【AI】端侧模型部署LiteRT篇

本文介绍了借助Google的LiteRT框架在Android平台上运行端侧AI模型的流程
LiteRT简介
TensorFlow Lite 是 TensorFlow 生态系统中的一个重要组成部分,它是专门为在资源受限的设备(如手机、物联网设备、嵌入式系统和微控制器)上高效运行机器学习模型而设计的。你可以理解为,它是 TensorFlow 模型的“压缩和优化版本”的运行时环境,让 AI 能够 “走出云端,进入设备” 。
和 llama.cpp 一样,TensorFlow Lite也是通过 模型优化和压缩 来实现有限资源时高效运行的。
将模型的参数(如权重和激活值)从浮点数转换为更小的整数类型(如 8 位整数),大大减少模型大小和内存占用,同时提高推理速度。移除模型中不重要的连接和参数。将多个操作合并为一个,减少计算开销。TFLite 解释器本身非常小巧,可以在内存和存储空间有限的设备上运行。
TensorFlowLite在24年9月已经更名为LiteRT。 之所以更名,是因为 TensorFlow Lite 在发展过程中已经超越了最初仅支持 TensorFlow 模型的范畴。它现在能够高效支持从 PyTorch、JAX 和 Keras 等其他主流机器学习框架导出的模型。为了更好地体现这种“多框架”的愿景,并强调其作为设备端高性能运行时的通用性,Google 决定将其更名为 LiteRT。

LiteRT 的核心价值在于提供一个 快速、小巧且高效 的运行时环境,使训练好的机器学习模型能够在设备上本地执行推理。主要特性:
- 针对设备端机器学习进行了优化:LiteRT 解决了五项关键的 ODML 约束条件:延迟时间(无需往返服务器)、隐私性(没有个人数据离开设备)、连接性(无需连接到互联网)、大小(缩减了模型和二进制文件大小)和功耗(高效推理和缺少网络连接)。
- 支持多平台:与 Android 和 iOS 设备、嵌入式 Linux 和微控制器兼容。
- 多框架模型选项:AI Edge 提供了一些工具,可将 TensorFlow、PyTorch 和 JAX 模型转换为 FlatBuffers 格式 (.tflite),让您能够在 LiteRT 上使用各种先进的模型。您还可以使用可处理量化和元数据的模型优化工具。
- 支持多种语言:包括适用于 Java/Kotlin、Swift、Objective-C、C++ 和 Python 的 SDK。
- 高性能:通过 GPU 和 iOS Core ML 等专用代理实现硬件加速。
LiteRT 将模型打包成一种名为 FlatBuffers 的高效可移植格式,文件扩展名为 .tflite。
LiteRT 的部署运行流程
1. 模型加载
第一步,将 .tflite 文件(包含模型的执行图、权重和偏差)加载到内存中。
LiteRT 模型采用 FlatBuffers 格式,这种格式允许直接映射到内存,避免了传统序列化/反序列化所需的额外解析和内存复制,从而加快加载速度。
2. 构建解释器 (Interpreter)
LiteRT Interpreter 解释器是执行模型的核心组件。它使用静态图排序和自定义(非动态)内存分配器。
在内存分配方面, Interpreter 在运行时根据模型图预先分配好所需的张量内存,避免了推理过程中的动态内存分配开销,确保推理延迟稳定且较低。
3. 设置硬件加速器(Delegate/委派)
这一步是 LiteRT 实现高性能的关键。LiteRT 引入了 Delegate(委派) 机制,这是一个 API 接口,用于将模型的部分或全部操作卸载到设备上的特定 硬件加速器 上执行,而不是仅仅依赖 CPU。
常见的加速器:
- GPU:通过 MLDrift(新的 GPU 加速实现)或旧的 GPU Delegate 进行加速。
- NPU/DSP:通过 NNAPI(Android 上的神经网络 API)或高通、联发科等供应商特定的 SDK 来利用神经处理单元。
- Edge TPU:Google 专用的边缘张量处理单元。
- XNNPack:一个高度优化的 CPU 浮点运算库。
Delegate 会检查模型中的哪些操作可以在加速器上运行,并将它们打包交给加速器执行。
4. 数据预处理与运行推理 (Invoke)
数据预处理截断会将输入数据(如图像、音频)转换为模型期望的格式和维度。通过调用 Interpreter::Invoke()(或 LiteRT Next 中的 CompiledModel::Run())方法,LiteRT 解释器执行模型图中的操作。如果设置了 Delegate,相应的操作将在硬件加速器上执行。
5. 解释输出
