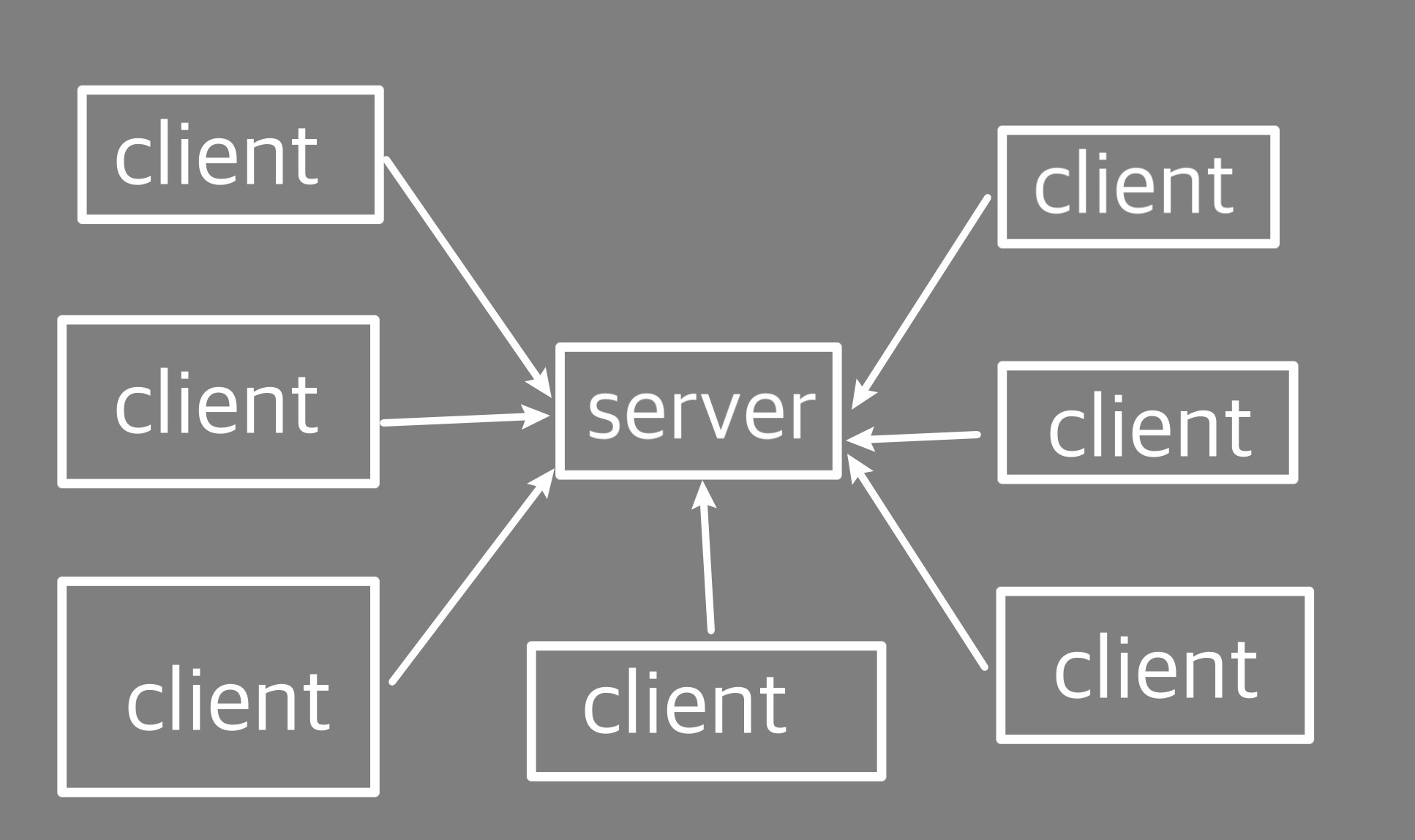
基本通信介绍 和其他网络通信流程一致,MQTT通信中的角色也是分为服务端和客户端。
服务端是MQTT信息传输的枢纽,负责将MQTT客户端发送来的信息传递给MQTT客户端。MQTT服务端还负责管理MQTT客户端。确保客户端之间的通讯顺畅,保证MQTT消息得以正确接收和准确投递。 客户端可以往服务端推送消息和获取消息。 MQTT协议的通信架构是独特的 订阅/发布机制 ,不像HTTP那种 请求/响应机制 ,从服务端获取数据需要客户端主动发起请求,服务端才能返回数据。
MQTT的通信机制更像是Android里的广播 ,客户端可以订阅(Subscribe) 某个主题,当服务端发现这个主题被某一个客户端发布(Publish) 更新时,就会将消息推送给订阅了该主题的客户端。
订阅发布机制 MQTT服务端在管理MQTT信息通讯时,就是使用一个个的“主题”来控制的。
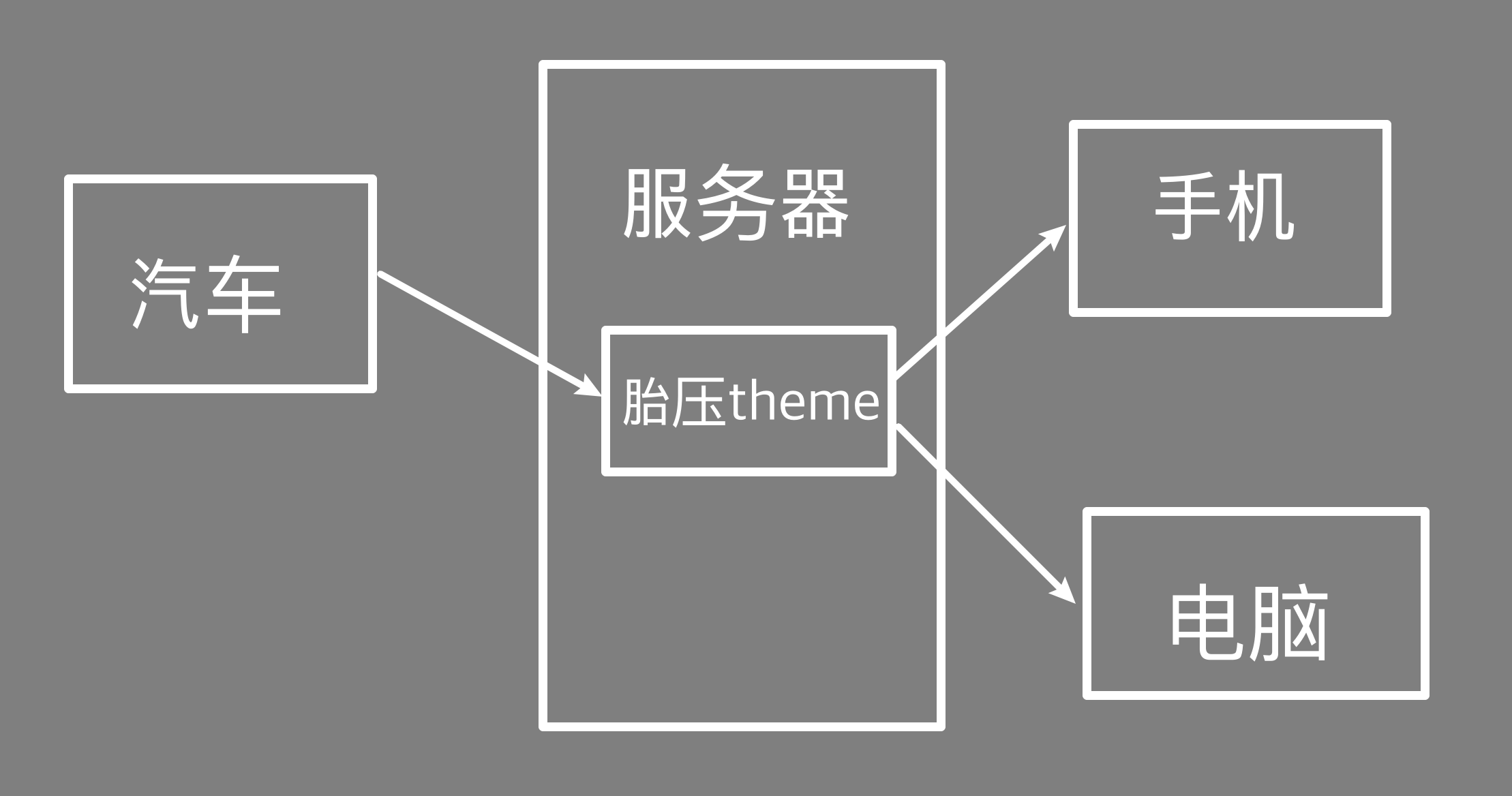
比如车载云平台开发时,就会有一个 车辆状态 的主题,当车辆状态发生变化时,就会往这个 车辆状态 主题发送消息。具体的,当汽车的胎压传感器有数据上报时,就会往“胎压传感器”这个主题发送消息。手机客户端,订阅了这个胎压主题,就可以收到胎压传感器上报到服务器,而后分发下来的消息。
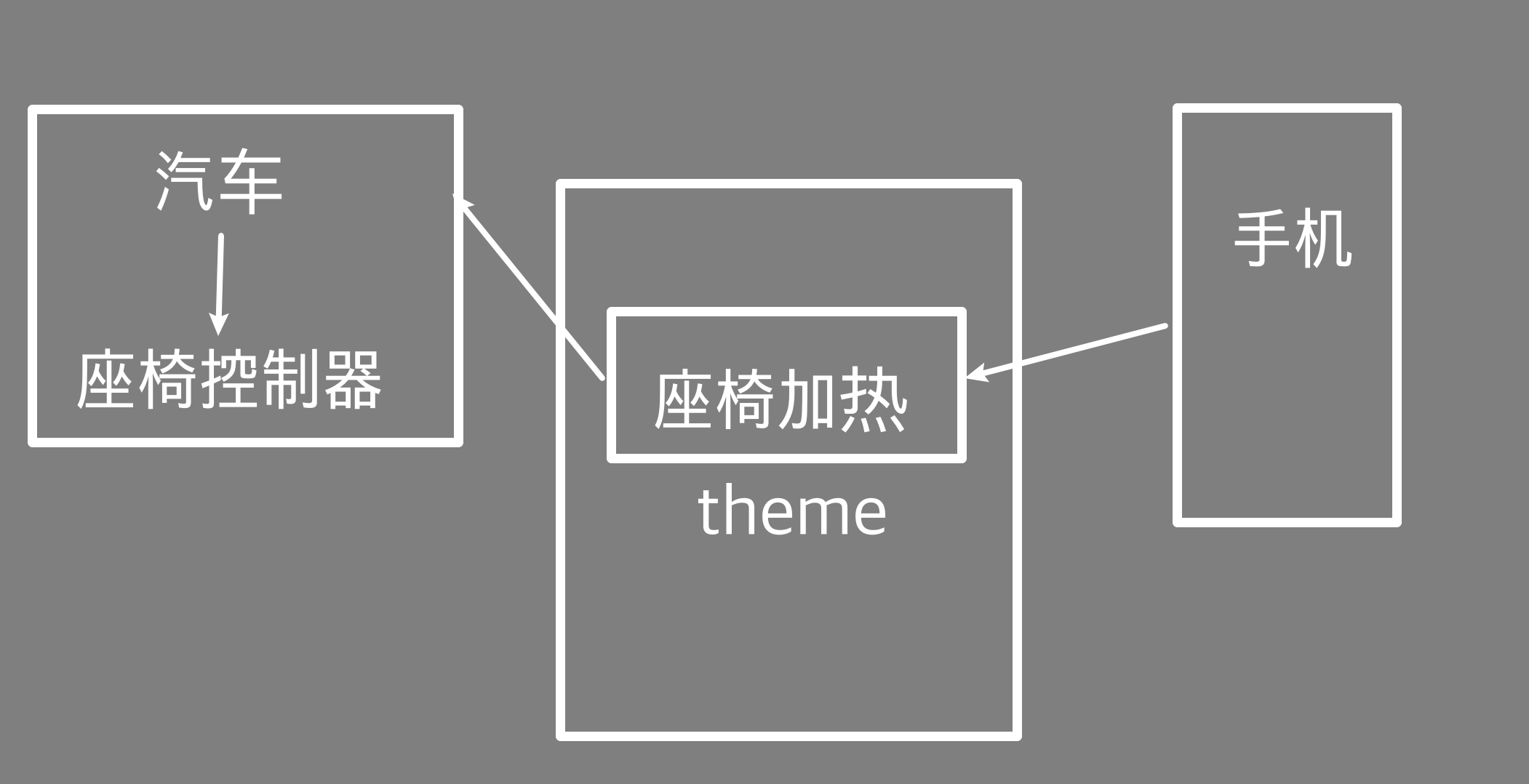
同时,手机端可以往 座椅加热 这个主题发布消息,打开开关。服务器收到消息后,就会下发到订阅这个主题的汽车客户端,车辆控制器收到后就可以远程打开座椅加热。在冬天,司机上车之前就可以提前打开座椅加热,上车之后就不会被冻了。
订阅发布的特性 从以上实例我们可以看到,MQTT通讯的核心枢纽是MQTT服务端。有了服务端对MQTT信息的接收、储存、处理和发送,客户端在发布和订阅信息时,可以相互独立,且在空间上可以分离,时间上可以异步。
相互可独立 MQTT客户端是一个个独立的个体。它们无需了解彼此的存在,依然可以实现信息交流。客户端本身可以完全不知道有多少个MQTT客户端订阅了这一主题。而订阅了同一主题的客户端也完全不知道彼此的存在。大家只要订阅了同一个主题,MQTT服务端就会在每次收到新信息时,将信息发送给订阅的客户端。
空间可分离 空间分离相对容易理解,MQTT客户端在通讯必要条件是连接到了同一个MQTT通讯网络。这个网络可以是互联网或者局域网。只要客户端联网,无论他们远在天边还是近在眼前,都可以实现彼此间的通讯交流。
时间可异步 MQTT客户端在发送和接收信息时无需同步 。这一特点对物联网设备尤为重要。有时物联网设备会发生意外离线的情况。当我们的汽车在行驶过程中,可能会突然进入隧道,这时汽车可能会断开与MQTT服务端的连接。假设在此时我们的手机客户端向汽车客户端所订阅的“空调温度”主题发布了信息,而汽车恰恰不在线。这时,MQTT服务端可以将“空调温度”主题的新信息保存,待汽车再次上线后,服务端再将“空调温度”信息推送给汽车。
主题Topic MQTT协议中,消息的传输是通过主题来实现的。主题是一个字符串,用来标识消息的类型。当客户端订阅了一个主题时,服务端会将该主题的信息发送给客户端。当客户端发布了一个主题时,服务端会将该主题的信息发送给所有订阅了该主题的客户端。
主题格式 MQTT主题是一个字符串,用来标识消息的类型。主题可以包含多个单词,单词之间使用斜杠(/)分隔。同时,主题也可以分级,例如:
motor_speed motor_speed/left motor_speed/right 这些主题可以用来标识不同类型的消息。例如,“motor_speed”主题可以用来标识电机的速度信息,而“motor_speed/left”主题可以用来标识左电机的速度信息。
定义主题时,需要注意以下几点:
主题是区分大小写的 。如上列表中的主题 motor_speed和Motor_speed是两个完全不同的主题。主题可以使用空格 ,如以上列表中的current time,虽然有空格分隔current和time这两个词,但这实际是一个MQTT主题。不过,虽然我们可以使用空格,但是笔者强烈建议您不要在主题中使用空格。我们在开发时一不小心,可能就会漏掉空格,这将造成不必要的麻烦。大部分MQTT服务端是 不支持中文主题 的,所以我们应使用英文字符或ASCII字符来作为MQTT主题。 主题通配符 当客户端订阅主题时,可以使用通配符同时订阅多个主题。通配符只能在订阅主题时使用,下面我们将介绍两种通配符:单级通配符和多级通配符。
单级通配符: + 顾名思义,单级通配符可以代替一个主题级别。 以下为含有单极通配符的主题示例。
home/sensor/+/temperature
当客户端订阅了以上主题后,它将会收到以下主题的信息内容:
home/sensor/kitchen/temperature
home/sensor/bedroom/temperature
我们可以看到,在home后面的级别中,由于客户端订阅的主题使用了+ 单级通配符,因此无论home级别后面的内容是什么,客户端都能收到这些主题的信息。
相反,客户端将无法收到以下主题的信息。
home/sensor/bedroom/brightness
office/sensor/bedroom//temperature
home/screen/livingroom/temperature
以上主题的红色部分都是客户端无法收到信息的原因。这些红色的部分都是与客户端订阅的主题“home/sensor/+/temperature”不相符的部分。
多级通配符 # 单级通配符仅可代替一个主题级别,而多级通配符”#”可以涵盖任意数量的主题级别。如下示例所示, 多级通配符必须是主题中的最后一个字符。
当客户端订阅了以上含有”#”的主题后,可以收到以下主题的信息。
home/sensor/kitchen/temperature
home/sensor/bedroom/brightness
home/sensor/data
多级通配符可以代替多级主题信息,因此无论”home/sensor”后面有一级还是多级主题,都可以被订阅了”home/sensor/#”的客户端接收到。
注意事项 以$开始的主题 以 $ 开始的主题是 MQTT服务端系统保留的特殊主题 ,我们不能随意订阅或者向其发布信息。以下是此类主题的示例:
$SYS/broker/clients/connected
$SYS/broker/clients/disconnected
$SYS/broker/clients/total
$SYS/broker/messages/sent
$SYS/broker/uptime
类似的主题还有很多。不过请记住一点,以$符号开头的主题是系统保留的特殊主题,我们不能随意订阅或者向其发布信息 。
不要用 “/” 作为主题开头 MQTT允许使用“/”作为主题的开头,例如/home/sensor/data。但是这将这么做毫无意义,而且会额外产生一个没有用处的主题级别。所以我们应避免使用/作为主题的开头。
连接服务器 分为两步,第一步是客户端发送连接请求,第二步是服务端发送连接确认。
一、客户端连接请求 首先MQTT客户端将会向服务端发送连接请求。该请求实际上是一个包含有连接请求信息的数据包。这个数据包的官方名称为CONNECT。
有三个必选参数:
客户端ID – 客户端的唯一标识。 cleansession – 是否清除该客户端之前的会话。 keepalive – 心跳时间,用于确认连接状态。 clientId ClientId 是MQTT客户端的标识。MQTT服务端用该标识来识别客户端。因此ClientId必须是独立的 。如果两个MQTT客户端使用相同ClientId标识,服务端会把它们当成同一个客户端来处理。
通常ClientId是由一串字符所构成的,如上图所示,此示例中的clientID是“client-1”。在车载端,clientID是由车载设备的唯一标识所构成的,通常为内部项目号加上车架号 ,也就是俗称的 VIN 码。
cleanSession 如果 cleanSession 被设置为“true”。那么服务端不需要客户端确认收到报文,也不会保存任何报文。在这种情况下,即使客户端错过了服务端发来的报文,也没办法让服务端再次发送报文。
将 cleanSession 设置为”false”。那么服务端就知道,后续通讯中,客户端可能会要求我保存没有收到的报文。
如果某个客户端用于收发非常重要的信息 (比如前文示例中汽车自动驾驶系统),那么该客户端在连接服务端时,应该将 cleanSession 设置为 false 。这样才能让服务端保存那些没有得到客户端接收确认的信息。以便服务端再次尝试将这些重要信息再次发送给客户端。请注意,如果需要服务端保存重要报文,光设置cleanSession 为false是不够的,还需要传递的MQTT信息QoS级别大于0。
