TCP/IP模型是实际应用中广泛使用的网络分层架构,它将网络通信分为四个层次:
网络接口层:对应于OSI模型的物理层和数据链路层,负责将数据帧从一个网络节点传输到另一个网络节点。 网络层:与OSI模型的网络层功能相同,负责在不同网络之间进行路由选择和数据包转发。 传输层:与OSI模型的传输层功能相同,提供端到端的可靠数据传输服务。 应用层:对应于OSI模型的会话层、表示层和应用层,为用户提供各种网络应用服务。 网络分层架构的优点包括:
模块化设计:每个层次都有明确的功能和接口,便于设计、实现和维护。 独立性:各层次可以独立发展和更新,互不影响。 易于理解:分层架构使得网络通信的过程更加清晰和易于理解。 灵活性:可以根据需要在不同层次上添加或修改功能。 通过这种分层架构,网络通信变得更加有序和高效,不同层次的技术可以协同工作,为用户提供可靠的网络服务。
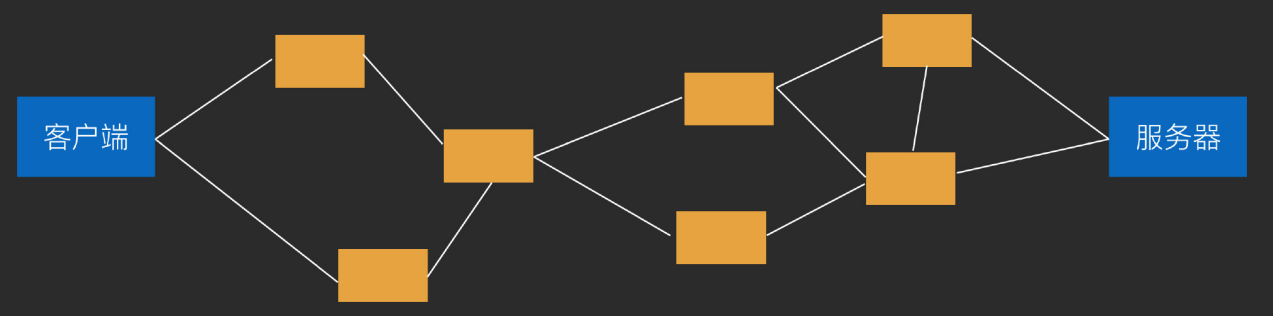
网络分层架构 为什么要分层? 从客户端到服务器的各节点
网络不稳定,所以需要分层。
比如客户端往服务端发起请求的过程中,中间某个节点如果损坏,客户端需要知道信息没发过去,再次发起重传。 但是如果很大的数据,就会传很多次,原本50ms的时间,可能需要传2s才能完成。解决:把这个大的数据切成5块,这5块分别来传,先把能传成功的全部发过去,如果检索到某一块没有收到,再把对应的块给传过去,就只需要多发20%,效率比较高。
分层:有分块传输所以需要分层。上层通信协议众多,http, ftp, mqtt等都有这种分块的需求。所以把包的分发这个工作专门抽出来一层。上层不管传输了,他们只需要把所有要传的数据准备好,再丢给下层TCP去处理。
那么有TCP了,为什么还要往下拉一层?
TCP叫传输层,用来传东西,其注重数据完整性。
但是并不是所有数据我们都需要重传,比如CS枪战游戏数据,如果网络卡顿了,这个数据不能再重传了,只需要不断将最新的数据传输过去就行了。这种需求所产生的协议叫UDP,强调传输性能而不是传输的完整性。
这两种协议又都有网络的需求,都需要从一个主机找到另一个主机。
TCP现在也不去传了,只是将数据分块,并全部按顺序的传输,并检测。UDP也一样,只管分块,不用管传输完整性与顺序。
而下一层的IP只管闷头传,负责寻址,找路由,上层有什么东西丢下来就直接传过去。
阶段小结:这三层都是共同的目的,将数据从一个地方传到另一个地方。 分层原因都是网络不稳定 ,如果网络稳定,所有东西都可以一次性到达,那就不需要这么麻烦了。
数据链路层:这层就是实际的网络,以太网,比如网线,WIFI。其为网络提供显示的实质的支持。
另外还有七层网络模型,它把数据链路层分开了,数据链路层和物理层。物理层为网线,交换器。
具体的分层:
Application Layer 应⽤层:HTTP、FTP、DNS Transport Layer 传输层:TCP、UDP Internet Layer ⽹络层:IP Link Layer 数据链路层:以太⽹、Wi-Fi 对于应用层工程师来说,可以只关心这四层模型。
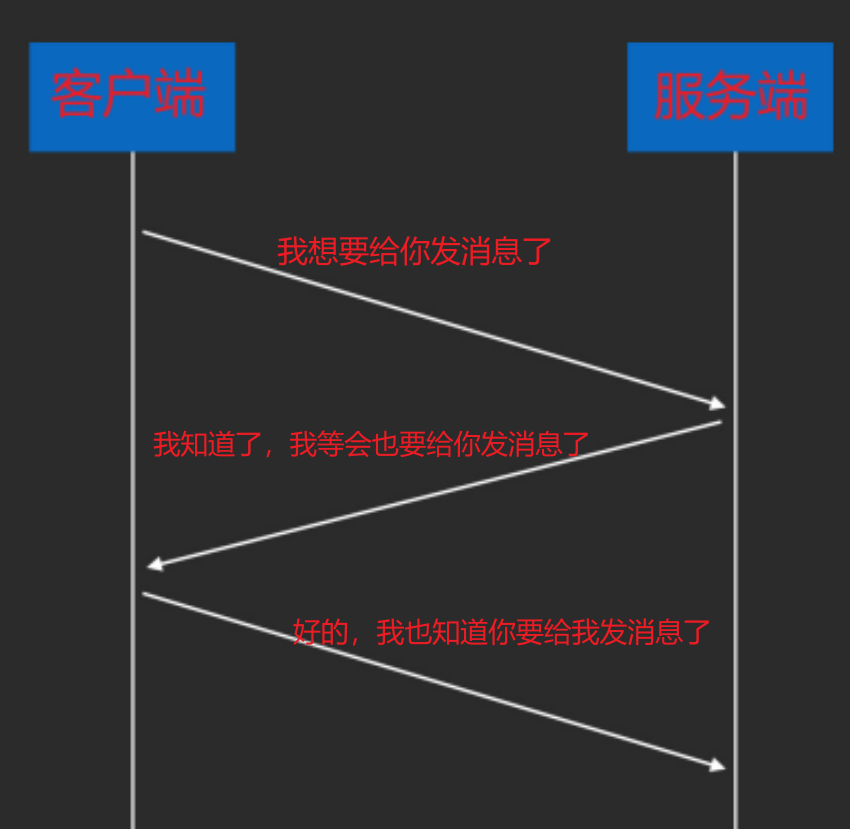
TCP连接 什么叫连接?
TCP是有状态的,他有很多小包需要发送。先建立起第一步通信,来共同确认数据传输包该怎么拼。
连接建立:
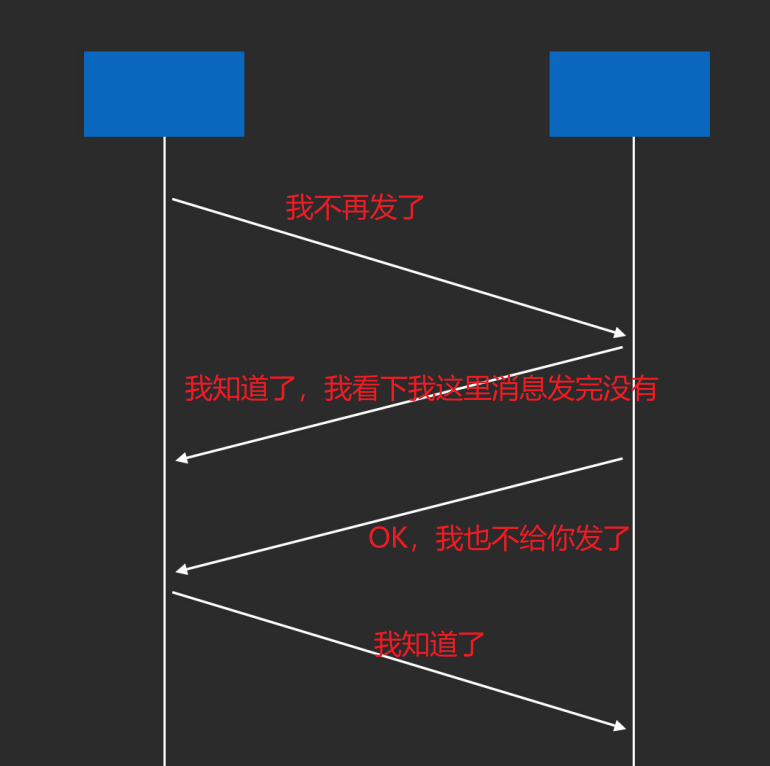
连接的关闭:
长连接 为什么需要长连接? 首先了解内网,一个网关,其内部有很多的主机,某个主机需要和外部的主机通信,网关会先开一个端口,走这个端口和外界主机通信。内网的主机所占用的端口实际是网关的端口。例如,我们的手机网络都是运行在运营商的内网里面的。 长连接:网关给内部主机开端口通信,需要耗费资源的。当内部主机一段时间里没有进行数据通信,网关会把这个端口给关闭掉。那么过一会,当外部主机再走这个端口想要通信时,就连不上了,网路就断了。为了突破这个限制,让网关不去主动关掉这个端口,就需要定时地通信一次,这就是心跳,实现长连接的方式。网关发现这个端口一直在用,就不会将这个端口给关掉了。 长连接很复杂,需要了解的东西相当多,实现很难。
登录:身份认证,确认“你是你”,用户“把我的权限授予我自己” 授权:把权限授予用户,可以持有令牌
登录 Cookie和Authorization都是Headers里的内容。
Cookie 起源:购物车,在 NetScape 网景浏览器时期。某电商网站希望有购物车功能,现在的购物车数据是存在服务器的,当时的人希望将购物车数据存在客户端本地。那么即使浏览器开发者与网站开发者的身份,开发这个就非常方便。
流程:服务器希望你记住什么,就把这个发过来,并标记这个是需要保存在本地的。客户端就将这些数据存在本地。浏览器下次访问相关域的时候,客户端就会自动附加这些数据,服务器不需要再次发送。
移动开发中使用cookie非常少了。
服务器需要客户端保存的内容,放在 Set-Cookie headers ⾥返回,客户端会自动保存。 客户端保存的 Cookies ,会在之后的所有请求⾥都携带进 Cookie header ⾥发回给服务器。 客户端保存 Cookie 是按照服务器域名来分类的,例如 shop.com 发回的 Cookie 保存下来以后,在之后向 games.com 的请求中并不会携带。 客户端保存的 Cookie 在超时后会被删除、没有设置超时时间的 Cookie (称作 SessionCookie)在浏览器关闭后就会⾃动删除;另外,服务器也可以主动删除还未过期的客户端Cookies。
作用:一般都是客户端给自己作标记,服务器拿本地的 Cookie 来对比。HTTP是无状态的,使用这个机制可以让服务器标识不同的用户。例如会话管理,登录状态,购物车,用户偏好,分析用户行为。
用户tracking流程图:
XSS(Cross-site scripting) 跨站脚本攻击 如果Cookie里有用户关键信息,比如密码等。那么本地有恶意的JavaScript脚本的话,就可以将这些Cookie发走,窃取用户数据。 应对:在Header里加入HttpOnly关键字。那本地脚本就看不到这个Cookie了。
XSRF 跨站请求伪造 即在⽤户不知情的情况下访问 已经保存了 Cookie 的⽹站,以此来越权操作⽤户账户(例如盗取⽤户资⾦)。应对⽅式主要是 从服务器安全⻆度考虑,就不多说了。
Referer校验
Authoriztion Basic 使用的不多 格式:Authorization: Basic <username:password(Base64ed)> 有安全风险,用户名和密码相当于明文传输,万一被截获。
Bearer “持有者” 格式:Authorization: Bearer token需要找授权方取得
Oauth2 例如:使用github登录稀土掘金,第三方是掘金。即将授权的令牌授予给要用的第三方的网站。 流程:
第三⽅⽹站向授权⽅⽹站申请第三⽅授权合作,拿到 client id 和 client secret ⽤户在使⽤第三⽅⽹站时,点击「通过 XX (如 GitHub) 授权」按钮,第三⽅⽹站将⻚⾯跳转到授权⽅⽹站,并传⼊ client id 作为⾃⼰的身份标识 授权⽅⽹站根据 client id ,将第三⽅⽹站的信息和第三⽅⽹站需要的⽤户权限展示给⽤户,并询问⽤户是否同意授权 ⽤户点击「同意授权」按钮后,授权⽅⽹站将⻚⾯跳转回第三⽅⽹站,并传⼊ Authorization code 作为⽤户认可的凭证。 第三⽅⽹站客户端将 Authorization code(只是表明用户同意授权) 发送回第三方⾃⼰的服务器 第三方网站的服务器将 Authorization code 和⾃⼰的 client secret(第三方向授权方申请时附加的表明自己的身份) ⼀并发送给授权⽅的服务器,说用户已经同意了。注意这个secret是需要绝对安全的。授权⽅服务器在验证通过后,返回 access token给第三方的服务器。OAuth 流程结束。 在上⾯的过程结束之后,第三⽅⽹站的服务器(或者有时客户端也会)就可以使⽤授权的 access token 作为⽤户授权的令牌,向授权⽅⽹站发送请求来获取⽤户信息或操作⽤户账户。但这已经在 OAuth 流程之外。 可以看到,最大的好处就是token是保密的,只在两个服务器方进行交互,保证登录安全。
易混淆:第三方登录 我和掘金之间的登录操作,利用了github登录,那么github属于第三方。
例子:微信登录(第三方登录)
流程:
第三⽅ App 向腾讯申请第三⽅授权合作,拿到 client id 和 client secret 用户在使⽤第三⽅ App 时,点击「通过微信登录」,第三⽅ App 将使⽤微信 SDK 跳转到微信,并传⼊⾃⼰的 client id 作为⾃⼰的身份标识 微信通过和服务器交互,拿到第三⽅ App 的信息,并限制在界⾯中,然后询问⽤户是否同意授权该 App 使⽤微信来登录 ⽤户点击「使⽤微信登录」后,微信和服务器交互将授权信息提交,然后跳转回第三⽅App,并传⼊ Authorization code 作为⽤户认可的凭证 第三⽅ App 调⽤⾃⼰服务器的「微信登录」Api,并传⼊ Authorization code,然后等待服务器的响应。让服务器去和微信的服务器换取token。 服务器在收到登录请求后,拿收到的 Authorization code 去向微信的第三⽅授权接⼝发送请求,将 Authorization code 和⾃⼰的 client secret ⼀起作为参数发送,微信在验证通过后,返回 access token 服务器在收到 access token 后,⽴即拿着 access token 去向微信的⽤户信息接⼝发送请求,微信验证通过后,返回⽤户信息 服务器在收到⽤户信息后,在⾃⼰的数据库中为⽤户创建⼀个账户,并使⽤从微信服务器拿来的⽤户信息填⼊⾃⼰的数据库,以及将⽤户的 ID 和⽤户的微信 ID 做关联 ⽤户创建完成后,服务器向客户端的请求发送响应,传送回刚创建好的⽤户信息 客户端收到服务器响应,⽤户登录成功 与github授权登录没有区别,只是叫法与概念不同。也是微信把自己的token授权给第三方的网站使用。
自己的服务器 使用Bearer token(流程需要加深理解,与OAuth第三方授权的区别)
有的 App 会在 Api 的设计中,将登录和授权设计成类似 OAuth2 的过程,但简化掉Authorization code 概念。即:登录接⼝请求成功时,会返回 access token,然后客户端在之后的请求中,就可以使⽤这个 access token 来当做 bearer token 进⾏⽤户操作了。
就是一种简化版的OAuth授权,直接使用code和自家服务器换取token。
refresh token ⽤法:access token 有失效时间,在它失效后,调⽤ refresh token 接⼝,传⼊ refresh_token 来获取新的 access token。
{
"token_type": "Bearer",
"access_token": "xxxxx",
"refresh_token": "xxxxx",
"expires_time": "xxxxx"
}
⽬的:安全。当 access token 失窃,由于它有失效时间,因此坏⼈只有较短的时间来「做坏事」;同时,由于(在标准的 OAuth2 流程中)refresh token 永远只存在与第三⽅服务的服务器中,因此 refresh token ⼏乎没有失窃的⻛险。
背景 HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
HTTP是一个属于 应用层 的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展。
HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
主要特点 简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。 灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。 无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。 无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。 支持B/S及C/S模式。 HTTP之URL HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息
URL,全称是UniformResourceLocator, 中文叫统一资源定位符,是互联网上用来标识某一处资源的地址。以下面这个URL为例,介绍下普通URL的各部分组成:
http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name
从上面的URL可以看出,一个完整的URL包括以下几部分:
协议部分:该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在”HTTP”后面的“//”为分隔符 域名部分:该URL的域名部分为“www.aspxfans.com”。一个URL中,也可以使用IP地址作为域名使用 端口部分:跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口 虚拟目录部分:从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是“/news/” 文件名部分:从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.asp”。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名 锚部分:从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。锚部分也不是一个URL必须的部分。锚的主要作用是在一个HTML文档中标识出一个特定的位置,这样当用户点击包含这个锚的链接时,浏览器就会直接滚动到文档中对应的位置。 参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为“boardID=5&ID=24618&page=1”。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。 URI和URL的区别 URI,是uniform resource identifier,统一资源标识符,用来唯一的标识一个资源。
Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是一个来URI来定位的。
URI一般由三部组成:
访问资源的命名机制 存放资源的主机名 资源自身的名称,由路径表示,着重强调于资源。 URL是uniform resource locator,统一资源定位器,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何locate这个资源。
URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上,特别是著名的Mosaic。
采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。URL一般由三部组成:
协议(或称为服务方式) 存有该资源的主机IP地址(有时也包括端口号) 主机资源的具体地址。如目录和文件名等 URN,uniform resource name,统一资源命名,是通过名字来标识资源,比如mailto:java-net@java.sun.com
URI是以一种抽象的,高层次概念定义统一资源标识,而URL和URN则是具体的资源标识的方式。
URL和URN都是一种URI。
笼统地说,每个 URL 都是 URI,但不一定每个 URI 都是 URL。这是因为 URI 还包括一个子类,即统一资源名称 (URN),它命名资源但不指定如何定位资源。
上面的 mailto、news 和 isbn URI 都是 URN 的示例。
在Java的URI中,一个URI实例可以代表绝对的,也可以是相对的,只要它符合URI的语法规则。而URL类则不仅符合语义,还包含了定位该资源的信息,因此它不能是相对的。
在Java类库中,URI类不包含任何访问资源的方法,它唯一的作用就是解析。 相反的是,URL类可以打开一个到达资源的流。
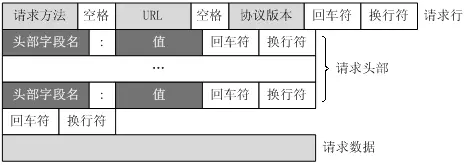
HTTP之请求消息Request 客户端发送一个HTTP请求到服务器的请求消息包括以下格式:
请求行(request line)、请求头部(header)、空行和请求数据 四个部分组成。
请求行以一个方法符号开头,以空格分开,后面跟着请求的URI和协议的版本。 Get请求例子,使用Charles抓取的request:
GET /562f25980001b1b106000338.jpg HTTP/1.1
Host img.mukewang.com
User-Agent Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36
Accept image/webp,image/*,*/*;q=0.8
Referer http://www.imooc.com/
Accept-Encoding gzip, deflate, sdch
Accept-Language zh-CN,zh;q=0.8
第一部分:请求行,用来说明请求类型,要访问的资源以及所使用的HTTP版本. GET说明请求类型为GET, [/562f25980001b1b106000338.jpg] 为要访问的资源,该行的最后一部分说明使用的是HTTP1.1版本。
第二部分:请求头部,紧接着请求行(即第一行)之后的部分,用来说明服务器要使用的附加信息。从第二行起为请求头部,HOST将指出请求的目的地。User-Agent,服务器端和客户端脚本都能访问它,它是浏览器类型检测逻辑的重要基础。该信息由你的浏览器来定义,并且在每个请求中自动发送等等。
第三部分:空行,请求头部后面的空行是必须的。即使第四部分的请求数据为空,也必须有空行。
第四部分:请求数据也叫主体,可以添加任意的其他数据。这个例子的请求数据为空。
POST请求例子,使用Charles抓取的request:
POST / HTTP1.1
Host:www.wrox.com
User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022)
Content-Type:application/x-www-form-urlencoded
Content-Length:40
Connection: Keep-Alive
name=Professional%20Ajax&publisher=Wiley
第一部分:请求行,第一行明了是post请求,以及http1.1版本。 第二部分:请求头部,第二行至第六行。 第三部分:空行,第七行的空行。 第四部分:请求数据,第八行。
请求头 请求头(Request Header)在HTTP通信中扮演着至关重要的角色,它为服务器提供了关于客户端请求的额外信息,帮助服务器更好地理解和处理请求。以下是请求头的一些主要作用:
传递元数据:请求头可以包含关于请求的各种元数据,如请求的方法(GET、POST等)、请求的目标资源(URL)、请求的协议版本(如HTTP/1.1)等。
身份验证:通过包含认证信息(如Authorization头部),客户端可以向服务器证明自己的身份,以便访问受保护的资源。
内容协商:客户端可以通过Accept、Accept-Encoding、Accept-Language等头部字段告知服务器自己能够接受的内容类型、编码方式和语言,服务器可以根据这些信息返回最合适的响应内容。
缓存控制:客户端可以通过Cache-Control、If-Modified-Since、If-None-Match等头部字段来控制缓存行为,减少不必要的网络传输。
会话管理:通过Cookie头部,客户端可以向服务器发送之前存储的会话信息,以便服务器识别用户并维护会话状态。
代理信息:请求头中可以包含关于客户端所使用的代理服务器的信息,如Via头部。
内容长度:Content-Length头部字段用于指示请求体的长度,帮助服务器正确处理请求。
内容类型:Content-Type头部字段用于指定请求体的媒体类型,如application/json、application/x-www-form-urlencoded等。
在移动端开发中,以下是一些最常用的请求头及其使用方法举例:
User-Agent:用于标识客户端的类型和版本,服务器可以根据这个信息返回适合移动端设备的内容。
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 14_4 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Mobile/15E148 Safari/604.1
Accept:用于指定客户端能够接受的内容类型。
Accept: application/json, text/plain, */*
Authorization:用于传递认证信息,通常用于访问需要身份验证的API。
Authorization: Bearer <token>
Content-Type:用于指定请求体的媒体类型。
Content-Type: application/json
Accept-Language:用于指定客户端能够接受的语言。
Accept-Language: zh-CN,zh;q=0.9
Cache-Control:用于控制缓存行为。
Cookie:用于发送之前存储的会话信息。
Cookie: session_id=abc123; user_id=12345
If-Modified-Since:用于检查资源是否在指定时间之后被修改过。
If-Modified-Since: Mon, 26 Jul 2021 12:00:00 GMT
这些请求头在移动端开发中经常被使用,它们帮助客户端和服务器之间进行有效的通信,确保请求和响应的正确处理。
请求数据 HTTP请求数据(也称为请求体或请求正文)在客户端向服务器发送请求时扮演着重要的角色。它包含了客户端希望发送给服务器的额外信息,这些信息通常是在请求方法(如POST、PUT等)中需要传递的数据。以下是HTTP请求数据的主要作用:
传递数据:请求数据允许客户端向服务器发送数据,这些数据可以是表单提交的数据、文件上传的数据、API调用的参数等。
更新资源:在使用PUT或PATCH请求方法时,请求数据用于更新服务器上的资源。
创建资源:在使用POST请求方法时,请求数据用于创建新的资源。
在移动端开发中,最常用的请求数据格式和类型包括:
JSON:JavaScript Object Notation,是一种轻量级的数据交换格式,易于阅读和编写,同时也易于机器解析和生成。它是移动端开发中最常用的数据格式之一,特别是在与RESTful API进行通信时。 {
"username" : "john.doe" ,
"password" : "secret123"
}
Form Data:表单数据是一种常见的请求数据格式,通常用于提交表单数据。在移动端开发中,表单数据通常用于用户登录、注册、提交表单等场景。 username=john.doe&password=secret123
Multipart Form Data:多部分表单数据是一种特殊的表单数据格式,用于上传文件。在移动端开发中,多部分表单数据通常用于上传图片、视频等文件。 Content-Disposition: form-data; name="file"; filename="example.jpg"
Content-Type: image/jpeg
<binary data>
XML:可扩展标记语言,是一种用于标记电子文件使其具有结构性的标记语言。虽然JSON在移动端开发中更为流行,但XML仍然在某些场景下被使用,特别是在与一些传统的Web服务进行通信时。 <user>
<username> john.doe</username>
<password> secret123</password>
</user>
Text:纯文本格式,通常用于发送简单的文本信息,如日志、错误消息等。
This is a sample text message.