获取输出张量的值,并将其转换为对应用有意义的结果(例如,将概率列表映射到具体的类别标签,或绘制目标检测的边界框)。
支持的 AI 模型
LiteRT 主要用于推理(Inference),它可以运行各种类型的经过优化的机器学习模型,特别是那些针对视觉、音频和自然语言处理 (NLP) 任务的模型:
| 模型类型 | 常见应用 | 优化特点 |
|---|---|---|
| 计算机视觉 (CV) | 图像分类、目标检测、图像分割、姿态估计、面部识别。 | CNN (如 MobileNet, EfficientNet) 经过量化和剪枝,利用 GPU 和 NPU 加速。 |
| 自然语言处理 (NLP) | 文本分类、命名实体识别、问答系统、小规模 LLM (轻量级大语言模型) 推理。 | Transformer 模型(如 BERT 变体)经过优化,注重模型大小和低延迟。 |
| 音频处理 | 语音识别、关键词唤醒、声纹识别、环境声分类。 | 各种序列模型和特定设计的声学模型。 |
| 通用机器学习 | 分类、回归、时间序列预测。 | 各种通用的 ML 模型,通常通过 TensorFlow、PyTorch 等框架训练后转换为 .tflite 格式。 |
Gallery 开源应用
应用层的集成,在 Google 自己的开源项目中有已经体现:
该应用也同步上架了Play Store,项目截图:
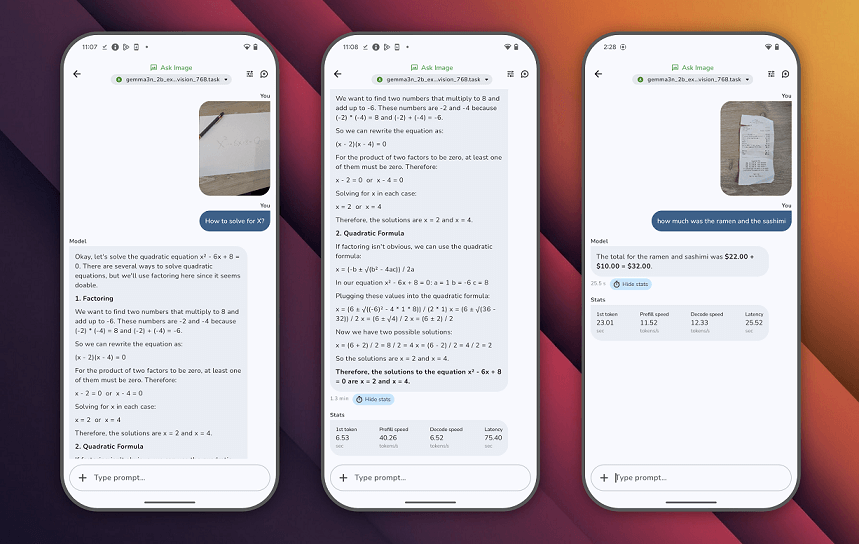
进入首页可以看到主要有四种使用主题,分别是图片分析,音频描述,提示词试验,以及AI模型对话。选择其中一个主题进入之后,通过 Chrome 浏览器授权 Hugging face 账号,就可以在 Gallery 中直接下载模型到其英应用到内部存储中。下图是音频识别到效果,做语言翻译,物种识别效果还不错,歌曲识别准确率不高。
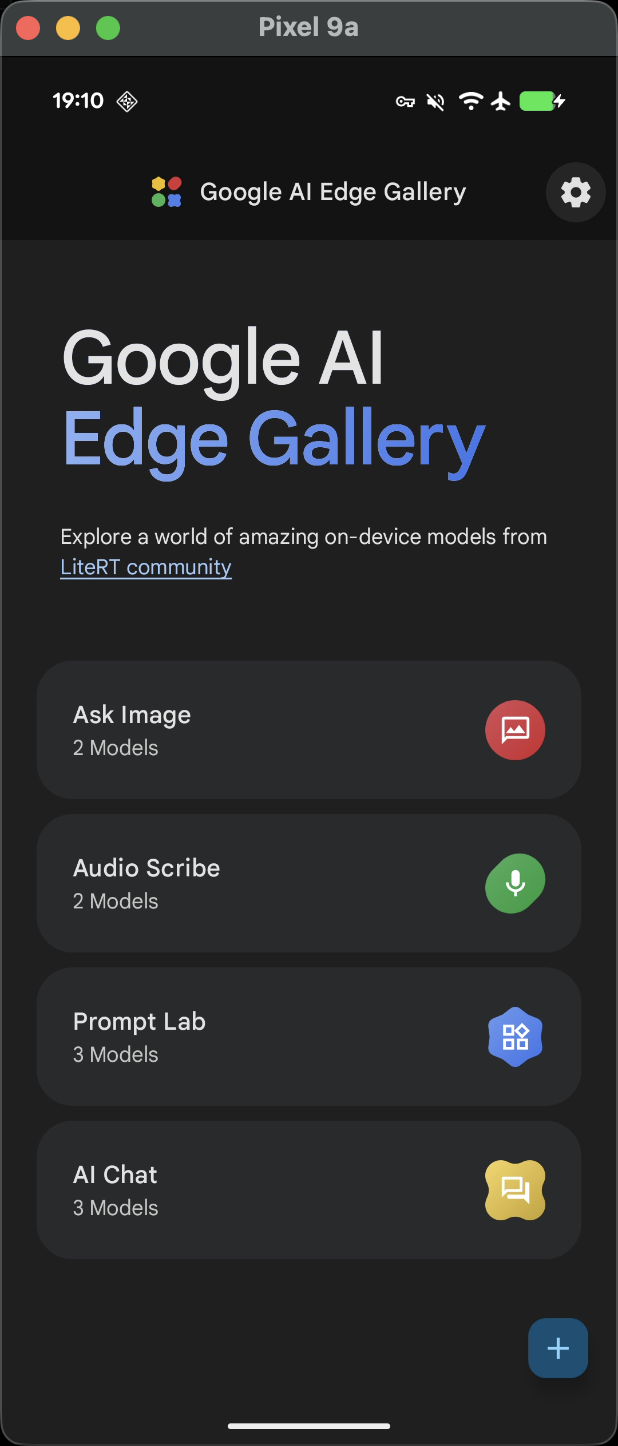
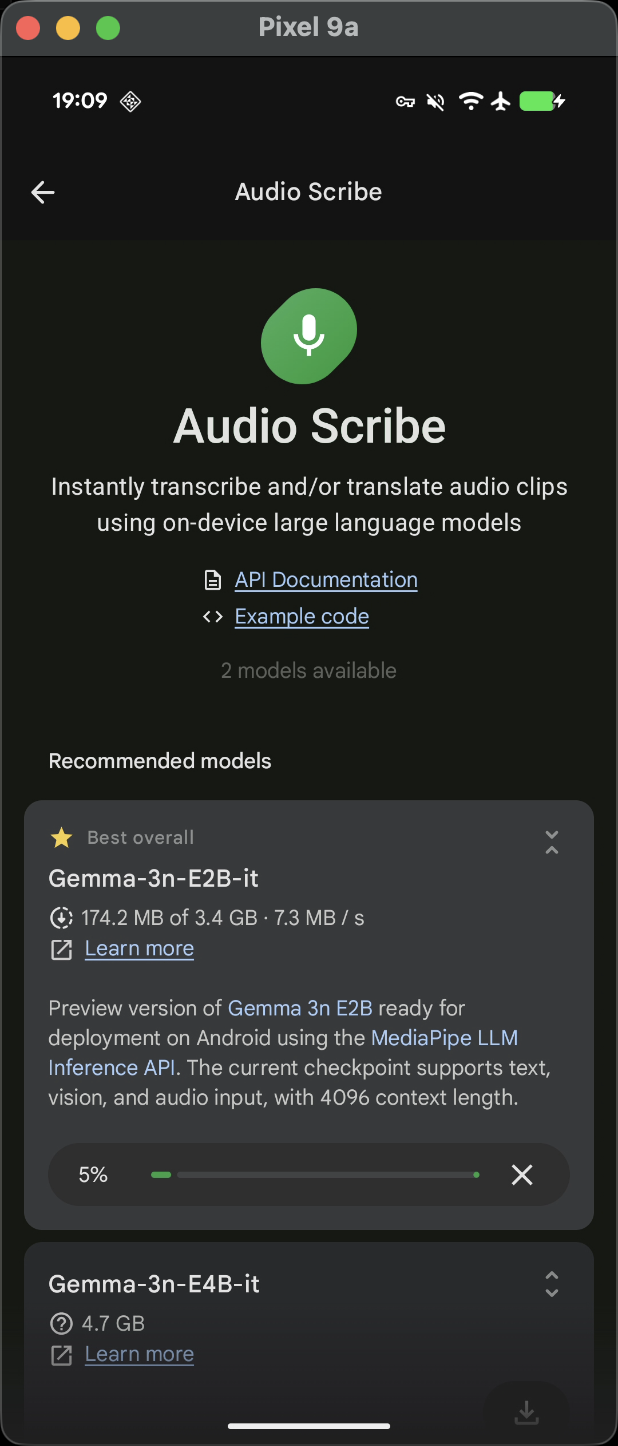
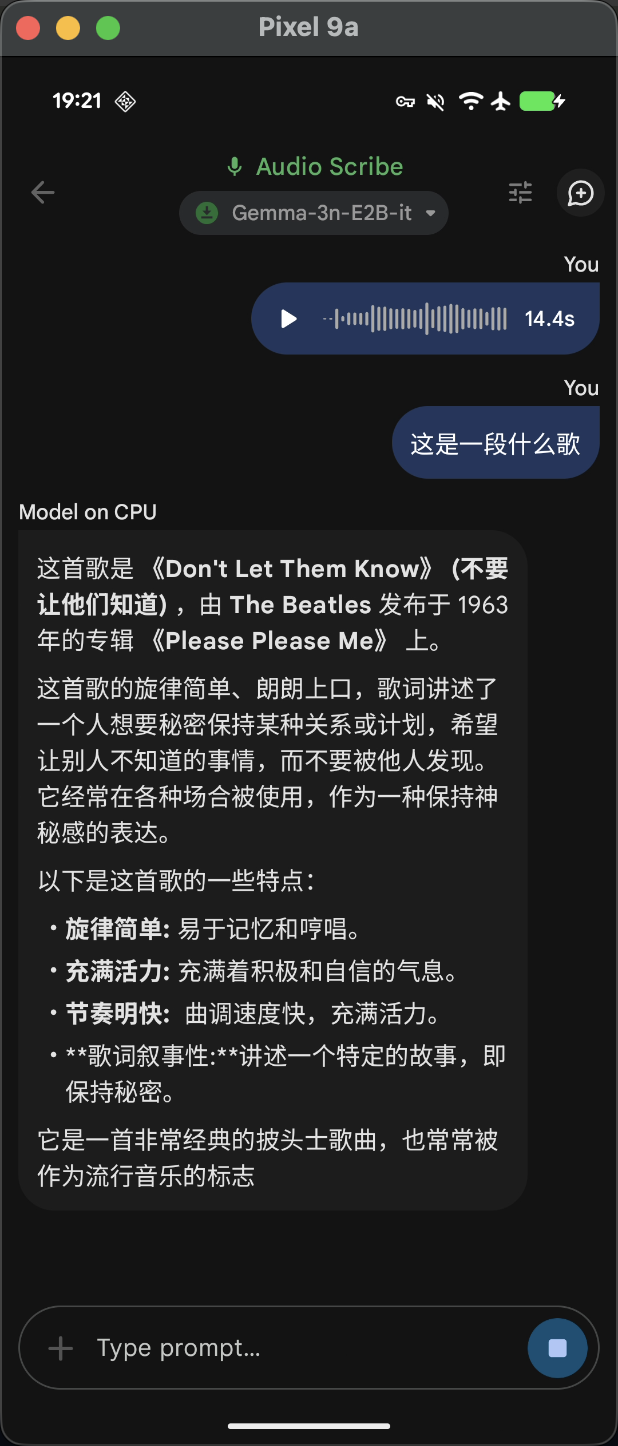
Gallery 运行流程追踪
初始化读取到内存
应用最开始的步骤其实是模型文件检查,以及获取 Token 认证 Hugginface 社区去下载模型,这一步分析省略,因为各家的部署肯定是放置于自己的服务器上,或者直接存在assets文件夹岁随应用打包。
第一步看整个应用模型加载到内存的关键节点,模型初始化流程,用户在UI界面选择一个模型后, ModelManagerViewModel.initializeModel() 方法被调用,会开始检查模型是否已经初始化或正在初始化,避免重复操作。测试中,我加载一个自己下载导入的 gemma3-1b-it-int4 模型,可以看到如下信息:
initializeModel: Model(
name=gemma3-1b-it-int4.litertlm,
displayName=,
info=,
configs=[com.google.ai.edge.gallery.data.LabelConfig@4061738, com.google.ai.edge.gallery.data.NumberSliderConfig@efb2311, com.google.ai.edge.gallery.data.NumberSliderConfig@5c34c76, com.google.ai.edge.gallery.data.NumberSliderConfig@eb7b277, com.google.ai.edge.gallery.data.SegmentedButtonConfig@ba16ee4],
learnMoreUrl=,
bestForTaskIds=[],
minDeviceMemoryInGb=null,
url=,
sizeInBytes=584417280,
downloadFileName=__imports/gemma3-1b-it-int4.litertlm,
version=_,
extraDataFiles=[],
localFileRelativeDirPathOverride=,
localModelFilePathOverride=,
showRunAgainButton=false,
showBenchmarkButton=false,
isZip=false,
unzipDir=,
llmPromptTemplates=[],
llmSupportImage=false,
llmSupportAudio=false,
imported=true,