相反的,如果某个客户端用于收发不重要的信息 (比如前文示例中车载音乐系统)那么该客户端在连接服务端时,应该将cleanSession设置为 true 。
keepalive keepalive是一个心跳时间 。该时间用来检测客户端是否在线 。如果客户端超过所设置的keepalive时间后,仍然没有收到服务端的任何报文,那么服务端就会认为客户端已经掉线。此时服务端会断开与客户端的连接。
其他参数 除了这三个必选的参数,同时还有几个可选参数 :
用户名 – 连接到MQTT服务端的用户名。 密码 – 连接到MQTT服务端的密码。 遗嘱消息 – 当客户端意外断开连接时,发布遗嘱消息。 遗嘱主题 – 当客户端意外断开连接时,会像该遗嘱主题发布遗嘱消息。 遗嘱QoS – 当客户端意外断开连接时,遗嘱消息的服务质量。 用户密码认证 username(用户名)和password(密码)是可选的CONNECT信息 。也就是说,有些服务端开启了客户端用户密码认证,这种服务端需要客户端在连接时正确提供认证信息才能连接。当然,那些没有开启用户密码认证的服务端无需客户端提供用户名和密码认证信息。
有些公用MQTT服务端也利用此信息来识别客户端属于哪一个用户,从而对客户端进行管理。比如用户可以拥有私人主题 ,这些主题只有该用户可以发布和订阅。对于私人主题,服务端就可以利用客户端连接时的用户名和密码来判断该客户端是否有发布订阅该用户私人主题的权限。
二、服务端连接确认 MQTT服务端收到客户端连接请求后,会向客户端发送连接确认。同样的,该确认也是一个数据包。这个数据包官方名称为CONNACK。
returnCode 这里可以类比HTTP的状态码。当服务端收到了客户端的连接请求后,会向客户端发送returnCode(连接返回码),用以说明连接情况。如果客户端与服务端成功连接 ,则返回数字 “0” 。如果未能成功连接,连接返回码将会是一个非零的数值,具体这个数值的含义如下:
0——成功连接 1——连接被服务端拒绝,原因是不支持客户端的MOTT协议版本 2——连接被服务端拒绝,原因是不支持客户端标识符的编码可能造成此原因的是客户端标识符编码是UTF-8,但是服务端不允许使用此编码, 3——连接被服务端拒绝,原因是服务端不可用。即,网络连接已经建立,但MQTT服务不可用。 4——连接被服务端拒绝,原因是用户名或密码无效。 5——连接被服务端拒绝,原因是客户端未被授权连接到此服务。 sessionPresent sessionPresent是一个布尔值。如果该值为“true”,则表示服务端已经保存了与客户端的会话。如果该值为“false”,则表示服务端没有保存与客户端的会话。
当重要客户端连接服务端时, 服务端可能保存着没有得到确认的报文 。如果是这样的话,那么客户端在连接服务端时,就会通过sessionPresent来了解服务端是否有之前未能确认的信息。
QoS服务质量 MQTT协议有三种服务质量级别:
QoS = 0 – 最多发一次 QoS = 1 – 最少发一次 QoS = 2 – 保证收一次
以上三种不同的服务质量级别意味着不同的MQTT传输流程。对于较为重要的MQTT消息,我们通常会选择QoS>0的服务级别(即QoS 为1或2)。
QoS=0 0是服务质量QoS的最低级别。当QoS为0级时,MQTT协议并不保证所有信息都能得以传输。也就是说,QoS=0的情况下,MQTT服务端和客户端不会对消息传输是否成功进行确认和检查。消息能否成功传输全看网络环境是否稳定。
也就是说,在QoS为0时。发送端一旦发送完消息后,就完成任务了。 发送端不会检查发出的消息能否被正确接收到。
QoS=1 QoS=1是服务质量QoS的中间级别。当QoS为1级时,MQTT协议会保证消息至少被传输一次。
当QoS=1时,MQTT服务端和客户端会对消息传输进行确认。也就是说,当MQTT服务端收到了客户端的消息后,会向客户端发送一个PUBACK(发布确认)报文。客户端收到PUBACK报文后,就知道消息已经被服务端成功接收。 保证收到一次消息的兜底机制,救赎客户端发送后会启动一个计时器,当倒计时结束还没有收到服务端反馈时,就再次发送。所以QoS为1时,有重复发送的可能。
QoS=2 MQTT服务质量最高级是2级,即QoS = 2。当MQTT服务质量为2级时,MQTT协议可以确保接收端只接收一次消息。这个最高质量的通信,是通过 两阶段确认,共四次握手 来实现的。
流程:
发送端发送QoS=2的 PUBLISH 报文给接收端,这条报文会附带一个 packetId 数据包标识符,用于识别单次通信并作为去重的依据; 接收端收到QoS为2的消息后,会把此报文进行临时存储,并立即返回 PUBREC (Publish Received) 报文作为应答。后面如果再次收到同一个 packetId 的消息时,会主动去重; 发送端收到接收端反馈的 PUBREC 报文后,可以确定接收方已经收到了第一次的消息,就不会再重复发送PUBLISH消息。然后,发送端会再次发送一条 PUBREL(Publish Release) 释放报文作为应答; 当接收端收到PUBREL报文后,会应答发送端一条 PUBCOMP(Publish Complete) 报文。至此,一次QoS=2的MQTT消息传输就结束了。 发布,订阅,取消订阅 PUBLISH – 发布信息 SUBSCRIBE – 订阅主题 SUBACK – 订阅确认 UNSUBSCRIBE – 取消订阅 一、PUBLISH发布信息 MQTT客户端可以向MQTT服务端发布信息。发布信息的数据包的官方名称为PUBLISH。
MQTT 中的 PUBLISH 消息具有多个决定其行为的属性,包括数据包标识符、主题名称、服务质量、保留标志、有效负载和 DUP 标志。让我们逐一了解一下。
topicName – 主题名 主题名用于识别此信息应发布到哪一个主题。
qos – 服务质量 QoS(Quality of Service)表示MQTT消息的服务质量等级。QoS有三个级别:0、1和2。QoS决定MQTT通讯有什么样的服务保证。
packetId – 数据包标识符 报文标识符可用于对MQTT报文进行标识。不同的MQTT报文所拥有的标识符不同。MQTT设备可以通过该标识符对MQTT报文进行甄别和管理。请注意:报文标识符的内容与QoS级别有密不可分的关系。只有QoS级别大于0时,报文标识符才是非零数值。如果QoS等于0,报文标识符为0。
retainFlag – 保留标志 在默认情况下,当客户端订阅了某一主题后,并不会马上接收到该主题的信息。只有在客户端订阅该主题后,服务端接收到该主题的新信息时,服务端才会将最新接收到的该主题信息推送给客户端。
但是在有些情况下,我们需要客户端在订阅了某一主题后马上接收到一条该主题的信息。这时候就需要用到保留标志这一信息。
在需要发布保留消息时,MQTT设备需要将PUBLISH报文中retainFlag设置为true(如上图所示)。
当然,如果要发布非保留消息,那么PUBLISH报文中retainFlag设置为false。
更新保留消息 每一个主题只能有一个“保留消息”,如果客户端想要更新“保留消息”,就需要向该主题发送一条新的“保留消息”,这样服务端会将新的“保留消息”覆盖旧的“保留消息”。当有客户端订阅该主题时,服务端就会将最新的“保留消息”发送给订阅客户端了。
删除保留消息的方法 如果要删除主题的“保留消息”,可以通过向该主题发布一条空的“保留消息”,也就是发送一条0字节payload的“保留消息”
payload – 有效负载 有效載荷是我们希望通过MQTT所发送的实际内容。我们可以使用MQTT协议发送文本,图像等格式的内容。这些内容都是通过有效載荷所发送的。
dupFlag – 重复标志 当MQTT报文的接收方没有及时确认收到报文时,发送方会重复发送MQTT报文。在重复发送MQTT报文时,发送方会将此“重发标志”设置为true。请注意,重发标志只在QoS级别大于0时使用。
二、SUBSCRIBE订阅主题 客户端要想订阅主题,首先要向服务端发送主题订阅请求。客户端是通过向服务端发送SUBSCRIBE报文来实现这一请求的。
该报文包含有一系列“订阅主题名”。请留意,一个SUBSCRIBE报文可以包含 有单个或者多个 订阅主题名。可以同时订阅一个或者多个主题。
在以上PUBLISH报文讲解中,我们曾经提到过QoS(服务质量等级)这一概念。同样的,客户端在订阅主题时也可以明确QoS。服务端会根据SUBSCRIBE中的QoS来提供相应的服务保证。
另外每一个SUBSCRIBE报文同样包含有“报文标识符”。