这些请求数据格式在移动端开发中经常被使用,具体使用哪种格式取决于服务器端的API设计和客户端的需求。
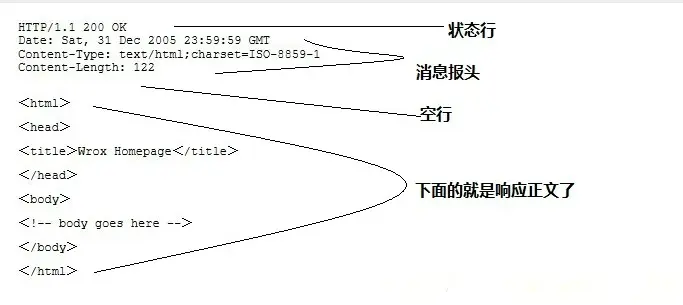
HTTP之响应消息Response 一般情况下,服务器接收并处理客户端发过来的请求后会返回一个HTTP的响应消息。
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
例子
HTTP / 1.1 200 OK
Date : Fri, 22 May 2009 06:07:21 GMT
Content-Type : text/html; charset=UTF-8
<html>
<head></head>
<body>
<!--body goes here-->
</body>
</html>
第一部分:状态行,由HTTP协议版本号,状态码,状态消息 三部分组成。第一行为状态行,(HTTP/1.1)表明HTTP版本为1.1版本,状态码为200,状态消息为(ok) 第二部分:消息报头,用来说明客户端要使用的一些附加信息。第二行和第三行为消息报头,Date:生成响应的日期和时间;Content-Type:指定了MIME类型的HTML(text/html),编码类型是UTF-8 第三部分:空行,消息报头后面的空行是必须的。 第四部分:响应正文,服务器返回给客户端的文本信息。空行后面的html部分为响应正文。 HTTP之状态码 状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx:指示信息–表示请求已接收,继续处理 2xx:成功–表示请求已被成功接收、理解、接受 3xx:重定向–要完成请求必须进行更进一步的操作 4xx:客户端错误–请求有语法错误或请求无法实现 5xx:服务器端错误–服务器未能实现合法的请求 常见状态码:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
消息报头 HTTP响应中的消息报头(Response Headers)用于向客户端提供关于响应的附加信息。这些信息可以帮助客户端更好地理解和处理服务器返回的响应内容。消息报头通常包含了以下几种类型的信息。
内容类型和编码:例如Content-Type和Content-Encoding,用于指定响应体的媒体类型和编码方式。 缓存控制:例如Cache-Control、Expires和ETag,用于控制客户端和代理服务器如何缓存响应。 重定向和跳转:例如Location,用于指示客户端应该重定向到的新URL。 认证和授权:例如WWW-Authenticate和Set-Cookie,用于要求客户端进行身份验证或设置会话信息。 内容长度和范围:例如Content-Length和Content-Range,用于指示响应体的长度和范围。 跨域资源共享:例如Access-Control-Allow-Origin和Access-Control-Allow-Methods,用于控制跨域请求的访问权限。 常见的响应数据 HTTP响应中的响应正文(Response Body)包含了服务器返回给客户端的实际数据。这些数据可以是HTML页面、JSON对象、图像、音频、视频或任何其他类型的文件。响应正文的主要作用是向客户端提供请求的资源或数据。
在移动端开发中,最常见的HTTP响应正文类型包括:
HTML页面:用于在移动浏览器中显示网页内容。 <html>
<head>
<title> Example Page</title>
</head>
<body>
<h1> Welcome to Example Page</h1>
<p> This is an example HTML page.</p>
</body>
</html>
JSON数据:用于在移动应用中与后端API进行数据交互。 {
"message" : "Hello, World!" ,
"status" : "success"
}
图像文件:如JPEG、PNG或GIF格式的图片。 Content-Type: image/jpeg
<binary data>
音频文件:如MP3、AAC或WAV格式的音频。 Content-Type: audio/mpeg
<binary data>
视频文件:如MP4、WebM或AVI格式的视频。 Content-Type: video/mp4
<binary data>
文件下载:用于从服务器下载文件,如PDF、Word文档等。 Content-Disposition: attachment; filename="example.pdf"
Content-Type: application/pdf
<binary data>
纯文本文件:用于返回简单的文本信息,如日志、错误消息等。 This is a sample text message.
这些响应正文类型在移动端开发中经常被使用,具体使用哪种类型取决于客户端的请求和服务器的响应。
HTTP请求方法 根据HTTP标准,HTTP请求可以使用多种请求方法。
HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。 HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
GET 请求指定的页面信息,并返回实体主体。
HEAD 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
PUT 从客户端向服务器传送的数据取代指定的文档的内容。
DELETE 请求服务器删除指定的页面。
CONNECT HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
OPTIONS 允许客户端查看服务器的性能。
TRACE 回显服务器收到的请求,主要用于测试或诊断。
HTTP工作原理 HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
以下是 HTTP 请求/响应的步骤:
1、客户端连接到Web服务器 一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.oakcms.cn。
2、发送HTTP请求 通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
3、服务器接受请求并返回HTTP响应 Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
4、释放连接TCP连接 若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
5、客户端浏览器解析HTML内容 客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
例如:在浏览器地址栏键入URL,按下回车之后会经历以下流程:
1、浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
2、解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立TCP连接;
3、浏览器发出读取文件(URL 中域名后面部分对应的文件)的HTTP 请求,该请求报文作为 TCP 三次握手的第三个报文的数据发送给服务器;
4、服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
5、释放 TCP连接;
6、浏览器将该 html 文本并显示内容;
GET和POST请求的区别 GET请求
GET /books/?sex=man&name=Professional HTTP/1.1
Host: www.wrox.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Connection: Keep-Alive
注意最后一行是空行
POST请求
POST / HTTP/1.1
Host: www.wrox.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 40
Connection: Keep-Alive
name=Professional%20Ajax&publisher=Wiley
差异一 地址栏 GET提交,请求的数据会附在URL之后(就是把数据放置在HTTP协议头中),以?分割URL和传输数据,多个参数用&连接;例如: login.action?name=hyddd&password=idontknow&verify=%E4%BD%A0 %E5%A5%BD 。如果数据是英文字母/数字,原样发送,如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用BASE64加密,得出如: %E4%BD%A0%E5%A5%BD,其中%XX中的XX为该符号以16进制表示的ASCII。
POST提交:把提交的数据放置在是HTTP包的包体中。上文示例中红色字体标明的就是实际的传输数据
因此,GET提交的数据会在地址栏中显示出来,而POST提交,地址栏不会改变
差异二 数据长度限制 传输数据的大小:首先声明:HTTP协议没有对传输的数据大小进行限制,HTTP协议规范也没有对URL长度进行限制。
而在实际开发中存在的限制主要有:
GET:特定浏览器和服务器对URL长度有限制,例如 IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系统的支持。
因此对于GET提交时,传输数据就会受到URL长度的限制。
POST:由于不是通过URL传值,理论上数据不受限。但实际各个WEB服务器会规定对post提交数据大小进行限制,Apache、IIS6都有各自的配置。
差异三 安全性 POST的安全性要比GET的安全性高。比如:通过GET提交数据,用户名和密码将明文出现在URL上,因为(1)登录页面有可能被浏览器缓存;(2)其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了,除此之外,使用GET提交数据还可能会造成Cross-site request forgery攻击。
4、Http get,post,soap协议都是在http上运行的
(1)get:请求参数是作为一个key/value对的序列(查询字符串)附加到URL上的查询字符串的长度受到web浏览器和web服务器的限制(如IE最多支持2048个字符),不适合传输大型数据集同时,它很不安全。
(2)post:请求参数是在http标题的一个不同部分(名为entity body)传输的,这一部分用来传输表单信息,因此必须将Content-type设置为:application/x-www-form-urlencoded。post设计用来支持web窗体上的用户字段,其参数也是作为key/value对传输。但是:它不支持复杂数据类型,因为post没有定义传输数据结构的语义和规则。
(3)soap:是http post的一个专用版本,遵循一种特殊的xml消息格式 Content-type设置为: text/xml 任何数据都可以xml化。
Http协议定义了很多与服务器交互的方法,最基本的有4种,分别是GET,POST,PUT,DELETE. 一个URL地址用于描述一个网络上的资源,而HTTP中的GET, POST, PUT, DELETE就对应着对这个资源的查,改,增,删4个操作。 我们最常见的就是GET和POST了。GET一般用于获取/查询资源信息,而POST一般用于更新资源信息.
总结 GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的Body中.
GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值。
GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码。
学习文章基于豪哥的教程,源地址:
Android Framework
源码分区 Android 常用的四个分区:
System 分区 Vender 分区 Odm 分区 Product 分区 ARM + Android 这个行业,一个简化的普遍流程:
Google 开发迭代 AOSP + Kernel 芯片厂商,针对自己的芯片特点,移植 AOSP 和 Kernel,使其可以在自己的芯片上跑起来。 方案厂商(很多芯片厂商也扮演了方案厂商的角色),设计电路板,给芯片添加外设,在芯片厂商源码基础上开发外设相关软件,主要是驱动和 hal,改进性能和稳定性。 产品厂商,主要是系统软件开发,UI 定制以及硬件上的定制(添加自己的外设),改进性能和稳定性. Google 开发的通用 Android 系统组件编译后会被存放到 System 分区,原则上不同厂商、不同型号的设备都通用。
芯片厂商和方案厂商针对硬件相关的平台通用的可执行程序、库、系统服务和 app 等一般放到 Vender 分区。(开发的驱动程序是放在 boot 分区的 kernel 部分)
到了产品厂商这里,情况稍微复杂一点,通常针对同一套软硬件平台,可能会开发多个产品。比如:小米 12s,小米12s pro,小米12s ultra 均源于骁龙8+平台。
每一个产品,我们称之为一个 Variant(变体)。
通常情况下,做产品的厂商在同一个硬件平台上针对不同的产品会从硬件和软件两个维度来做定制。
硬件上,产品 A 可能用的是京东方的屏,产品 B 可能用的是三星的屏;差异硬件相关的软件部分都会放在 Odm 分区。这样,产品 A 和产品 B 之间 Odm 以外的分区都是一样的,便于统一维护与升级。(硬件相关的软件共用部分放在 vendor 分区)
软件上,产品 A 可能是带广告的版本,产品 B 可能是不带广告的版本。这些有差异的软件部分都放在 Product 分区,这样产品 A 和产品 B 之间 Product 以外的分区都是一样的,便于统一维护与升级。(软件共用部分都放在 System分区)
总结一下,不同产品之间公共的部分放在 System 和 Vender 分区,差异的部分放在 Odm 和 Product 分区。
Product配置 在编译之前执行的 lunch 命令,所展示的那些列表,就是一个个不同的product。可以看到后缀大致有user,userdebug,eng三种。
区别如下:
用户模式 user
仅安装标签为 user 的模块 设定属性 ro.secure=1,打开安全检查功能 设定属性 ro.debuggable=0,关闭应用调试功能 默认关闭 adb 功能 打开 Proguard 混淆器 打开 DEXPREOPT 预先编译优化
用户调试模式 userdebug
安装标签为 user、debug 的模块 设定属性 ro.secure=1,打开安全检查功能 设定属性 ro.debuggable=1,启用应用调试功能 默认打开 adb 功能 打开 Proguard 混淆器 打开 DEXPREOPT 预先编译优化
工程模式 eng
安装标签为 user、debug、eng 的模块 设定属性 ro.secure=0,关闭安全检查功能 设定属性 ro.debuggable=1,启用应用调试功能 设定属性 ro.kernel.android.checkjni=1,启用 JNI 调用检查 默认打开 adb 功能 关闭 Proguard 混淆器 关闭 DEXPREOPT 预先编译优化
由于我使用的是谷歌官方的Pixel 5设备,所以所需的product已经在源码里面配置完毕了。
此设备配置文件在这个目录:
device/google_car/redfin_car
主要集成相关的配置文件:
#
# Copyright 2020 The Android Open Source Project
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
$(call inherit-product, device/google_car/common/pre_google_car.mk)
$(call inherit-product, device/google_car/redfin_car/device-redfin-car.mk)
$(call inherit-product-if-exists, vendor/google_devices/redfin/proprietary/device-vendor.mk)
$(call inherit-product-if-exists, vendor/google_devices/redfin/prebuilts/device-vendor-redfin.mk)
$(call inherit-product, device/google_car/common/post_google_car.mk)
PRODUCT_MANUFACTURER := Google
PRODUCT_BRAND := Android
PRODUCT_NAME := aosp_redfin_car
PRODUCT_DEVICE := redfin
PRODUCT_MODEL := Stephen_Car001
PRODUCT_PACKAGES += \
RedfinDemo \
hello \
hellojava \
Kugou \
Sougou \
BaiduMap \
Term \
Gemini \
Google \
busybox \
SystemAppDemo \
helloseandroid \
initscript
PRODUCT_BROKEN_VERIFY_USES_LIBRARIES := true
PRODUCT_PROPERTY_OVERRIDES := \
persist.sys.language=zh \
persist.sys.country=CN \
persist.sys.timezone=Asia/Shanghai
BOARD_SEPOLICY_DIRS += \
device/google_car/redfin_car/sepolicy
要自己定制,可以直接基于Google的源码改。
新定义一个product 如果是使用模拟器,直接跑X86_64的环境的话。就需要自己重新定义product。
针对我们选择的 aosp_x86_64-eng,我们主要关注以下几个文件:
/board/generic_x86_64/BoardConfig.mk : 用于硬件相关配置
/product/AndroidProducts.mk 和 /product/aosp_x86_64.mk:用于配置 Product
BoardConfig.mk 用于定义和硬件相关的底层特性和变量,比如当前源码支持的 cpu 位数(64/32位),bootloader 和 kernel, 是否支持摄像头,GPS导航等一些板级特性。主要和硬件相关,有一个基本的了解即可。一般很少改动。 AndroidProducts.mk 定义我们执行 lunch 命令时,打印的列表以及每个选项对应的配置文件 PRODUCT_MAKEFILES 用于引入产品的配置文件。 COMMON_LUNCH_CHOICES 用于添加 lunch 时的选项,选项的名字由两部分过程 产品名 + 构建模式: 产品名就是 PRODUCT_MAKEFILES 中引入的产品配置文件名去掉 .mk 后缀,例如 aosp_x86_64 构建模式有三种:用户模式 user、用户调试模式 userdebug 和工程模式 eng。在上面已经展示了它们的区别。 aosp_x86_64.mk:这个文件就是模拟器产品配置的主基地。 PRODUCT_USE_DYNAMIC_PARTITIONS := true
# The system image of aosp_x86_64-userdebug is a GSI for the devices with:
# - x86 64 bits user space
# - 64 bits binder interface
# - system-as-root
# - VNDK enforcement
# - compatible property override enabled
# This is a build configuration for a full-featured build of the
# Open-Source part of the tree. It's geared toward a US-centric
# build quite specifically for the emulator, and might not be
# entirely appropriate to inherit from for on-device configurations.
# GSI for system/product
$(call inherit-product, $(SRC_TARGET_DIR)/product/core_64_bit.mk)
$(call inherit-product, $(SRC_TARGET_DIR)/product/gsi_common.mk)
# Emulator for vendor
$(call inherit-product-if-exists, device/generic/goldfish/x86_64-vendor.mk)
$(call inherit-product, $(SRC_TARGET_DIR)/product/emulator_vendor.mk)
$(call inherit-product, $(SRC_TARGET_DIR)/board/generic_x86_64/device.mk)
# Enable mainline checking for excat this product name
ifeq (aosp_x86_64,$(TARGET_PRODUCT))
PRODUCT_ENFORCE_ARTIFACT_PATH_REQUIREMENTS := relaxed
endif
PRODUCT_ARTIFACT_PATH_REQUIREMENT_WHITELIST += \
root/init.zygote32_64.rc \
root/init.zygote64_32.rc \
# Copy different zygote settings for vendor.img to select by setting property
# ro.zygote=zygote64_32 or ro.zygote=zygote32_64:
# 1. 64-bit primary, 32-bit secondary OR
# 2. 32-bit primary, 64-bit secondary
# init.zygote64_32.rc is in the core_64_bit.mk below
PRODUCT_COPY_FILES += \
system/core/rootdir/init.zygote32_64.rc:root/init.zygote32_64.rc
# Product 基本信息
PRODUCT_NAME := aosp_x86_64
PRODUCT_DEVICE := generic_x86_64
PRODUCT_BRAND := Android
PRODUCT_MODEL := AOSP on x86_64
inherit-product 函数表示继承另外一个文件
$(call inherit-product, $(SRC_TARGET_DIR)/product/emulator_vendor.mk)
$(call inherit-product-if-exists, device/generic/goldfish/x86_64-vendor.mk)
在 Makefile 中可使用 “-include” 来代替 “include”,来忽略由于包含文件不存在或者无法创建时的错误提示(“-”的意思是告诉make,忽略此操作的错误。make继续执行),如果不加-,当 include 的文件出错或者不存在的时候, make 会报错并退出。
-include $(TARGET_DEVICE_DIR)/AndroidBoard.mk
include 和 inherit-product 的区别:
假设 PRODUCT_VAR := a 在 A.mk 中, PRODUCT_VAR := b 在 B.mk 中。
如果你在 A.mk 中 include B.mk,你最终会得到 PRODUCT_VAR := b。
但是如果你在 A.mk inherit-product B.mk,你会得到 PRODUCT_VAR := a b。
并且 inherit-product 确保您不会两次包含同一个 makefile 。
添加product 在device目录下新建一个产品名:
Jelly/
└── Rice14
├── AndroidProducts.mk
├── BoardConfig.mk
└── Rice14.mk
BoardConfig.mk 包含了硬件芯片架构配置,分区大小配置等信息这里我们直接使用 aosp_x86_64 的 BoardConfig.mk 就行。BoardConfig.mk 拷贝自 build/target/board/generic_x86_64/BoardConfig.mk
Rice14.mk 拷贝自 build/target/product/aosp_x86_64.mk
其中的 if 语句需要注释掉,同时需要修改最后四行:
PRODUCT_USE_DYNAMIC_PARTITIONS := true
# The system image of aosp_x86_64-userdebug is a GSI for the devices with:
# - x86 64 bits user space
# - 64 bits binder interface
# - system-as-root
# - VNDK enforcement
# - compatible property override enabled
# This is a build configuration for a full-featured build of the
# Open-Source part of the tree. It's geared toward a US-centric
# build quite specifically for the emulator, and might not be
# entirely appropriate to inherit from for on-device configurations.
# GSI for system/product
$(call inherit-product, $(SRC_TARGET_DIR)/product/core_64_bit.mk)
$(call inherit-product, $(SRC_TARGET_DIR)/product/gsi_common.mk)
# Emulator for vendor
$(call inherit-product-if-exists, device/generic/goldfish/x86_64-vendor.mk)
$(call inherit-product, $(SRC_TARGET_DIR)/product/emulator_vendor.mk)
$(call inherit-product, $(SRC_TARGET_DIR)/board/generic_x86_64/device.mk)
# Enable mainline checking for excat this product name
#ifeq (aosp_x86_64,$(TARGET_PRODUCT))
PRODUCT_ENFORCE_ARTIFACT_PATH_REQUIREMENTS := relaxed
#endif
PRODUCT_ARTIFACT_PATH_REQUIREMENT_WHITELIST += \
root/init.zygote32_64.rc \
root/init.zygote64_32.rc \
# Copy different zygote settings for vendor.img to select by setting property
# ro.zygote=zygote64_32 or ro.zygote=zygote32_64:
# 1. 64-bit primary, 32-bit secondary OR
# 2. 32-bit primary, 64-bit secondary
# init.zygote64_32.rc is in the core_64_bit.mk below
PRODUCT_COPY_FILES += \
system/core/rootdir/init.zygote32_64.rc:root/init.zygote32_64.rc
# Overrides
PRODUCT_BRAND := Jelly
PRODUCT_NAME := Rice14
PRODUCT_DEVICE := Rice14
PRODUCT_MODEL := Android SDK built for x86_64 Rice14
AndroidProducts.mk 内容如下:
PRODUCT_MAKEFILES := \
$(LOCAL_DIR)/Rice14.mk
COMMON_LUNCH_CHOICES := \
Rice14-eng \
Rice14-userdebug \
Rice14-user
验证:
source build/envsetup.sh
lunch Rice14-eng
make -j16
emulator
集成脚本编写 mk文件 以下是一个简单的示例,展示了如何编写一个基本的Android.mk文件来编译一个C或C++库:
# 定义本地路径
LOCAL_PATH := $(call my-dir)
# 清除变量
include $(CLEAR_VARS)
# 定义模块名称
LOCAL_MODULE := mylibrary
# 定义源文件
LOCAL_SRC_FILES := \
file1.cpp \
file2.cpp \
file3.cpp
# 定义编译标志
LOCAL_CFLAGS := -Wall -Werror
# 定义链接库
LOCAL_LDLIBS := -llog
# 构建静态库
include $(BUILD_STATIC_LIBRARY)
LOCAL_PATH: 定义了当前Android.mk文件所在的目录。 LOCAL_PATH := $(call my-dir)
CLEAR_VARS: 清除所有之前定义的变量,以确保每个模块的编译都是独立的。 LOCAL_MODULE: 定义了要生成的模块名称。 LOCAL_SRC_FILES: 列出了所有要编译的源文件。 LOCAL_SRC_FILES := file1.c file2.c
LOCAL_CFLAGS: 定义了编译时的标志,如警告和错误处理。 LOCAL_CFLAGS := -Wall -Werror
LOCAL_LDLIBS: 定义了链接时需要的库。 LOCAL_C_INCLUDES:指定头文件目录。 LOCAL_C_INCLUDES := $(LOCAL_PATH)/include
include $(BUILD_STATIC_LIBRARY)
include:包含其他 Makefile 文件。 include $(LOCAL_PATH)/../SomeOther.mk
LOCAL_C_INCLUDES:指定头文件目录。 LOCAL_C_INCLUDES := $(LOCAL_PATH)/include
LOCAL_SHARED_LIBRARIES 和 LOCAL_STATIC_LIBRARIES:指定依赖的共享库或静态库。 LOCAL_SHARED_LIBRARIES := libutils libcutils
LOCAL_STATIC_LIBRARIES := libmylib
LOCAL_PRELINK_MODULE:指定模块是否需要预链接。 LOCAL_PRELINK_MODULE := false
LOCAL_PACKAGE_NAME:定义 APK 包的名称。 LOCAL_PACKAGE_NAME := MyApp
LOCAL_JAVA_LIBRARIES:指定依赖的 Java 库。 LOCAL_JAVA_LIBRARIES := android-support-v4
bp文件 Android.bp 文件使用类似 JSON 的语法,但有一些特定的扩展。以下是一些基本的语法规则:
模块定义:使用 module 关键字定义一个模块,后面跟着模块类型(如 cc_binary、java_library 等)和模块的属性。
属性赋值:属性使用键值对的形式,键和值之间用冒号 : 分隔。值可以是字符串、列表或嵌套的对象。
列表:列表使用方括号 [] 表示,列表中的元素用逗号 , 分隔。
嵌套对象:嵌套对象使用花括号 {} 表示,嵌套对象中的属性也使用键值对的形式。
示例: 以下是一个简单的 Android.bp 文件示例,定义了一个 C++ 可执行文件:
cc_binary {
name: "hello",
srcs: ["hello.cpp"],
cflags: ["-Werror"],
}
cc_binary:表示这是一个 C++ 可执行文件模块。 name:指定模块的名称,这里是 “hello”。 srcs:指定源文件列表,这里只有一个源文件 “hello.cpp”。 cflags:指定编译标志,这里是 “ -Werror”,表示将所有警告视为错误。 常见模块类型 cc_binary:C++ 可执行文件。 cc_library:C++ 库。 java_library:Java 库。 java_binary:Java 可执行文件。 android_app:Android 应用程序。
模块属性 不同类型的模块有不同的属性,但一些常见的属性包括:
name:模块的名称。 srcs:源文件列表。 cflags:编译标志。 ldflags:链接标志。 shared_libs:依赖的共享库列表。 static_libs:依赖的静态库列表。
系统签名制作 如果系统供应商和app是不同的开发人员,又想在系统app的上下文中进行应用的开发,就需要制作一系统签名文件,提供给app开发人员,这样app就可以在系统的环境下进行开发和调试了。
生成系统签名需要java的openssl工具,可以使用apt工具安装。
首先切到~/aaos/build/target/product/security目录下,应有如下文件:
stephen@CODE01:~/aaos/build/target/product/security$ ls
Android.bp fsverity-release.x509.der platform.jks shared.pk8 verity.x509.pem
Android.mk media.pk8 platform.p12 shared.x509.pem verity_key
README media.x509.pem platform.pem testkey.pk8
cts_uicc_2021.pk8 networkstack.pk8 platform.pk8 testkey.x509.pem
cts_uicc_2021.x509.pem networkstack.x509.pem platform.x509.pem verity.pk8
执行命令:
第一,生成platform.pem文件
openssl pkcs8 -inform DER -nocrypt -in platform.pk8 -out platform.pem
第二,将在目录下生成platform.p12文件。
其中,pass后的字段为签名密码password,name后字段为Keyalias,根据自己喜好设置。
openssl pkcs12 -export -in platform.x509.pem -out platform.p12 -inkey platform.pem -password pass:stephen -name stephen
第三,就是生成jks签名文件了。
其中-deststorepass后也会用到上一步设置的password字段。
keytool -importkeystore -deststorepass stephen -destkeystore platform.jks -srckeystore platform.p12 -srcstoretype PKCS12 -srcstorepass stephen
生成的platform.jks就是我们需要的系统签名了。
将这个签名文件部署到我们应用文件夹里,并在app应用级的gradle里进行配置:
release {
storeFile file('../platform.jks')
storePassword 'stephen'
keyAlias 'stephen'
keyPassword 'stephen'
}
之后在AndroidManifest文件里,设置android:sharedUserId="android.uid.system"和系统进程共享userid,就可以获取到系统权限了。
集成C程序 源码集成 在product的目录下,新建一个hello文件夹,用来放置源代码文件和编译脚本文件。
~/aaos/device/google_car/redfin_car/hello
# Android.bp
cc_binary{
name:"hello",
srcs:["hello.cpp"],
cflags:["-Werrors"],
}
hello . cpp
#include <cstdio>
int main (){
printf ( "hello world! \n " );
return 0 ;
}
最后在aosp_redfin_car.mk里面添加:
PRODUCT_PACKAGES += \
RedfinDemo \
···
hello \
集成C可执行文件 busybox介绍: busybox 是一个类 Unix 操作系统的工具箱,它提供了许多常用的命令,例如 ls、cp、rm 等。
一样的,提前新建一个prebuilt文件夹,用来放置可执行文件。
# Android.bp
cc_prebuilt_binary {
name: "busybox",
srcs: ["busybox-armv8l"],
product_specific: true,
}
第二个就是busybox的可执行文件了,busybox-armv8l
同样需要在aosp_redfin_car.mk里面加入编译的包。
集成Java程序 新建一个helloJava的文件夹。
# Android.bp
java_library {
name: "hellojava",
installable: true,
product_specific: true,
srcs: ["**/*.java"],
sdk_version: "current"
}
java文件放置在包里面,目录结构为:
helloJava/com/stephen/main/HelloJava.java
package com.stephen.main ;
public class HelloJava
{
public static void main ( String [] args )
{
System . out . println ( "Hello Java" );
}
}
apk的方式集成系统app apk文件形式集成 RedfinDemo是第一个项目,里面是一些调试使用的功能,版本信息罗列,app管理等。
# Amdroid.mk
LOCAL_PATH:= $(call my-dir)
include $(CLEAR_VARS)
LOCAL_MODULE := RedfinDemo
LOCAL_MODULE_CLASS := APPS
LOCAL_MODULE_TAGS := optional
LOCAL_BUILT_MODULE_STEM := package.apk
LOCAL_MODULE_SUFFIX := $(COMMON_ANDROID_PACKAGE_SUFFIX)
LOCAL_CERTIFICATE := PRESIGNED
LOCAL_PRIVILEGED_MODULE := true
LOCAL_VENDOR_MODULE := false
LOCAL_SRC_FILES := RedfinDemo.apk
LOCAL_OVERRIDES_PACKAGES := \
Calendar \
CalendarProvider \
Email \
Exchange2 \
Gallery2 \
HoloSpiralWallpaper \
HTMLViewer \
SharedStorageBackup \
SoundRecorder \
TelephonyProvider \
VideoEditor \
VoiceDialer \
VoicePlus \
Camera \
Clock \
Contacts \
include $(BUILD_PREBUILT)
LOCAL_OVERRIDES_PACKAGES 是一个列表,其中包含了要覆盖的系统应用程序的包名。当 RedfinDemo.apk 安装时,它会覆盖这些系统应用程序。
同样,需要在aosp_redfin_car.mk里面加入编译的包。
PARODUCT_PACKAGES += \
RedfinDemo \
···
源码方式集成系统app 首先,我们敲定包名为package="com.example.systemappdemo"
在product目录下新建一个SystemAppDemo文件夹,用来放置源码。
定义Android.bp脚本:
android_app {
name: "SystemAppDemo",
srcs: ["src/**/*.java"],
resource_dirs: ["res"],
manifest: "AndroidManifest.xml",
platform_apis: true,
privileged: true,
sdk_version: "",
//签名证书
certificate: "platform",
//依赖
static_libs: ["androidx.appcompat_appcompat",
"com.google.android.material_material",
"androidx-constraintlayout_constraintlayout"],
}
借助Android Studio,新建一个空项目,注意新建VIEW架构而不是Compose的。然后进行文件的复制。
将res文件夹完全复制到这个目录下 然后将AndroidManifest.xml文件复制到这个目录下。 最后将MainActivity.java文件,复制到: SystemAppDemo/src/com/example/systemappdemo/MainActivity.java
引入其他的库 当我们的系统 App 需要引入一个库的时候,通常会在 prebuilds 目录下查找:
androidx 相关库引入,先在 prebuilts/sdk/current/androidx 下寻找配置好的 bp 文件 其他库引入,先在 prebuilts/tools/common/m2 下寻找寻找配置好的 bp 文件 都没有,就得自己引入了 以recyclerView为例,在Android.bp文件中添加现成的源码:
android_library_import {
name: "androidx.recyclerview_recyclerview-nodeps",
aars: ["m2repository/androidx/recyclerview/recyclerview/1.1.0-alpha07/recyclerview-1.1.0-alpha07.aar"],
sdk_version: "current",
min_sdk_version: "14",
static_libs: [
"androidx.annotation_annotation",
"androidx.collection_collection",
"androidx.core_core",
"androidx.customview_customview",
],
}
三方app集成 有时候需要集成一些第三方的app,比如国内的输入法,影音媒体等软件。
拿到第三方的apk之后,直接在product目录下建立对应的目录,将apk放进去,然后配置mk文件,最后在aosp_redfin_car.mk里面加入编译的包。
注意大多数app都有专门的动态库文件,需要在编译时提取出来编译对应平台的so库。
以百度地图为例:
# Android.mk
LOCAL_PATH := $(call my-dir)
APK_NAME_FULL :=$(shell cd $(LOCAL_PATH); ls -A | grep apk)
APK_NAME :=$(shell echo $(APK_NAME_FULL) | sed 's/.apk//g')
$(warning --------------fullName=$(APK_NAME_FULL)---------------------name=$(APK_NAME))
define get-all-libraries-module-name-in-subdirs
$(sort $(shell cd $(LOCAL_PATH) ; rm -rf lib >/dev/null ; unzip $(APK_NAME_FULL) 'lib/*.so' -d . >/dev/null ; find -L $(1) -name "*.so"))
endef
ALL_LIBRARIES_MODULE_NAME := $(call get-all-libraries-module-name-in-subdirs, lib/arm64-v8a)
$(warning ALL_LIBRARIES_MODULE_NAME:--- $(ALL_LIBRARIES_MODULE_NAME) )
#integrate the apk
include $(CLEAR_VARS)
LOCAL_MODULE := BaiduMap
LOCAL_MODULE_TAGS := optional
LOCAL_MODULE_CLASS := APPS
LOCAL_CERTIFICATE := PRESIGNED
LOCAL_MODULE_SUFFIX := .apk
LOCAL_SRC_FILES := $(APK_NAME_FULL)
LOCAL_PRIVILEGED_MODULE := true
LOCAL_VENDOR_MODULE := false
LOCAL_MODULE_PATH := $(TARGET_OUT_SYSTEM_APPS)
LOCAL_PREBUILT_JNI_LIBS := $(ALL_LIBRARIES_MODULE_NAME)
include $(BUILD_PREBUILT)
背景 学习C++之余,想把原生AOSP的开机动画给更新替换下,换换口味。
我们都知道,AOSP的默认开机动画是一个“ANDROID”的字样,配合一个渐变的底色动画。定制一个自己的开机动画,对于手机厂商来说,有利于宣传品牌,彰显企业文化。
像国内广为人知的定制系统,比如MIUI,ColorOS,FlymeOS等,都是没有直接使用默认动画的,定制了一套他们自己厂商的开机动画。而考虑到大厂都是人力充足,设计师,动效师,应有尽有。
那像我这自己在下面玩玩源码的,没有设计师帮忙,该怎么搞一套看得过去的定制化的开机动画呢?
开始制作 从压缩包制作倒推流程 首先经过调研了解到,我们如果想要自己定制Android的开机动画,需要准备一个名为bootanimation.zip的压缩包,去替换系统默认的动画。
那压缩包里放什么文件呢?
zip包里面的文件格式一般比较固定:
disc.txt,用来描述帧动画的播放策略和显示大小。 若干个文件夹,里面是按照顺序命名的帧动画文件。 像我的就是下面这个结构:
disc.txt 这个文件里的内容格式也比较简单:
第一排364 830 15,依次表示:开机动画显示区域heiht高度364,width宽度830,帧数15
后面可以设置多行不同表现形式的动画,这里我设置一个简单动画,只有一行p 1 0 part0 ,首个字母表示动画播放的时段,有三种方案可选:
p -- this part will play unless interrupted by the end of the boot
c -- this part will play to completion, no matter what
f -- same as p but in addition the specified number of frames is being faded out while continue playing. Only the first interrupted f part is faded out, other subsequent f parts are skipped
p 就表示直接全程播放,直到开机完成。第二位的 1 表示播放一次,如果是 0 就是循环播放。
第三位的0表示每两帧图片之间时间间隔为 0 ms,
最后的part0表示需要展示的这些帧动画在这个文件夹中。
注意:最后需要留出一个空行,编辑时需要注意。
文件写法明确了。难点在于,没有UI设计师帮忙,如何搞到这些帧动画呢?
帧动画的制作 直接先展示制作路线:
Android应用里手动写一个简单的渐亮动画——>录屏——>MP4转PNG
我准备在Android应用里手写一个动画,在想办法转成png。
设计上力求简洁,我使用“Stephen OS”作为文案,也是做一个渐亮的表现形式。
方案定下来了,接下来随便新建一个demo项目。我找到一个免费字体Cooper Black,到应用xml里添加TextView控件,设置字体fontFamily:
<TextView
android:id= "@+id/tv_animationtext"
android:layout_width= "wrap_content"
android:layout_height= "wrap_content"
android:fontFamily= "@font/cooper_black"
android:rotation= "90"
android:alpha= "0"
android:text= "Stephen OS"
android:textColor= "@color/white"
android:textSize= "88sp"
app:layout_constraintBottom_toBottomOf= "parent"
app:layout_constraintEnd_toEndOf= "parent"
app:layout_constraintStart_toStartOf= "parent"
app:layout_constraintTop_toTopOf= "parent" />
因为我是Pixel 5手机上刷的AOSP车机系统,所以开机时的屏幕方向还是vertical方向的,而我需要让其横向展示,所以在这个控件放置时直接旋转了90度。而且初始的透明度为0.
然后在Activity里准备写逻辑,顺手在工具类里写一个顶层扩展方法,给Activity设置强制全屏:
fun AppCompatActivity . setFullScreenMode () {
val layoutParams = window . attributes
layoutParams . layoutInDisplayCutoutMode =
WindowManager . LayoutParams . LAYOUT_IN_DISPLAY_CUTOUT_MODE_SHORT_EDGES
window . attributes = layoutParams
window . setFlags (
WindowManager . LayoutParams . FLAG_FULLSCREEN ,
WindowManager . LayoutParams . FLAG_FULLSCREEN
)
val uiOptions = ( View . SYSTEM_UI_FLAG_HIDE_NAVIGATION
or View . SYSTEM_UI_FLAG_IMMERSIVE_STICKY or View . SYSTEM_UI_FLAG_FULLSCREEN )
window . decorView . systemUiVisibility = uiOptions
}
动画编码为求简洁迅速,没有用传统的ValueAnimator,而是直接协程里使用repeat加delay,这种写法相当简单粗暴。
val logoText = rootView . findViewById < TextView >( R . id . tv_animationtext )
MainScope (). launch {
delay ( 2000L )
repeat ( 255 ) {
delay ( 7 )
infoLog ( it . toString ())
logoText . alpha = ( it / 255.0 ). toFloat ()
}
}
然后开启录屏软件,减去首尾多余部分,得到一个纯净的MP4,就是预设的开机动画了。
最后用到这样一个网站,可以将MP4转为png:Video to PNG image sequence converter
得到png后我们下载到本地,批量重命名成顺序的格式。将其放置到part0的文件夹中。准备和disc.txt一起打包。这里有一个坑,不可以直接用7zip打包成zip,最好使用winrar,压缩方式要选择存储:
集成到源码 压缩完成后,我们将bootanimation.zip放置到源码的某一个文件夹中。然后在你设备product的mk文件中,随意一个位置,加一句文件复制的指令:
PRODUCT_COPY_FILES += \
<path-to-your-bootanimation.zip>:system/media/bootanimation.zip
含义为在打包时,将这个zip包复制到ROM的system/media文件夹下。
设备开机后android系统会检索这个文件夹下有没有名为bootanimation.zip的文件,有的话就优先播这个动画替换默认的开机动画。
Pixel5使用体验 去年2022年中的时候网购了一台Pixel5的库存机,现在闲置成备用机了。
之所以有这个在手机上跑车机的想法,是因为笔者是车机Android应用层开发,想着谷歌手机原生支持那么好,能不能整一个Google Automotive的车机系统上去跑跑,顺便还可以学习学习AOSP源码、系统编译、系统apk集成、权限管理、CarService服务等等。
一看官方网站居然还真有定制,而且目前恰好支持Pixel4a和Pixel5,另外还有Pixel6,但是是Experimental实验性的,拿6代设备的朋友整活有风险。
2024-12-31更新:目前已经支持到了Pixel8手机
废话不多说,开始正经的经验记录!