normalizedName=gemma3_1b_it_int4_litertlm,
instance=null,
initializing=false,
cleanUpAfterInit=false,
configValues={Max tokens=1024, TopK=40.0, TopP=0.9, Temperature=1.0, Choose accelerator=CPU},
totalBytes=584417280,
acessToken=null)
在各种初始化和清除资源检查完成之后,会调用到 LlmChatModelHelper.initialize() 方法。创建 EngineConfig 对象,配置模型路径、后端(CPU/GPU)、最大token数等参数。使用配置创建 Engine 实例并初始化,通过 engine.createConversation() 创建对话实例,将引擎和对话实例包装在 LlmModelInstance 对象中,并赋值给 Model.instance 属性。
关键代码实现:
// LlmChatModelHelper.kt
val engineConfig = EngineConfig(
modelPath = model.getPath(context = context),
backend = preferredBackend,
visionBackend = if (shouldEnableImage) Backend.GPU else null,
audioBackend = if (shouldEnableAudio) Backend.CPU else null,
maxNumTokens = maxTokens,
enableBenchmark = true,
)
val engine = Engine(engineConfig)
engine.initialize()
val conversation = engine.createConversation(ConversationConfig(...))
model.instance = LlmModelInstance(engine = engine, conversation = conversation)
这一步初始化完成之后,就有了和模型进行对话的环境,本地AI模型可以接收输入和进行推理。
输入和输出缓存处理
输入处理
Gemma-3n-E2B 和 Gemma-3n-E4B 具有多模态输入支持,可以接收文本、图像、音频等多种输入类型。在 LlmChatModelHelper.runInference() 方法中处理不同类型的输入。
如果用户输入时,有带上图像和音频类型的文件,会将图像和音频转换为字节数组:
val contents = mutableListOf<Content>()
for (image in images) {
contents.add(Content.ImageBytes(image.toPngByteArray()))
}
for (audioClip in audioClips) {
contents.add(Content.AudioBytes(audioClip))
}
// add the text after image and audio for the accurate last token
if (input.trim().isNotEmpty()) {
contents.add(Content.Text(input))
}
所有内容被封装在 Content 对象列表中。再使用 conversation.sendMessageAsync() 异步发送消息,并且提供回调接口处理推理过程中的事件。
conversation.sendMessageAsync(
Message.of(contents),
object : MessageCallbacks {
override fun onMessage(message: Message) {
message.contents.filterIsInstance<Content.Text>().forEach {
resultListener(it.text, false)
}
}
override fun onDone() {
resultListener("", true)
}
override fun onError(throwable: Throwable) {
if (throwable is CancellationException) {
Log.i(TAG, "The inference is canncelled.")