三、SUBACK订阅确认 服务端接收到客户端的订阅报文后,会向客户端发送SUBACK报文确认订阅。SUBACK报文包含有“订阅返回码”和“报文标识符”这两个信息。
客户端可通过一个SUBSCRIBE报文发送多个主题的订阅请求。服务端会针对SUBSCRIBE报文中的所有订阅主题来 逐一回复给客户端一个返回码 。
返回码含义:
返回码 Return Code Response 0 订阅成功 – QoS 0 1 订阅成功- QoS 1 2 订阅成功- QoS 2 128 订阅失败
四、UNSUBSCRIBE取消订阅 当客户端要取消订阅某主题时,可通过向服务端发送UNSUBSCRIBE – 取消订阅报文来实现。
UNSUBSCRIBE报文包含两个重要信息,第一个是取消订阅的主题名称。同一个UNSUBSCRIBE报文可以同时包含多个取消订阅的主题名称。另外,UNSUBSCRIBE报文也包含“报文标识符”,MQTT设备可以通过该标识符对报文进行管理。
当服务端接收到UNSUBSCRIBE报文后,会向客户端发送取消订阅确认报文 – UNSUBACK报文。该报文含有客户端所发送的“取消订阅报文标识符”。
客户端接收到UNSUBACK报文后就可以确认取消主题订阅已经成功完成了。
心跳机制 客户端并不经常发送消息给服务端。对于这种客户端,服务端可以使用类似心跳检测的方法,来判断客户端是否在线。
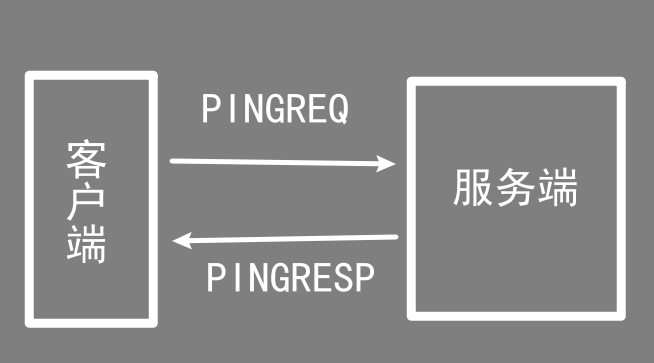
这个心跳机制不仅可以用于服务端判断客户端是否保持连接,也可以用于客户端判断自己与服务端是否保持连接。如果客户端在发送心跳请求(PINGREQ) 后,没有收到服务端的心跳响应(PINGRESP) ,那么客户端就会认为自己与服务端的连接已经被断开了。
客户端发送心跳请求的时间间隔就是连接时CONNECT报文中keepalive的值。
双方对齐了心跳间隔之后,不是每次都必须要发送消息才可以确认连接在线。
如果客户端在心跳时间间隔内 发布了业务消息给服务端 ,那么服务端不需要客户端发送心跳请求也可以确定该客户端肯定在线。
当客户端在心跳间隔内没有新消息发送给服务端,这时客户端才会主动发送一个心跳请求消息给服务端。以表明自己仍让在线。
在实际运行中,如果服务端没有在1.5倍心跳时间间隔内收到客户端发布消息(PUBLISH)或发来心跳请求(PINGREQ),那么服务端就会认为这个客户端已经掉线。
遗嘱消息 在CONNECT报文里,同样有一条遗嘱消息。客户端可以提前设置好一条遗嘱消息,当客户端异常掉线之后,由服务端将这条遗嘱消息发送给其他订阅了这条遗嘱主题的客户端。如果是正常断开,则不会发送。
正常断联 当客户端正常断开连接时,会向服务端发送DISCONNECT报文,服务端接收到该报文后,就知道,客户端是正常断开连接,而并非意外断开连接。
意外断联 然而,当服务端在没有收到DISCONNECT报文的情况下,发现客户端“心跳”停止了,这时服务端就知道客户端是意外断线了。
回顾一下CONNNECT报文:
有关遗嘱消息的参数含义如下:
lastWillTopic – 遗嘱主题 遗嘱消息也有主题和正文内容。lastWillTopic的作用正是告知服务端,本客户端的遗嘱主题是什么。只有那些订阅了这一遗嘱主题的客户端才会收到本客户端的遗嘱消息。
lastWillMessage – 遗嘱消息 遗嘱消息定义了遗嘱消息内容。在本示例中,那些订阅了主题”hans/will”的客户端会在客户端意外断线时,收到服务端发布的“unexpected exit”。
lastWillQoS – 遗嘱QoS 对于遗嘱消息来说,同样可以使用服务质量来控制遗嘱消息的传递和接收。这里的服务质量与普通MQTT消息的服务质量是一样的概念。
lastWillRetain – 遗嘱保留 遗嘱消息也可以设置为保留消息,服务端会根据此处内容,对遗嘱消息进行相应的保留与否处理
HTTP over SSL 的简称,即⼯作在 SSL (或 TLS)上的 HTTP。说⽩了就是加密通信的 HTTP,注意并不是一个单独的协议。HTTPS(SSL/TLS)是计算机网络的知识,主要用来对HTTP协议传输的文本进行加密,提高安全性的一种协议。
SSL:Secure Socket Layer TSL: Transport Layer Secure 因为HTTP是明文传输,所以会很有可能产生中间人攻击(获取并篡改传输在客户端及服务端的信息并不被人发觉),HTTPS加密应运而生。在HTTP之下增加一个安全层,其位于HTTP和TCP之间,更靠近应用层,作用是来加密解密。
本质:在客户端和服务器之间协商出⼀套对称密钥,每次发送信息之前将内容加密,收到之后解密,达到内容的加密传输。 用非对称加密来商讨出一套对称式密钥,再用这个对称密钥来通信。
为啥不直接用非对称加密通信?因为非对称加密效率低,速度慢。
实现流程:
客户端请求建立TLS连接 服务器发回证书 客户端验证服务器的证书 客户端新任服务器之后,和服务器协商对称密钥 最后使用对称密钥开始通信 最后一步才进入HTTP通信的范畴,前面均是TCP通信。
Client Hello 客户端跟服务器请求建立连接,附带告诉服务器,我所支持的TLS版本,还有Cipher Suite加密套件,里面是客户端支持的对称加密算法,非对称加密算法,Hash算法。同时还有一个随机数X。 Server Hello 服务器给客户端返回数据,选择好TLS版本,算法等。同时返回一个随机数Y。 服务器给客户端发送证书,里面核心是非对称加密的公钥,还有服务器的域名,地址,等信息,最后还有服务器的签名,对本次传输所有数据进行签名,表明确实是这个服务器所发。还有证书机构的公钥和证书机构的其他信息签名来对这个服务器的证明数据进行签名,即下图黄色机构对蓝色数据进行签名证明。但是只是可以说明数据确实是由这个公钥对应私钥的持有者所签发。还需要根证书机构的签名对证书机构的签名进行签名,即紫色根证书机构对黄色的证书机构进行签名证明。这个根证书机构的验证来自操作系统内部,到了这一层如果签名能对得上,就可以确定来源的可信了。
根证书的来源:在操作系统生产出的时候,被研发方所认证了的,级上方为一个信任链,到最底层的根证书列表就需要无条件信任。根证书机构很忙,需要一个中间机构去分担压力。
服务器证书验证就通过了。客户端浏览器拿到服务器公钥的时候,使用这个公钥加密一个信息: Pre-master Secret,这也是一个随机数。整个通信过程中唯一一次非对称加密来处理的数据。现在就有三个随机数了,X, Y, Pre-master Secret。前两个随机数X, Y大家都能看见,虽然是明文传输,但加上之后就可以使密钥更安全。现在双方就有足够的信息来生产一个对称加密的密钥了。即Master Secret。这个密钥实际上包含四个东西:客户端加密密钥,服务端加密密钥,客户端Hash Key,服务端Hash Key。HMAC:hash-based message authenticate code,改良版的Hash算法。虽然是对称加密,服务端和客户端之间的通信仍然是用不同的加密密钥来通信,客户端发送时使用客户端加密密钥来加密,服务端接收到之后,使用客户端密钥来解密。用作证明身份,双方都会用MAC Secret来作签名和验证。 双方作一次验证,看上面沟通的加密算法能不能用。 简要的连接建立过程:
Client Hello Server Hello 服务器证书 信任建⽴ Pre-master Secret 客户端通知:将使⽤加密通信 客户端发送:Finished 服务器通知:将使⽤加密通信 服务器发送:Finished 问题:如果另一个拥有合法证书的机构把消息拦截下来,而且也发生给客户端一份完整的ServerHello返给客户端,这样可以建立起HTTPS连接吗? 客户端请求时,会将要访问的Host地址附加在报文里。同样,在服务端的证书包里,也会附加Host名。客户端收到之后,会对Host主机地址进行校验,只有两者域名一致才能通过验证继续往下建立连接。签发证书的机构会将证书和域名进行绑定。
安全性 非对称加密可以防范中间人攻击吗?
鉴于非对称加密的机制,我们可能会有这种思路:服务器先把公钥以明文方式传输给浏览器,之后浏览器向服务器传数据前都先用这个公钥加密好再传,这条数据的安全似乎可以保障了!因为只有服务器有相应的私钥能解开公钥加密的数据。
然而反过来由服务器到浏览器的这条路怎么保障安全?如果服务器用它的私钥加密数据传给浏览器,那么浏览器用公钥可以解密它,而这个公钥是一开始通过明文传输给浏览器的,若这个公钥被中间人劫持到了,那他也能用该公钥解密服务器传来的信息了。所以目前似乎只能保证由浏览器向服务器传输数据的安全性。用两组私钥公钥对即可解决。
所以我们证明了一组公钥私钥,至少可以确保单向的数据安全,那么我可不可以合理推断如果我有两组公钥私钥,那我就可以保证双向数据传输的安全了呢?