系统环境准备 首先最低硬盘控件需要准备300G,低于这个数就很危险了。
打开Windows功能 注意Google的AOSP开源项目,谷歌宣称其开发和调试均是在Ubuntu14上进行的。强烈建议开发者也需要使用Ubuntu系统进行AOSP源码的拉取和编译。
不想把自己电脑刷成Ubuntu系统的话,也可以使用windows上的wsl虚拟机,这个也是需要win10及以上可以使用,直接通过微软Microsoft应用商店搜索Ubuntu即可下载安装。注意安装之前要在控制面板的“程序和功能”里打开“windows子系统选项”,重启系统后生效。
WSL迁移其他盘与空间扩展 安装完成后,进行简单的username用户名和password设置就可以进入系统了,啊,还是熟悉的terminal指令。然后下一步我们需要将这个子系统的位置从C盘移出去。
因为安装位置默认在C盘,而一份源码下载和编译后至少需要300G的空间,所以为了windows系统的流畅运行,我们最好不要将其挤在C盘,使用工具将其迁移到其他盘下面。为了完成这个操作,我们需要下载一个第三方工具 LxRunOffline,这个是由国人开发的 WSL 工具,其可以弥补官方工具的不足,比如说他可以实现将任何发行版的 Linux 以 WSL 形式安装到 Windows 10 中,增强 WSL 发行版管理功能,甚至可以实现 WSL 系统备份和恢复,这样无论是学习 Linux 还是进行开发工作都要比以往操作更为方便。
# 以管理员权限打开PowerShell,首先关闭wsl虚拟机
wsl --shutdown
#切到LxRunOfflin目录下,查看系统里wsl有哪些
.\LxRunOffline.exe list
#迁移wsl,需要十几分钟,完成后会生成虚拟硬件磁盘ext4.vhdx文件
.\LxRunOffline.exe move -n Ubuntu-20.04 -d f:\wsl_ubuntu20
#迁移完成,查看迁移后路径
.\LxRunOffline.exe get-dir -n Ubuntu-20.04
完成后还有一个问题,WSL默认只支持最大256G的硬盘空间,我们下载源码编译后很有可能就会超过256G,那么WSL就会报错,编译等操作也会中断。想要将WSL的最大硬盘空间突破这个限制,需要通过扩展 VHD 大小来解决:
#关闭wsl
wsl --shutdown
#查看wsl版本
wsl -l -v
NAME STATE VERSION
* Ubuntu-20.04 Stopped 2
#进入disk命令行
diskpart
#选择虚拟磁盘
DISKPART> Select vdisk file=f:\wsl_ubuntu20\ext4.vhdx
#查看VHD的详细信息
DISKPART> detail vdisk
#扩展vdisk空间,xxx为空间大小,以MB为单位,默认为256000,我拓展到了1000000
DISKPART> expand vdisk maximum=xxx
#退出DISKPART,进入wsl
DISKPART> exit
$wsl
#查看分区
$df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sdb 251G 991M 238G 1% /
tools 200G 53G 148G 27% /init
none 4.9G 0 4.9G 0% /dev
tmpfs 4.9G 0 4.9G 0% /sys/fs/cgroup
none 4.9G 4.0K 4.9G 1% /run
...
#在wsl中操作,使wsl知道磁盘大小限制已经更改
$sudo mount -t devtmpfs none /dev
# 将none挂载到/dev目录下,若返回'mount: /dev: none already mounted on /dev.',可忽略
$mount | grep ext4
# 得到none挂载到/dev目录下的磁盘路径名
# 本句命令返还的信息 '/dev/sdX' 即为磁盘路径名,X可能是a,b,c等,xxx为前面分配的vhd大小,M为MB单位
$ sudo resize2fs /dev/sdb 1000000M
resize2fs 1.44.1 (24-Mar-2018)
Filesystem at /dev/sdb is mounted on /; on-line resizing required
old_desc_blocks = 32, new_desc_blocks = 123
The filesystem on /dev/sdb is now 256000000 (4k) blocks long.
# 重新查看分区配置
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sdb 961G 1000M 918G 1% /
tools 200G 53G 148G 27% /init
none 4.9G 0 4.9G 0% /dev
WSL拉取同步Android源码 上面WSL移出C盘和硬盘空间扩展完成之后,Ubuntu环境准备完成,即可开始Android源码的拉取了,注意拉代码前一定要提前下载这些辅助工具,以免正式开始后缺工具,手忙脚乱。
代码拉取前的程序安装 注意不要习惯性的将Ubuntu换源阿里或者中科大,我们直接使用WSL上自带的默认软件源,否则有些官方工具的安装会产生链式依赖问题,在Ubuntu18及以上终端输入:
sudo apt-get install git-core gnupg flex bison build-essential zip curl zlib1g-dev gcc-multilib g++-multilib libc6-dev-i386 libncurses5 lib32ncurses5-dev x11proto-core-dev libx11-dev lib32z1-dev libgl1-mesa-dev libxml2-utils xsltproc unzip fontconfig
另外别忘了安装java,后面编译,还有开发系统应用生成Android系统platform签名,需要用到java的keytool工具。
sudo apt install oracle-java8-installer
WSL不可使用adb,刷机流程更改 使用wsl的话,我们虽然可以使用usbipd这个工具来配置,访问windows电脑连接的usb设备,但是不可以识别手机,也不可以在wsl上使用adb进行调试刷机。所以我最终采用的方案是Ubuntu编译,将编译产物同步到windows,再在windows上连接手机,最后进行设备刷写推送。
# 这个目录就是windows的文件夹在wsl的挂载同步,可以以此作为两个系统的文件同步区域
cd mnt/d/Pixel5
# 复制编译产物到Windows下的文件夹
cp -r /aaos/build/product/XXXX /mnt/d/Pixel5
使用repo进行源码拉取同步 首先明确一点,Pixel 5手机其支持的车机版本只有一个,我们必须使用 Android 12,和build SP1A.210812.016.A1,对应AOSP分支为 android-12.0.0_r3
Android的AOSP源码使用repo来进行版本管理,repo是Google开发的用于管理Android版本库的一个工具,repo是使用Python对git进行了一定的封装,并不是用于取代git,它简化了对多个Git版本库的管理。用repo管理的版本库都需要使用git命令来进行操作。
下载repo工具:
mkdir ~/bin
PATH=~/bin:$PATH
curl https://storage.googleapis.com/git-repo-downloads/repo > ~/bin/repo
chmod a+x ~/bin/repo
建议在home的个人文件夹下,建立放置源码的工作目录,一开机ls就是它了:
# 新建文件夹
mkdir aaos_on_phone
# 切换工作目录
cd aaos_on_phone
为了下载速度能拉满,我没有使用谷歌的官方仓库来拉取同步代码,而是改为使用清华大学的镜像网站,内容是相同的:清华大学开源软件镜像站 | Tsinghua Open Source Mirror 打开后,可以看到第一个就是AOSP项目。
在新建好的工作目录下,使用如下命令通过repo工具拉取AOSP源码,笔者没有WI-FI,直接使用手机流量来硬刚的,大概需要70个G左右,耗时2小时。
# 初始化repo仓库,拉取某一个特定的分支
repo init -u https://mirrors.tuna.tsinghua.edu.cn/git/AOSP/platform/manifest -b android-12.0.0_r3
# 开始同步拉取代码
repo sync
经过漫长的等待之后,打开工作目录,应该是下面的目录结构,因为我已经编译过,还加入了设备build文件,所以会多一点东西:
特定设备的二进制文件下载解包 源码拉取完成后,需下载特定设备的专有二进制文件和补丁程序,在如下网站找到对应设备与安卓版本的二进制包Nexus 和 Pixel 设备的驱动程序二进制文件 | Google Play services | Google for Developers
对于Pixel 5,需要找到:适用于 Android 12.0.0 (SP1A.210812.016.A1) 的 Pixel 5 二进制文件。
下载完毕之后,将此文件copy到源码目录进行解压:
# 复制供应商映像和高通的驱动二进制文件到源码目录
cp mnt/d/Downloads/extract-google_devices-redfin.sh /home/stephen/aaos
cp mnt/d/Downloads/extract-qcom-redfin.sh /home/stephen/aaos
# 解压缩两个文件
curl --output - https://dl.google.com/dl/android/aosp/google_devices-redfin-sp1a.210812.016.a1-8813b219.tgz | tar -xzvf -
tail -n +315 extract-google_devices-redfin.sh | tar -zxvf -
curl --output - https://dl.google.com/dl/android/aosp/qcom-redfin-sp1a.210812.016.a1-8d32b5b1.tgz | tar -xzvf -
tail -n +315 extract-qcom-redfin.sh | tar -xzvf -
开始编译源码 WSL运行内存分配 源码和设备二进制文件准备完成后,可能有的朋友就按耐不住要开始编译了,其实还有很重要的一个步骤。
源码的编译是非常非常耗性能的,特别是内存,默认分配的是物理机一半的运行内存,对于编译源码是不太够的,所以我们要对WSL子系统进行一些特殊的性能配置,在个人用户文件夹下,新建一个 .wslconfig 文件,里面配置的字段含义可以参考微软官方文档:WSL 中的高级设置配置 | Microsoft Learn
[wsl2]
# Limits VM memory to use no more than 24 GB, this can be set as whole numbers using GB or MB
memory=24GB
# Sets the VM to use 6 virtual processors
processors=6
# Sets amount of swap storage space to 8GB, default is 25% of available RAM
swap=0
# Turn on default connection to bind WSL 2 localhost to Windows localhost
localhostForwarding=true
# 一些实验性的配置
# Enable experimental features
[experimental]
autoMemoryReclaim=gradual
networkingMode=mirrored
dnsTunneling=true
firewall=true
autoProxy=true
配置完成后,笔者电脑是32G内存,核显显存分出去1个G,虚拟机分配24G,合理设置保证性能同时不会使windows系统其他功能可用内存太局促。
切换到wsl的源码目录,准备开始编译。
launch起编系统 名词解释:
Makefile → Android平台编译系统,用Makefile写出来的一个独立项目,定义了编译规则,实现自动化编译,将分散在数百个Git库中的代码整合起来,统一编译,而且把产物分门别类地输出到一个目录,打包成手机ROM,还可以生成应用开发时使用的SDK、NDK等。 Android.mk → 定义一个模块的必要参数,使模块随着平台编译,简单点说就是告诉系统以什么规则编译源代码,并生成对应目标文件; kati → Google专门为Android研发的小工具,基于Golang和C++,作用是:将Android中的Makefile转换为Ninja文件 Ninja → 致力于速度的小型编译系统,把Makefile看做高级语言,那它就是汇编,文件后缀为.ninja; Android.bp → 替换Android.mk的配置文件; Blueprint → 解析Android.bp文件翻译成Ninja语法文件; Soong → Makefile编译系统的替代品,负责解析Android.bp文件,并将之转换为Ninja文件; 起编的命令不多,只有两三行:
# 预声明环境命令
. build/envsetup.sh
# 编译Pixel系统,target选择aosp_redfin_car
lunch <target>
# 开始make编译,新版上直接一个m即可
m
# 构建与汽车相关的软件包
m android.hardware.automotive.audiocontrol@1.0-service android.hardware.automotive.vehicle@2.0-service
每次开始编译开始的第一个命令便是. build/envsetup.sh。在文件envsetup.sh声明了当前会话终端可用的命令,这里需要注意的是当前会话终端,也就意味着每次新打开一个终端都必须再一次执行这些指令。build/envsetup.sh文件存在的意义就是,设置一些环境变量和shell函数为后续的编译工作做准备。
而后的lunch操作执行的其实就是build/envsetup.sh脚本中的lunch函数,选择一个版本进行编译,一般可选user,userdebug,eng三种版本,其上的权限是逐步升级的。如果launch后没有参数,那么会出现一列版本可供选择,选择对应版本前的数字即可。
最后m开始起编,过程很长,笔者第一次编译晚上11点开始,等了两小时才到40%,于是放下电脑睡觉去,早上醒来就编完了。在编译过程中,以前只在论坛文章里看到的那些类,现在全部在命令行里一个个闪现出来参与编译,站在上层应用开发者的角度来看,就很神奇。
源码单编某个模块 除了系统整体进行编译,我们也可以对单个应用模块进行编译,编完的apk可以push推送到系统对应文件夹下,完成单个模块的置换。
source build/envsetup.sh
lunch aosp_bonito-eng
#进入模块目录
cd package/apps/Setting
#编译单独模块的可选指令如下:
#mm → 编译当前目录下的模块,不编译依赖模块
#mmm → 编译指定目录下的模块,不编译依赖模块
#mma → 编译当前目录下的模块及其依赖项
#mmmma → 编译指定路径下所有模块,切包含依赖
mm
#编译成功会提示生成文件的存放路径,除了生成Setting.odex外,还会在
#priv-app/Settings目录下生成Settings.apk,可直接adb push或adb install
#安装APK验证效果,也可以使用make snod命令重新打包生成system.img,运行模拟器查看
开始刷机流程 AOSP编译产物 经过make编译后的产物,都位于源码的 /out目录 ,该目录下我们主要关注下面几个目录:
/out/host:Android开发工具的产物,包含SDK各种工具,比如adb,dex2oat,aapt等。 /out/target/common:通用的一些编译产物,包含Java应用代码和Java库; /out/target/product/[product_name]:针对特定设备的编译产物以及平台相关C/C++代码和二进制文件; 在/out/target/product/[product_name]目录下,有几个重量级的镜像文件:
system.img:挂载为根分区,主要包含Android OS的系统文件; ramdisk.img:主要包含init.rc文件和配置文件等; userdata.img:被挂载在/data,主要包含用户以及应用程序相关的数据; 当然还有boot.img,reocovery.img等镜像文件,这里就不介绍了。 查看/aaos/out/target/product/redfin文件夹下关于Pixel 5设备特定的文件:
stephen@CODE01:~/aaos/out/target/product/redfin$ ls
android-info.txt misc_info.txt
apex module-info.json
appcompat module-info.json.rsp
boot-debug.img obj
boot-test-harness.img obj_arm
boot.img previous_build_config.mk
bootloader.img product
build_fingerprint.txt product.img
build_thumbprint.txt radio.img
clean_steps.mk ramdisk
data ramdisk-debug.img
debug_ramdisk ramdisk-test-harness.img
dexpreopt_config ramdisk.img
dtb.img recovery
dtbo.img root
fake_packages super_empty.img
gen symbols
installed-files-product.json system
installed-files-product.txt system.img
installed-files-ramdisk-debug.json system_ext
installed-files-ramdisk-debug.txt system_ext.img
installed-files-ramdisk.json system_other
installed-files-ramdisk.txt system_other.img
installed-files-recovery.json test_harness_ramdisk
installed-files-recovery.txt testcases
installed-files-root.json userdata.img
installed-files-root.txt vbmeta.img
installed-files-system-other.json vbmeta_system.img
installed-files-system-other.txt vendor
installed-files-system_ext.json vendor.img
installed-files-system_ext.txt vendor_boot-debug.img
installed-files-vendor-ramdisk-debug.json vendor_boot-test-harness.img
installed-files-vendor-ramdisk-debug.txt vendor_boot.img
installed-files-vendor-ramdisk.json vendor_debug_ramdisk
installed-files-vendor-ramdisk.txt vendor_ramdisk
installed-files.json vendor_ramdisk-debug.img
installed-files.txt vendor_ramdisk.img
kernel
确认无问题后,我把整个文件夹全部转到mnt挂载的windows目录下,准备好手机设备后即可刷写了。
cp -r ~/aaos/out/target/product/redfin /mnt/d/Pixel5
设置设备,刷写镜像文件 首先打开pixel 5的开发者选项里的USB调试模式,也需要打开OEM锁:
adb reboot bootloader
fastboot flashing unlock
在编译产物的文件夹,执行以下指令。开始清空设备数据,刷写车机系统,完成后推送汽车相关文件:
# 这些命令也可以制作成sh脚本,每次刷完机都执行一遍即可,免去手动输入
# 等刷写完毕并主屏幕显示后,再推送汽车专用文件
adb root
adb remount
adb reboot
# 每次刷写新系统都需要执行上面三步,使文件系统重新挂载生效
# 就可以使windows的shell获取root权限
adb root
adb remount
adb sync vendor
adb reboot
等手机再次reboot重启后就是下面的动画和launcher界面了:
后续 刷完了系统,不光是走完了一次体验,还需要找到可以学习的角度,深入改动系统代码,通过定制系统,达到需要的效果。
原文链接:
Kotlin Language Documentation 2.2.0
查漏补缺 lambda作为函数参数类型 这个操作平时使用较少,将lambda作为返回参数类型的场景。例如:
val upperCaseString : ( String ) -> String = { text -> text . uppercase () }
fun main () {
println ( upperCaseString ( "hello" ))
// HELLO
}
将一个字符串对象全部转换为大写,将 upperCaseString 声明为lambda类型,就可以作为参数传递。
另外一种用法是作为返回的参数类型。
fun toSeconds ( time : String ): ( Int ) -> Int = when ( time ) {
"hour" -> { value -> value * 60 * 60 }
"minute" -> { value -> value * 60 }
"second" -> { value -> value }
else -> { value -> value }
}
fun main () {
val timesInMinutes = listOf ( 2 , 10 , 15 , 1 )
val min2sec = toSeconds ( "minute" )
val totalTimeInSeconds = timesInMinutes . map ( min2sec ). sum ()
println ( "Total time is $totalTimeInSeconds secs" )
// Total time is 1680 secs
}
toSeconds 函数会根据传入的用法名称,返回一个lambda类型的函数,该函数将一个Int类型的参数转换为另一个Int类型的参数。
页码92
之前写过协程api介绍和核心的挂起恢复原理,再次对其设计思想进行记录,以从更上层的思维模型构筑方面了解 Kotlin 语言的协程。
已有线程为何要使用协程呢 在 JVM 生态系统中,已经有了 Thread 这个设计,对异步计算进行建模的抽象。
但是,JVM 直接映射到 OS 线程的 线程很重 。对于每个线程,OS 必须在堆栈上 分配大量上下文信息 。此外,每次计算达到 阻塞 操作时,底层线程都会暂停,JVM 必须加载另一个线程的上下文。上下文切换成本高昂,因此我们应避免在代码中使用阻塞操作。
JVM 线程上下文(Thread Context)指的是在 JVM 中每个线程所拥有的一组信息,这些信息定义了 线程在运行时的环境和状态 。包含: (1)程序计数器(Program Counter,PC):用于记录线程当前执行的字节码指令地址。当线程被暂停后恢复执行时,程序计数器能让线程知道从哪里继续执行。 (2)栈帧(Stack Frame):线程的栈内存用于存储方法调用的信息,每个方法调用都会在栈上创建一个栈帧。栈帧包含局部变量表、操作数栈、动态链接、方法返回地址等信息。 (3)线程局部存储(Thread Local Storage,TLS):允许线程拥有自己独立的变量副本,不同线程对这些变量的操作互不影响。 (4)寄存器状态:包括 CPU 寄存器的值,如通用寄存器、指令指针寄存器等。这些寄存器的值反映了线程当前的执行状态。 (5)线程优先级:决定了线程在竞争 CPU 资源时的优先顺序。 (6)线程状态:如新建、就绪、运行、阻塞、终止等状态。
另一方面,正如我们将看到的,协程非常轻量级。它们不是直接映射到操作系统线程上,而是在用户级别,使用称为 Continuation 的简单对象。在协程之间切换不需要操作系统加载另一个线程的上下文,而是切换对 Continuation 对象的引用。
采用协程的另一个很好的理由是它们是一种 以同步方式编写异步代码 的方法。
作为替代方案,我们可以使用回调。但是,回调不太优雅,而且不可组合。此外,很难推理它们。很容易陷入回调地狱,代码难以阅读和维护:
a ( aInput ) { resultFromA ->
b ( resultFromA ) { resultFromB ->
c ( resultFromB ) { resultFromC ->
d ( resultFromC ) { resultFromD ->
println ( "A, B, C, D: $resultFromA, $resultFromB, $resultFromC, $resultFromD" )
}
}
}
}
上面的例子展示了使用回调风格执行四个函数。我们可以看出,收集四个函数返回的四个值需要很多工作。而且,代码还有很多优化空间,可以变得易于阅读和维护一些。
异步编程中使用的另一种模型是响应式编程。然而,问题在于它需要生成更复杂的代码才能理解和维护。让我们以 RxJava 库官方文档中的以下代码片段为例:
Flowable . fromCallable (() -> {
Thread . sleep ( 1000 ); // imitate expensive computation
return "Done" ;
})
. subscribeOn ( Schedulers . io ())
. observeOn ( Schedulers . single ())
. subscribe ( System . out :: println , Throwable: : printStackTrace );
上述代码模拟了在后台线程上运行某些计算和网络请求,并在 UI 线程上显示结果(或错误)。它不是自解释的,并不能立即看懂每个方法的作用是什么,我们需要熟悉该库才能理解发生了什么。
协程解决了上述所有问题。让我们看看它是如何解决的。
suspend挂起函数 首先,你可以将协程视为轻量级线程,这意味着它不直接映射到操作系统线程。它是一种可以 随时暂停和恢复 的计算任务。因此,在开始了解如何构建协程之前,我们需要了解如何暂停和恢复协程。
Kotlin 提供了 suspend 关键字来标记可以暂停协程的函数,即允许它暂停并稍后恢复:
suspend fun bathTime () {
logger . info ( "Going to the bathroom" )
delay ( 500L )
logger . info ( "Exiting the bathroom" )
}
该 delay(timeMillis: Long) 函数是suspend函数,会暂停协程500ms。
suspend函数只能从协程或其他suspend函数调用 。它可以被暂停和恢复。在上面的例子中,bathTime函数里,当协程执行到了delay函数时,batchTime函数可以被暂停。一旦delay执行完毕,batchTime恢复,其将从暂停后立即执行的行继续执行。
上述机制完全在 Kotlin 运行时中实现,但它是如何实现的呢?无需深入研究协程的内部结构,suspend function的整个上下文保存在类型为 的对象中 Continuation<T> 。T类型变量表示函数的返回类型。
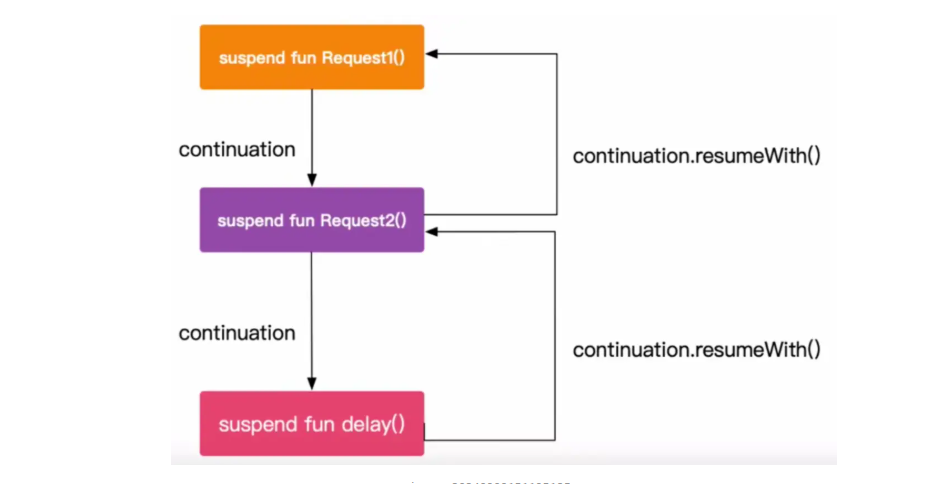
Continuation 包含函数变量和参数的所有状态。此外,它还包括 一个标签 ,用于存储执行暂停的点。因此, Kotlin 编译器将重写每个suspend function ,在函数签名中添加一个 Continuation 类型的参数。我们的函数签名bathTime将被重写如下:
fun bathTime ( continuation : Continuation < * >): Any
为什么编译器还要 改变返回值类型 为 Any 呢?答案是,当函数suspend被挂起时,它不能直接返回函数的值。它必须返回一个值来标记该函数被挂起COROUTINE_SUSPENDED,这样调用方才知道自己调用了一个挂起函数,需要在这里暂停自身的执行。
在 continuation 对象内部,编译器将保存函数执行的状态。由于我们没有参数,也没有内部变量,因此 continuation 仅存储标记 执行进度的标签 。为了简单起见,我们引入一个 BathTimeContinuation 类型来存储函数的上下文。
在我们的示例中,运行时可以bathTime在函数开始时或delay函数之后调用该函数。如果我们使用Int标签,则可以表示函数的两种可能状态,如下所示:
fun bathTime ( continuation : Continuation < * >): Any {
val continuation =
continuation as ? BathTimeContinuation ?: BathTimeContinuation ( continuation )
if ( continuation . label == 0 ) {
logger . info ( "Going to the bathroom" )
continuation . label = 1
if ( delay ( 500L , continuation ) == COROUTINE_SUSPENDED )
return COROUTINE_SUSPENDED
}
if ( continuation . label == 1 ) {
logger . info ( "Exiting the bathroom" )
}
error ( "This line should never be reached" )
}
首先,必须检查continuation对象是否是 BathTimeContinuation 类型。如果不是,我们创建一个新BathTimeContinuation对象,并将该continuation对象作为参数传递。
当bathTime第一次调用该函数时,我们会创建一个新的continuation实例。正如我们所见,continuation就像一层层的洋葱:每次调用suspend function时,我们都会将 continuation 对象包装在一个新的 continuation 中。
然后,如果label是0,我们打印第一条消息并将标签设置为1。然后,我们调用该delay函数,传递continuation对象。如果delay函数返回COROUTINE_SUSPENDED,则表示该函数已暂停,我们也返回COROUTINE_SUSPENDED给调用者。