resultListener("", true)
} else {
Log.e(TAG, "onError", throwable)
resultListener("Error: ${throwable.message}", true)
}
}
},
)
输出处理流程
在上面触发消息发送那里,可以看到是通过 MessageCallbacks 接口处理输出:
onMessage()回调处理中间结果,支持流式输出onDone()回调标记推理完成onError()回调处理错误情况
内部已经自动处理完了从向量到tokenid再查词汇表的对应过程,直接返回的string结果。
模型生命周期管理
如果是建立新对话,就调用的对话重置方法 LlmChatModelHelper.resetConversation() ,会停止并关闭当前对话并创建新的对话实例,保持引擎实例不变,仅重新创建对话对象。
如果是要退出页面,这时候就需要执行资源释放步骤。
LlmChatModelHelper.cleanUp() 方法负责清理模型资源,关闭本轮对话和引擎,将持有的模型实例置空。
fun cleanUp(model: Model, onDone: () -> Unit) {
if (model.instance == null) {
return
}
val instance = model.instance as LlmModelInstance
try {
instance.conversation.close()
} catch (e: Exception) {
Log.e(TAG, "Failed to close the LLM Inference conversation: ${e.message}")
}
try {
instance.engine.close()
} catch (e: Exception) {
Log.e(TAG, "Failed to close the LLM Inference engine: ${e.message}")
}
val onCleanUp = cleanUpListeners.remove(model.name)
if (onCleanUp != null) {
onCleanUp()
}
model.instance = null
onDone()
Log.d(TAG, "Clean up done.")
}
退出对话重新进入的内存表现:
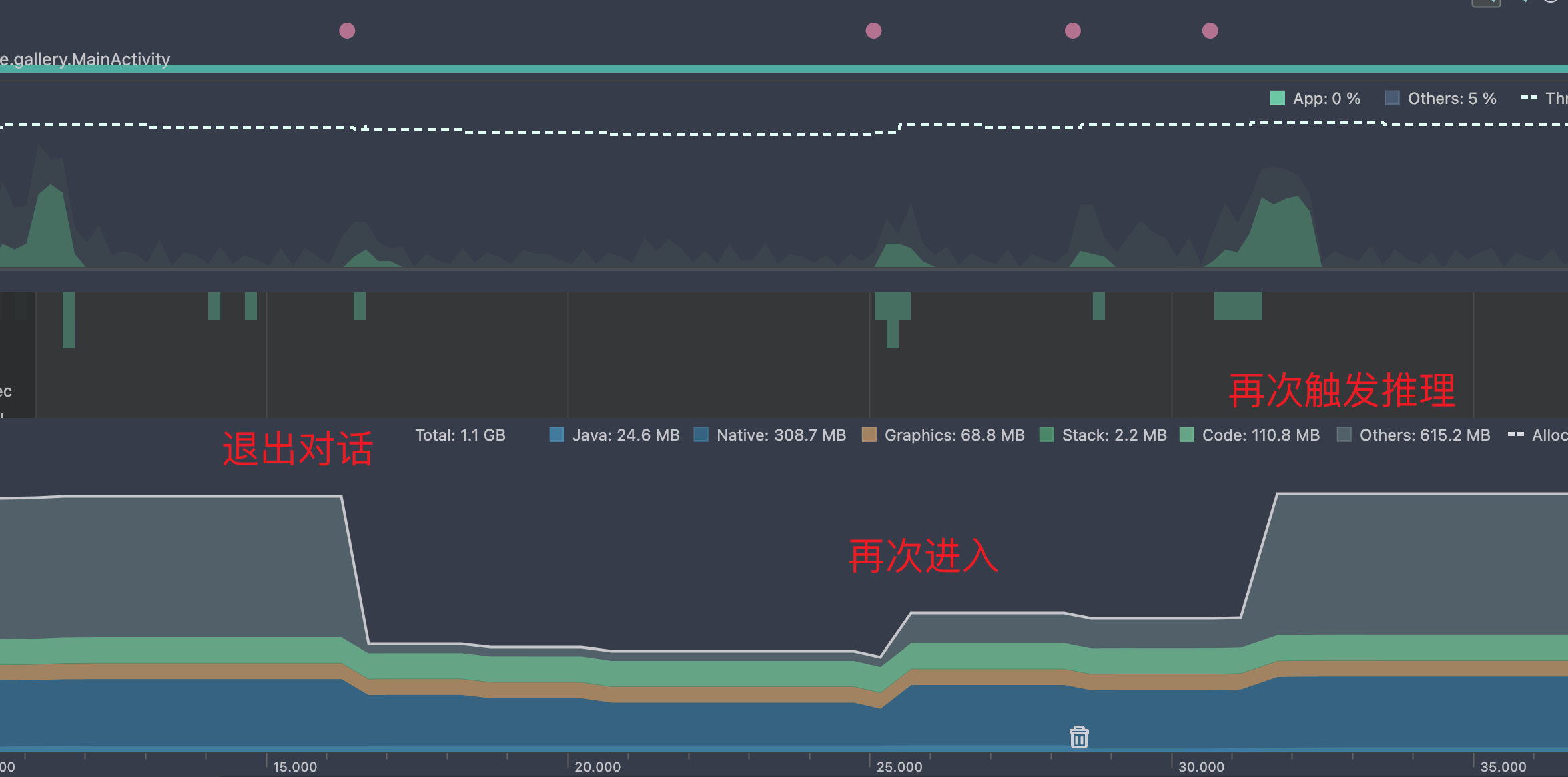
Gallery 整体性能测试
整体使用时的占用和 llama.cpp 持平,主要区别就是分了两段加载,在刚进入对话 loadModel() 时,没有加载全部权重数据到内存,在推理真正调用再加载的。
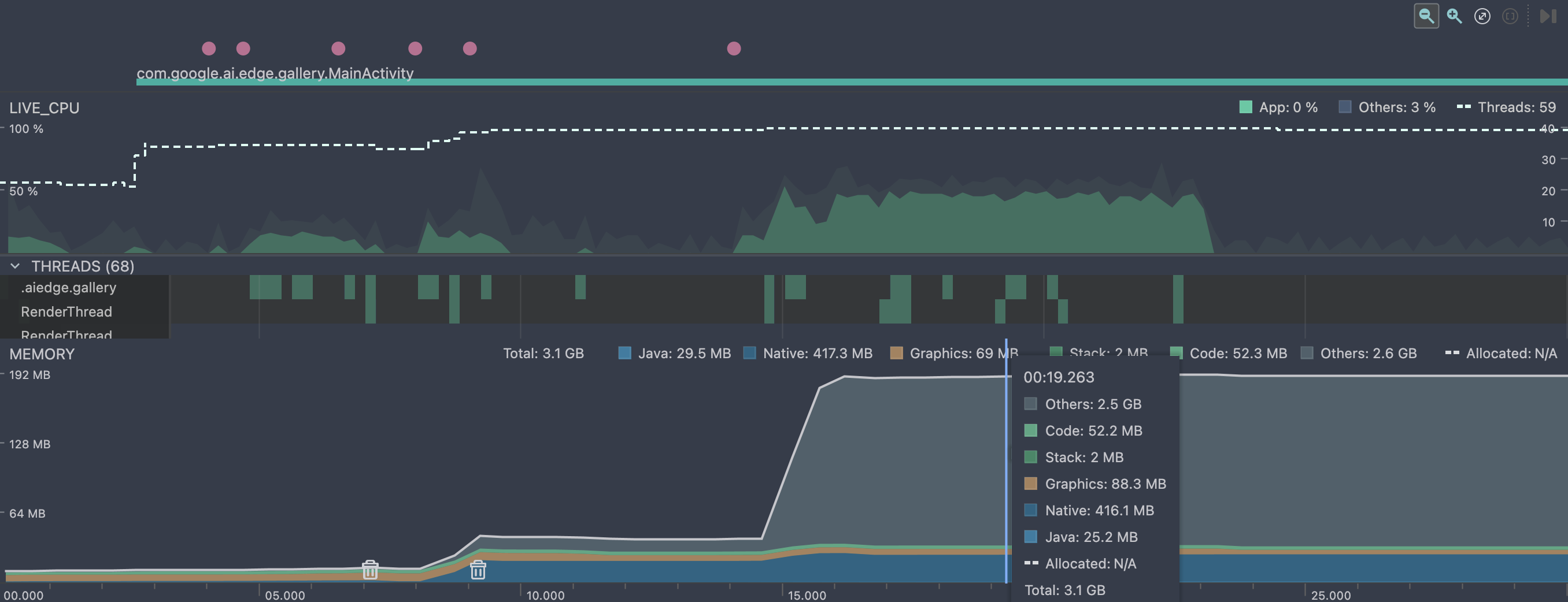
这条有别于llama.cpp的路线,在集成gguf模型时,主要的权重张量全部读取到了Native堆中,另外可以看到 Others 是占用最多的一块内存,核心原因可能是硬件加速与内存委托,端侧模型很可能在推理开始时,将计算任务委托给了专用的硬件加速器,例如 GPU、DSP 或 NPU,并通过 Android 神经网络 API (NNAPI) 或厂商特定的 SDK 实现。