某网站服务器拥有公钥A与对应的私钥A’;浏览器拥有公钥B与对应的私钥B’。
浏览器把公钥B明文传输给服务器。
服务器把公钥A明文给传输浏览器。
之后浏览器向服务器传输的内容都用公钥A加密,服务器收到后用私钥A’解密。由于只有服务器拥有私钥A’,所以能保证这条数据的安全。
同理,服务器向浏览器传输的内容都用公钥B加密,浏览器收到后用私钥B’解密。 同上也可以保证这条数据的安全。
bingo!好像成功了!但是这个方法并没有被大范围推广,并且也不可能被大范围推广。很重要的原因是非对称加密算法非常耗时,而对称加密快很多。
好家伙,说来说去又回到对称加密了,合着你就非得用对称加密是吗?
对!就是要找一个方法,让客户端和服务端都知道那个公共密钥并且确保第三方不会获取,那我就是可以放心的使用对称加密传输数据了
对称加密和非对称加密的综合版本 某网站拥有用于非对称加密的公钥A、私钥A’
浏览器向网站服务器请求,服务器把公钥A明文给传输浏览器。
浏览器随机生成一个用于对称加密的密钥X,用公钥A加密后传给服务器。
服务器拿到后用私钥A’解密得到密钥X。
这样双方就都拥有密钥X了,且别人无法知道它。之后双方所有数据都通过密钥X加密解密即可。
成功!HTTPS基本就是采用了这种方案。
但是这并不是完美的,这仍然有漏洞喔!
对称加密和非对称加密的综合版本的漏洞 如果在数据传输过程中,中间人劫持到了数据,此时他的确无法得到浏览器生成的密钥X,这个密钥本身被公钥A加密了,只有服务器才有私钥A’解开它,然而中间人却完全不需要拿到私钥A’就能干坏事了。请看:
某网站有用于非对称加密的公钥A、私钥A’。 浏览器向网站服务器请求,服务器把公钥A明文给传输浏览器。 中间人劫持到公钥A,保存下来,把数据包中的公钥A替换成自己伪造的公钥B(它当然也拥有公钥B对应的私钥B’)。 浏览器生成一个用于对称加密的密钥X,用公钥B(浏览器以为是公钥A)加密后传给服务器。 中间人劫持后用私钥B’解密得到密钥X,再用公钥A加密后传给服务器(保证两方通信能顺利进行)。 服务器拿到后用私钥A’解密得到密钥X。 这样在双方都不会发现异常的情况下,中间人通过一套“狸猫换太子”的操作,掉包了服务器传来的公钥,进而得到了密钥X。根本原因是客户端浏览器无法确认收到的公钥是不是服务器发来的,因为公钥本身是明文传输的。
所以!我们只剩下最后一个问题,那就是怎么确保浏览器收到的公钥是网站的,而不是中间人的!
网站在使用HTTPS前,需要向CA机构申领一份数字证书,数字证书里含有证书持有者信息、公钥信息等。服务器把证书传输给浏览器,浏览器从证书里获取公钥就行了,证书就如身份证,证明“该公钥对应该网站”。而这里又有一个显而易见的问题,“证书本身的传输过程中,如何防止被篡改”?
注意这个CA机构需要完全可信,他的证明需要是有效的。
服务器将自己的公钥,Hash后用服务器的私钥制作签名。再将CA机构的证书一同打包发送给客户端。
每次发送HTTPS请求都需要在TLS/SSL层进行握手传输密钥吗?
如果是的话,那也太浪费资源和时间了吧。
服务器会为每个浏览器(或客户端软件)维护一个session ID,在TLS握手阶段传给浏览器,浏览器生成好密钥传给服务器后,服务器会把该密钥存到相应的session ID下,之后浏览器每次请求都会携带session ID,服务器会根据session ID找到相应的密钥并进行解密加密操作,这样就不必要每次重新制作、传输密钥了!
在Android中使用时 一般都是正常用即可。
需要自己写证书验证过程的场景:
⽤的是⾃签名证书(例如只⽤于内⽹的 https) 证书信息不全,缺乏中间证书机构(可能性不⼤) ⼿机操作系统较旧,没有安装最新加⼊的根证书 TCP/IP模型是实际应用中广泛使用的网络分层架构,它将网络通信分为四个层次:
网络接口层:对应于OSI模型的物理层和数据链路层,负责将数据帧从一个网络节点传输到另一个网络节点。 网络层:与OSI模型的网络层功能相同,负责在不同网络之间进行路由选择和数据包转发。 传输层:与OSI模型的传输层功能相同,提供端到端的可靠数据传输服务。 应用层:对应于OSI模型的会话层、表示层和应用层,为用户提供各种网络应用服务。 网络分层架构的优点包括:
模块化设计:每个层次都有明确的功能和接口,便于设计、实现和维护。 独立性:各层次可以独立发展和更新,互不影响。 易于理解:分层架构使得网络通信的过程更加清晰和易于理解。 灵活性:可以根据需要在不同层次上添加或修改功能。 通过这种分层架构,网络通信变得更加有序和高效,不同层次的技术可以协同工作,为用户提供可靠的网络服务。
网络分层架构 为什么要分层? 从客户端到服务器的各节点
网络不稳定,所以需要分层。
比如客户端往服务端发起请求的过程中,中间某个节点如果损坏,客户端需要知道信息没发过去,再次发起重传。 但是如果很大的数据,就会传很多次,原本50ms的时间,可能需要传2s才能完成。解决:把这个大的数据切成5块,这5块分别来传,先把能传成功的全部发过去,如果检索到某一块没有收到,再把对应的块给传过去,就只需要多发20%,效率比较高。
分层:有分块传输所以需要分层。上层通信协议众多,http, ftp, mqtt等都有这种分块的需求。所以把包的分发这个工作专门抽出来一层。上层不管传输了,他们只需要把所有要传的数据准备好,再丢给下层TCP去处理。
那么有TCP了,为什么还要往下拉一层?
TCP叫传输层,用来传东西,其注重数据完整性。
但是并不是所有数据我们都需要重传,比如CS枪战游戏数据,如果网络卡顿了,这个数据不能再重传了,只需要不断将最新的数据传输过去就行了。这种需求所产生的协议叫UDP,强调传输性能而不是传输的完整性。
这两种协议又都有网络的需求,都需要从一个主机找到另一个主机。
TCP现在也不去传了,只是将数据分块,并全部按顺序的传输,并检测。UDP也一样,只管分块,不用管传输完整性与顺序。
而下一层的IP只管闷头传,负责寻址,找路由,上层有什么东西丢下来就直接传过去。
阶段小结:这三层都是共同的目的,将数据从一个地方传到另一个地方。 分层原因都是网络不稳定 ,如果网络稳定,所有东西都可以一次性到达,那就不需要这么麻烦了。
数据链路层:这层就是实际的网络,以太网,比如网线,WIFI。其为网络提供显示的实质的支持。
另外还有七层网络模型,它把数据链路层分开了,数据链路层和物理层。物理层为网线,交换器。
具体的分层:
Application Layer 应⽤层:HTTP、FTP、DNS Transport Layer 传输层:TCP、UDP Internet Layer ⽹络层:IP Link Layer 数据链路层:以太⽹、Wi-Fi 对于应用层工程师来说,可以只关心这四层模型。
TCP连接 什么叫连接?
TCP是有状态的,他有很多小包需要发送。先建立起第一步通信,来共同确认数据传输包该怎么拼。
连接建立:
连接的关闭:
长连接 为什么需要长连接? 首先了解内网,一个网关,其内部有很多的主机,某个主机需要和外部的主机通信,网关会先开一个端口,走这个端口和外界主机通信。内网的主机所占用的端口实际是网关的端口。例如,我们的手机网络都是运行在运营商的内网里面的。 长连接:网关给内部主机开端口通信,需要耗费资源的。当内部主机一段时间里没有进行数据通信,网关会把这个端口给关闭掉。那么过一会,当外部主机再走这个端口想要通信时,就连不上了,网路就断了。为了突破这个限制,让网关不去主动关掉这个端口,就需要定时地通信一次,这就是心跳,实现长连接的方式。网关发现这个端口一直在用,就不会将这个端口给关掉了。 长连接很复杂,需要了解的东西相当多,实现很难。
登录:身份认证,确认“你是你”,用户“把我的权限授予我自己” 授权:把权限授予用户,可以持有令牌
登录 Cookie和Authorization都是Headers里的内容。
Cookie 起源:购物车,在 NetScape 网景浏览器时期。某电商网站希望有购物车功能,现在的购物车数据是存在服务器的,当时的人希望将购物车数据存在客户端本地。那么即使浏览器开发者与网站开发者的身份,开发这个就非常方便。
流程:服务器希望你记住什么,就把这个发过来,并标记这个是需要保存在本地的。客户端就将这些数据存在本地。浏览器下次访问相关域的时候,客户端就会自动附加这些数据,服务器不需要再次发送。
移动开发中使用cookie非常少了。
服务器需要客户端保存的内容,放在 Set-Cookie headers ⾥返回,客户端会自动保存。 客户端保存的 Cookies ,会在之后的所有请求⾥都携带进 Cookie header ⾥发回给服务器。 客户端保存 Cookie 是按照服务器域名来分类的,例如 shop.com 发回的 Cookie 保存下来以后,在之后向 games.com 的请求中并不会携带。 客户端保存的 Cookie 在超时后会被删除、没有设置超时时间的 Cookie (称作 SessionCookie)在浏览器关闭后就会⾃动删除;另外,服务器也可以主动删除还未过期的客户端Cookies。
作用:一般都是客户端给自己作标记,服务器拿本地的 Cookie 来对比。HTTP是无状态的,使用这个机制可以让服务器标识不同的用户。例如会话管理,登录状态,购物车,用户偏好,分析用户行为。
用户tracking流程图:
XSS(Cross-site scripting) 跨站脚本攻击 如果Cookie里有用户关键信息,比如密码等。那么本地有恶意的JavaScript脚本的话,就可以将这些Cookie发走,窃取用户数据。 应对:在Header里加入HttpOnly关键字。那本地脚本就看不到这个Cookie了。
XSRF 跨站请求伪造 即在⽤户不知情的情况下访问 已经保存了 Cookie 的⽹站,以此来越权操作⽤户账户(例如盗取⽤户资⾦)。应对⽅式主要是 从服务器安全⻆度考虑,就不多说了。
Referer校验
Authoriztion Basic 使用的不多 格式:Authorization: Basic <username:password(Base64ed)> 有安全风险,用户名和密码相当于明文传输,万一被截获。
Bearer “持有者” 格式:Authorization: Bearer token需要找授权方取得
Oauth2 例如:使用github登录稀土掘金,第三方是掘金。即将授权的令牌授予给要用的第三方的网站。 流程:
第三⽅⽹站向授权⽅⽹站申请第三⽅授权合作,拿到 client id 和 client secret ⽤户在使⽤第三⽅⽹站时,点击「通过 XX (如 GitHub) 授权」按钮,第三⽅⽹站将⻚⾯跳转到授权⽅⽹站,并传⼊ client id 作为⾃⼰的身份标识 授权⽅⽹站根据 client id ,将第三⽅⽹站的信息和第三⽅⽹站需要的⽤户权限展示给⽤户,并询问⽤户是否同意授权 ⽤户点击「同意授权」按钮后,授权⽅⽹站将⻚⾯跳转回第三⽅⽹站,并传⼊ Authorization code 作为⽤户认可的凭证。 第三⽅⽹站客户端将 Authorization code(只是表明用户同意授权) 发送回第三方⾃⼰的服务器 第三方网站的服务器将 Authorization code 和⾃⼰的 client secret(第三方向授权方申请时附加的表明自己的身份) ⼀并发送给授权⽅的服务器,说用户已经同意了。注意这个secret是需要绝对安全的。授权⽅服务器在验证通过后,返回 access token给第三方的服务器。OAuth 流程结束。 在上⾯的过程结束之后,第三⽅⽹站的服务器(或者有时客户端也会)就可以使⽤授权的 access token 作为⽤户授权的令牌,向授权⽅⽹站发送请求来获取⽤户信息或操作⽤户账户。但这已经在 OAuth 流程之外。 可以看到,最大的好处就是token是保密的,只在两个服务器方进行交互,保证登录安全。
易混淆:第三方登录 我和掘金之间的登录操作,利用了github登录,那么github属于第三方。
例子:微信登录(第三方登录)
流程:
第三⽅ App 向腾讯申请第三⽅授权合作,拿到 client id 和 client secret 用户在使⽤第三⽅ App 时,点击「通过微信登录」,第三⽅ App 将使⽤微信 SDK 跳转到微信,并传⼊⾃⼰的 client id 作为⾃⼰的身份标识 微信通过和服务器交互,拿到第三⽅ App 的信息,并限制在界⾯中,然后询问⽤户是否同意授权该 App 使⽤微信来登录 ⽤户点击「使⽤微信登录」后,微信和服务器交互将授权信息提交,然后跳转回第三⽅App,并传⼊ Authorization code 作为⽤户认可的凭证 第三⽅ App 调⽤⾃⼰服务器的「微信登录」Api,并传⼊ Authorization code,然后等待服务器的响应。让服务器去和微信的服务器换取token。 服务器在收到登录请求后,拿收到的 Authorization code 去向微信的第三⽅授权接⼝发送请求,将 Authorization code 和⾃⼰的 client secret ⼀起作为参数发送,微信在验证通过后,返回 access token 服务器在收到 access token 后,⽴即拿着 access token 去向微信的⽤户信息接⼝发送请求,微信验证通过后,返回⽤户信息 服务器在收到⽤户信息后,在⾃⼰的数据库中为⽤户创建⼀个账户,并使⽤从微信服务器拿来的⽤户信息填⼊⾃⼰的数据库,以及将⽤户的 ID 和⽤户的微信 ID 做关联 ⽤户创建完成后,服务器向客户端的请求发送响应,传送回刚创建好的⽤户信息 客户端收到服务器响应,⽤户登录成功 与github授权登录没有区别,只是叫法与概念不同。也是微信把自己的token授权给第三方的网站使用。
自己的服务器 使用Bearer token(流程需要加深理解,与OAuth第三方授权的区别)
有的 App 会在 Api 的设计中,将登录和授权设计成类似 OAuth2 的过程,但简化掉Authorization code 概念。即:登录接⼝请求成功时,会返回 access token,然后客户端在之后的请求中,就可以使⽤这个 access token 来当做 bearer token 进⾏⽤户操作了。
就是一种简化版的OAuth授权,直接使用code和自家服务器换取token。