假设delay函数返回的值不同于COROUTINE_SUSPENDED。在这种情况下,这意味着函数已恢复,我们可以继续执行该bathTime函数。如果标签是1,则该函数刚刚恢复,我们打印第二条消息。
以上是 Kotlin 编译器生成并由 Kotlin 运行时运行的实际代码的简化版本。不过,这足以理解协程的工作原理。
简单来说,就是 将需要执行的代码封装在Continuation对象 中,并将其传递给JVM运行时。运行时将检查该Continuation对象是否已暂停。如果是,则运行时将暂停该函数的执行,并将该待执行的Continuation对象传递给该函数 ,作为一种回调。进入到下一层的挂起函数中,重复这个检查,直接遇到非 COROUTINE_SUSPENDED 状态的返回值,这时候运行时将一层层地恢复该函数的执行。
协程作用域和结构并发 现在我们可以开始研究 Kotlin 如何实现结构并发的概念。让我们声明另一个suspend function,它将模拟煮沸一些水的动作:
suspend fun boilingWater () {
logger . info ( "Boiling water" )
delay ( 1000L )
logger . info ( "Water boiled" )
}
我们介绍的第一个函数是 coroutineScope 挂起函数。此函数是协程的核心,用于创建新的协程作用域。它以挂起 lambda 作为参数,以 CoroutineScope 的实例作为接收者:
suspend fun < R > coroutineScope (
block : suspend CoroutineScope .() -> R
): R
协程作用域代表了 Kotlin 中结构化并发的实现。 运行时会阻塞 lambda 的执行,block直到 lambda 内部启动的所有协程block都完成 。这些协程被称为作用域的子协程。此外,结构化并发还为我们带来了以下特性:
子协程继承父协程的上下文 (CoroutineContext),并且可以覆盖它。协程的上下文是Continuation我们之前见过的对象的一部分。它包含协程的名称、调度程序(即执行协程的线程池)、异常处理程序等。 当父协程被取消时,子协程也会被取消。 当子协程抛出异常时,父协程也会停止。 此外,该coroutineScope函数还创建了一个新的协程,它会暂停前一个协程的执行,直到其执行结束。因此,如果我们想按顺序执行晨间例程的两个步骤,我们可以使用以下代码:
suspend fun sequentialMorningRoutine () {
coroutineScope {
bathTime ()
}
// coroutineScope会挂起当前协程,等bathTime走完才会往下执行
coroutineScope {
boilingWater ()
}
}
为了执行sequentialMorningRoutine,我们必须声明一个暂停main函数,我们将在本文的其余部分重复使用该函数:
suspend fun main () {
logger . info ( "Starting the morning routine" )
sequentialMorningRoutine ()
logger . info ( "Ending the morning routine" )
}
该sequentialMorningRoutine函数将按顺序执行该bathTime函数,然后boilingWater在两个不同的协程中执行该函数。因此,我们不应该对上述代码的输出类似于以下内容感到惊讶:
15:27:05.260 [main] INFO CoroutinesPlayground - Starting the morning routine
15:27:05.286 [main] INFO CoroutinesPlayground - Going to the bathroom
15:27:05.811 [kotlinx.coroutines.DefaultExecutor] INFO CoroutinesPlayground - Exiting the bathroom
15:27:05.826 [kotlinx.coroutines.DefaultExecutor] INFO CoroutinesPlayground - Boiling water
15:27:06.829 [kotlinx.coroutines.DefaultExecutor] INFO CoroutinesPlayground - Water boiled
15:27:06.830 [kotlinx.coroutines.DefaultExecutor] INFO CoroutinesPlayground - Ending the morning routine
我们可以看到,执行是纯顺序的。但是,我们可以看到运行时使用两个不同的线程来执行整个过程,即 main 和 kotlinx.coroutines.DefaultExecutor 线程。协程的一个重要特性是, 当它们恢复时,它们可以在与暂停它们的线程不同的线程中执行 。例如,bathTime协程在 main 主线程上启动。然后,delay函数将其暂停。最后,它在 kotlinx.coroutines.DefaultExecutor 线程上恢复。
协程构建器 launch Builder 至此,我们应该了解suspend function和结构并发的基础知识。现在是时候明确创建我们的第一个协程了。Kotlin 协程库提供了一组称为 builders 的函数。这些函数用于创建协程并开始执行。我们将看到的第一个函数是launch:
public fun CoroutineScope . launch (
context : CoroutineContext = EmptyCoroutineContext ,
start : CoroutineStart = CoroutineStart . DEFAULT ,
block : suspend CoroutineScope .() -> Unit
): Job
该库将 launch 构建器定义为 CoroutineScope 类型的扩展函数。因此,我们需要一个作用域来以这种方式创建协程。要创建协程,我们还需要一个CoroutineContext和一个包含要执行的代码的 lambda。构建器将把它作为接收器传递CoroutineScope给blocklambda。这样,我们可以重用作用域来创建新的子协程。最后,构建器的默认行为是立即启动新的协程(CoroutineStart.DEFAULT)。
因此,让我们在早晨的例行工作中添加一些并发功能。我们可以在两个新的协程中启动boilingWater和bathTime函数,并观察它们的竞争情况:
suspend fun concurrentMorningRoutine () {
coroutineScope {
launch {
bathTime ()
}
launch {
boilingWater ()
}
}
}
上述代码的日志类似于以下内容:
09:09:44.817 [main] INFO CoroutinesPlayground - Starting the morning routine
09:09:44.870 [DefaultDispatcher-worker-1 @coroutine#1] INFO CoroutinesPlayground - Going to the bathroom
09:09:44.871 [DefaultDispatcher-worker-2 @coroutine#2] INFO CoroutinesPlayground - Boiling water
09:09:45.380 [DefaultDispatcher-worker-2 @coroutine#1] INFO CoroutinesPlayground - Exiting the bathroom
09:09:45.875 [DefaultDispatcher-worker-2 @coroutine#2] INFO CoroutinesPlayground - Water boiled
09:09:45.876 [DefaultDispatcher-worker-2 @coroutine#2] INFO CoroutinesPlayground - Ending the morning routine
我们可以从上面的日志中提取出很多信息。首先,我们可以看到我们有效地产生了两个新的协程,coroutine#1和coroutine#2。第一个运行bathTime挂起函数,第二个运行boilingWater。
两个函数的日志是交错的,因此两个函数的执行是并发的。这种并发模型是协作的。只有coroutine#1遇到suspend函数,暂停执行时,coroutine#2才有机会执行。
此外,coroutine#1在线程上运行 DefaultDispatcher-worker-1 暂停,而在 DefaultDispatcher-worker-2线程上恢复。协程在可配置的线程池上运行。正如日志所建议的那样,默认线程池被称为Dispatchers.Default。
最后但并非最不重要的一点是,日志显示了结构并发的一个清晰示例。执行main在两个协程执行后打印了方法中的最后一条日志。我们可能已经注意到,我们没有任何显式同步机制来实现main函数中的这一结果。我们没有等待或延迟main函数的执行。正如我们所说,这是由于结构并发。该coroutineScope函数创建一个用于创建两个协程的作用域。由于这两个协程是同一作用域的子代,因此它将等到它们两个的执行结束才返回。
我们也可以避免使用结构化并发。在这种情况下,我们需要添加一些等待协程执行结束的操作。我们可以使用GlobalScope对象而不是 coroutineScope 函数。它就像一个空的协程作用域,不强制任何父子关系。因此,我们可以重写晨间例程函数,如下所示:
suspend fun noStructuralConcurrencyMorningRoutine () {
GlobalScope . launch {
bathTime ()
}
GlobalScope . launch {
boilingWater ()
}
Thread . sleep ( 1500L )
}
上述代码的日志与前一个代码大体相同:
14:06:57.670 [main] INFO CoroutinesPlayground - Starting the morning routine
14:06:57.755 [DefaultDispatcher-worker-2 @coroutine#2] INFO CoroutinesPlayground - Boiling water
14:06:57.755 [DefaultDispatcher-worker-1 @coroutine#1] INFO CoroutinesPlayground - Going to the bathroom
14:06:58.264 [DefaultDispatcher-worker-1 @coroutine#1] INFO CoroutinesPlayground - Exiting the bathroom
14:06:58.763 [DefaultDispatcher-worker-1 @coroutine#2] INFO CoroutinesPlayground - Water boiled
14:06:59.257 [main] INFO CoroutinesPlayground - Ending the morning routine
由于我们没有使用任何结构化的并发机制GlobalScope,我们Thread.sleep(1500L)在函数末尾添加了一个,以等待两个协程的执行结束。如果我们删除该Thread.sleep调用,日志将类似于以下内容:
21:47:09.418 [main] INFO CoroutinesPlayground - Starting the morning routine
21:47:09.506 [main] INFO CoroutinesPlayground - Ending the morning routine
正如预期的那样,主函数在两个协程执行结束之前就返回了。因此,我们可以说,GlobalScope不是创建协程的好选择 。
如果我们查看该 launch 函数的定义,我们可以看到它返回一个Job对象。该对象是 coroutine 的句柄。我们可以使用它来取消协程的执行或等待其完成。让我们看看如何使用它来等待协程的完成。让我们为我们的钱包添加一个新的suspend function:
suspend fun preparingCoffee () {
logger . info ( "Preparing coffee" )
delay ( 500L )
logger . info ( "Coffee prepared" )
}
在我们的早晨例行工作中,我们只想在洗澡和烧水后准备咖啡。因此,我们需要等待两个协程的完成。我们可以通过join在结果Job对象上调用方法来做到这一点,join方法是一个suspend函数,可以用于等待协程的block完全执行完毕,代码如下:
suspend fun morningRoutineWithCoffee () {
coroutineScope {
val bathTimeJob : Job = launch {
bathTime ()
}
val boilingWaterJob : Job = launch {
boilingWater ()
}
bathTimeJob . join ()
boilingWaterJob . join ()
launch {
preparingCoffee ()
}
}
}
正如我们所料,从日志中我们可以看到,在两个协程执行结束后,我们才准备了咖啡:
21:56:18.040 [main] INFO CoroutinesPlayground - Starting the morning routine
21:56:18.128 [DefaultDispatcher-worker-1 @coroutine#1] INFO CoroutinesPlayground - Going to the bathroom
21:56:18.130 [DefaultDispatcher-worker-2 @coroutine#2] INFO CoroutinesPlayground - Boiling water
21:56:18.639 [DefaultDispatcher-worker-1 @coroutine#1] INFO CoroutinesPlayground - Exiting the bathroom
21:56:19.136 [DefaultDispatcher-worker-1 @coroutine#2] INFO CoroutinesPlayground - Water boiled
21:56:19.234 [DefaultDispatcher-worker-2 @coroutine#3] INFO CoroutinesPlayground - Preparing coffee
21:56:19.739 [DefaultDispatcher-worker-2 @coroutine#3] INFO CoroutinesPlayground - Coffee prepared
21:56:19.739 [DefaultDispatcher-worker-2 @coroutine#3] INFO CoroutinesPlayground - Ending the morning routine
但是,既然我们现在知道了结构并发的所有秘密,我们可以 使用coroutineScope函数 的功能重写上述代码:
suspend fun structuralConcurrentMorningRoutineWithCoffee () {
coroutineScope {
coroutineScope {
launch {
bathTime ()
}
launch {
boilingWater ()
}
}
launch {
preparingCoffee ()
}
}
}
上述代码的输出和前一个代码相同。
async Builder 如果我们想从协程的执行中返回一个值怎么办?例如,让我们定义两个新的挂起函数:前者产生我们准备的咖啡混合物。同时,后者返回烤面包:
suspend fun preparingJavaCoffee (): String {
logger . info ( "Preparing coffee" )
delay ( 500L )
logger . info ( "Coffee prepared" )
return "Java coffee"
}
suspend fun toastingBread (): String {
logger . info ( "Toasting bread" )
delay ( 1000L )
logger . info ( "Bread toasted" )
return "Toasted bread"
}
幸运的是,库提供了一种让协程返回值的方法。我们可以使用 async构建器 创建一个返回值的协程。具体来说,它会产生一个 Deferred<T> 类型的值,其行为或多或少类似于 java Future<T> 。在 Deferred<T> 类型的对象上,我们可以调用 await方法 等待协程完成并获取返回值。库还将async构建器定义为 CoroutineScope 扩展方法:
public fun < T > CoroutineScope . async (
context : CoroutineContext = EmptyCoroutineContext ,
start : CoroutineStart = CoroutineStart . DEFAULT ,
block : suspend CoroutineScope .() -> T
): Deferred < T >
让我们看看如何使用它来返回我们准备的咖啡和烤面包的混合:
suspend fun breakfastPreparation () {
coroutineScope {
val coffee : Deferred < String > = async {
preparingJavaCoffee ()
}
val toast : Deferred < String > = async {
toastingBread ()
}
logger . info ( "I'm eating ${coffee.await()} and ${toast.await()}" )
}
}
如果我们查看日志,我们可以看到两个协程的执行仍然是并发的。最后一条日志等待两个协程完成后打印,最终消息:
21:56:46.091 [main] INFO CoroutinesPlayground - Starting the morning routine
21:56:46.253 [DefaultDispatcher-worker-1 @coroutine#1] INFO CoroutinesPlayground - Preparing coffee
21:56:46.258 [DefaultDispatcher-worker-2 @coroutine#2] INFO CoroutinesPlayground - Toasting bread
21:56:46.758 [DefaultDispatcher-worker-1 @coroutine#1] INFO CoroutinesPlayground - Coffee prepared
21:56:47.263 [DefaultDispatcher-worker-1 @coroutine#2] INFO CoroutinesPlayground - Bread toasted
21:56:47.263 [DefaultDispatcher-worker-1 @coroutine#2] INFO CoroutinesPlayground - I'm eating Java coffee and Toasted bread
21:56:47.263 [DefaultDispatcher-worker-1 @coroutine#2] INFO CoroutinesPlayground - Ending the morning routine
协作调度 到这里,我们应该对协程的一些基础知识有所了解了。然而,我们仍然需要讨论协程的一个重要方面:协作调度。
协程调度模型与 Java 采用的Threads抢占式调度模型有很大不同。在抢占式调度中,操作系统决定何时从一个线程切换到另一个线程。在协作式调度中, 协程本身决定何时将控制权交给另一个协程 。
在 Kotlin 中,协程决定放弃控制权并到达挂起函数。只有此时执行它的线程才会被释放并允许运行另一个协程。
如果我们注意到,在迄今为止看到的日志中,执行控制在调用delay挂起函数时总是会发生变化。但是,为了更好地理解它,让我们看另一个示例。让我们定义一个新的挂起函数来模拟执行一个非常长时间运行的任务:
suspend fun workingHard () {
logger . info ( "Working" )
while ( true ) {
// Do nothing
}
delay ( 100L )
logger . info ( "Work done" )
}
无限循环会阻止函数到达delay挂起函数,因此协程永远不会放弃控制权。现在,我们定义另一个挂起函数与前一个函数并发执行:
suspend fun takeABreak () {
logger . info ( "Taking a break" )
delay ( 1000L )
logger . info ( "Break done" )
}
最后,让我们将所有内容整合到一个新的挂起函数中,该函数在两个专用协程中运行前两个函数。为了确保我们能看到协作调度的效果,我们将执行协程的线程池限制为单个线程:
@OptIn ( ExperimentalCoroutinesApi :: class )
suspend fun workingHardRoutine () {
val dispatcher : CoroutineDispatcher = Dispatchers . Default . limitedParallelism ( 1 )
coroutineScope {
launch ( dispatcher ) {
workingHard ()
}
launch ( dispatcher ) {
takeABreak ()
}
}
}
表示CoroutineDispatcher用于执行协程的线程池。该limitedParallelism函数是接口的扩展方法CoroutineDispatcher,用于 将线程池中的线程数限制为给定值 。由于这是一个实验性 API,因此我们需要用@OptIn(ExperimentalCoroutinesApi::class)注释注释该函数以避免编译器警告。
我们在唯一可用的线程上启动了两个协程dispatcher,日志向我们展示了协作调度的效果:
08:46:04.804 [main] INFO CoroutinesPlayground - Starting the morning routine
08:46:04.884 [DefaultDispatcher-worker-2 @coroutine#1] INFO CoroutinesPlayground - Working
-- Running forever --
由于workingHard协程从未到达挂起函数,因此它永远不会交出控制权。然后,takeABreak协程永远不会被执行。相反,如果我们定义一个挂起函数,将控制权交还给调度程序,takeABreak协程将有机会被执行:
suspend fun workingConsciousness () {
logger . info ( "Working" )
while ( true ) {
delay ( 100L )
}
logger . info ( "Work done" )
}
@OptIn ( ExperimentalCoroutinesApi :: class )
suspend fun workingConsciousnessRoutine () {
val dispatcher : CoroutineDispatcher = Dispatchers . Default . limitedParallelism ( 1 )
coroutineScope {
launch ( dispatcher ) {
workingConsciousness ()
}
launch ( dispatcher ) {
takeABreak ()
}
}
}
现在,日志显示takeABreak协程 有机会执行 ,即使 workingConsciousness 永远运行,并且我们只有一个线程:
09:02:49.302 [main] INFO CoroutinesPlayground - Starting the morning routine
09:02:49.376 [DefaultDispatcher-worker-1 @coroutine#1] INFO CoroutinesPlayground - Working
09:02:49.382 [DefaultDispatcher-worker-1 @coroutine#2] INFO CoroutinesPlayground - Taking a break
09:02:50.387 [DefaultDispatcher-worker-1 @coroutine#2] INFO CoroutinesPlayground - Break done
-- Running forever --
我们可以使用协程来获取相同的日志workingHard,并向线程池中添加一个线程:
@OptIn ( ExperimentalCoroutinesApi :: class )
suspend fun workingHardRoutine () {
val dispatcher : CoroutineDispatcher = Dispatchers . Default . limitedParallelism ( 2 )
coroutineScope {
launch ( dispatcher ) {
workingHard ()
}
launch ( dispatcher ) {
takeABreak ()
}
}
}
由于我们有两个线程和两个协程,因此并发度现在为 2。照例,日志证实了该理论:coroutine#1在 上执行DefaultDispatcher-worker-1,coroutine#2在 上执行DefaultDispatcher-worker-2。
13:40:59.864 [main] INFO CoroutinesPlayground - Starting the morning routine
13:40:59.998 [DefaultDispatcher-worker-1 @coroutine#1] INFO CoroutinesPlayground - Working
13:41:00.003 [DefaultDispatcher-worker-2 @coroutine#2] INFO CoroutinesPlayground - Taking a break
13:41:01.010 [DefaultDispatcher-worker-2 @coroutine#2] INFO CoroutinesPlayground - Break done
-- Running forever --
协作式调度迫使我们在设计协程时非常小心。假设一个协程执行了一个阻塞底层线程的操作,比如 JDBC 调用。在这种情况下,它会阻止该线程执行任何其他协程。
因此,该库允许我们针对不同的操作使用不同的调度程序。主要有:
Dispatchers.Default是库使用的默认调度程序。它使用线程数等于可用处理器数的线程池。它是 CPU 密集型操作的正确选择。 Dispatchers.IO是用于 I/O 操作的调度程序。它使用线程池,线程数等于可用处理器数,或最多 64 个。它是 I/O 操作(例如网络调用或文件操作)的正确选择。 从线程池创建的 Dispatcher:可以CoroutineDispatcher使用线程池来创建我们的实例。我们可以轻松使用接口asCoroutineDispatcher的扩展功能Executor。但是,请注意,当我们不再需要底层线程池时,我们有责任将其关闭:val dispatcher = Executors.newFixedThreadPool(10).asCoroutineDispatcher() 如果我们同时拥有 CPU 密集型部分和阻塞部分,我们必须同时使用Dispatchers.Default 和 Dispatchers.IO ,并确保在默认调度程序上启动 CPU 密集型协程,在 IO 调度程序上启动阻塞代码。
协程的取消 当我们思考并发编程时,取消始终是一个棘手的话题。终止线程并突然停止任务的执行并不是一个好的做法。在停止任务之前,我们必须释放正在使用的资源,避免泄漏,并使系统处于一致状态。
我们可以想象,Kotlin 允许我们取消协程的执行。该库提供了一种机制来协作取消协程以避免出现问题。该Job类型提供了一个cancel取消协程执行的函数。但是,取消不是立即的,只有当协程到达暂停点时才会发生。该机制与我们在协作调度中看到的机制非常接近。
让我们看一个例子。我们想模拟一下我们在工作期间接到一个重要电话。我们忘记了我们最好的朋友的生日,我们想在商场关门前去买一份礼物:
suspend fun forgettingTheBirthDayRoutine () {
coroutineScope {
val workingJob = launch {
workingConsciousness ()
}
launch {
delay ( 2000L )
workingJob . cancel ()
workingJob . join ()
logger . info ( "I forgot the birthday! Let's go to the mall!" )
}
}
}
此代码片段中发生了很多事情。首先,我们启动了workingConsciousness协程并收集了相应的Job。我们使用了workingConsciousness挂起函数,因为它在无限循环内挂起,并调用该delay函数。
同时,我们启动另一个协程,该协程workingJob在 2 秒后调用 workingJob 的取消函数,并等待其完成。workingJob被取消,但workingConsciousness协程不会立即停止。它继续执行,直到 到达暂停点 ,然后被取消。由于我们想等待取消,我们调用了workingJob的join函数。
日志证实了这一理论。在 coroutine#1 启动后约 2 秒,coroutine#2打印了其日志,并且coroutine#1被取消:
21:36:04.205 [main] INFO CoroutinesPlayground - Starting the morning routine
21:36:04.278 [DefaultDispatcher-worker-1 @coroutine#1] INFO CoroutinesPlayground - Working
21:36:06.390 [DefaultDispatcher-worker-2 @coroutine#2] INFO CoroutinesPlayground - I forgot the birthday! Let's go to the mall!