在推理开始之前,模型权重、输入/输出张量等可能已经被加载到内存中,并通过标准的 C/C++ malloc/new 在 Native Heap 上分配。当推理开始并决定使用硬件加速时,模型运行时(例如 TensorFlow Lite Runtime)会 释放 Native Heap 上的一些大型张量(特别是那些将在硬件上处理的中间结果和输出张量)。这导致 Native Heap 内存下降。
为了实现高效的硬件加速,数据(张量)需要被放置在硬件驱动可以直接访问的内存区域。模型运行时会使用特殊的系统 API 来分配这些内存,而不是标准的 malloc。Android Studio Profiler 的 Native Heap 类别主要跟踪标准的 C/C++ 运行时分配。当内存被分配到 Ashmem、ION 或其他驱动管理的内存池时,它们在 dumpsys meminfo 的分类中可能被归类为 Shared、Private Clean 或未被精确识别的系统保留内存,最终落入 Profiler 的 Others(其他)类别中。
另外一个可能的原因是系统或运行时内部调整。如果模型运行时(如 TFLite)在推理时创建了新的执行图(Execution Plan)或缓存了更多的上下文信息,这些非张量数据可能以系统未明确分类的方式被分配,计入 Others。某些高性能计算库会尝试使用大内存页来提高内存访问效率,这些内存页在某些 Profiler 版本中可能不会被准确地归类到 Native Heap。
简化方式一 MediaPipe Tasks
底层依然基于 LiteRT 的运行时来运行端侧AI模型,只是在应用层进行了封装,提供了更方便的接口。
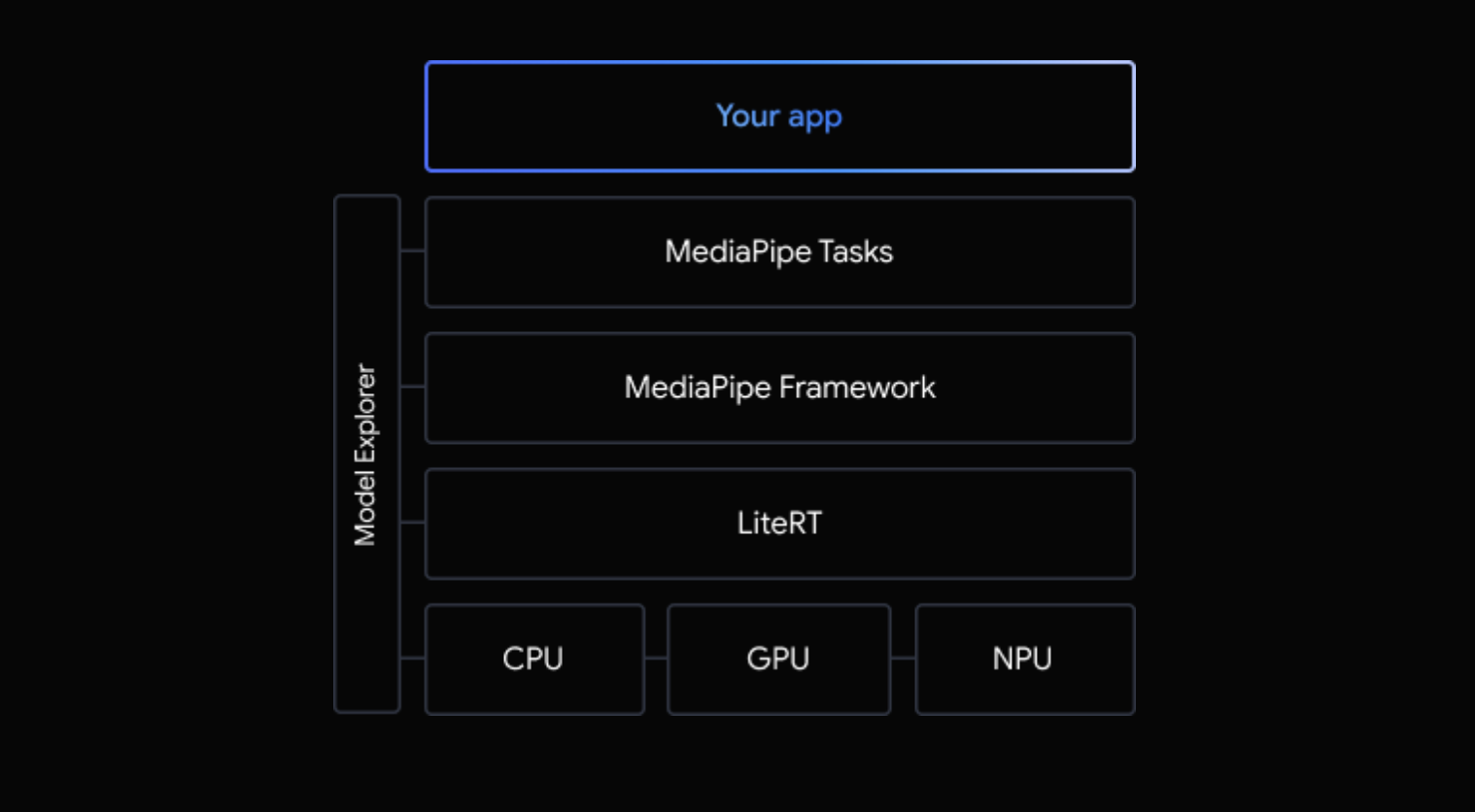
简化方式二 AI Core 应用进行IPC通信
这个方法,便利性上较前两种方式更进了一步。Google 直接将Gemini Nano模型的下载,加载,推理都封装在 AI Core 中,应用层只需要调用AIDL接口和 AI Core 进行通信即可。
Google介绍:Gemini Nano 是我们专为设备端任务打造的最高效模型,它直接在移动芯片上运行,从而支持一系列重要用例。设备端运行支持数据无需离开设备的功能,例如在端到端加密消息应用中提供消息回复建议。它还能通过确定性延迟实现一致的体验,即使在没有网络的情况下也能始终使用各项功能。
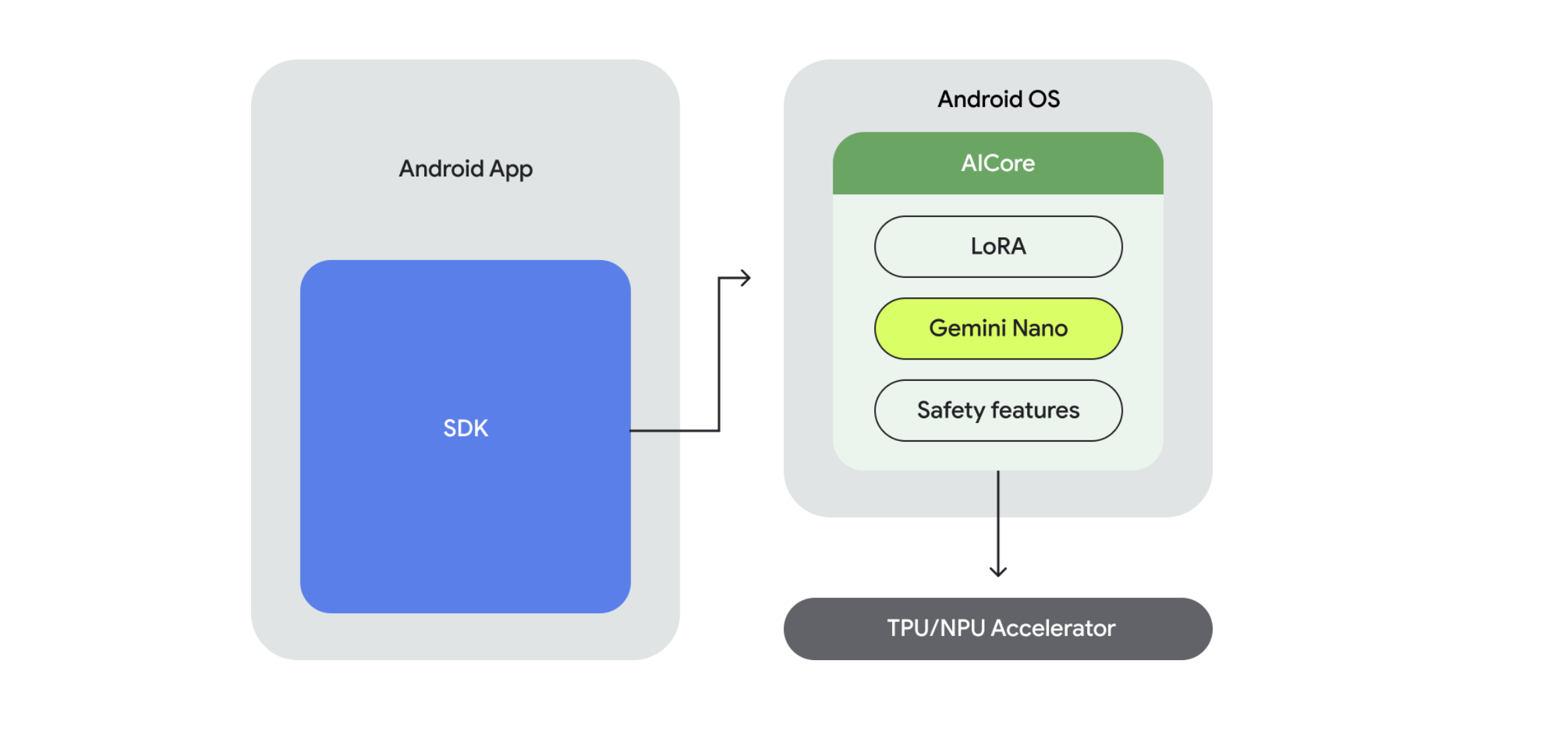
图中的Lora是什么呢?
LoRA (Low-Rank Adaptation) 是一种用于微调(fine-tuning)大型预训练模型的技术,比如大型语言模型 (LLMs) 或图像生成模型 (如 Stable Diffusion)。
简单来说,LoRA 的核心思想是:在不修改原始大模型参数的情况下,通过向模型中注入少量可训练的层(或称为适配器)来适应新的任务或数据。
可以类比 Kotlin的扩展函数 来理解。
需要注意,目前测试版的 AI Core 只有 Pixel 9 及以上的设备支持。
使用AICore来和Genimi Nano模型进行通信的步骤非常简单。首先加入gradle依赖:
implementation("com.google.ai.edge.aicore:aicore:0.0.1-exp01")
注意最低SDK需要31及以上。
在此仅做最小功能验证,直接在Composable组合项中观察一个顶层变量 aiCoreOutput 这个 StateFlow 的状态变化,在顶层方法中出发通信逻辑,结果会更新到 aiCoreOutput 中。
val aiCoreOutput = MutableStateFlow("")