refresh token ⽤法:access token 有失效时间,在它失效后,调⽤ refresh token 接⼝,传⼊ refresh_token 来获取新的 access token。
{
"token_type": "Bearer",
"access_token": "xxxxx",
"refresh_token": "xxxxx",
"expires_time": "xxxxx"
}
⽬的:安全。当 access token 失窃,由于它有失效时间,因此坏⼈只有较短的时间来「做坏事」;同时,由于(在标准的 OAuth2 流程中)refresh token 永远只存在与第三⽅服务的服务器中,因此 refresh token ⼏乎没有失窃的⻛险。
背景 HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
HTTP是一个属于 应用层 的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展。
HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
主要特点 简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。 灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。 无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。 无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。 支持B/S及C/S模式。 HTTP之URL HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息
URL,全称是UniformResourceLocator, 中文叫统一资源定位符,是互联网上用来标识某一处资源的地址。以下面这个URL为例,介绍下普通URL的各部分组成:
http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name
从上面的URL可以看出,一个完整的URL包括以下几部分:
协议部分:该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在”HTTP”后面的“//”为分隔符 域名部分:该URL的域名部分为“www.aspxfans.com”。一个URL中,也可以使用IP地址作为域名使用 端口部分:跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口 虚拟目录部分:从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是“/news/” 文件名部分:从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.asp”。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名 锚部分:从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。锚部分也不是一个URL必须的部分。锚的主要作用是在一个HTML文档中标识出一个特定的位置,这样当用户点击包含这个锚的链接时,浏览器就会直接滚动到文档中对应的位置。 参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为“boardID=5&ID=24618&page=1”。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。 URI和URL的区别 URI,是uniform resource identifier,统一资源标识符,用来唯一的标识一个资源。
Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是一个来URI来定位的。
URI一般由三部组成:
访问资源的命名机制 存放资源的主机名 资源自身的名称,由路径表示,着重强调于资源。 URL是uniform resource locator,统一资源定位器,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何locate这个资源。
URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上,特别是著名的Mosaic。
采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。URL一般由三部组成:
协议(或称为服务方式) 存有该资源的主机IP地址(有时也包括端口号) 主机资源的具体地址。如目录和文件名等 URN,uniform resource name,统一资源命名,是通过名字来标识资源,比如mailto:java-net@java.sun.com
URI是以一种抽象的,高层次概念定义统一资源标识,而URL和URN则是具体的资源标识的方式。
URL和URN都是一种URI。
笼统地说,每个 URL 都是 URI,但不一定每个 URI 都是 URL。这是因为 URI 还包括一个子类,即统一资源名称 (URN),它命名资源但不指定如何定位资源。
上面的 mailto、news 和 isbn URI 都是 URN 的示例。
在Java的URI中,一个URI实例可以代表绝对的,也可以是相对的,只要它符合URI的语法规则。而URL类则不仅符合语义,还包含了定位该资源的信息,因此它不能是相对的。
在Java类库中,URI类不包含任何访问资源的方法,它唯一的作用就是解析。 相反的是,URL类可以打开一个到达资源的流。
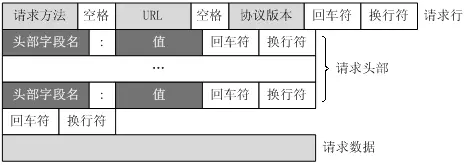
HTTP之请求消息Request 客户端发送一个HTTP请求到服务器的请求消息包括以下格式:
请求行(request line)、请求头部(header)、空行和请求数据 四个部分组成。
请求行以一个方法符号开头,以空格分开,后面跟着请求的URI和协议的版本。 Get请求例子,使用Charles抓取的request:
GET /562f25980001b1b106000338.jpg HTTP/1.1
Host img.mukewang.com
User-Agent Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36
Accept image/webp,image/*,*/*;q=0.8
Referer http://www.imooc.com/
Accept-Encoding gzip, deflate, sdch
Accept-Language zh-CN,zh;q=0.8
第一部分:请求行,用来说明请求类型,要访问的资源以及所使用的HTTP版本. GET说明请求类型为GET, [/562f25980001b1b106000338.jpg] 为要访问的资源,该行的最后一部分说明使用的是HTTP1.1版本。
第二部分:请求头部,紧接着请求行(即第一行)之后的部分,用来说明服务器要使用的附加信息。从第二行起为请求头部,HOST将指出请求的目的地。User-Agent,服务器端和客户端脚本都能访问它,它是浏览器类型检测逻辑的重要基础。该信息由你的浏览器来定义,并且在每个请求中自动发送等等。
第三部分:空行,请求头部后面的空行是必须的。即使第四部分的请求数据为空,也必须有空行。
第四部分:请求数据也叫主体,可以添加任意的其他数据。这个例子的请求数据为空。
POST请求例子,使用Charles抓取的request:
POST / HTTP1.1
Host:www.wrox.com
User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022)
Content-Type:application/x-www-form-urlencoded
Content-Length:40
Connection: Keep-Alive
name=Professional%20Ajax&publisher=Wiley
第一部分:请求行,第一行明了是post请求,以及http1.1版本。 第二部分:请求头部,第二行至第六行。 第三部分:空行,第七行的空行。 第四部分:请求数据,第八行。
请求头 请求头(Request Header)在HTTP通信中扮演着至关重要的角色,它为服务器提供了关于客户端请求的额外信息,帮助服务器更好地理解和处理请求。以下是请求头的一些主要作用:
传递元数据:请求头可以包含关于请求的各种元数据,如请求的方法(GET、POST等)、请求的目标资源(URL)、请求的协议版本(如HTTP/1.1)等。
身份验证:通过包含认证信息(如Authorization头部),客户端可以向服务器证明自己的身份,以便访问受保护的资源。
内容协商:客户端可以通过Accept、Accept-Encoding、Accept-Language等头部字段告知服务器自己能够接受的内容类型、编码方式和语言,服务器可以根据这些信息返回最合适的响应内容。
缓存控制:客户端可以通过Cache-Control、If-Modified-Since、If-None-Match等头部字段来控制缓存行为,减少不必要的网络传输。
会话管理:通过Cookie头部,客户端可以向服务器发送之前存储的会话信息,以便服务器识别用户并维护会话状态。
代理信息:请求头中可以包含关于客户端所使用的代理服务器的信息,如Via头部。
内容长度:Content-Length头部字段用于指示请求体的长度,帮助服务器正确处理请求。
内容类型:Content-Type头部字段用于指定请求体的媒体类型,如application/json、application/x-www-form-urlencoded等。
在移动端开发中,以下是一些最常用的请求头及其使用方法举例:
User-Agent:用于标识客户端的类型和版本,服务器可以根据这个信息返回适合移动端设备的内容。
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 14_4 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Mobile/15E148 Safari/604.1
Accept:用于指定客户端能够接受的内容类型。
Accept: application/json, text/plain, */*
Authorization:用于传递认证信息,通常用于访问需要身份验证的API。
Authorization: Bearer <token>
Content-Type:用于指定请求体的媒体类型。
Content-Type: application/json
Accept-Language:用于指定客户端能够接受的语言。
Accept-Language: zh-CN,zh;q=0.9
Cache-Control:用于控制缓存行为。
Cookie:用于发送之前存储的会话信息。
Cookie: session_id=abc123; user_id=12345
If-Modified-Since:用于检查资源是否在指定时间之后被修改过。
If-Modified-Since: Mon, 26 Jul 2021 12:00:00 GMT
这些请求头在移动端开发中经常被使用,它们帮助客户端和服务器之间进行有效的通信,确保请求和响应的正确处理。
请求数据 HTTP请求数据(也称为请求体或请求正文)在客户端向服务器发送请求时扮演着重要的角色。它包含了客户端希望发送给服务器的额外信息,这些信息通常是在请求方法(如POST、PUT等)中需要传递的数据。以下是HTTP请求数据的主要作用:
传递数据:请求数据允许客户端向服务器发送数据,这些数据可以是表单提交的数据、文件上传的数据、API调用的参数等。
更新资源:在使用PUT或PATCH请求方法时,请求数据用于更新服务器上的资源。
创建资源:在使用POST请求方法时,请求数据用于创建新的资源。
在移动端开发中,最常用的请求数据格式和类型包括:
JSON:JavaScript Object Notation,是一种轻量级的数据交换格式,易于阅读和编写,同时也易于机器解析和生成。它是移动端开发中最常用的数据格式之一,特别是在与RESTful API进行通信时。 {
"username" : "john.doe" ,
"password" : "secret123"
}
Form Data:表单数据是一种常见的请求数据格式,通常用于提交表单数据。在移动端开发中,表单数据通常用于用户登录、注册、提交表单等场景。 username=john.doe&password=secret123
Multipart Form Data:多部分表单数据是一种特殊的表单数据格式,用于上传文件。在移动端开发中,多部分表单数据通常用于上传图片、视频等文件。 Content-Disposition: form-data; name="file"; filename="example.jpg"
Content-Type: image/jpeg
<binary data>
XML:可扩展标记语言,是一种用于标记电子文件使其具有结构性的标记语言。虽然JSON在移动端开发中更为流行,但XML仍然在某些场景下被使用,特别是在与一些传统的Web服务进行通信时。 <user>
<username> john.doe</username>
<password> secret123</password>
</user>
Text:纯文本格式,通常用于发送简单的文本信息,如日志、错误消息等。
This is a sample text message.