21:36:06.391 [DefaultDispatcher-worker-2 @coroutine#2] INFO CoroutinesPlayground - Ending the morning routine
cancel和join配合使用的模式非常常见,因此 Kotlin 协程库为我们提供了一个cancelAndJoin结合这两种操作的函数。
正如我们所说,在 Kotlin 中,取消是一种合作行为。 如果协程从不暂停,则根本无法取消 。让我们改用suspend function来更改上述示例workingHard。在这种情况下,该workingHard函数从不暂停,因此我们预计workingJob无法取消:
suspend fun forgettingTheBirthDayRoutineWhileWorkingHard () {
coroutineScope {
val workingJob = launch {
workingHard ()
}
launch {
delay ( 2000L )
workingJob . cancelAndJoin ()
logger . info ( "I forgot the birthday! Let's go to the mall!" )
}
}
}
这次,我们的朋友将不会收到她的礼物。workingJob被取消,但workingHard函数没有停止,因为它从未到达暂停点。 日志再次证实了这一理论:
08:56:10.784 [main] INFO CoroutinesPlayground - Starting the morning routine
08:56:10.849 [DefaultDispatcher-worker-1 @coroutine#1] INFO CoroutinesPlayground - Working
-- Running forever --
在后台,该cancel函数将 设置Job为“正在取消”状态。在第一次到达暂停点时,运行时抛出一个CancellationException,协程最终被取消。这种机制使我们能够安全地清理协程使用的资源。我们可以实施许多策略来清理资源,但首先,我们需要在示例中释放资源。我们可以定义代表我们办公室办公桌的 Desk 类:
class Desk : AutoCloseable {
init {
logger . info ( "Starting to work on the desk" )
}
override fun close () {
logger . info ( "Cleaning the desk" )
}
}
该类Desk实现了AutoCloseable接口。因此,它是协程取消期间释放资源的绝佳选择。由于它实现了AutoCloseable,我们可以使用该use函数在代码块完成时自动关闭资源:
suspend fun forgettingTheBirthDayRoutineAndCleaningTheDesk () {
val desk = Desk ()
coroutineScope {
val workingJob = launch {
desk . use { _ ->
workingConsciousness ()
}
}
launch {
delay ( 2000L )
workingJob . cancelAndJoin ()
logger . info ( "I forgot the birthday! Let's go to the mall!" )
}
}
}
use 是 Kotlin 标准库中的一个扩展函数,主要用于自动管理需要关闭的资源(如文件、网络连接等)。它确保资源在使用完毕后被正确关闭,即使发生异常也不会遗漏。
正如预期的那样,在我们搬到商场之前,我们清理了桌子,日志也证实了这一点:
21:38:30.117 [main] INFO CoroutinesPlayground - Starting the morning routine
21:38:30.124 [main] INFO CoroutinesPlayground - Starting to work on the desk
21:38:30.226 [DefaultDispatcher-worker-1 @coroutine#1] INFO CoroutinesPlayground - Working
21:38:32.298 [DefaultDispatcher-worker-2 @coroutine#1] INFO CoroutinesPlayground - Cleaning the desk
21:38:32.298 [DefaultDispatcher-worker-2 @coroutine#2] INFO CoroutinesPlayground - I forgot the birthday! Let's go to the mall!
21:38:32.298 [DefaultDispatcher-worker-2 @coroutine#2] INFO CoroutinesPlayground - Ending the morning routine
我们还可以使用invokeOnCompletion取消上的函数在函数完成workingConsciousness Job后清理桌面:
suspend fun forgettingTheBirthDayRoutineAndCleaningTheDeskOnCompletion () {
val desk = Desk ()
coroutineScope {
val workingJob = launch {
workingConsciousness ()
}
workingJob . invokeOnCompletion { exception : Throwable ? ->
desk . close ()
}
launch {
delay ( 2000L )
workingJob . cancelAndJoin ()
logger . info ( "I forgot the birthday! Let's go to the mall!" )
}
}
}
我们可以看到,该invokeOnCompletion方法将可空异常作为输入参数。如果Job被取消,则异常为CancellationException。
取消的另一个特性是它会传播到子协程。 当我们取消一个协程时,我们会隐式取消它的所有子协程 。让我们看一个例子。白天,保持水分是必不可少的。我们可以使用 drinkWater 来喝水:
suspend fun drinkWater () {
while ( true ) {
logger . info ( "Drinking water" )
delay ( 1000L )
logger . info ( "Water drunk" )
}
}
然后,我们可以创建一个协程,并生成两个新的协程,分别用于工作和饮用水。最后,我们可以取消父协程,并且我们期望两个子协程也被取消:
suspend fun forgettingTheBirthDayWhileWorkingAndDrinkingWaterRoutine () {
coroutineScope {
val workingJob = launch {
launch {
workingConsciousness ()
}
launch {
drinkWater ()
}
}
launch {
delay ( 2000L )
workingJob . cancelAndJoin ()
logger . info ( "I forgot the birthday! Let's go to the mall!" )
}
}
}
正如预期的那样,当我们取消 时workingJob,我们也会取消并停止其子协程。以下是描述情况的日志:
13:18:49.143 [main] INFO CoroutinesPlayground - Starting the morning routine
13:18:49.275 [DefaultDispatcher-worker-2 @coroutine#2] INFO CoroutinesPlayground - Working
13:18:49.285 [DefaultDispatcher-worker-3 @coroutine#3] INFO CoroutinesPlayground - Drinking water
13:18:50.285 [DefaultDispatcher-worker-3 @coroutine#3] INFO CoroutinesPlayground - Water drunk
13:18:50.286 [DefaultDispatcher-worker-3 @coroutine#3] INFO CoroutinesPlayground - Drinking water
13:18:51.288 [DefaultDispatcher-worker-2 @coroutine#3] INFO CoroutinesPlayground - Water drunk
13:18:51.288 [DefaultDispatcher-worker-2 @coroutine#3] INFO CoroutinesPlayground - Drinking water
13:18:51.357 [DefaultDispatcher-worker-2 @coroutine#4] INFO CoroutinesPlayground - I forgot the birthday! Let's go to the mall!
13:18:51.357 [DefaultDispatcher-worker-2 @coroutine#4] INFO CoroutinesPlayground - Ending the morning routine
这就是协程取消的全部内容!
协程上下文 在关于continuation的部分和关于构建器的部分中,我们简要介绍了协程上下文的概念。此外,CoroutineScope保留对协程上下文的引用。你可以想象, 这是一种存储从父级传递给子级的信息的方法 ,以在内部开发结构并发性。
表示协程上下文的类型称为CoroutineContext,它是 Kotlin 核心库的一部分。这是一个有趣的类型,因为它表示元素的集合,但同时,每个元素都是一个集合:
public interface CoroutineContext
// But also
public interface Element : CoroutineContext
CoroutineContext 的实现与 Continuation<T> 类型一起放在 Kotlin 协程库中。在实际实现中,我们有CoroutineName,它代表协程的名称:
val name : CoroutineContext = CoroutineName ( "Morning Routine" )
此外,CoroutineDispatcher和Job类型实现了CoroutineContext接口。我们在上面的日志中看到的标识符是CoroutineId。当我们启用调试模式时,运行时会自动将此上下文添加到每个协程中。
由于 CoroutineContext 其行为类似于集合,因此该库还定义了向上下文添加元素的 + 运算符。因此,创建一个包含许多元素的新上下文非常简单:
val context : CoroutineContext = CoroutineName ( "Morning Routine" ) + Dispatchers . Default + Job ()
也可以使用以下函数从上下文中删除元素minusKey:
val newContext : CoroutineContext = context . minusKey ( CoroutineName )
我们应该记住,我们可以将上下文传递给构建器来更改所创建协程的行为。例如,假设我们想要创建一个使用 Dispatchers.Default 的特定名称的协程。在这种情况下,我们可以按如下方式执行:
suspend fun asynchronousGreeting () {
coroutineScope {
launch ( CoroutineName ( "Greeting Coroutine" ) + Dispatchers . Default ) {
logger . info ( "Hello Everyone!" )
}
}
}
我们在main函数内部运行一下,在日志中我们可以看到,这个协程以指定的名称创建,并在调度器中执行Default:
11:56:46.747 [DefaultDispatcher-worker-1 @Greeting Coroutine#1] INFO CoroutinesPlayground - Hello Everyone!
协程上下文也可以表现得像一个映射,因为我们可以使用与我们要检索的元素相对应的类型的名称来搜索和访问它包含的元素:
logger.info("Coroutine name: {}", context[CoroutineName]?.name)
上述代码打印了上下文中存储的协程名称(如果有)。CoroutineName方括号内的既不是类型也不是类。实际上,它引用了Key类的伴生对象,即只是一些 Kotlin 语法糖。
该库还定义了 EmptyCoroutineContext 空的协程上下文,我们可以将其用作“零”元素来创建新的自定义上下文。
因此,上下文是一种在协程之间传递信息的方式。任何父协程都会将其上下文提供给其子协程。子协程将值从父级复制到它们可以覆盖的上下文的新实例。让我们看一个没有覆盖的继承示例:
suspend fun coroutineCtxInheritance () {
coroutineScope {
launch ( CoroutineName ( "Greeting Coroutine" )) {
logger . info ( "Hello everyone from the outer coroutine!" )
launch {
logger . info ( "Hello everyone from the inner coroutine!" )
}
delay ( 200L )
logger . info ( "Hello again from the outer coroutine!" )
}
}
}
上述代码的日志如下,它突出显示两个协程共享相同的名称:
12:19:12.962 [DefaultDispatcher-worker-1 @Greeting Coroutine#1] INFO CoroutinesPlayground - Hello everyone from the outer coroutine!
12:19:12.963 [DefaultDispatcher-worker-2 @Greeting Coroutine#2] INFO CoroutinesPlayground - Hello everyone from the inner coroutine!
12:19:12.963 [DefaultDispatcher-worker-1 @Greeting Coroutine#1] INFO CoroutinesPlayground - Hello again from the outer coroutine!
正如我们所说的,如果我们愿意,我们可以从子协程覆盖上下文中的值:
suspend fun coroutineCtxOverride () {
coroutineScope {
launch ( CoroutineName ( "Greeting Coroutine" )) {
logger . info ( "Hello everyone from the outer coroutine!" )
launch ( CoroutineName ( "Greeting Inner Coroutine" )) {
logger . info ( "Hello everyone from the inner coroutine!" )
}
delay ( 200L )
logger . info ( "Hello again from the outer coroutine!" )
}
}
}
上面代码的log显示了父协程被覆盖了,但是父上下文中的值还是原来的:
12:22:33.869 [DefaultDispatcher-worker-1 @Greeting Coroutine#1] INFO CoroutinesPlayground - Hello everyone from the outer coroutine!
12:22:33.870 [DefaultDispatcher-worker-2 @Greeting Inner Coroutine#2] INFO CoroutinesPlayground - Hello everyone from the inner coroutine!
12:22:34.077 [DefaultDispatcher-worker-1 @Greeting Coroutine#1] INFO CoroutinesPlayground - Hello again from the outer coroutine!