@SuppressLint("StaticFieldLeak")
val generationConfig = generationConfig {
context = appContext
temperature = 0.2f
topK = 16
maxOutputTokens = 256
}
val downloadCallback = object : DownloadCallback {
override fun onDownloadProgress(totalBytesDownloaded: Long) {
super.onDownloadProgress(totalBytesDownloaded)
println("Download progress: $totalBytesDownloaded")
}
override fun onDownloadCompleted() {
super.onDownloadCompleted()
println("Download completed")
}
}
val downloadConfig = DownloadConfig(downloadCallback)
val generativeModel = GenerativeModel(
generationConfig = generationConfig,
downloadConfig = downloadConfig
)
suspend fun startChat(input: String) {
runCatching {
val response = generativeModel.generateContent(input)
print(response.text)
aiCoreOutput.value = response.text.toString()
}.onFailure { e ->
e.printStackTrace()
}
}
fun closeChatResponse() {
println("Closing chat response")
generativeModel.close()
}
Android 平台自定义使用 LiteRT
在 Android 上,可以使用 Java 或 C++ API 执行 LiteRT 推理。通过 Java API 提供了便利,可以直接在 Android 应用中使用 activity 类。C++ API 提供了更高的灵活性和速度,但可能需要 编写 JNI 封装容器以在 Java 层和 C++ 层之间移动数据。
运行架构解析
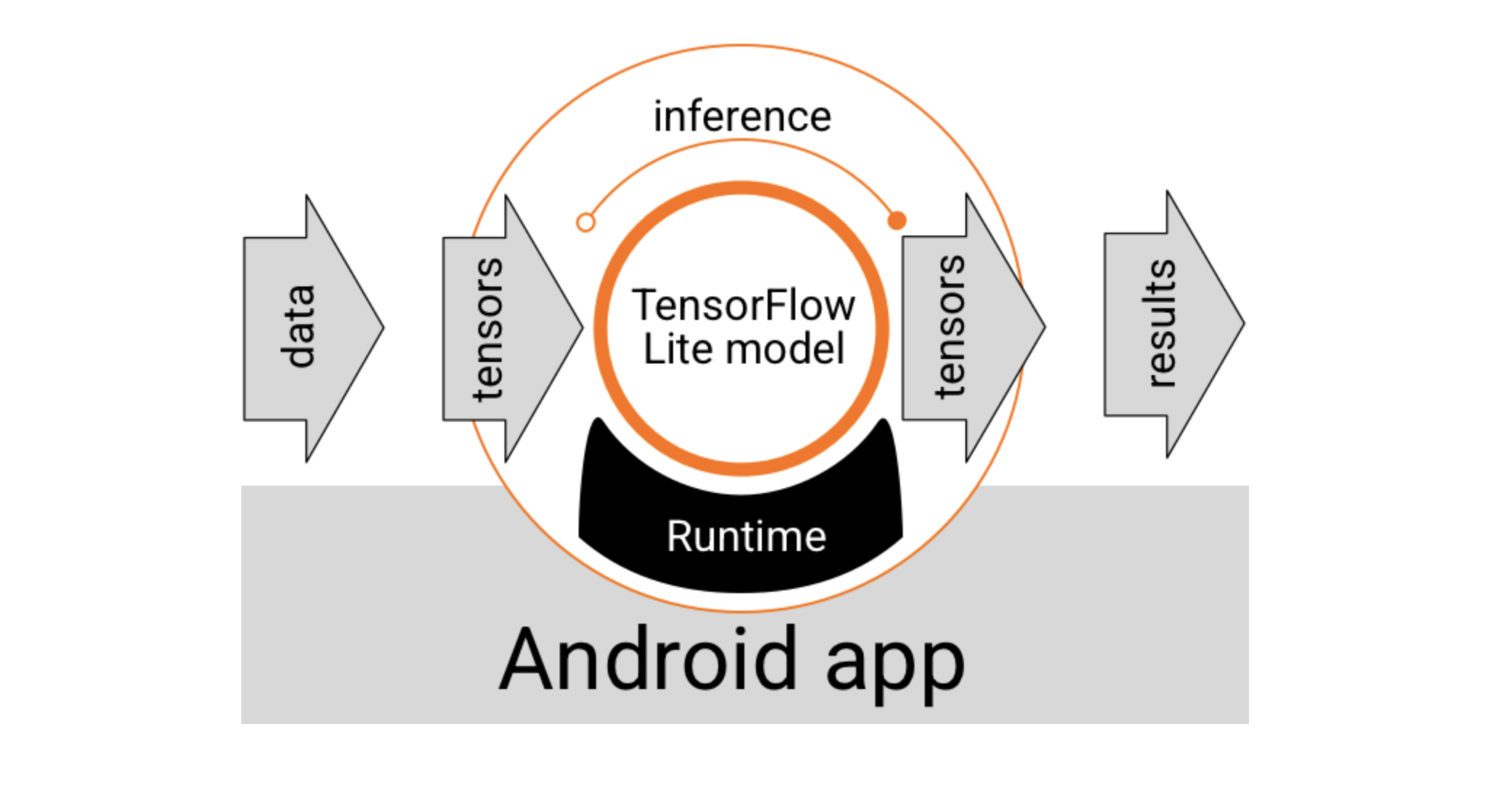
LiteRT 模型需要特殊的运行时环境才能执行,并且传入模型的数据必须采用特定的数据格式(称为张量)。当模型处理数据(称为运行推理)时,它会将预测结果生成为新的张量,并将其传递给 Android 应用,以便应用执行操作,例如向用户显示结果或执行其他业务逻辑。
在功能设计层面,您的 Android 应用需要以下元素才能运行 LiteRT 模型:
- 用于执行模型的
LiteRT运行时环境 - 模型输入处理程序,用于将数据转换为张量
- 模型输出处理脚本,用于接收输出结果张量并将其解读为预测结果
Google Play 服务的运行时
使用 Java API 访问 Google Play 服务中的 LiteRT。具体而言,Google Play 服务中的 LiteRT 可通过 LiteRT 解释器 API 来使用。