这些请求数据格式在移动端开发中经常被使用,具体使用哪种格式取决于服务器端的API设计和客户端的需求。
HTTP之响应消息Response 一般情况下,服务器接收并处理客户端发过来的请求后会返回一个HTTP的响应消息。
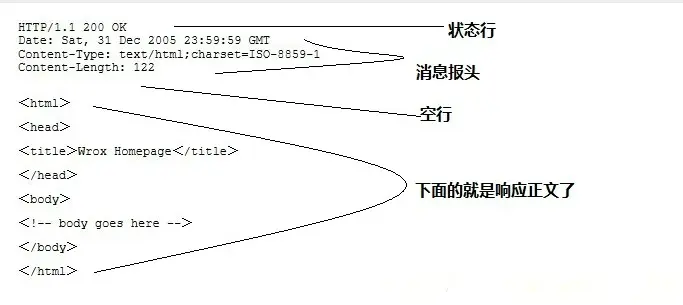
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
例子
HTTP / 1.1 200 OK
Date : Fri, 22 May 2009 06:07:21 GMT
Content-Type : text/html; charset=UTF-8
<html>
<head></head>
<body>
<!--body goes here-->
</body>
</html>
第一部分:状态行,由HTTP协议版本号,状态码,状态消息 三部分组成。第一行为状态行,(HTTP/1.1)表明HTTP版本为1.1版本,状态码为200,状态消息为(ok) 第二部分:消息报头,用来说明客户端要使用的一些附加信息。第二行和第三行为消息报头,Date:生成响应的日期和时间;Content-Type:指定了MIME类型的HTML(text/html),编码类型是UTF-8 第三部分:空行,消息报头后面的空行是必须的。 第四部分:响应正文,服务器返回给客户端的文本信息。空行后面的html部分为响应正文。 HTTP之状态码 状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx:指示信息–表示请求已接收,继续处理 2xx:成功–表示请求已被成功接收、理解、接受 3xx:重定向–要完成请求必须进行更进一步的操作 4xx:客户端错误–请求有语法错误或请求无法实现 5xx:服务器端错误–服务器未能实现合法的请求 常见状态码:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
消息报头 HTTP响应中的消息报头(Response Headers)用于向客户端提供关于响应的附加信息。这些信息可以帮助客户端更好地理解和处理服务器返回的响应内容。消息报头通常包含了以下几种类型的信息。
内容类型和编码:例如Content-Type和Content-Encoding,用于指定响应体的媒体类型和编码方式。 缓存控制:例如Cache-Control、Expires和ETag,用于控制客户端和代理服务器如何缓存响应。 重定向和跳转:例如Location,用于指示客户端应该重定向到的新URL。 认证和授权:例如WWW-Authenticate和Set-Cookie,用于要求客户端进行身份验证或设置会话信息。 内容长度和范围:例如Content-Length和Content-Range,用于指示响应体的长度和范围。 跨域资源共享:例如Access-Control-Allow-Origin和Access-Control-Allow-Methods,用于控制跨域请求的访问权限。 常见的响应数据 HTTP响应中的响应正文(Response Body)包含了服务器返回给客户端的实际数据。这些数据可以是HTML页面、JSON对象、图像、音频、视频或任何其他类型的文件。响应正文的主要作用是向客户端提供请求的资源或数据。
在移动端开发中,最常见的HTTP响应正文类型包括:
HTML页面:用于在移动浏览器中显示网页内容。 <html>
<head>
<title> Example Page</title>
</head>
<body>
<h1> Welcome to Example Page</h1>
<p> This is an example HTML page.</p>
</body>
</html>
JSON数据:用于在移动应用中与后端API进行数据交互。 {
"message" : "Hello, World!" ,
"status" : "success"
}
图像文件:如JPEG、PNG或GIF格式的图片。 Content-Type: image/jpeg
<binary data>
音频文件:如MP3、AAC或WAV格式的音频。 Content-Type: audio/mpeg
<binary data>
视频文件:如MP4、WebM或AVI格式的视频。 Content-Type: video/mp4
<binary data>
文件下载:用于从服务器下载文件,如PDF、Word文档等。 Content-Disposition: attachment; filename="example.pdf"
Content-Type: application/pdf
<binary data>
纯文本文件:用于返回简单的文本信息,如日志、错误消息等。 This is a sample text message.
这些响应正文类型在移动端开发中经常被使用,具体使用哪种类型取决于客户端的请求和服务器的响应。
HTTP请求方法 根据HTTP标准,HTTP请求可以使用多种请求方法。
HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。 HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
GET 请求指定的页面信息,并返回实体主体。
HEAD 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
PUT 从客户端向服务器传送的数据取代指定的文档的内容。
DELETE 请求服务器删除指定的页面。
CONNECT HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
OPTIONS 允许客户端查看服务器的性能。
TRACE 回显服务器收到的请求,主要用于测试或诊断。
HTTP工作原理 HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
以下是 HTTP 请求/响应的步骤:
1、客户端连接到Web服务器 一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.oakcms.cn。
2、发送HTTP请求 通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
3、服务器接受请求并返回HTTP响应 Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
4、释放连接TCP连接 若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
5、客户端浏览器解析HTML内容 客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
例如:在浏览器地址栏键入URL,按下回车之后会经历以下流程:
1、浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
2、解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立TCP连接;
3、浏览器发出读取文件(URL 中域名后面部分对应的文件)的HTTP 请求,该请求报文作为 TCP 三次握手的第三个报文的数据发送给服务器;
4、服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
5、释放 TCP连接;
6、浏览器将该 html 文本并显示内容;
GET和POST请求的区别 GET请求
GET /books/?sex=man&name=Professional HTTP/1.1
Host: www.wrox.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Connection: Keep-Alive
注意最后一行是空行
POST请求
POST / HTTP/1.1
Host: www.wrox.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 40
Connection: Keep-Alive
name=Professional%20Ajax&publisher=Wiley
差异一 地址栏 GET提交,请求的数据会附在URL之后(就是把数据放置在HTTP协议头中),以?分割URL和传输数据,多个参数用&连接;例如: login.action?name=hyddd&password=idontknow&verify=%E4%BD%A0 %E5%A5%BD 。如果数据是英文字母/数字,原样发送,如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用BASE64加密,得出如: %E4%BD%A0%E5%A5%BD,其中%XX中的XX为该符号以16进制表示的ASCII。
POST提交:把提交的数据放置在是HTTP包的包体中。上文示例中红色字体标明的就是实际的传输数据
因此,GET提交的数据会在地址栏中显示出来,而POST提交,地址栏不会改变
差异二 数据长度限制 传输数据的大小:首先声明:HTTP协议没有对传输的数据大小进行限制,HTTP协议规范也没有对URL长度进行限制。
而在实际开发中存在的限制主要有:
GET:特定浏览器和服务器对URL长度有限制,例如 IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系统的支持。
因此对于GET提交时,传输数据就会受到URL长度的限制。
POST:由于不是通过URL传值,理论上数据不受限。但实际各个WEB服务器会规定对post提交数据大小进行限制,Apache、IIS6都有各自的配置。
差异三 安全性 POST的安全性要比GET的安全性高。比如:通过GET提交数据,用户名和密码将明文出现在URL上,因为(1)登录页面有可能被浏览器缓存;(2)其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了,除此之外,使用GET提交数据还可能会造成Cross-site request forgery攻击。
4、Http get,post,soap协议都是在http上运行的
(1)get:请求参数是作为一个key/value对的序列(查询字符串)附加到URL上的查询字符串的长度受到web浏览器和web服务器的限制(如IE最多支持2048个字符),不适合传输大型数据集同时,它很不安全。
(2)post:请求参数是在http标题的一个不同部分(名为entity body)传输的,这一部分用来传输表单信息,因此必须将Content-type设置为:application/x-www-form-urlencoded。post设计用来支持web窗体上的用户字段,其参数也是作为key/value对传输。但是:它不支持复杂数据类型,因为post没有定义传输数据结构的语义和规则。
(3)soap:是http post的一个专用版本,遵循一种特殊的xml消息格式 Content-type设置为: text/xml 任何数据都可以xml化。
Http协议定义了很多与服务器交互的方法,最基本的有4种,分别是GET,POST,PUT,DELETE. 一个URL地址用于描述一个网络上的资源,而HTTP中的GET, POST, PUT, DELETE就对应着对这个资源的查,改,增,删4个操作。 我们最常见的就是GET和POST了。GET一般用于获取/查询资源信息,而POST一般用于更新资源信息.
总结 GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的Body中.
GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值。
GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码。
学习文章基于豪哥的教程,源地址:
Android Framework
源码分区 Android 常用的四个分区:
System 分区 Vender 分区 Odm 分区 Product 分区 ARM + Android 这个行业,一个简化的普遍流程:
Google 开发迭代 AOSP + Kernel 芯片厂商,针对自己的芯片特点,移植 AOSP 和 Kernel,使其可以在自己的芯片上跑起来。 方案厂商(很多芯片厂商也扮演了方案厂商的角色),设计电路板,给芯片添加外设,在芯片厂商源码基础上开发外设相关软件,主要是驱动和 hal,改进性能和稳定性。 产品厂商,主要是系统软件开发,UI 定制以及硬件上的定制(添加自己的外设),改进性能和稳定性. Google 开发的通用 Android 系统组件编译后会被存放到 System 分区,原则上不同厂商、不同型号的设备都通用。
芯片厂商和方案厂商针对硬件相关的平台通用的可执行程序、库、系统服务和 app 等一般放到 Vender 分区。(开发的驱动程序是放在 boot 分区的 kernel 部分)
到了产品厂商这里,情况稍微复杂一点,通常针对同一套软硬件平台,可能会开发多个产品。比如:小米 12s,小米12s pro,小米12s ultra 均源于骁龙8+平台。
每一个产品,我们称之为一个 Variant(变体)。
通常情况下,做产品的厂商在同一个硬件平台上针对不同的产品会从硬件和软件两个维度来做定制。
硬件上,产品 A 可能用的是京东方的屏,产品 B 可能用的是三星的屏;差异硬件相关的软件部分都会放在 Odm 分区。这样,产品 A 和产品 B 之间 Odm 以外的分区都是一样的,便于统一维护与升级。(硬件相关的软件共用部分放在 vendor 分区)
软件上,产品 A 可能是带广告的版本,产品 B 可能是不带广告的版本。这些有差异的软件部分都放在 Product 分区,这样产品 A 和产品 B 之间 Product 以外的分区都是一样的,便于统一维护与升级。(软件共用部分都放在 System分区)
总结一下,不同产品之间公共的部分放在 System 和 Vender 分区,差异的部分放在 Odm 和 Product 分区。
Product配置 在编译之前执行的 lunch 命令,所展示的那些列表,就是一个个不同的product。可以看到后缀大致有user,userdebug,eng三种。
区别如下:
用户模式 user
仅安装标签为 user 的模块 设定属性 ro.secure=1,打开安全检查功能 设定属性 ro.debuggable=0,关闭应用调试功能 默认关闭 adb 功能 打开 Proguard 混淆器 打开 DEXPREOPT 预先编译优化
用户调试模式 userdebug
安装标签为 user、debug 的模块 设定属性 ro.secure=1,打开安全检查功能 设定属性 ro.debuggable=1,启用应用调试功能 默认打开 adb 功能 打开 Proguard 混淆器 打开 DEXPREOPT 预先编译优化
工程模式 eng
安装标签为 user、debug、eng 的模块 设定属性 ro.secure=0,关闭安全检查功能 设定属性 ro.debuggable=1,启用应用调试功能 设定属性 ro.kernel.android.checkjni=1,启用 JNI 调用检查 默认打开 adb 功能 关闭 Proguard 混淆器 关闭 DEXPREOPT 预先编译优化
由于我使用的是谷歌官方的Pixel 5设备,所以所需的product已经在源码里面配置完毕了。
此设备配置文件在这个目录:
device/google_car/redfin_car
主要集成相关的配置文件:
#
# Copyright 2020 The Android Open Source Project
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
$(call inherit-product, device/google_car/common/pre_google_car.mk)
$(call inherit-product, device/google_car/redfin_car/device-redfin-car.mk)
$(call inherit-product-if-exists, vendor/google_devices/redfin/proprietary/device-vendor.mk)
$(call inherit-product-if-exists, vendor/google_devices/redfin/prebuilts/device-vendor-redfin.mk)
$(call inherit-product, device/google_car/common/post_google_car.mk)
PRODUCT_MANUFACTURER := Google
PRODUCT_BRAND := Android
PRODUCT_NAME := aosp_redfin_car
PRODUCT_DEVICE := redfin
PRODUCT_MODEL := Stephen_Car001
PRODUCT_PACKAGES += \
RedfinDemo \
hello \
hellojava \
Kugou \
Sougou \
BaiduMap \
Term \
Gemini \
Google \
busybox \
SystemAppDemo \
helloseandroid \
initscript
PRODUCT_BROKEN_VERIFY_USES_LIBRARIES := true
PRODUCT_PROPERTY_OVERRIDES := \
persist.sys.language=zh \
persist.sys.country=CN \
persist.sys.timezone=Asia/Shanghai
BOARD_SEPOLICY_DIRS += \
device/google_car/redfin_car/sepolicy
要自己定制,可以直接基于Google的源码改。
新定义一个product 如果是使用模拟器,直接跑X86_64的环境的话。就需要自己重新定义product。
针对我们选择的 aosp_x86_64-eng,我们主要关注以下几个文件:
/board/generic_x86_64/BoardConfig.mk : 用于硬件相关配置
/product/AndroidProducts.mk 和 /product/aosp_x86_64.mk:用于配置 Product
BoardConfig.mk 用于定义和硬件相关的底层特性和变量,比如当前源码支持的 cpu 位数(64/32位),bootloader 和 kernel, 是否支持摄像头,GPS导航等一些板级特性。主要和硬件相关,有一个基本的了解即可。一般很少改动。 AndroidProducts.mk 定义我们执行 lunch 命令时,打印的列表以及每个选项对应的配置文件 PRODUCT_MAKEFILES 用于引入产品的配置文件。 COMMON_LUNCH_CHOICES 用于添加 lunch 时的选项,选项的名字由两部分过程 产品名 + 构建模式: 产品名就是 PRODUCT_MAKEFILES 中引入的产品配置文件名去掉 .mk 后缀,例如 aosp_x86_64 构建模式有三种:用户模式 user、用户调试模式 userdebug 和工程模式 eng。在上面已经展示了它们的区别。 aosp_x86_64.mk:这个文件就是模拟器产品配置的主基地。 PRODUCT_USE_DYNAMIC_PARTITIONS := true