12:22:34.078 [DefaultDispatcher-worker-1 @Greeting Coroutine#1] INFO CoroutinesPlayground - Ending the morning routine
上下文继承规则的唯一例外是Job上下文实例。每个新协程都会创建自己的Job实例,该实例不会从父级继承。而其他上下文元素(例如CoroutineName或调度程序)则从父级继承。
首先要了解的就是CPS转换。
CPS转换 在Kotlin协程中,挂起函数的执行是通过 Continuation Passing Style (CPS)转换 来实现的。CPS转换是一种将函数式编程中的函数调用转换为可传递的 Continuation 对象的过程。这里的转换是Kotlin编译器实现的,在跨平台属性上,也保证了流程的一致性。
CPS转换调用的过程如下:
当一个函数被调用时,它的参数和返回值会被封装在一个Continuation对象中。 函数的执行过程中,遇到挂起操作时,会将当前的Continuation对象传递给挂起函数。 挂起函数执行完毕后,会将结果封装在一个新的Continuation对象中,并将其传递给原始的Continuation对象。 原始的Continuation对象会继续执行,直到所有的挂起操作都完成。 假设我们有一个简单的suspend函数,它模拟了一个异步操作:
suspend fun fetchData (): String {
delay ( 1000 ) // 模拟耗时操作
return "Data fetched"
}
在CPS转换后,这个函数可能会被转换为类似以下的形式:
fun fetchData ( continuation : Continuation < String >) {
delay ( 1000 , object : Continuation < Unit > {
override val context : CoroutineContext = continuation . context
override fun resumeWith ( result : Result < Unit >) {
continuation . resume ( "Data fetched" )
}
})
}
在这个转换后的函数中,fetchData不再直接返回结果,而是通过continuation.resume方法将结果传递给调用者。简单来说,CPS其实就是函数通过回调传递结果的一种方式。
Kotlin协程通过将异步流程拆解为一系列 挂起点 ,对含有 suspend 关键字的函数进行了 CPS转换 ,即Continuation Passing Style转换,使其能够 接收Continuation对象 作为参数,并在异步操作完成后通过调用 Continuation 的恢复方法来继续执行协程。
在编译后的字节码中,协程的状态会被转换为状态机的形式,每个挂起点对应状态机的一个状态。当协程挂起时,它的执行状态会被保存在Continuation对象中,包括局部变量上下文和执行位置。
Continuation Continuation (续体)是一个保存协程状态的对象,它记录了协程挂起的位置以及局部变量上下文,使得协程可以在任何时候从上次挂起的地方继续执行。Continuation是一个接口,它定义了 resumeWith 方法,用于恢复协程的执行。
interface Continuation < in T > {
val context : CoroutineContext
fun resumeWith ( result : Result < T >) //result 为返回的结果
}
续体是一个较为抽象的概念,简单来说它包装了协程在挂起之后应该继续执行的代码;在编译的过程中,一个完整的协程被分割切块成一个又一个续体。 在suspend函数或者 await 函数的挂起结束以后,它会调用 continuation 参数的 resumeWith 函数,来恢复执行suspend函数或者await 函数后面的代码。 CPS转换 使得协程能够在不阻塞线程的情况下执行异步操作。当协程挂起时,线程可以被释放去执行其他任务,从而提高了系统的并发性能。此外,CPS转换使得协程的挂起和恢复操作对开发者来说是透明的,开发者可以像编写同步代码一样编写异步代码。
发生 CPS 变换的函数,返回值类型变成了 Any?,这是因为这个函数在发生变换后,除了要返回它本身的返回值,还要返回一个标记CoroutineSingletons.COROUTINE_SUSPENDED,为了适配各种可能性,CPS 转换后的函数返回值类型就只能是 Any?了。
协程的启动 下面跟随启动,挂起,恢复的流程,从源码层面看看协程的核心原理。
测试代码入口:
object CoroutineExample {
private val TAG : String = "CoroutineExample"
fun main (){
// 启动协程,分析入口
GlobalScope . launch ( Dispatchers . Main ) {
request ()
}
}
private suspend fun request (): String {
delay ( 2000 )
Log . e ( TAG , "request complete" )
return "result from request"
}
}
从 CoroutineScope.launch 开始:
public fun CoroutineScope . launch (
context : CoroutineContext = EmptyCoroutineContext ,
start : CoroutineStart = CoroutineStart . DEFAULT ,
block : suspend CoroutineScope .() -> Unit
): Job {
val newContext = newCoroutineContext ( context )
val coroutine = if ( start . isLazy ){
LazyStandaloneCoroutine ( newContext , block )
} else {
StandaloneCoroutine ( newContext , active = true )
}
coroutine . start ( start , coroutine , block )
return coroutine
}
参数一context:协程上下文,并不是我们平时理解的Android中的上下文,它是一种key-value数据结构。可以传入Main用于主线程调度。 参数二start:启动模式,此处我们没有传值则为默认值(DEFAULT),共有三种启动模式。DEFAULT:默认模式,创建即启动协程,可随时取消; ATOMIC:自动模式,创建即启动协程,启动前不可取消; LAZY:延迟启动模式,只有当调用start方法时才能启动。 参数三block:协程真正执行的代码块,即上面例子中launch{}闭包内的代码块。 SuspendLambda CoroutineScope.launch中第三个参数类型为suspend CoroutineScope.() -> Unit函数,这是怎么来的呢?我们编写代码的时候并没有这个东西,其实它由编译器生成的,我们的 block代码块 经过编译器编译后会生成一个 继承Continuation 的 类SuspendLambda 。一起看下反编译的java代码,为了关注主要逻辑方便理解,去掉了一些无关代码大概代码如下:
public final void main () {
BuildersKt . launch $default (( CoroutineScope ) GlobalScope . INSTANCE , ( CoroutineContext ) Dispatchers . getMain (), ( CoroutineStart ) null , ( Function2 )( new Function2 (( Continuation ) null ) {
int label ;
@Nullable
public final Object invokeSuspend ( @NotNull Object $result ) {
Object var2 = IntrinsicsKt . getCOROUTINE_SUSPENDED ();
switch ( this . label ) {
case 0 :
ResultKt . throwOnFailure ( $result );
CoroutineExample var10000 = CoroutineExample . this ;
this . label = 1 ;
if ( var10000 . request ( this ) == var2 ) {
return var2 ;
}
break ;
case 1 :
ResultKt . throwOnFailure ( $result );
break ;
default :
throw new IllegalStateException ( "call to 'resume' before 'invoke' with coroutine" );
}
return Unit . INSTANCE ;
}
···
}
从上面反编译的java代码中好像并不能很好的看出来协程中的block代码块具体编译长什么样子,但可以确定他是编译成了 Continuation类 ,因为我们可以看到实现的 invokeSuspend 方法实际是来自BaseContinuationImpl,而BaseContinuationImpl的父类就是Continuation。这个继承关系我们后面再说。既然从反编译的java代码中看的不明显,我们直接看上面例子的字节码文件,其中可以很明显的看到这样一段代码:
final class com/imile/pda/CoroutineExample$main$1 extends kotlin/coroutines/jvm/internal/SuspendLambda implements kotlin/jvm/functions/Function2
这下恍然大悟,launch函数的第三个参数,即协程中的 block代码块 是一个编译后 继承了SuspendLambda并且实现了Function2的实例 。
SuspendLambda 本质上是一个 Continuation ,前面我们已经说过 Continuation 是一个有着恢复操作的接口,其 resume 方法可以恢复协程的执行。
SuspendLambda继承机构如下:
- Continuation: 续体,恢复协程的执行
- BaseContinuationImpl: 实现 resumeWith(Result) 方法,控制状态机的执行,定义了 invokeSuspend 抽象方法
- ContinuationImpl: 增加 intercepted 拦截器,实现线程调度等
- SuspendLambda: 封装协程体代码块
- 协程体代码块生成的子类: 实现 invokeSuspend 方法,其内实现状态机流转逻辑
每一层封装都对应添加了不同的功能,我们先忽略掉这些功能细节,着眼于我们的主线,继续跟进 launch 函数执行过程,由于第二个参数是默认值(DEFAULT),所以创建的是 StandaloneCoroutine , 最后启动协程:
// 启动协程
coroutine.start(start, coroutine, block)
// 启动协程
public fun <R> start(start: CoroutineStart, receiver: R, block: suspend R.() -> T) {
start(block, receiver, this)
}
上面 coroutine.start 的调用涉及到运算符重载,实际上会调到 CoroutineStart.invoke() 方法:
public operator fun < R , T > invoke ( block: suspend R .() -> T , receiver: R , completion: Continuation < T >): Unit =
when ( this ) {
DEFAULT -> block . startCoroutineCancellable ( receiver , completion )
ATOMIC -> block . startCoroutine ( receiver , completion )
UNDISPATCHED -> block . startCoroutineUndispatched ( receiver , completion )
LAZY -> Unit // will start lazily
}
这里启动方式为默认的 DEFAULT ,所以接着往下看:
internal fun < R , T > ( suspend ( R ) -> T ). startCoroutineCancellable (
receiver : R , completion : Continuation < T >,
onCancellation : (( cause : Throwable ) -> Unit )? = null
) = runSafely ( completion ) {
createCoroutineUnintercepted ( receiver , completion )
. intercepted ()
. resumeCancellableWith ( Result . success ( Unit ), onCancellation )
}
整理下调用链如下:
coroutine.start(start, coroutine, block)
-> CoroutineStart.start(block, receiver, this)
-> CoroutineStart.invoke(block: suspend R.() -> T, receiver: R, completion: Continuation<T>)
-> block.startCoroutineCancellable(receiver, completion)
->
createCoroutineUnintercepted(receiver,completion).intercepted().resumeCancellableWith(Result.success(Unit), onCancellation)
最后走到 createCoroutineUnintercepted(receiver,completion).intercepted().resumeCancellableWith(Result.success(Unit), onCancellation) ,这里创建了一个协程,并链式调用 intercepted、resumeCancellable 方法,利用协程上下文中的 ContinuationInterceptor 对协程的执行进行拦截,intercepted 实际上调用的是 ContinuationImpl 的 intercepted 方法:
internal abstract class ContinuationImpl (
completion : Continuation < Any ?>?,
private val _context : CoroutineContext ?
) : BaseContinuationImpl ( completion ) {
.. .
public fun intercepted (): Continuation < Any ?> =
intercepted
?: ( context [ ContinuationInterceptor ] ?. interceptContinuation ( this ) ?: this )
. also { intercepted = it }
.. .
}
context[ContinuationInterceptor]?.interceptContinuation调用的是 CoroutineDispatcher 的 interceptContinuation 方法:
public final override fun < T > interceptContinuation ( continuation : Continuation < T >): Continuation < T > =
DispatchedContinuation ( this , continuation )
内部创建了一个 DispatchedContinuation 可分发的协程实例,我们继续进到看resumeCancellableWith 方法:
internal class DispatchedContinuation < in T >(
@JvmField val dispatcher : CoroutineDispatcher ,
@JvmField val continuation : Continuation < T >
) : DispatchedTask < T >( MODE_UNINITIALIZED ), CoroutineStackFrame , Continuation < T > by continuation {
.. .
public fun < T > Continuation < T >. resumeCancellableWith (
result : Result < T >,
onCancellation : (( cause : Throwable ) -> Unit )? = null
): Unit = when ( this ) {
// 判断是否是DispatchedContinuation 根据我们前面的代码追踪 这里是DispatchedContinuation
is DispatchedContinuation -> resumeCancellableWith ( result , onCancellation )
else -> resumeWith ( result )
}
inline fun resumeCancellableWith (
result : Result < T >,
noinline onCancellation : (( cause : Throwable ) -> Unit )?
) {
val state = result . toState ( onCancellation )
// 判断是否需要线程调度
// 由于我们之前使用的是 `GlobalScope.launch(Main)` Android主线程调度器所以这里为true
if ( dispatcher . isDispatchNeeded ( context )) {
_state = state
resumeMode = MODE_CANCELLABLE
dispatcher . dispatch ( context , this )
} else {
executeUnconfined ( state , MODE_CANCELLABLE ) {
if (! resumeCancelled ( state )) {
resumeUndispatchedWith ( result )
}
}
}
}
.. .
}
最终走到 dispatcher.dispatch(context, this) 而这里的 dispatcher 就是通过工厂方法创建的 HandlerDispatcher ,dispatch() 函数第二个参数this是一个runnable这里为 DispatchedTask
HandlerDispatcher internal class HandlerContext private constructor (
private val handler : Handler ,
private val name : String ?,
private val invokeImmediately : Boolean
) : HandlerDispatcher (), Delay {
.. .
// 最终执行这里的 dispatch方法 而handler则是android中的 MainHandler
override fun dispatch ( context : CoroutineContext , block : Runnable ) {
if (! handler . post ( block )) {
cancelOnRejection ( context , block )
}
}
.. .
}
这里借用 Android 的主线程消息队列来在主线程中执行 block Runnable而这个 Runnable 即为 DispatchedTask:
internal abstract class DispatchedTask < in T >(
@JvmField public var resumeMode : Int
) : SchedulerTask () {
.. .
public final override fun run () {
.. .
withContinuationContext ( continuation , delegate . countOrElement ) {
.. .
if ( job != null && ! job . isActive ) {
val cause = job . getCancellationException ()
cancelCompletedResult ( state , cause )
// 异常情况下
continuation . resumeWithStackTrace ( cause )
} else {
if ( exception != null ) {
// 异常情况下
continuation . resumeWithException ( exception )
} else {
// step1:正常情况下走到这一步
continuation . resume ( getSuccessfulResult ( state ))
}
}
}
.. .
}
}
//step2:这是Continuation的扩展函数,内部调用了resumeWith()
@InlineOnly public inline fun < T > Continuation < T >. resume ( value : T ): Unit =
resumeWith ( Result . success ( value ))
//step3:最终会调用到BaseContinuationImpl的resumeWith()方法中
internal abstract class BaseContinuationImpl ( .. .) {
// 实现 Continuation 的 resumeWith,并且是 final 的,不可被重写
public final override fun resumeWith ( result : Result < Any ?>) {
.. .
val outcome = invokeSuspend ( param )
.. .
}
// 由编译生成的协程相关类来实现,例如 CoroutineExample$main$1
protected abstract fun invokeSuspend ( result : Result < Any ?>): Any ?
}
最终调用到 continuation.resumeWith() 而 resumeWith() 中会调用 invokeSuspend,即之前编译器生成的 SuspendLambda 中的 invokeSuspend 方法:
@Nullable
public final Object invokeSuspend ( @NotNull Object $result ) {
Object var2 = IntrinsicsKt . getCOROUTINE_SUSPENDED ();
switch ( this . label ) {
case 0 :
ResultKt . throwOnFailure ( $result );
CoroutineExample var10000 = CoroutineExample . this ;
this . label = 1 ;
if ( var10000 . request ( this ) == var2 ) {
return var2 ;
}
break ;
case 1 :
ResultKt . throwOnFailure ( $result );
break ;
}
}
这段代码是一个状态机机制,每一个挂起点都是一种状态,协程恢复只是跳转到下一个状态,挂起点将执行过程分割成多个片段,利用状态机的机制保证各个片段按顺序执行。
可以看到 协程非阻塞的异步底层实现其实就是一种Callback回调 (这一点我们在介绍Continuation时有提到过),只不过有多个挂起点时就会有多个Callback回调,这里协程把多个Callback回调封装成了一个状态机。
以上就是协程的启动过程,下面我们再来看下协程中的重点挂起和恢复。
协程的挂起与恢复 协程的挂起和恢复有两个关键方法 : invokeSuspend() 和 resumeWith(Result)。我们以上一节中的例子,反编译后逆向剖析协程的挂起和恢复,先整体看下是怎样的一个过程。
suspend fun reqeust (): String {
delay ( 2000 )
return "result from request"
}
反编译后的代码如下(为了方便理解,代码有删减和修改):
//1.函数返回值由String变成Object,入参也增加了Continuation参数
public final Object reqeust ( @NotNull Continuation completion ) {
//2.通过completion创建一个ContinuationImpl,并且复写了invokeSuspend()
Object continuation ;
if ( completion instanceof < undefinedtype >){
continuation = < undefinedtype > completion
} else {
continuation = new ContinuationImpl ( completion ) {
Object result ;
int label ; //初始值为0
@Nullable
public final Object invokeSuspend ( @NotNull Object $ result ) {
this . result = $ result ;
this . label |= Integer . MIN_VALUE ;
return request ( this ); //又调用了request()方法
}
};
}
Object $ result = ( continuation ). result ;
Object var4 = IntrinsicsKt . getCOROUTINE_SUSPENDED ();
//状态机
//3.方法被恢复的时候又会走到这里,第一次进入case 0分支,label的值从0变为1,第二次进入就会走case 1分支
switch ( continuation . label ) {
case 0 :
ResultKt . throwOnFailure ( $ result );
continuation . label = 1 ;
//4.delay()方法被suspend修饰,传入一个continuation回调,返回一个object结果。这个结果要么是`COROUTINE_SUSPENDED`,否则就是真实结果。
Object delay = DelayKt . delay ( 2000L , continuation )
if ( delay == var4 ) {
//如果是 COROUTINE_SUSPENDED 则直接return,就不会往下执行了,request()被暂停了。
// 如果不是COROUTINE_SUSPENDED,则说明不需要挂起,就会break跳出switch语句。正常返回继续往下执行后续外部代码。
return var4 ;
}
break ;
case 1 :
ResultKt . throwOnFailure ( $ result );
break ;
default :
throw new IllegalStateException ( "call to 'resume' before 'invoke' with coroutine" );
}
return "result from request" ;
}
ResultKt.throwOnFailure($result) 是 Kotlin 协程中的一个重要方法,主要用于处理协程的异常情况。它的主要作用是: (1)检查异常:它会检查传入的 $result 对象,如果这个对象是一个异常(即协程执行过程中抛出的异常),它会立即抛出这个异常。 (2)确保正常执行:如果 $result 不是异常,则继续正常执行后续代码。
挂起过程 函数返回值由 String 变成 Object,编译器自动增加了Continuation参数,相当于帮我们添加Callback。
根据 completion 创建了一个 ContinuationImpl(如果已经创建就直接用,避免重复创建),复写了 invokeSuspend() 方法,在这个方法里面它又调用了 request() 方法,这里又调用了一次自己(是不是很神奇),并且把 continuation 传递进去。
在 switch 语句中,label 的默认初始值为 0,第一次会进入 case 0 分支,delay() 是一个挂起函数,传入上面的 continuation 参数,会有一个 Object 类型的返回值。这个结果要么是COROUTINE_SUSPENDED,否则就是真实结果。
DelayKt.delay(2000, continuation)的返回结果如果是 COROUTINE_SUSPENDED , 则直接 return ,那么方法执行就被结束了,方法就被挂起了。
函数即便被 suspend 修饰了,但是也未必会挂起。需要里面的代码编译后有返回值为 COROUTINE_SUSPENDED 这样的标记位才可以。
协程的挂起实际是方法的挂起,本质是return。
恢复过程 因为 delay() 是 IO操作,在2000ms后就会通过传递给它的 continuation 回调回来。
回调到 ContinuationImpl 类的 resumeWith() 方法,会再次调用 invokeSuspend() 方法,进而再次调用 request() 方法。
即反编译代码中的这一段:
Object continuation ;
if ( completion instanceof < undefinedtype >){
continuation = < undefinedtype > completion
} else {
continuation = new ContinuationImpl ( completion ) {
Object result ;
int label ; //初始值为0
@Nullable
public final Object invokeSuspend ( @NotNull Object $result ) {
this . result = $result ;
this . label |= Integer . MIN_VALUE ;
return request ( this ); //又调用了request()方法
}
};
}
程序会再次进入switch语句,由于第一次在 case 0 时把 label = 1 赋值为1,所以这次会进入 case 1 分支,检查无异常之后,再次 break ,并且返回了结果result from request。
并且 request() 的返回值作为 invokeSuspend() 的返回值返回。重新被执行的时候就代表着方法被恢复了。
看到大家一定会疑问, 步骤2中 invokeSuspend() 是如何被再次调用呢? 我们都知道 ContinuationImpl 的父类是 BaseContinuationImpl,实际上ContinuationImpl中调用的resumeWith()是来自父类。
BaseContinuationImpl internal abstract class BaseContinuationImpl (
public val completion : Continuation < Any ?>?
) : Continuation < Any ?>, CoroutineStackFrame , Serializable {
//这个实现是最终的,用于展开 resumeWith 递归。
public final override fun resumeWith ( result : Result < Any ?>) {
var current = this
var param = result
while ( true ) {
with ( current ) {
val completion = completion !!
val outcome : Result < Any ?> =
try {
// 1.调用 invokeSuspend()方法执行,执行协程的真正运算逻辑,拿到返回值
val outcome = invokeSuspend ( param )
// 2.如果返回的还是COROUTINE_SUSPENDED则提前结束
if ( outcome == COROUTINE_SUSPENDED ) return
Result . success ( outcome )
} catch ( exception : Throwable ) {
Result . failure ( exception )
}
if ( completion is BaseContinuationImpl ) {
//3.如果 completion 是 BaseContinuationImpl,内部还有suspend方法,则会进入循环递归,继续执行和恢复
current = completion
param = outcome
} else {
//4.否则是最顶层的completion,则会调用resumeWith恢复上一层并且return
// 这里实际调用的是其父类 AbstractCoroutine 的 resumeWith 方法
completion . resumeWith ( outcome )
return
}
}
}
}
}
实际上任何一个挂起函数它在恢复的时候都会调到 BaseContinuationImpl 的 resumeWith() 方法里面。
一但 invokeSuspend() 方法被执行,那么 request() 又会再次被调用, invokeSuspend() 就会拿到 request() 的返回值,在 ContinuationImpl 里面根据 val outcome = invokeSuspend() 的返回值来判断我们的 request() 方法恢复了之后的操作。
如果 outcome 是 COROUTINE_SUSPENDED 常量(可能挂起函数中又返回了一个挂起函数),说明你即使被恢复了,执行了一下, if (outcome == COROUTINE_SUSPENDED) return但是立马又被挂起了,所以又 return 了。
如果本次恢复 outcome 是一个正常的结果,就会走到 completion.resumeWith(outcome),当前被挂起的方法已经被执行完了,实际调用的是其父类 AbstractCoroutine 的 resumeWith 方法,那么协程就恢复了。
我们知道 request() 肯定是会被协程调用的(从上面反编译代码知道会传递一个Continuation completion参数),request() 方法恢复完了就会让协程completion.resumeWith()去恢复,所以说协程的恢复是方法的恢复,本质其实是 callback(resumeWith) 回调。
一张图总结一下:
协程的核心是挂起——恢复,挂起——恢复的本质是return & callback回调
协程挂起 我们说过协程启动后会调用到上面这个 resumeWith() 方法,接着调用其 invokeSuspend() 方法:
当 invokeSuspend() 返回 COROUTINE_SUSPENDED 后,就直接 return 终止执行了,此时协程被挂起。 当 invokeSuspend() 返回非 COROUTINE_SUSPENDED 后,说明协程体执行完毕了,对于 launch 启动的协程体,传入的 completion 是 AbstractCoroutine 子类对象,最终会调用其 AbstractCoroutine.resumeWith() 方法做一些状态改变之类的收尾逻辑。至此协程便执行完毕了。
协程恢复 这里我们接着看上面第一条:协程执行到挂起函数被挂起后,当这个挂起函数执行完毕后是怎么恢复协程的,以下面挂起函数为例:
private suspend fun login () = withContext ( Dispatchers . IO ) {
Thread . sleep ( 2000 )
return @withContext true
}
通过反编译可以看到上面挂起函数中的函数体也被编译成了 SuspendLambda 的子类,创建其实例时也需要传入 Continuation 续体参数(调用该挂起函数的协程所在续体)。贴下 withContext 的源码:
public suspend fun < T > withContext (
context : CoroutineContext ,
block : suspend CoroutineScope .() -> T
): T {
return suspendCoroutineUninterceptedOrReturn sc@ { uCont ->
// 创建 new context
val oldContext = uCont . context
val newContext = oldContext + context
// 检查新上下文是否作废
newContext . ensureActive ()
// 新上下文与旧上下文相同
if ( newContext === oldContext ) {
val coroutine = ScopeCoroutine ( newContext , uCont )
return @sc coroutine . startUndispatchedOrReturn ( coroutine , block )
}
// 新调度程序与旧调度程序相同
if ( newContext [ ContinuationInterceptor ] == oldContext [ ContinuationInterceptor ]) {
val coroutine = UndispatchedCoroutine ( newContext , uCont )
// 上下文有变化,所以这个线程需要更新
withCoroutineContext ( newContext , null ) {
return @sc coroutine . startUndispatchedOrReturn ( coroutine , block )
}
}
// 使用新的调度程序
val coroutine = DispatchedCoroutine ( newContext , uCont )
block . startCoroutineCancellable ( coroutine , coroutine )
coroutine . getResult ()
}
}
首先调用了 suspendCoroutineUninterceptedOrReturn 方法,看注释知道可以通过它来获取到当前的续体对象 uCont, 接着有几条分支调用,但最终都是会通过续体对象来创建挂起函数体对应的 SuspendLambda 对象,并执行其 invokeSuspend() 方法,在其执行完毕后调用 uCont.resume() 来恢复协程,具体逻辑大家感兴趣可以自己跟代码,与前面大同小异。
至于其他的顶层挂起函数如 await(), suspendCoroutine(), suspendCancellableCoroutine() 等,其内部也是通过 suspendCoroutineUninterceptedOrReturn() 来获取到当前的续体对象,以便在挂起函数体执行完毕后,能通过这个续体对象恢复协程执行。
Desktop平台举例分析挂起恢复(Kotlin 2.1.0) Kotlin测试代码如下:
class MySimpleTest {
suspend fun stephenTest (): String {
delay ( 500L )
return "result From stephenTest"
}
}
fun callFromOutside () {
CoroutineScope ( Dispatchers . IO ). launch {
val result = MySimpleTest (). stephenTest ()
println ( result )
}
}
在callFromOutside函数中,我们创建了一个协程作用域,并在其中启动了一个协程。该协程将调用stephenTest函数。而stephenTest函数是一个挂起函数,它会暂停该协程的执行,直到delay函数返回。
将这个片段反编译成java代码,删掉导包和元数据注解信息等,分析过程见注释流程号:
public final class MySimpleTest {
public static final int $stable ;
@Nullable
// (8)stephenTest函数本来是无参的,现在有一个Continuation类型的参数
// 这个就是外部调用代码块封装成的实例,stephenTest方法执行完毕,需要继续往下执行的代码都在这个对象里面
public final Object stephenTest ( @NotNull Continuation $completion ) {
Continuation $continuation ;
// (9)label20: 是一个Java中的标签(label),主要用于控制流程跳转。在这里它被用来实现协程的挂起和恢复机制
label20: {
if ( $completion instanceof < undefinedtype >) {
$continuation = (< undefinedtype >) $completion ;
// (10)用于检查当前协程是否处于挂起状态。Integer.MIN_VALUE 是一个特殊的标志位,用于标记协程是否被挂起。
// 它的值是10000000 00000000 00000000 00000000
// label首次传进来是1,即00000000 00000000 00000000 00000001,和Integer.MIN_VALUE按位与的结果为0,表示需要挂起,会走到11步,基于外部传入的 completion 对象创建一个新的ContinuationImpl对象
//=======================分割线====================
// (16)这里的label在15步被赋值成了10000000 00000000 00000000 00000001,按位与的结果是Integer.MIN_VALUE,即条件检查结果为真(即 != 0)
// 10000000 00000000 00000000 00000001减去Integer.MIN_VALUE,结果是1,即00000000 00000000 00000000 00000001
// 并将label20标签跳出循环,继续往下执行stephenTest的switch状态判断
if (( $continuation . label & Integer . MIN_VALUE ) != 0 ) {
$continuation . label -= Integer . MIN_VALUE ;
break label20 ;
}
}
// (11)开始创建关于stephenTest代码块的ContinuationImpl对象,用于传递给下一个suspend函数
$continuation = new ContinuationImpl ( $completion ) {
// $FF: synthetic field
Object result ;
// 初始值为0
int label ;
@Nullable
// (13)delay执行完,调用resumeWith,触发这个invokeSuspend方法
public final Object invokeSuspend ( @NotNull Object $result ) {
this . result = $result ;
//(14)将label = 1和Integer.MIN_VALUE按位或,
// 运算的结果是 10000000 00000000 00000000 00000001(即 -2147483647)
this . label |= Integer . MIN_VALUE ;
//(15)重入调用stephenTest函数,这次是传入 $continuation 自己作为参数。
return MySimpleTest . this . stephenTest (( Continuation ) this );
}
};
}
Object $result = $continuation . result ;
Object var4 = IntrinsicsKt . getCOROUTINE_SUSPENDED ();
// (17) 本轮调用中,label值为1,检查无异常后,就会返回这个字符串
// "result From stephenTest"
switch ( $continuation . label ) {
case 0 :
ResultKt . throwOnFailure ( $result );
$continuation . label = 1 ;
// (12)调用delay函数,之后就和外部调用的(3)-(7)步流程一样.
// 传入ContinuationImpl对象,delay函数内部会判断是否需要挂起,如果需要挂起,就return掉本轮stephenTest方法的调用
// 进入了delay内部执行,等500ms过后,调用外部传进来的ContinuationImpl对象的 resumeWith 函数回调
// 而resumeWith方法,必然会调用到这个ContinuationImpl 对象自己的invokeSuspend方法,就跳转到第13步了
if ( DelayKt . delay ( 500L , $continuation ) == var4 ) {
return var4 ;
}
break ;
case 1 :
ResultKt . throwOnFailure ( $result );
break ;
default :
throw new IllegalStateException ( "call to 'resume' before 'invoke' with coroutine" );
}
return "result From stephenTest" ;
}
}
// CoroutineTestKt.java
public final class CoroutineTestKt {
public static final void callFromOutside () {
// (1)分析入口,从最外部的调用开始
BuildersKt . launch $default ( CoroutineScopeKt . CoroutineScope (( CoroutineContext ) Dispatchers . getIO ()), ( CoroutineContext ) null , ( CoroutineStart ) null , new Function2 (( Continuation ) null ) {
// (2)函数代码块里的任务,被封装在了继承自Continuation的一个匿名内部类对象中
// launch开始后,进入就会调用其invoke方法,并首次执行invokeSuspend方法,这时候label为0
int label ;
// (18) 17步返回后,标志着 stephenTest 方法中 $continuation实例的invokeSuspend方法调用完毕
// 将调用completion的invokeSuspend方法
// (19)这时候外部的这个label值也已经为1了,就是继续往下执行了
public final Object invokeSuspend ( Object $result ) {
Object var3 = IntrinsicsKt . getCOROUTINE_SUSPENDED ();
Object var10000 ;
// (3)通过label来判断当前是到了哪一个状态
switch ( this . label ) {
case 0 :
// (4)首先检查异常
ResultKt . throwOnFailure ( $result );
// (5)创建一个MySimpleTest对象,并调用其stephenTest方法
var10000 = new MySimpleTest ();
// (6)将这个匿名内部类自己传进去,作为参数
Continuation var10001 = ( Continuation ) this ;
// 将label状态设置为1,等下次再次调用invokeSuspend就会走switch的1的分支
this . label = 1 ;
var10000 = ( MySimpleTest ) var10000 . stephenTest ( var10001 );
// (7) 如果 stephenTest 这个方法的返回值是COROUTINE_SUSPENDED,则表示该函数已暂停,我们也返回COROUTINE_SUSPENDED给调用者
// 通知这个函数是挂起函数,暂时不往下执行了
if ( var10000 == var3 ) {
return var3 ;
}
// 转到MySimpleTest这个类分析 ->(8)
break ;
case 1 :
ResultKt . throwOnFailure ( $result );
var10000 = ( MySimpleTest ) $result ;
break ;
default :
throw new IllegalStateException ( "call to 'resume' before 'invoke' with coroutine" );
}
// (20)挂起和恢复流程执行完毕,打印结果
String result = ( String ) var10000 ;
System . out . println ( result );
return Unit . INSTANCE ;
}
public final Continuation create ( Object value , Continuation $completion ) {
return ( Continuation )( new < anonymous constructor >( $completion ));
}
public final Object invoke ( CoroutineScope p1 , Continuation p2 ) {
return ((< undefinedtype >) this . create ( p1 , p2 )). invokeSuspend ( Unit . INSTANCE );
}
// $FF: synthetic method
// $FF: bridge method
public Object invoke ( Object p1 , Object p2 ) {
return this . invoke (( CoroutineScope ) p1 , ( Continuation ) p2 );
}
}, 3 , ( Object ) null );
}
}
以上的分析流程就是协程的挂起恢复过程。
自动的线程切换 引例 在Android上使用协程,从本地读取一个字符串,或其他耗时逻辑,可能会写下这样的代码:
// MainViewModel.kt
suspend fun getLocalString () = withContext ( Dispatchers . IO ) {
// 模拟IO操作
Thread . sleep ( 2000 )
"result from local"
}
// MainActivity.kt
class MainActivity : AppCompatActivity () {
override fun onCreate ( savedInstanceState : Bundle ?) {
super . onCreate ( savedInstanceState )
setContentView ( R . layout . activity_main )
// 开启协程
lifecycleScope . launch {
val result = getLocalString ()
tv_result . text = result
}
}
}
getLocalString() 方法,我们设置了上下文为IO,很明显直觉上会在 IO 线程中执行。
在 MainActivity 中,我们通过 lifecycleScope.launch 开启了一个协程,协程中调用 getLocalString() 方法,最初为主线程环境,是怎么从主线程切换到IO线程来运行这个方法的呢?
ContinuationInterceptor Kotlin协程实现自动线程切换的核心在于其调度器(Dispatcher) 机制,而调度器 Dispatcher 就是 ContinuationInterceptor 的实现。
ContinuationInterceptor 接口(简化):
public interface ContinuationInterceptor : CoroutineContext . Element {
// 拦截 Continuation 的恢复
fun < T > interceptContinuation ( continuation : Continuation < T >): Continuation < T >
}
AbstractCoroutine (例如 StandaloneCoroutine) 的 resumeWith 方法:
当协程需要恢复时,通常会调用 Continuation 的 resumeWith 方法。在协程的底层实现中,例如 AbstractCoroutine (所有 Job 的子类,如 StandaloneCoroutine 继承的基类),其 resumeWith 方法会检查 CoroutineContext 中是否存在 ContinuationInterceptor。
// AbstractCoroutine.kt (简化)
override fun resumeWith ( result : Result < T >) {
val context = this . context
val dispatcher = context [ ContinuationInterceptor ] as ? ContinuationInterceptor
if ( dispatcher == null ) {
// 没有调度器,直接在当前线程执行
dispatchResume ( result )
} else {
// 有调度器,通过调度器来分发恢复操作
dispatcher . dispatch ( this , result ) // 最终会调用 dispatchResume
}
}
Dispatcher 的 dispatch 方法Dispatcher 的 dispatch 方法是实际执行线程切换的地方。不同的调度器有不同的实现。
Dispatchers.Default (例如 DefaultScheduler.kt):
Dispatchers.Default 通常使用一个共享的线程池来执行协程。
// DefaultScheduler.kt (简化)
internal object DefaultScheduler : CoroutineDispatcher (), Executor {
override fun dispatch ( context : CoroutineContext , block : Runnable ) {
// 将 block (即恢复协程的Runnable) 提交到默认的线程池
DefaultExecutor . enqueue ( block ) // DefaultExecutor 是一个线程池
}
// ... 其他方法
}
当 dispatch 被调用时,它会将协程的恢复逻辑封装在一个 Runnable 中,然后提交给调度器底层的 线程池 。这个 Runnable 最终会在线程池中的某个线程上执行,从而实现了线程的切换。
Dispatchers.IO 通常会使用一个独立的、容量更大的线程池,用于处理 IO 密集型任务。其 dispatch 逻辑与 Default 类似,只是提交给不同的线程池。Dispatchers.Main 在 Android 上通常会与主线程的 Looper 绑定。// AndroidMainDispatcherFactory.kt (简化)
internal class AndroidMainDispatcherFactory : MainDispatcherFactory {
override fun createDispatcher ( allFactories : List < MainDispatcherFactory >): MainCoroutineDispatcher {
// ...
return HandlerContext ( Looper . getMainLooper (), "Main" ) // 包装了 Looper
}
}
// HandlerDispatcher.kt (简化)
class HandlerContext ( .. .) : MainCoroutineDispatcher () {
override fun dispatch ( context : CoroutineContext , block : Runnable ) {
// 将 block 提交到 Looper 关联的 Handler
handler . post ( block )
}
// ...
}
上面的代码可以看出, Dispatchers.Main 会将协程的恢复操作通过 Android Handler 的 post 方法发送到主线程的消息队列,从而确保协程在主线程上恢复执行。
suspendCoroutine / suspendCancellableCoroutine除了编译器自动生成的挂起点,我们也可以手动创建挂起点,这通常通过 suspendCoroutine 或 suspendCancellableCoroutine 函数实现。
suspend fun manualSuspendExample (): String = suspendCancellableCoroutine { continuation ->
// 可以在这里执行一些异步操作
Thread {
Thread . sleep ( 1000 )
continuation . resume ( "Resumed from another thread" ) // 在另一个线程调用 resume
}. start ()
}
这里 continuation.resume(...) 的调用是关键。当这个 resume 被调用时,它会触发之前提到的 ContinuationInterceptor 机制,如果 CoroutineContext 中有调度器,就会通过调度器进行线程切换。
总结挂起和线程切换流程 协程挂起: 当协程遇到 suspend 函数(如 delay,或自定义的挂起函数),如果该函数需要等待某个异步操作完成,它会返回 COROUTINE_SUSPENDED,并将当前的执行上下文(Continuation)保存起来。异步操作完成: 当异步操作完成时(例如网络请求返回数据,或 delay 时间到),会调用之前保存的 Continuation 对象的 resumeWith 方法。调度器介入: resumeWith 方法会检查协程的 CoroutineContext 中是否存在 ContinuationInterceptor (即 Dispatcher)。分发恢复: 如果存在调度器,resumeWith 会调用调度器的 dispatch 方法。线程切换: 调度器的 dispatch 方法会将协程的恢复逻辑(一个 Runnable)提交到其管理的线程(如线程池中的线程,或 Android 主线程)。协程恢复: Runnable 在目标线程上执行,调用实际的恢复逻辑,协程从挂起的地方继续执行。通过这种 CPS转换 + 回调resume + 调度器拦截 的机制,Kotlin 协程得以在不阻塞线程的情况下,根据需要自动在不同的线程之间切换执行,从而实现高效的并发编程。
在 Kotlin 中,集合类(Collections)是非常重要的一部分,它提供了丰富且功能强大的 API 来操作数据集合。Kotlin 的集合类在很大程度上与 Java 的集合框架兼容,但 Kotlin 在其基础上进行了扩展和增强,提供了更简洁、更安全、更富表达力的 API。
一个重要的概念是,Kotlin 明确区分了只读 (read-only) 集合和可变 (mutable) 集合。
只读集合接口: 它们只提供读取数据的方法,不能添加、删除或修改元素。例如:List<T>、Set<T>、Map<K, V>。 可变集合接口: 它们在只读接口的基础上,提供了修改集合的方法。例如:MutableList<T>、MutableSet<T>、MutableMap<K, V>。 Kotlin 的集合类主要分为三大类:列表 (List)、集合 (Set) 和 映射 (Map)。这些集合类都继承自 kotlin.collections 包中的接口。
List<T>有序集合,保持元素的插入顺序,其内部的元素可以重复。
只读列表 :通常通过 listOf() 或 mutableListOf().toList() 创建。可变列表 :通常通过 mutableListOf() 创建。除了 List 的功能外,还支持添加、删除、更新元素。除了上面两种创建方式,还可以使用 arrayListOf() 返回一个 ArrayList ,其实就是Java 的 ArrayList。
Set<T>Set是一种无序的集合,不包含重复的元素。
只读集合 通常通过 setOf() 或 mutableSetOf().toSet() 创建。不保证元素的顺序,不允许有重复元素。可变集合 通常通过 mutableSetOf() 创建。支持添加、删除元素。其他的创建方式还有 hashSetOf(),返回一个 HashSet (Java 的 HashSet)。
linkedSetOf(): 返回一个 LinkedHashSet (Java 的 LinkedHashSet)。
Map<K, V>映射 (也称为字典或关联数组) 存储键值对,其中每个键都是唯一的,并且映射到一个值。
Map<K, V> (只读):mapOf() 或 mutableMapOf().toMap() 创建。用来存储键值对,键是唯一的,不保证元素的顺序 (除非使用特定实现如 LinkedHashMap)。MutableMap<K, V> (可变):mutableMapOf() 创建。支持添加、删除、更新键值对。还可以使用 hashMapOf() 创建一个 HashMap (Java 的 HashMap)。
linkedMapOf(): 返回一个 LinkedHashMap (Java 的 LinkedHashMap)。
Kotlin 集合与 Java 集合对比 Kotlin 的集合在很大程度上是基于 Java 集合框架的,但进行了优化和扩展,提供了更安全、更简洁的 API。
1. 只读与可变分离 (最主要区别) Kotlin: 明确区分了只读接口 (List, Set, Map) 和可变接口 (MutableList, MutableSet, MutableMap)。
这在编译时强制执行了不变性,有助于避免运行时错误和并发问题。当你只需要读取集合时,声明为只读类型可以更好地表达意图,并防止意外修改。
val readOnlyList : List < String > = listOf ( "A" , "B" , "C" )
// readOnlyList.add("D") // 编译错误!
val mutableList : MutableList < String > = mutableListOf ( "X" , "Y" , "Z" )
mutableList . add ( "W" ) // 可以修改
而使用 Java的集合接口 (如 List, Set, Map) 本身就包含了修改方法。虽然可以通过 Collections.unmodifiableList() 等方法创建不可修改的视图,但这只是一个运行时检查,如果你仍然持有原始的可变集合引用,它仍然可以被修改。
List < String > javaList = new ArrayList <>( Arrays . asList ( "A" , "B" , "C" ));
// javaList.add("D"); // 可以直接修改
List < String > unmodifiableJavaList = Collections . unmodifiableList ( javaList );
// unmodifiableJavaList.add("E"); // 运行时抛出 UnsupportedOperationException
// 但是,如果修改 javaList,unmodifiableJavaList 也会随之改变
javaList . add ( "F" ); // unmodifiableJavaList 现在也包含 "F"
在Java中也可以直接创建不可变集合,使用 Java 9 以后引入的 List.of(), Set.of(), Map.of() 方法。
List < Integer > numbers = Arrays . asList ( 1 , 2 , 3 ); // 返回一个固定大小的List
// 或者
List < Integer > numbersJava9 = List . of ( 1 , 2 , 3 ); // 不可变List
Map < String , Integer > users = new HashMap <>();
users . put ( "Alice" , 30 );
2. 可空性支持 Kotlin 的类型系统原生支持可空性。这意味着你可以明确指定集合是否可以包含 null 元素,以及集合本身是否可以为 null。
val nullableStrings : List < String ?> = listOf ( "A" , null , "B" ) // 列表中可以有 null
val nonNullableList : List < String > = listOf ( "C" , "D" ) // 列表中不能有 null
// 如果一个List本身可能为null
var maybeList : List < Int >? = null
maybeList = listOf ( 1 , 2 )
而 Java 在语言层面没有原生支持可空性,null 是一种常见的运行时错误源 (NullPointerException)。通常通过 @Nullable 和 @NonNull 注解来提示,但这些只是编译器或工具的提示,不能像 Kotlin 那样在编译时强制执行。
3. 集合扩展函数 Kotlin提供了大量的 扩展函数 (Extension Functions) 来操作集合,这使得集合操作变得非常简洁和富有表现力。例如:filter, map, forEach, firstOrNull, count, groupBy 等。这些函数通常链式调用,形成了非常强大的函数式编程风格。
val nums = listOf ( 1 , 2 , 3 , 4 , 5 )
val evenSquared = nums . filter { it % 2 == 0 }. map { it * it } // 过滤偶数并平方
println ( evenSquared ) // 输出: [4, 16]
以下是一些常用的扩展函数:
map:对集合中的每个元素进行转换,返回新的集合。filter:过滤出符合条件的元素,返回新的集合。flatMap:先对每个元素进行转换,然后将结果扁平化为一个新的集合。reduce 和 fold:对集合中的元素进行累积操作。forEach:遍历集合中的每个元素。any 和 all:判断集合中是否存在或所有元素满足某个条件。find 和 first:查找符合条件的元素。示例:
val numbers = listOf ( 1 , 2 , 3 , 4 , 5 )
val doubled = numbers . map { it * 2 } // [2, 4, 6, 8, 10]
val even = numbers . filter { it % 2 == 0 } // [2, 4]
val sum = numbers . reduce { acc , i -> acc + i } // 15
这些扩展函数让 Kotlin 的集合操作更加直观和简洁,提高了开发效率。
4. 与 Java 集合的互操作性 Kotlin 集合与 Java 集合是完全兼容的,并且可以无缝互操作。
在 Kotlin 代码中,你可以直接使用 Java 的 ArrayList, HashSet, HashMap 等。当你在 Kotlin 中使用这些 Java 集合时,它们会自动被视为可变集合。 当 Kotlin 的只读集合传递给 Java 方法时,它们会被转换为相应的 Java 接口,但仍然是“只读视图”。修改这些视图会导致运行时异常,而修改原始 Kotlin 可变集合则会反映在 Java 视图中。 当你从 Java 方法接收集合时,Kotlin 会将其视为可变集合,但在 Kotlin 中你可以轻松地将其转换为只读视图(例如 someJavaList.toList())。 Kotlin 的 Sequence(序列) Sequence 是 Kotlin 提供的一种惰性集合操作机制,类似于 Java 的 Stream API。它的主要特点是:
惰性计算 :Sequence 中的操作不会立即执行,而是按需计算,只有在终端操作(如 toList()、forEach())被调用时才会执行。适合大数据集 :由于是惰性计算,Sequence 在处理大量数据时更高效,因为它避免了创建中间集合。链式操作 :支持链式调用多个操作,代码更简洁。示例:
val numbers = sequenceOf ( 1 , 2 , 3 , 4 , 5 )
val result = numbers
. map { it * 2 } // 不会立即执行
. filter { it % 3 == 0 } // 不会立即执行
. toList () // 触发实际计算,返回 [6]
println ( result ) // 输出 [6]
与 Java 的 Stream 相比,Kotlin 的 Sequence 在语法上更简洁,且与 Kotlin 的集合体系无缝集成。
Pagination © 2024. All rights reserved. LICENSE | NOTICE | CHANGELOG
Powered by Hydejack v9.2.1