使用 Interpreter API
TensorFlow 运行时提供的 LiteRT 解释器 API 提供了一个用于构建和运行机器学习模型的通用接口。按照以下步骤操作,即可使用 Google Play 服务中的 TensorFlow Lite 运行时通过 Interpreter API 运行推理。
1. 添加项目依赖项
注意: Google Play 服务中的 LiteRT 使用 play-services-tflite 软件包。 将以下依赖项添加到您的应用项目代码中,以访问 LiteRT 的 Play 服务 API:
dependencies {
...
// LiteRT dependencies for Google Play services
implementation 'com.google.android.gms:play-services-tflite-java:16.1.0'
// Optional: include LiteRT Support Library
implementation 'com.google.android.gms:play-services-tflite-support:16.1.0'
...
}
2. 添加了 LiteRT 的初始化
在之前使用 LiteRT API 时,初始化 Google Play 服务 API 的 LiteRT 组件:
val initializeTask: Task<Void> by lazy { TfLite.initialize(this) }
注意: 请确保 TfLite.initialize 任务在执行访问 LiteRT API 的代码之前完成。使用 addOnSuccessListener() 方法,如下一部分所示。
3. 创建解释器并设置运行时选项
使用 InterpreterApi.create() 创建解释器,并通过调用 InterpreterApi.Options.setRuntime() 将其配置为使用 Google Play 服务运行时 ,如以下示例代码所示:
import org.tensorflow.lite.InterpreterApi
import org.tensorflow.lite.InterpreterApi.Options.TfLiteRuntime
...
private lateinit var interpreter: InterpreterApi
...
initializeTask.addOnSuccessListener {
val interpreterOption =
InterpreterApi.Options().setRuntime(TfLiteRuntime.FROM_SYSTEM_ONLY)
interpreter = InterpreterApi.create(
modelBuffer,
interpreterOption
)}
.addOnFailureListener { e ->
Log.e("Interpreter", "Cannot initialize interpreter", e)
}
您应使用上述实现,因为它可以避免阻塞 Android 界面线程。如果您需要更密切地管理线程执行,可以向解释器创建添加 Tasks.await() 调用:
import androidx.lifecycle.lifecycleScope
...