# The system image of aosp_x86_64-userdebug is a GSI for the devices with:
# - x86 64 bits user space
# - 64 bits binder interface
# - system-as-root
# - VNDK enforcement
# - compatible property override enabled
# This is a build configuration for a full-featured build of the
# Open-Source part of the tree. It's geared toward a US-centric
# build quite specifically for the emulator, and might not be
# entirely appropriate to inherit from for on-device configurations.
# GSI for system/product
$(call inherit-product, $(SRC_TARGET_DIR)/product/core_64_bit.mk)
$(call inherit-product, $(SRC_TARGET_DIR)/product/gsi_common.mk)
# Emulator for vendor
$(call inherit-product-if-exists, device/generic/goldfish/x86_64-vendor.mk)
$(call inherit-product, $(SRC_TARGET_DIR)/product/emulator_vendor.mk)
$(call inherit-product, $(SRC_TARGET_DIR)/board/generic_x86_64/device.mk)
# Enable mainline checking for excat this product name
ifeq (aosp_x86_64,$(TARGET_PRODUCT))
PRODUCT_ENFORCE_ARTIFACT_PATH_REQUIREMENTS := relaxed
endif
PRODUCT_ARTIFACT_PATH_REQUIREMENT_WHITELIST += \
root/init.zygote32_64.rc \
root/init.zygote64_32.rc \
# Copy different zygote settings for vendor.img to select by setting property
# ro.zygote=zygote64_32 or ro.zygote=zygote32_64:
# 1. 64-bit primary, 32-bit secondary OR
# 2. 32-bit primary, 64-bit secondary
# init.zygote64_32.rc is in the core_64_bit.mk below
PRODUCT_COPY_FILES += \
system/core/rootdir/init.zygote32_64.rc:root/init.zygote32_64.rc
# Product 基本信息
PRODUCT_NAME := aosp_x86_64
PRODUCT_DEVICE := generic_x86_64
PRODUCT_BRAND := Android
PRODUCT_MODEL := AOSP on x86_64
inherit-product 函数表示继承另外一个文件
$(call inherit-product, $(SRC_TARGET_DIR)/product/emulator_vendor.mk)
$(call inherit-product-if-exists, device/generic/goldfish/x86_64-vendor.mk)
在 Makefile 中可使用 “-include” 来代替 “include”,来忽略由于包含文件不存在或者无法创建时的错误提示(“-”的意思是告诉make,忽略此操作的错误。make继续执行),如果不加-,当 include 的文件出错或者不存在的时候, make 会报错并退出。
-include $(TARGET_DEVICE_DIR)/AndroidBoard.mk
include 和 inherit-product 的区别:
假设 PRODUCT_VAR := a 在 A.mk 中, PRODUCT_VAR := b 在 B.mk 中。
如果你在 A.mk 中 include B.mk,你最终会得到 PRODUCT_VAR := b。
但是如果你在 A.mk inherit-product B.mk,你会得到 PRODUCT_VAR := a b。
并且 inherit-product 确保您不会两次包含同一个 makefile 。
添加product 在device目录下新建一个产品名:
Jelly/
└── Rice14
├── AndroidProducts.mk
├── BoardConfig.mk
└── Rice14.mk
BoardConfig.mk 包含了硬件芯片架构配置,分区大小配置等信息这里我们直接使用 aosp_x86_64 的 BoardConfig.mk 就行。BoardConfig.mk 拷贝自 build/target/board/generic_x86_64/BoardConfig.mk
Rice14.mk 拷贝自 build/target/product/aosp_x86_64.mk
其中的 if 语句需要注释掉,同时需要修改最后四行:
PRODUCT_USE_DYNAMIC_PARTITIONS := true
# The system image of aosp_x86_64-userdebug is a GSI for the devices with:
# - x86 64 bits user space
# - 64 bits binder interface
# - system-as-root
# - VNDK enforcement
# - compatible property override enabled
# This is a build configuration for a full-featured build of the
# Open-Source part of the tree. It's geared toward a US-centric
# build quite specifically for the emulator, and might not be
# entirely appropriate to inherit from for on-device configurations.
# GSI for system/product
$(call inherit-product, $(SRC_TARGET_DIR)/product/core_64_bit.mk)
$(call inherit-product, $(SRC_TARGET_DIR)/product/gsi_common.mk)
# Emulator for vendor
$(call inherit-product-if-exists, device/generic/goldfish/x86_64-vendor.mk)
$(call inherit-product, $(SRC_TARGET_DIR)/product/emulator_vendor.mk)
$(call inherit-product, $(SRC_TARGET_DIR)/board/generic_x86_64/device.mk)
# Enable mainline checking for excat this product name
#ifeq (aosp_x86_64,$(TARGET_PRODUCT))
PRODUCT_ENFORCE_ARTIFACT_PATH_REQUIREMENTS := relaxed
#endif
PRODUCT_ARTIFACT_PATH_REQUIREMENT_WHITELIST += \
root/init.zygote32_64.rc \
root/init.zygote64_32.rc \
# Copy different zygote settings for vendor.img to select by setting property
# ro.zygote=zygote64_32 or ro.zygote=zygote32_64:
# 1. 64-bit primary, 32-bit secondary OR
# 2. 32-bit primary, 64-bit secondary
# init.zygote64_32.rc is in the core_64_bit.mk below
PRODUCT_COPY_FILES += \
system/core/rootdir/init.zygote32_64.rc:root/init.zygote32_64.rc
# Overrides
PRODUCT_BRAND := Jelly
PRODUCT_NAME := Rice14
PRODUCT_DEVICE := Rice14
PRODUCT_MODEL := Android SDK built for x86_64 Rice14
AndroidProducts.mk 内容如下:
PRODUCT_MAKEFILES := \
$(LOCAL_DIR)/Rice14.mk
COMMON_LUNCH_CHOICES := \
Rice14-eng \
Rice14-userdebug \
Rice14-user
验证:
source build/envsetup.sh
lunch Rice14-eng
make -j16
emulator
集成脚本编写 mk文件 以下是一个简单的示例,展示了如何编写一个基本的Android.mk文件来编译一个C或C++库:
# 定义本地路径
LOCAL_PATH := $(call my-dir)
# 清除变量
include $(CLEAR_VARS)
# 定义模块名称
LOCAL_MODULE := mylibrary
# 定义源文件
LOCAL_SRC_FILES := \
file1.cpp \
file2.cpp \
file3.cpp
# 定义编译标志
LOCAL_CFLAGS := -Wall -Werror
# 定义链接库
LOCAL_LDLIBS := -llog
# 构建静态库
include $(BUILD_STATIC_LIBRARY)
LOCAL_PATH: 定义了当前Android.mk文件所在的目录。 LOCAL_PATH := $(call my-dir)
CLEAR_VARS: 清除所有之前定义的变量,以确保每个模块的编译都是独立的。 LOCAL_MODULE: 定义了要生成的模块名称。 LOCAL_SRC_FILES: 列出了所有要编译的源文件。 LOCAL_SRC_FILES := file1.c file2.c
LOCAL_CFLAGS: 定义了编译时的标志,如警告和错误处理。 LOCAL_CFLAGS := -Wall -Werror
LOCAL_LDLIBS: 定义了链接时需要的库。 LOCAL_C_INCLUDES:指定头文件目录。 LOCAL_C_INCLUDES := $(LOCAL_PATH)/include
include $(BUILD_STATIC_LIBRARY)
include:包含其他 Makefile 文件。 include $(LOCAL_PATH)/../SomeOther.mk
LOCAL_C_INCLUDES:指定头文件目录。 LOCAL_C_INCLUDES := $(LOCAL_PATH)/include
LOCAL_SHARED_LIBRARIES 和 LOCAL_STATIC_LIBRARIES:指定依赖的共享库或静态库。 LOCAL_SHARED_LIBRARIES := libutils libcutils
LOCAL_STATIC_LIBRARIES := libmylib
LOCAL_PRELINK_MODULE:指定模块是否需要预链接。 LOCAL_PRELINK_MODULE := false
LOCAL_PACKAGE_NAME:定义 APK 包的名称。 LOCAL_PACKAGE_NAME := MyApp
LOCAL_JAVA_LIBRARIES:指定依赖的 Java 库。 LOCAL_JAVA_LIBRARIES := android-support-v4
bp文件 Android.bp 文件使用类似 JSON 的语法,但有一些特定的扩展。以下是一些基本的语法规则:
模块定义:使用 module 关键字定义一个模块,后面跟着模块类型(如 cc_binary、java_library 等)和模块的属性。
属性赋值:属性使用键值对的形式,键和值之间用冒号 : 分隔。值可以是字符串、列表或嵌套的对象。
列表:列表使用方括号 [] 表示,列表中的元素用逗号 , 分隔。
嵌套对象:嵌套对象使用花括号 {} 表示,嵌套对象中的属性也使用键值对的形式。
示例: 以下是一个简单的 Android.bp 文件示例,定义了一个 C++ 可执行文件:
cc_binary {
name: "hello",
srcs: ["hello.cpp"],
cflags: ["-Werror"],
}
cc_binary:表示这是一个 C++ 可执行文件模块。 name:指定模块的名称,这里是 “hello”。 srcs:指定源文件列表,这里只有一个源文件 “hello.cpp”。 cflags:指定编译标志,这里是 “ -Werror”,表示将所有警告视为错误。 常见模块类型 cc_binary:C++ 可执行文件。 cc_library:C++ 库。 java_library:Java 库。 java_binary:Java 可执行文件。 android_app:Android 应用程序。
模块属性 不同类型的模块有不同的属性,但一些常见的属性包括:
name:模块的名称。 srcs:源文件列表。 cflags:编译标志。 ldflags:链接标志。 shared_libs:依赖的共享库列表。 static_libs:依赖的静态库列表。
系统签名制作 如果系统供应商和app是不同的开发人员,又想在系统app的上下文中进行应用的开发,就需要制作一系统签名文件,提供给app开发人员,这样app就可以在系统的环境下进行开发和调试了。
生成系统签名需要java的openssl工具,可以使用apt工具安装。
首先切到~/aaos/build/target/product/security目录下,应有如下文件:
stephen@CODE01:~/aaos/build/target/product/security$ ls
Android.bp fsverity-release.x509.der platform.jks shared.pk8 verity.x509.pem
Android.mk media.pk8 platform.p12 shared.x509.pem verity_key
README media.x509.pem platform.pem testkey.pk8
cts_uicc_2021.pk8 networkstack.pk8 platform.pk8 testkey.x509.pem
cts_uicc_2021.x509.pem networkstack.x509.pem platform.x509.pem verity.pk8
执行命令:
第一,生成platform.pem文件
openssl pkcs8 -inform DER -nocrypt -in platform.pk8 -out platform.pem
第二,将在目录下生成platform.p12文件。
其中,pass后的字段为签名密码password,name后字段为Keyalias,根据自己喜好设置。
openssl pkcs12 -export -in platform.x509.pem -out platform.p12 -inkey platform.pem -password pass:stephen -name stephen
第三,就是生成jks签名文件了。
其中-deststorepass后也会用到上一步设置的password字段。
keytool -importkeystore -deststorepass stephen -destkeystore platform.jks -srckeystore platform.p12 -srcstoretype PKCS12 -srcstorepass stephen
生成的platform.jks就是我们需要的系统签名了。
将这个签名文件部署到我们应用文件夹里,并在app应用级的gradle里进行配置:
release {
storeFile file('../platform.jks')
storePassword 'stephen'
keyAlias 'stephen'
keyPassword 'stephen'
}
之后在AndroidManifest文件里,设置android:sharedUserId="android.uid.system"和系统进程共享userid,就可以获取到系统权限了。
集成C程序 源码集成 在product的目录下,新建一个hello文件夹,用来放置源代码文件和编译脚本文件。
~/aaos/device/google_car/redfin_car/hello
# Android.bp
cc_binary{
name:"hello",
srcs:["hello.cpp"],
cflags:["-Werrors"],
}
hello . cpp
#include <cstdio>
int main (){
printf ( "hello world! \n " );
return 0 ;
}
最后在aosp_redfin_car.mk里面添加:
PRODUCT_PACKAGES += \
RedfinDemo \
···
hello \
集成C可执行文件 busybox介绍: busybox 是一个类 Unix 操作系统的工具箱,它提供了许多常用的命令,例如 ls、cp、rm 等。
一样的,提前新建一个prebuilt文件夹,用来放置可执行文件。
# Android.bp
cc_prebuilt_binary {
name: "busybox",
srcs: ["busybox-armv8l"],
product_specific: true,
}
第二个就是busybox的可执行文件了,busybox-armv8l
同样需要在aosp_redfin_car.mk里面加入编译的包。
集成Java程序 新建一个helloJava的文件夹。
# Android.bp
java_library {
name: "hellojava",
installable: true,
product_specific: true,
srcs: ["**/*.java"],
sdk_version: "current"
}
java文件放置在包里面,目录结构为:
helloJava/com/stephen/main/HelloJava.java
package com.stephen.main ;
public class HelloJava
{
public static void main ( String [] args )
{
System . out . println ( "Hello Java" );
}
}
apk的方式集成系统app apk文件形式集成 RedfinDemo是第一个项目,里面是一些调试使用的功能,版本信息罗列,app管理等。
# Amdroid.mk
LOCAL_PATH:= $(call my-dir)
include $(CLEAR_VARS)
LOCAL_MODULE := RedfinDemo
LOCAL_MODULE_CLASS := APPS
LOCAL_MODULE_TAGS := optional
LOCAL_BUILT_MODULE_STEM := package.apk
LOCAL_MODULE_SUFFIX := $(COMMON_ANDROID_PACKAGE_SUFFIX)
LOCAL_CERTIFICATE := PRESIGNED
LOCAL_PRIVILEGED_MODULE := true
LOCAL_VENDOR_MODULE := false
LOCAL_SRC_FILES := RedfinDemo.apk
LOCAL_OVERRIDES_PACKAGES := \
Calendar \
CalendarProvider \
Email \
Exchange2 \
Gallery2 \
HoloSpiralWallpaper \
HTMLViewer \
SharedStorageBackup \
SoundRecorder \
TelephonyProvider \
VideoEditor \
VoiceDialer \
VoicePlus \
Camera \
Clock \
Contacts \
include $(BUILD_PREBUILT)
LOCAL_OVERRIDES_PACKAGES 是一个列表,其中包含了要覆盖的系统应用程序的包名。当 RedfinDemo.apk 安装时,它会覆盖这些系统应用程序。
同样,需要在aosp_redfin_car.mk里面加入编译的包。
PARODUCT_PACKAGES += \
RedfinDemo \
···
源码方式集成系统app 首先,我们敲定包名为package="com.example.systemappdemo"
在product目录下新建一个SystemAppDemo文件夹,用来放置源码。
定义Android.bp脚本:
android_app {
name: "SystemAppDemo",
srcs: ["src/**/*.java"],
resource_dirs: ["res"],
manifest: "AndroidManifest.xml",
platform_apis: true,
privileged: true,
sdk_version: "",
//签名证书
certificate: "platform",
//依赖
static_libs: ["androidx.appcompat_appcompat",
"com.google.android.material_material",
"androidx-constraintlayout_constraintlayout"],
}
借助Android Studio,新建一个空项目,注意新建VIEW架构而不是Compose的。然后进行文件的复制。
将res文件夹完全复制到这个目录下 然后将AndroidManifest.xml文件复制到这个目录下。 最后将MainActivity.java文件,复制到: SystemAppDemo/src/com/example/systemappdemo/MainActivity.java
引入其他的库 当我们的系统 App 需要引入一个库的时候,通常会在 prebuilds 目录下查找:
androidx 相关库引入,先在 prebuilts/sdk/current/androidx 下寻找配置好的 bp 文件 其他库引入,先在 prebuilts/tools/common/m2 下寻找寻找配置好的 bp 文件 都没有,就得自己引入了 以recyclerView为例,在Android.bp文件中添加现成的源码:
android_library_import {
name: "androidx.recyclerview_recyclerview-nodeps",
aars: ["m2repository/androidx/recyclerview/recyclerview/1.1.0-alpha07/recyclerview-1.1.0-alpha07.aar"],
sdk_version: "current",
min_sdk_version: "14",
static_libs: [
"androidx.annotation_annotation",
"androidx.collection_collection",
"androidx.core_core",
"androidx.customview_customview",
],
}
三方app集成 有时候需要集成一些第三方的app,比如国内的输入法,影音媒体等软件。
拿到第三方的apk之后,直接在product目录下建立对应的目录,将apk放进去,然后配置mk文件,最后在aosp_redfin_car.mk里面加入编译的包。
注意大多数app都有专门的动态库文件,需要在编译时提取出来编译对应平台的so库。
以百度地图为例:
# Android.mk
LOCAL_PATH := $(call my-dir)
APK_NAME_FULL :=$(shell cd $(LOCAL_PATH); ls -A | grep apk)
APK_NAME :=$(shell echo $(APK_NAME_FULL) | sed 's/.apk//g')
$(warning --------------fullName=$(APK_NAME_FULL)---------------------name=$(APK_NAME))
define get-all-libraries-module-name-in-subdirs
$(sort $(shell cd $(LOCAL_PATH) ; rm -rf lib >/dev/null ; unzip $(APK_NAME_FULL) 'lib/*.so' -d . >/dev/null ; find -L $(1) -name "*.so"))
endef
ALL_LIBRARIES_MODULE_NAME := $(call get-all-libraries-module-name-in-subdirs, lib/arm64-v8a)
$(warning ALL_LIBRARIES_MODULE_NAME:--- $(ALL_LIBRARIES_MODULE_NAME) )
#integrate the apk
include $(CLEAR_VARS)
LOCAL_MODULE := BaiduMap
LOCAL_MODULE_TAGS := optional
LOCAL_MODULE_CLASS := APPS
LOCAL_CERTIFICATE := PRESIGNED
LOCAL_MODULE_SUFFIX := .apk
LOCAL_SRC_FILES := $(APK_NAME_FULL)
LOCAL_PRIVILEGED_MODULE := true
LOCAL_VENDOR_MODULE := false
LOCAL_MODULE_PATH := $(TARGET_OUT_SYSTEM_APPS)
LOCAL_PREBUILT_JNI_LIBS := $(ALL_LIBRARIES_MODULE_NAME)
include $(BUILD_PREBUILT)
背景 学习C++之余,想把原生AOSP的开机动画给更新替换下,换换口味。
我们都知道,AOSP的默认开机动画是一个“ANDROID”的字样,配合一个渐变的底色动画。定制一个自己的开机动画,对于手机厂商来说,有利于宣传品牌,彰显企业文化。
像国内广为人知的定制系统,比如MIUI,ColorOS,FlymeOS等,都是没有直接使用默认动画的,定制了一套他们自己厂商的开机动画。而考虑到大厂都是人力充足,设计师,动效师,应有尽有。
那像我这自己在下面玩玩源码的,没有设计师帮忙,该怎么搞一套看得过去的定制化的开机动画呢?
开始制作 从压缩包制作倒推流程 首先经过调研了解到,我们如果想要自己定制Android的开机动画,需要准备一个名为bootanimation.zip的压缩包,去替换系统默认的动画。
那压缩包里放什么文件呢?
zip包里面的文件格式一般比较固定:
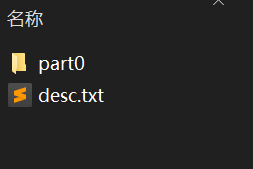
disc.txt,用来描述帧动画的播放策略和显示大小。 若干个文件夹,里面是按照顺序命名的帧动画文件。 像我的就是下面这个结构:
disc.txt 这个文件里的内容格式也比较简单:
第一排364 830 15,依次表示:开机动画显示区域heiht高度364,width宽度830,帧数15
后面可以设置多行不同表现形式的动画,这里我设置一个简单动画,只有一行p 1 0 part0 ,首个字母表示动画播放的时段,有三种方案可选:
p -- this part will play unless interrupted by the end of the boot
c -- this part will play to completion, no matter what
f -- same as p but in addition the specified number of frames is being faded out while continue playing. Only the first interrupted f part is faded out, other subsequent f parts are skipped
p 就表示直接全程播放,直到开机完成。第二位的 1 表示播放一次,如果是 0 就是循环播放。
第三位的0表示每两帧图片之间时间间隔为 0 ms,
最后的part0表示需要展示的这些帧动画在这个文件夹中。
注意:最后需要留出一个空行,编辑时需要注意。
文件写法明确了。难点在于,没有UI设计师帮忙,如何搞到这些帧动画呢?
帧动画的制作 直接先展示制作路线:
Android应用里手动写一个简单的渐亮动画——>录屏——>MP4转PNG
我准备在Android应用里手写一个动画,在想办法转成png。
设计上力求简洁,我使用“Stephen OS”作为文案,也是做一个渐亮的表现形式。
方案定下来了,接下来随便新建一个demo项目。我找到一个免费字体Cooper Black,到应用xml里添加TextView控件,设置字体fontFamily:
<TextView
android:id= "@+id/tv_animationtext"
android:layout_width= "wrap_content"
android:layout_height= "wrap_content"
android:fontFamily= "@font/cooper_black"
android:rotation= "90"
android:alpha= "0"
android:text= "Stephen OS"
android:textColor= "@color/white"
android:textSize= "88sp"
app:layout_constraintBottom_toBottomOf= "parent"
app:layout_constraintEnd_toEndOf= "parent"
app:layout_constraintStart_toStartOf= "parent"
app:layout_constraintTop_toTopOf= "parent" />
因为我是Pixel 5手机上刷的AOSP车机系统,所以开机时的屏幕方向还是vertical方向的,而我需要让其横向展示,所以在这个控件放置时直接旋转了90度。而且初始的透明度为0.
然后在Activity里准备写逻辑,顺手在工具类里写一个顶层扩展方法,给Activity设置强制全屏:
fun AppCompatActivity . setFullScreenMode () {
val layoutParams = window . attributes
layoutParams . layoutInDisplayCutoutMode =
WindowManager . LayoutParams . LAYOUT_IN_DISPLAY_CUTOUT_MODE_SHORT_EDGES
window . attributes = layoutParams
window . setFlags (
WindowManager . LayoutParams . FLAG_FULLSCREEN ,
WindowManager . LayoutParams . FLAG_FULLSCREEN
)
val uiOptions = ( View . SYSTEM_UI_FLAG_HIDE_NAVIGATION
or View . SYSTEM_UI_FLAG_IMMERSIVE_STICKY or View . SYSTEM_UI_FLAG_FULLSCREEN )
window . decorView . systemUiVisibility = uiOptions
}
动画编码为求简洁迅速,没有用传统的ValueAnimator,而是直接协程里使用repeat加delay,这种写法相当简单粗暴。
val logoText = rootView . findViewById < TextView >( R . id . tv_animationtext )
MainScope (). launch {
delay ( 2000L )
repeat ( 255 ) {
delay ( 7 )
infoLog ( it . toString ())
logoText . alpha = ( it / 255.0 ). toFloat ()
}
}
然后开启录屏软件,减去首尾多余部分,得到一个纯净的MP4,就是预设的开机动画了。
最后用到这样一个网站,可以将MP4转为png:Video to PNG image sequence converter
得到png后我们下载到本地,批量重命名成顺序的格式。将其放置到part0的文件夹中。准备和disc.txt一起打包。这里有一个坑,不可以直接用7zip打包成zip,最好使用winrar,压缩方式要选择存储:
集成到源码 压缩完成后,我们将bootanimation.zip放置到源码的某一个文件夹中。然后在你设备product的mk文件中,随意一个位置,加一句文件复制的指令:
PRODUCT_COPY_FILES += \
<path-to-your-bootanimation.zip>:system/media/bootanimation.zip
含义为在打包时,将这个zip包复制到ROM的system/media文件夹下。
设备开机后android系统会检索这个文件夹下有没有名为bootanimation.zip的文件,有的话就优先播这个动画替换默认的开机动画。
Pagination © 2024. All rights reserved. LICENSE | NOTICE | CHANGELOG
Powered by Hydejack v9.2.1