lifecycleScope.launchWhenStarted { // uses coroutine
initializeTask.await()
}
警告: 请勿在前景界面线程上调用 .await(),因为这会中断界面元素的显示,从而导致用户体验不佳。
4. 运行推理
使用您创建的 interpreter 对象,调用 run() 方法以生成推理结果。
interpreter.run(inputBuffer, outputBuffer)
硬件加速
借助 LiteRT,您可以使用专用硬件处理器(例如图形处理单元 GPU)来提升模型的性能。您可以使用称为“委托”的硬件驱动程序来利用这些专用处理器。
GPU 委托通过 Google Play 服务提供,并且会动态加载,就像 Interpreter API 的 Play 服务版本一样。
检查设备兼容性
并非所有设备都支持使用 TFLite 进行 GPU 硬件加速。为了减少错误和潜在的崩溃,请使用 TfLiteGpu.isGpuDelegateAvailable 方法检查设备是否与 GPU 委托兼容。
使用此方法可确认设备是否与 GPU 兼容,并在不支持 GPU 时使用 CPU 作为后备。
useGpuTask = TfLiteGpu.isGpuDelegateAvailable(context)
获得 useGpuTask 等变量后,您可以使用它来确定设备是否使用 GPU 委托。
val interpreterTask = useGpuTask.continueWith { task ->
val interpreterOptions = InterpreterApi.Options()
.setRuntime(TfLiteRuntime.FROM_SYSTEM_ONLY)
if (task.result) {
interpreterOptions.addDelegateFactory(GpuDelegateFactory())
}
InterpreterApi.create(FileUtil.loadMappedFile(context, MODEL_PATH), interpreterOptions)
}
使用 Interpreter API 的 GPU
如需将 GPU 委托与 Interpreter API 搭配使用,请执行以下操作:
更新项目依赖项以使用 Play 服务中的 GPU 委托:
implementation 'com.google.android.gms:play-services-tflite-gpu:16.2.0'
在 TFlite 初始化中启用 GPU 委托选项:
TfLite.initialize(context,
TfLiteInitializationOptions.builder()
.setEnableGpuDelegateSupport(true)
.build())
在解释器选项中启用 GPU 代理:通过调用 InterpreterApi.Options() 中的 addDelegateFactory() 将代理工厂设置为 GpuDelegateFactory:
val interpreterOption = InterpreterApi.Options()
.setRuntime(TfLiteRuntime.FROM_SYSTEM_ONLY)
.addDelegateFactory(GpuDelegateFactory())
独立的 LiteRT 运行时
通常,您应使用 Google Play 服务提供的运行时环境,因为它比标准环境更节省空间,因为它会动态加载,从而缩减应用大小。Google Play 服务还会自动使用最新的稳定版 LiteRT 运行时,随着时间的推移,为您提供更多功能并提升性能。如果您 在未包含 Google Play 服务的设备上提供应用,或者需要密切管理 ML 运行时环境,则应使用标准 LiteRT 运行时 。此选项会将额外的代码捆绑到您的应用中,让您可以更好地控制应用中的机器学习运行时,但代价是增加应用的下载大小。
您可以通过将 LiteRT 开发库添加到应用开发环境,在 Android 应用中访问这些运行时环境。
步骤一:添加 LiteRT 核心依赖
在 应用级 build.gradle 文件(通常是 app/build.gradle)中,添加 LiteRT 核心库的依赖项。
dependencies {
// 1. LiteRT 核心库(Standalone/Bundled 运行时)
implementation 'org.tensorflow:tensorflow-lite:LITERT_VERSION'
// 2. 推荐:用于模型元数据和实用程序的库
implementation 'org.tensorflow:tensorflow-lite-support:LITERT_VERSION'
// 3. 可选:如果您需要特定的硬件加速(Delegate),请添加对应的独立依赖。
// 例如,使用 GPU Delegate:
implementation 'org.tensorflow:tensorflow-lite-gpu:LITERT_VERSION'
// ... 其他依赖项
}
注意: 应将
LITERT_VERSION替换为当前的稳定版本号。这些库就是以前的org.tensorflow:tensorflow-lite系列,是独立于 Google Play 服务的。
步骤二:将 LiteRT 模型文件添加到项目
将的 .tflite 模型文件放置在 Android 项目的 assets 文件夹中:
- 在
app/src/main/目录下创建或找到assets文件夹。 - 将您的
model_name.tflite文件复制到此文件夹中。
步骤三:在 Kotlin/Java 中加载和运行模型
使用 LiteRT 的 Interpreter 类来加载模型并执行推理。
import org.tensorflow.lite.Interpreter
import java.nio.ByteBuffer
import java.nio.ByteOrder
import java.io.FileInputStream
import java.nio.channels.FileChannel
// ... 您的 Activity 或 Fragment ...
fun runInference() {
// 1. 配置 LiteRT 解释器选项
val options = Interpreter.Options()
// 2. [可选] 如果添加了 GPU 依赖,可以设置 GPU Delegate
// **注意:** 独立的 GPU Delegate 在某些设备上可能不如 Play Services 托管的稳定。
// val gpuDelegate = GpuDelegate()
// options.addDelegate(gpuDelegate)
// 3. 创建解释器实例
val interpreter: Interpreter
try {
interpreter = Interpreter(loadModelFile(), options)
} catch (e: Exception) {
// 处理加载模型时的错误
e.printStackTrace()
return
}
// --- 假设输入和输出张量大小 ---
// 示例:输入形状 [1, 224, 224, 3] (Float32)
val inputShape = interpreter.getInputTensor(0).shape()
val outputShape = interpreter.getOutputTensor(0).shape()
// 创建输入和输出缓冲区
val inputBuffer = ByteBuffer.allocateDirect(
inputShape[0] * inputShape[1] * inputShape[2] * inputShape[3] * 4 // 4 bytes for float
).apply { order(ByteOrder.nativeOrder()) }
val outputBuffer = ByteBuffer.allocateDirect(
outputShape[0] * outputShape[1] * 4 // 4 bytes for float
).apply { order(ByteOrder.nativeOrder()) }
// [TODO] 准备您的输入数据,并将其写入 inputBuffer
// 例如:将您的图像数据转换为 float 数组并写入 inputBuffer
// 4. 运行模型推理
interpreter.run(inputBuffer, outputBuffer)
// 5. [TODO] 处理 outputBuffer 中的结果
// 6. 清理资源
// interpreter.close()
// gpuDelegate.close() // 如果使用了 Delegate
}
/**
* 从 assets 文件夹加载 .tflite 模型文件
*/
private fun loadModelFile(): ByteBuffer {
val fileDescriptor = assets.openFd("model_name.tflite")
val inputStream = FileInputStream(fileDescriptor.fileDescriptor)
val fileChannel = inputStream.channel
val startOffset = fileDescriptor.startOffset
val declaredLength = fileDescriptor.declaredLength
return fileChannel.map(FileChannel.MapMode.READ_ONLY, startOffset, declaredLength)
}
步骤四:清理和资源管理
不再需要解释器时,务必调用 interpreter.close() 来释放本地资源,这对于防止内存泄漏非常重要。如果使用了硬件加速委托(如 GPU Delegate),也要调用其 close() 方法。
// 确保在 Activity/Fragment 生命周期结束时或不再需要时关闭
override fun onDestroy() {
interpreter.close()
// gpuDelegate?.close()
super.onDestroy()
}
通过这些步骤,Android 应用将使用独立的 LiteRT 运行时进行机器学习推理,完全不依赖 Google Play 服务。
自己构建 LiteRT
某些高级自定义操作可能需要自己构建LiteRT的整个依赖库,直接参考官方指南: