这个工具绝大部分功能都是基于 adb 命令来实现的,在ProcessBuilder中执行命令,获取输出流,对输出的内容进行解析,在结构化地展示到界面。
然而没有直接获取应用图标文件这样的命令,只能从android内部下手,获取png文件再发送到Desktop端。本文介绍一下应用管理功能,图标文件获取这个实现的发展历程和最新的使用AYA服务端更改的版本。
发展历程 一、车机阶段 这个工具在最初开发的时候,是面向车机平台。
由于我可以获取到我们平台的系统签名文件,所以是直接编写了一个带系统签名的APP,内部有一个服务,在 onCreate() 中获取安装所有的应用信息:
label packageName versionName versionCode lastUpdateTime … 最麻烦的需要存储的是应用的ICON图标文件,因为想要在电脑端的JVM应用 DebugManager 中显示应用的图标,是没有adb命令可以使用的,只能从Android平台上获取到 Bitmap 数据,转换为png存储下来。最后拉取到Desktop端,读取文件显示图标。
编写玩服务代码,在安装这个APK后,通过 am startService 来运行这个服务,服务端获取信息,将所有信息准备好后再存储到应用内部路径的文件中。
/data/data/com.stephen.appinfoservice/files/appinfo.json
/data/data/com.stephen.appinfoservice/icons/*.png
二、手机阶段 在面对更普遍的手机端的应用管理功能时,我发现了没有系统签名的应用,是不可以直接使用 am startservice 命令来拉起服务的。而且不同手机平台还有权限上面的区别,比如类原生的系统上(Pixel平台,LineageOS),是不用动态申请就可以获取安装的应用信息,但是在国产OS上,有更严格的管理,需要处理读取应用列表权限。
当然可以专门做一个Activity来交互,让用户同意读取应用列表的权限。但是我更希望这个过程是无感的。
所以还是要探索其他的办法。
AYA项目服务端 AYA也是一个基于adb命令来显示Android设备信息,进行调试的项目,同样为跨平台的产品形态。
它是使用比较火的Electron框架,TypeScript 语言编写的。看到他们有类似的应用管理页面,可以显示APP图标,我想他们肯定也是在Android设备上有一个服务端的。看看他们服务端的实现方式,并将其改写成适配 DebugManager 项目的数据传输方案。
AYA的服务端不是承载于一个普通的Android应用进程上,而是类似于一个DEAMON守护进程。
代码运行分析 这是一个 Android 应用,但它并不是一个常规的 APK,而是一个在 Android 设备上通过 dex 文件直接运行的程序。这种方式通常用于需要更高权限或者直接访问系统服务的工具类应用,类似于 adb shell 上的一个服务。
在项目的Gradle脚本中,配置了一个任务,这个任务会将项目的代码build生成的apk里面的 dex 文件提取出来,然后通过 adb 命令,推送到设备的 data/local/tmp 路径下,使用 CLASSPATH 指定运行。
android . applicationVariants . all { variant ->
variant . outputs . all {
outputFileName = "aya-server-v${versionName}.apk"
def dexPath = rootProject . rootDir . path
variant . assembleProvider . get (). doLast {
copy {
def file = zipTree ( file ( outputFile )). matching { include 'classes*.dex' }. singleFile
from file
into dexPath
rename { String fileName ->
fileName . replace ( file . getName (), "aya.dex" )
}
}
}
}
}
从整个流程看,这个项目是一个用于在 Android 设备上获取和管理应用信息的工具。它利用了 LocalSocket反射 访问 Android 隐藏的 API 来获取详细的系统和应用信息,并将这些信息缓存到设备的文件系统中。
对原来的代码进行了改写,AYA项目继承了protobuf通信框架,直接将所有的应用信息,全部通过protobuf协议进行传输,包括图标文件(base64编码后)。
protobuf是Google开发的一种语言无关、平台无关、可扩展的序列化数据结构的方法,它可以将数据结构序列化为二进制格式,用于在网络上传输或存储。
我选择了更简单的通信方案,直接使用JSON字符串,在客户端使用Kotin序列化解析。然后服务端在运行时,将图标png存储到固定位置,拉取到电脑端再显示。这种方式打包的dex文件体积缩小了90%。
代码简要分析:
服务入口 Server.kt Server.kt 的 main 方法是整个程序的入口点。
fun start ( args : Array < String >) {
Log . i ( TAG , "Start server" )
val server = LocalServerSocket ( "aya" )
Log . i ( TAG , "Server started, listening on ${server.localSocketAddress}" )
while ( true ) {
val conn = Connection ( server . accept ())
Log . i ( TAG , "Client connected" )
executor . submit ( conn )
}
}
Server.main 方法被调用,创建一个 Server 实例并调用其 start 方法。start 方法首先创建一个名为 "aya" 的 LocalServerSocket。LocalSocket 是 Android 上一种特殊的 IPC(Inter-Process Communication,进程间通信)机制,它允许同一个设备上的不同进程通过本地套接字进行通信。服务器进入一个无限循环 while (true),等待客户端连接。 每当有客户端连接时 (server.accept()),服务器会创建一个新的 Connection 实例,并将该实例提交给一个缓存线程池 executor 来执行。这意味着每个客户端连接都会在一个独立的线程中处理,从而实现了并发处理。 请求处理 Connection.kt Connection.kt 负责与单个客户端进行通信。
run 方法获取客户端的输入流和输出流,用于读取请求和发送响应。它进入一个循环,从输入流中读取客户端发送的 JSON 字符串请求。 读取到的 JSON 字符串被解析,然后调用 handleRequest 方法来处理具体的请求。 handleRequest 方法根据请求中的 method 字段来分发不同的处理逻辑。
when ( method ) {
"getVersion" -> {
put ( "version" , getVersion ())
}
"getPackageInfos" -> {
put ( "packageInfos" , getPackageInfos ( JSONObject ( params )))
}
"saveAllInfoToFile" -> {
put ( "saveResult" , saveAllInfoToFile ( params ))
}
else -> {
Log . e ( TAG , "Unknown method: $method" )
put ( "error" , "Unknown method: $method" )
}
}
调用的 getPackageInfo 方法是核心逻辑,它利用反射机制获取系统服务并查询应用信息。
获取系统服务 :通过 ServiceManager.packageManager 和 ServiceManager.storageStatsManager 获取 PackageManager 和 StorageStatsManager 的实例。 ServiceManager.kt 中使用反射调用了隐藏的 android.os.ServiceManager.getService 方法,从而获取系统的 IPackageManager 和 IStorageStatsManager 服务。这种方式通常需要特殊的权限或者在 root 环境下才能成功。查询信息 :使用 ServiceManager.packageManager.getPackageInfo 获取 PackageInfo 对象,其中包含了应用版本、安装时间等基本信息。 从 PackageInfo 中获取 ApplicationInfo,进而获取应用的 apkPath 和 flags。通过 flags 判断应用是否为系统应用。 如果设备版本在 Android 8.0(Oreo)及以上,会使用 ServiceManager.storageStatsManager.queryStatsForPackage 获取应用的存储统计信息,包括应用数据大小、缓存大小等。 获取应用名称和图标 :利用 apkPath,通过反射创建 AssetManager 并加载 APK 资源,然后获取应用的名称(label)和图标(icon)。 如果图标存在,会将其转换为 PNG 格式并保存到 /data/local/tmp/aya/icons 目录下。 组织和返回数据 :所有获取到的信息都被封装成一个 JSONObject 返回。 生命周期与数据流转 普通 Android 应用(APK)的生命周期是由系统 PackageManager 和 ActivityManager 严格管理的。而这个服务端则是一个 “裸” 进程 。
它的生命周期管理方式更接近于一个传统的 Linux 守护进程(daemon)。它没有标准的 Android 应用入口点(如 Launcher Activity)。它通常需要通过 adb shell 或其他特殊工具(如 Magisk 模块)来手动启动,命令通常类似于 app_process /system/bin io.liriliri.aya.Server。
它的生命周期完全由启动它的进程控制。只要启动它的 shell 进程或父进程不被终止,这个服务端进程就会一直运行。它没有 onStop、onPause 等 Android 生命周期回调。由于它不是一个常规的应用进程,系统不会像管理普通应用那样主动去管理它。如果它没有被其他应用组件绑定,系统通常不会轻易终止它,除非设备内存极度紧张。
使用 反射 来调用系统隐藏的 API 。这种方式绕过了标准的权限检查。
这个服务端运行在一个单独的 JVM(Java Virtual Machine)进程 上。
具体来说:
独立的进程 : AYA的服务端代码有一个 main 方法在 Server.kt 中。在 Android 平台上,当一个 Java/Kotlin 程序通过 CLASSPATH 运行并带有 main 方法时,它会被系统启动为一个独立的进程。这个进程会拥有自己的 Dalvik 或 ART(Android Runtime)虚拟机实例。本地套接字服务器 : 这个进程创建了一个 LocalServerSocket。LocalSocket 是一种 Android 内部的 IPC(进程间通信)机制,它允许同一个设备上的不同进程进行通信。你的服务端进程会监听这个套接字,等待其他客户端进程(例如,一个通过 adb shell 启动的客户端,或者一个单独的 Android 应用)来连接。服务端程序可以被看作是一个后台服务,它作为一个独立的进程在 Android 系统中运行,并通过本地套接字提供服务。运行成功后,再通过 adb forward tcpip:xxxx localabstract:aya 命令,把这个设备内部的本地套接字通信,映射到电脑的 TCP/IP 端口上。
以下是完整的通信流程:
你的电脑上的客户端程序(例如,一个 Python 脚本或一个 C++ 程序)会尝试连接到 localhost:xxxx。这个连接请求是一个标准的 TCP/IP 连接请求。 当 adb 发现一个连接到你电脑 xxxx 端口的请求时,它会拦截这个请求。adb 作为一个桥梁,将这个 TCP/IP 流量通过 USB 数据线或 Wi-Fi 发送到你连接的 Android 设备。 设备端的 adb 守护进程(adbd)接收到这个连接请求。它会识别出这个请求是为 localabstract:aya 设定的转发规则。 adbd 守护进程在设备上作为一个新的客户端,主动去连接 localabstract:aya 这个本地套接字。Server.kt 里的 LocalServerSocket 正在监听 localabstract:aya。当 adbd 发出连接请求时,server.accept() 会返回一个与 adbd 建立连接的 LocalSocket。基于以上分析路线,电脑上的客户端发送的所有数据,都会通过以下路径传输:
PC 客户端 → PC 的 adb → USB 数据线/Wi-Fi → 设备上的 adbd → localabstract:aya 本地套接字你的服务端进程 (Server.kt)
同时,Android服务端发送的响应数据也会通过这条路径原路返回。
这种方式允许你像调试一个常规的网络服务一样,直接在电脑上与运行在 Android 设备上的程序进行交互。你不需要在设备上安装一个完整的网络服务器,也不需要担心防火墙或其他网络配置问题。adb 巧妙地为你解决了跨进程、跨设备的通信问题,将本地 IPC 流量无缝地转发到了你的电脑上。
DebugManager对接 电脑端的代码,在数据处理上几乎没有改动,将原来的安装apk流程和启动服务流程,改为了推送dex文件到设备,使用
CLASSPATH = /data/local/tmp/aya/aya.dex app_process /system/bin io.liriliri.aya.Server
来启动服务,再通过adb forward tcpip:xxxx localabstract:aya命令,把这个设备内部的本地套接字通信,映射到电脑的TCP/IP端口上。
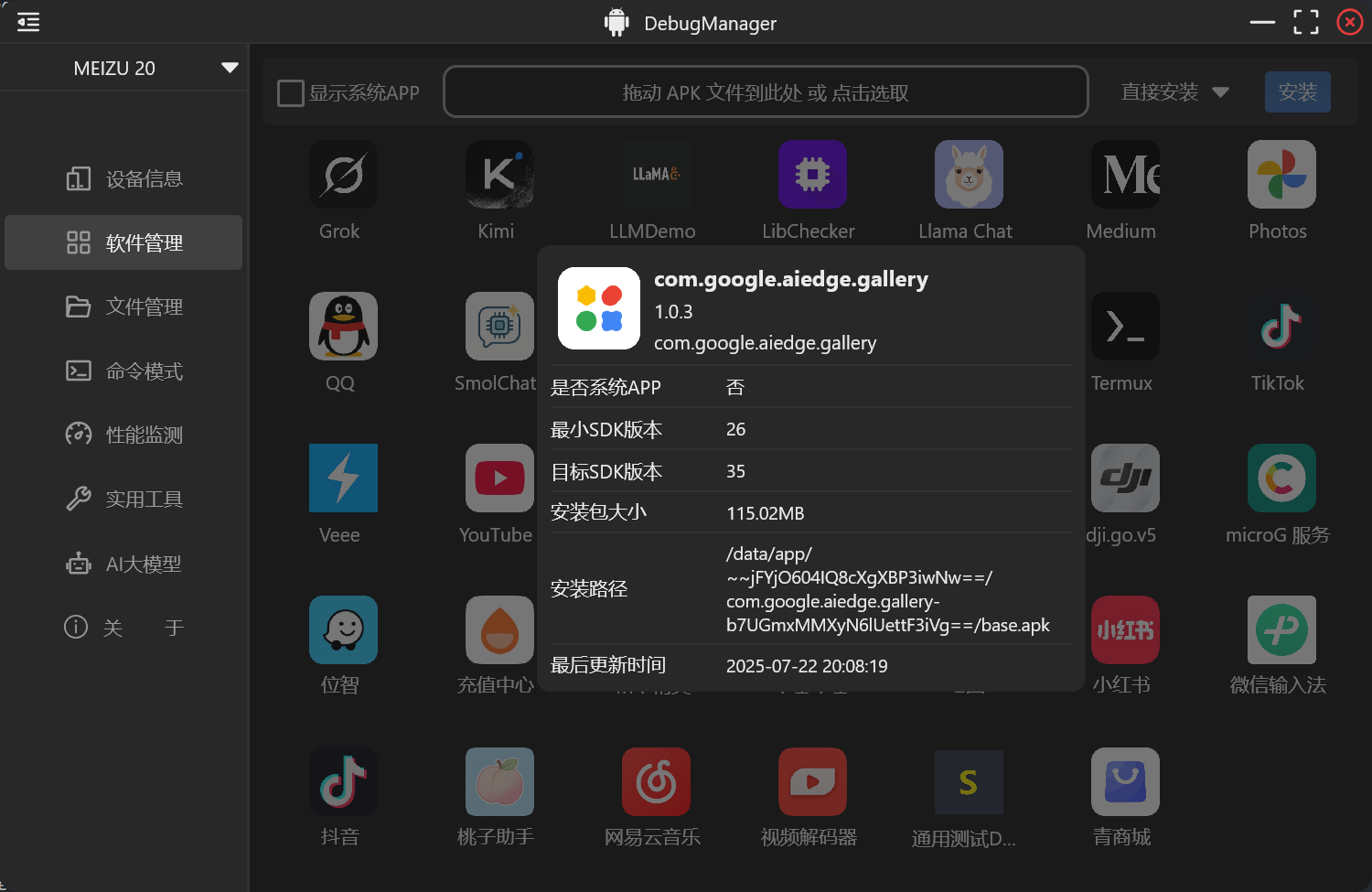
DebugManager内部,通过 adb shell pm list packages 命令,获取到所有安装的应用列表。解析出每一个包名,再调用服务端的 getPackageInfo 方法,获取应用label,版本信息。最后通过coil的AsyncImage组件,填入icon文件路径,异步加载图标。
界面升级 此前的交互也进行了同步升级,再有限的窗口内展示更多的信息,全局缩小了字号和模块之前的padding,将列表类型改为了图标矩阵,使用 LazyVerticalGrid 组件来承接应用图标展示。
详细信息弹窗:
同时为了缩小重组范围,使用应用的packageName作为key,来标识每一个item,还可以以此来实现每一个item的移动动效,比图标的体验更丝滑。
LazyVerticalGrid ( columns = GridCells . Adaptive ( minSize = 105 . dp )) {
items ( appListState . sortedBy { it . label }, key = { it . packageName }) {
Box (
Modifier . animateItem (
fadeInSpec = null ,
fadeOutSpec = null ,
placementSpec = tween ( 300 )
)
) {
GridAppItem (
label = it . label ,
iconFilePath = mainStateHolder . getIconFilePath ( it . packageName ),
modifier = Modifier . padding ( 5 . dp )
. size ( 100 . dp ). clip ( RoundedCornerShape ( 10 ))
. padding ( 5 . dp )
. bounceClick (). clickable (
indication = null ,
interactionSource = remember { MutableInteractionSource () }
) {
dialogInfoItem . value = it
},
onClickShowInfo = {
dialogInfoItem . value = it
},
onClickOpen = {
mainStateHolder . startMainActivity ( it . packageName )
},
onForceStop = {
mainStateHolder . forceStopApp ( it . packageName )
},
onExtractApk = {
mainStateHolder . pullInstalledApk ( it . packageName , it . versionName )
},
)
}
}
}
在动效方面,直接使用 animateItem 函数就可以实现列表项的移动动效。
Modifier . animateItem (
fadeInSpec = null ,
fadeOutSpec = null ,
placementSpec = tween ( 300 )
)
论题来自于 霍丙乾(Benny Huo) 在B站上的答网友问。基于其描述,详细扩展开来。
有浏览器H5套壳,为什么还要用Kotlin跨端 H5 主要是使用 Web 技术(HTML、CSS、JavaScript)来构建应用程序,然后通过 WebView(一个内嵌的浏览器组件)在不同平台的原生应用中运行。常见的 H5 跨平台框架包括 Ionic、PhoneGap (Cordova)、以及一些基于小程序(如微信小程序)的开发方式。
实现上是将 Web 应用打包成原生应用,通过 WebView 渲染界面和执行逻辑。由于运行在 WebView 中,性能通常不如原生应用,尤其是在处理复杂动画、大量数据或需要高性能计算的场景。启动速度也不如原生应用。对原生功能的访问需要借助插件。
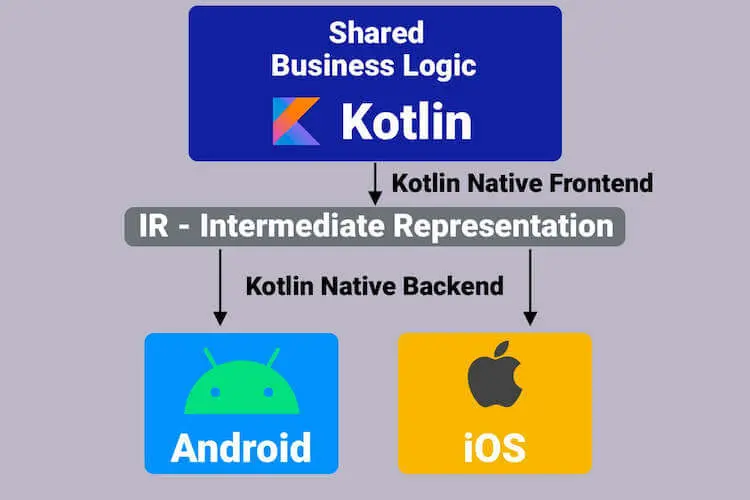
Kotlin Multiplatform (KMP) 是 JetBrains 推出的一项技术,它允许开发者使用 Kotlin 语言编写共享的业务逻辑(如数据处理、网络请求、商业规则等),并将其编译成适用于不同平台的原生代码。UI 层通常仍然使用各平台的原生技术(Android 的 Jetpack Compose/XML,iOS 的 SwiftUI/UIKit)来实现,但也支持使用 Compose Multiplatform 实现共享 UI。
Kotlin编译器会将面向不同平台的Kotlin代码直接 编译成对应平台的Native代码实现 ,可以说在每个平台上都是 原生应用 ,从性能上来说媲美原生。如果进一步使用Compose Multiplatform,则可以在各个平台上共享一套UI代码,使用 Skia 跨端渲染引擎,其性能也远高于 H5 开发。在开发周期上比 H5 长一点。体量大一点的应用一般都会追求更长远,性能更好的技术
总结起来就是:
H5 跨平台 更像是“将网页打包成应用”,优势在于开发速度快、Web 开发者门槛低,但性能和原生体验是其短板。 Kotlin Multiplatform 更像是“用 Kotlin 编写原生应用的一部分”,优势在于性能接近原生、能充分利用原生特性,并且可以灵活选择共享业务逻辑或 UI,但对开发者有一定的 Kotlin 基础要求,且 UI 部分(如果选择原生)仍需单独开发。 Kotlin/Native性能对比其他语言如何 Kotlin/Native 旨在将 Kotlin 代码编译为可以在没有虚拟机 (VM) 的情况下运行的本地二进制文件,使其适用于嵌入式设备或 iOS 等平台。Kotlin/Native 代码直接编译为机器码,因此它的执行速度通常非常快,可以与原生应用媲美。对于 CPU 密集型任务,其性能通常远优于 JVM 上的 Kotlin 或 JavaScript。
Kotlin/Native 包含一个现代的跟踪垃圾回收器。虽然自动内存管理简化了开发,但在某些情况下,GC 可能会引入微小的暂停,这可能会影响对实时性要求极高的应用。不过,JetBrains 正在不断优化其内存管理器。
同Swift相比,Kotlin不会自动回收,内存消耗会高一点,这使得其运行起来反而更快。对象在内存管理级别做了池化,创建和使用都会比Swift更快。
与 C/C++ 相比,它在以下几个方面通常存在差异。
C/C++: 提供对内存的直接控制(通过指针)、更细粒度的硬件优化(如 SIMD 指令、CPU 缓存优化)以及手动内存管理。这使得 C/C++ 成为需要极致性能和资源控制的场景(如操作系统、驱动程序、游戏引擎、高性能计算)的首选。
Kotlin/Native: 虽然性能接近原生,但它仍然是高级语言,抽象层高于 C/C++。它提供了垃圾回收机制,简化了内存管理,但也意味着开发者对内存布局和生命周期的直接控制较少。在需要极度细致的内存布局和手动优化以榨取每一丝性能的场景下,C/C++ 仍然更具优势。
非Android平台为什么不使用Kotlin/Native替代JVM 以Android平台为例,如果使用 Kotlin/Native 去绕过Android虚拟机,那么开发上,Google的api都不可以直接使用了,仍然需要套一层壳。
在移动端的另外两大平台上,KMP在开发时,是采用了类似RN的桥接调用的,腾讯在将Kotlin/Native移植到鸿蒙系统时,就是使用ArkTS包装鸿蒙的系统api,给Kotlin调用,包括IOS上也是如此实现。
对于桌面端,Compose Desktop 仍然是运行在JVM上。Windows、MACOS、Linux等桌面系统底层的差异性,想抹平是非常困难的。
目前桌面端最火的 Electron 框架为例,Electron 应用通常需要独立运行,不能依赖用户本地环境的 Chromium 或 Node.js 版本,都会自己打包一个 V8 引擎,负责解析、编译和执行应用中的 JavaScript 代码(包括前端页面逻辑和 Node.js 后端代码)。正是因为有这个附带的引擎,安装包体积高达几百M,但是其能提供的开发体验和跨平台生态是更应该关注的点。
同理,Compose Desktop没有选择直接对接操作系统,而是选择运行于 JVM 上,也是由于JVM已经把平台适配给做完了,并且提供的接口和性能已经过多年发展验证,可以很好地支持快速开发和功能达成。包括前段时间的Rust,甚至是基于浏览器来运行。
如果不谈Compose UI界面,Kotlin本身其实是可以通过Kotlin/Native直接跑在各个桌面平台上的,比如Windows端通过 Mingw(Windows系统api封装中间层)。另外也可以通过GTK来实现UI界面。
GTK(GIMP Toolkit) 是一个开源的跨平台 图形用户界面(GUI)工具库,最初为图像处理软件 GIMP 开发,现广泛用于 Linux 桌面环境(如 GNOME)以及其他操作系统(Windows、macOS)。GTK 本身是用 C 编写的,和 Kotlin 无法直接交互,Binding 充当了“桥梁”,将 GTK 的 C 语言接口通过某种方式(如 JNI、FFI 或原生库)暴露给 Kotlin,使 Kotlin 开发者能直接调用 GTK 的功能来构建 GUI 应用。
Compose IOS 的一些坑 Kotlin 最开始是和OC互调用的,后来的2.1版本才开始转向和 Swift 互调用。IOS开发端,Cocapods 处于不维护的存量状态,整体在往Swift生态迁移,后面会全面转向Swift了。
腾讯视频 在IOS上自研了一套渲染引擎,因为要兼容大量的原生存量代码,前期只能小范围替换,省掉了一个渲染层的内存。在鸿蒙端是纯以来CMP的Skia了。
混合开发的时候,内存,画布开销。 单独的View容器需要自己管理生命周期。 列表组件单独嵌入到原生容器,可能开发上会比较麻烦,处理手势。 和 OC 互操作方面,类的导出有很多限制。和Swift应该差不多,也会有这些限制。编译的时候不会发现,运行时才知道,
霍老师在腾讯云开发者平台上发布的Kotlin/Native的文章,详细列出了这些限制的问题。
深入理解Kotlin/Native
互操作尽可能少,导出一些工具函数等。
能做到三大移动端一把梭哈吗 前段时间 Jetbrains 发布通知,CMP的IOS端已经稳定。
在鸿蒙端,腾讯视频团队已经实现了比较稳定的方案,在和Jetbrains沟通能否贡献到官方代码中。
所以技术上Android、IOS、鸿蒙三端共用是没有问题的。
CMP和RN和Flutter的对比 此前已经对比过一次三者的易用性,性能,渲染方式上的差异。 差异。
Kotlin Multiplatform 对比 React Native 和 Flutter
CMP最大的优势还是来自于Kotlin,在各个平台上,编译完后都是Native实现。另外在UI渲染上采用Skia,性能优于RN,持平Flutter。
能否替代Flutter?
有潜力,但是CMP的潜力不止于替换Flutter,Kotlin编译器编译完的代码,在框架上和原生开发无异,胃口大一点问问是否可以替代原生。
每个平台都有最合适的原生代码,CMP三段一码的开发成本,对大型app诱惑还是很大,成本和收益都是需要考虑的。
CMP前景如何 CMP前景依托于Kotlin跨端的前景。
Kotlin跨平台是语言特性,而不是框架,并没有做一个中间层来转换。
Kotlin中可以直接访问C的结构体。
以Java生态要求Kotlin,还是有很长的路要走。
Compose的WebAssembly,也是 Jetbrains 官方下一阶段的重点,IOS端已经稳定。
相比其他的框架,其问题在于正是因为到处都是Native,就需要 对这个target的原生环境有一定了解 。知道如何去调用原生的API,比如处理内存,处理生命周期,处理手势等。
在IOS上写代码,就需要对Swift有一定了解,依赖原生api去配置。
ovCompose 腾讯视频团队推出的跨平台开发框架ovCompose以及相关基础库KuiklyBase,旨在解决跨平台开发中的一些痛点问题,并推动Compose跨端生态的发展。
项目背景 跨平台需求:随着鸿蒙系统的推出,客户端跨平台开发的需求显著增加。传统的UI跨端方案已无法满足业务需求,全跨端APP(覆盖Android、iOS和鸿蒙)的开发成为降低开发成本和提升效率的关键。 现有技术的局限性:尽管Kotlin Multiplatform具备高性能和灵活的原生交互能力,但它存在一些问题,如不支持鸿蒙系统、iOS混排能力受限以及GC性能表现一般等。 ovCompose和KuiklyBase的特性优势 鸿蒙高性能:KuiklyBase选择了Kotlin Native(KN)作为鸿蒙适配方案,相比JavaScript(JS)具有更快的执行速度和更好的三端一致性。通过性能优化,如内联优化、ThreadLocal优化等,显著提升了执行效率。 鸿蒙三明治架构支持混排:利用Skia渲染方案和XComponent组件,解决了Compose与原生组件的混排问题,支持粘贴按钮等安全组件的混排。 三端高一致性:通过Kotlin Native方案解决了跨线程访问问题,保持了逻辑运行的一致性。同时,iOS和鸿蒙平台均采用Skia渲染,确保了UI绘制的一致性。 iOS多模态渲染:采用指令映射方案,解决了Compose在iOS上的混排难题,并实现了与原生UI的灵活混排。 Kotlin Native内存优化:包括GC优化(如GC抑制、分段GC、Sweep优化)和堆Dump优化,显著提升了内存管理效率。 KuiklyBase组件生态:提供了丰富的组件,如异常堆栈还原组件、跨语言互调用组件、资源管理组件、原子操作组件、协程组件、序列化组件等,为开发者提供了强大的支持。 实现原理 KN鸿蒙平台适配:通过在Kotlin IR转LLVM IR时使用苹果的LLVM 11,在LLVM IR生成可执行文件时使用鸿蒙的LLVM 12,解决了鸿蒙平台的适配问题。 KN性能优化:包括内联优化、ThreadLocal优化、协程性能优化、调试性能优化等,显著提升了Kotlin Native在鸿蒙平台上的性能。 鸿蒙绘制不同步问题解决:通过采用XComponent的Texture模式,解决了Compose与ArkUI绘制不同步的问题。 iOS多模态渲染:设计了基于iOS的PictureRecorder局部更新架构,通过增量hash减少hash计算量,优化了绘制效率。 开源信息 开源仓库:ovCompose和KuiklyBase已在GitHub开源,包含5个仓库,地址为:https://github.com/Tencent-TDS
未来计划 持续优化:重点优化GC在业务场景的表现、Kotlin-Native组件化、开发体验优化以及UIKit渲染模式与Skia的进一步对齐。 扩展支持:计划将ovCompose和KuiklyBase扩展到TV和PC端,进一步完善跨平台开发框架。 与KuiklyUI的差异 KuiklyUI:侧重于静态化+动态化双运行模式,采用轻量原生渲染,支持H5和小程序。 ovCompose:专注于全面对齐Compose Multiplatform标准API,采用自渲染方式实现鸿蒙平台的适配,确保三端高度一致性。 背景 最近对CMP跨平台很感兴趣,为了练手,在移动端做了一个Android和IOS共享UI和逻辑代码的天气软件,简单适配了一下双端的深浅主题切换,网络状态监测,刷新调用振动器接口。
做了两年多车机Android开发,偶尔玩下手机端跨平台也蛮有意思。
然后又了解到CMP不仅仅是移动端的,还可以做web和desktop端。
在我们日常的开发过程中,对于车机设备的adb调试操作很多,一大半全是固定的流程。使用bat脚本的话又不那么灵活,体验也不好。所以我很早就想要做一个带界面的Android设备调试工具。在移动端上写纯原生的Compose界面比较熟悉了,想着这个估计也差不多的,就开启了为期一个多月的Compose for Desktop开发。开发体验可以算中上,很多的问题在stackoverflow和官网上都能找到方案。软件命名为DebugManager。
架构设计 我没有开发Desktop端的经验,不知道最优的架构设计是什么样的。使用CMP的话Google推崇的MVI模式依然可以通用,所以最初制定的技术路线就是使用响应式的架构。
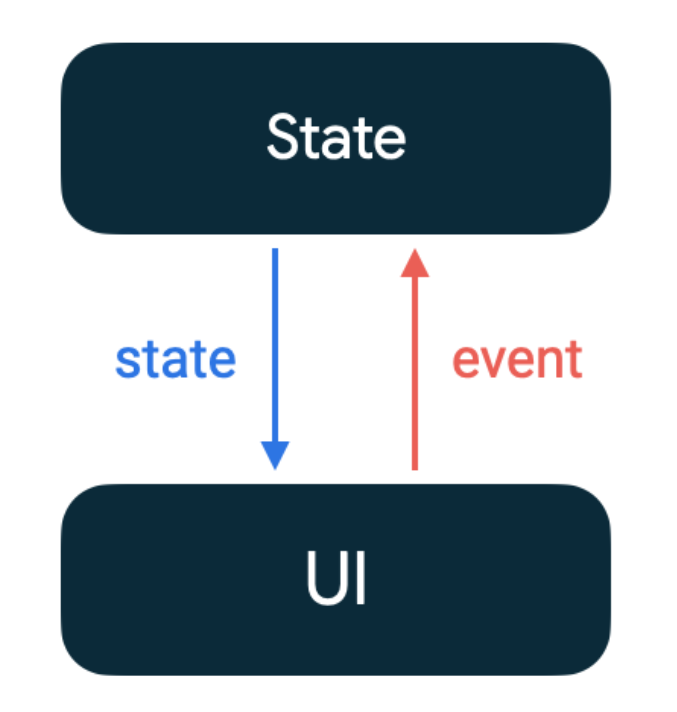
由于功能单一,几乎所有操作都是执行一些命令行,获取反馈结果,所以没有抽象的很厉害,数据层直接使用单例类,使用adb工具获取数据透传到StateHolder。StateHolder为界面的状态State管理层,在Composable方法初入时,触发StateHolder的数据获取逻辑,数据拿取到之后,更新State状态,通过界面收集监听的stateflow通知composable方法刷新UI。
即用户事件从上到下,数据状态从下到上,确保唯一可信数据流。
gradle配置 这一步决定DebugManager项目面向的各个平台的配置,软件版本,安装包。
由于这个软件面向不同岗位,不同操作系统,目标是一套代码适配Windows,Linux,MacOS,达到多端通用。而且目前没有交叉编译,只能在各自的系统上打包,windows打exe,ubuntu上打deb,macos上打dmg,所以我现在给使用不同系统的同事发布软件时,都是三端各打一遍。
Windows端有配置是否显示在开始菜单,桌面快捷方式,uuid用于更新识别,自行选择安装目录。
// 开始菜单
menu = true
// 桌面快捷方式
shortcut = true
// 可自行选择安装目录
dirChooser = true
// 可单独为当前用户安装,不需要管理员权限
perUserInstall = true
// 设置图标
iconFile . set ( project . file ( "launcher/icon.ico" ))
// uuid用于更新识别
upgradeUuid = "xxxx-xxxxxxx-xxxxx"
更详细的Gradle属性配置参考可以看官方github仓库的教程文档: JetBrains官方配置文档
图标配置 关于三个平台应用图标的设置,我们需要手动制作三端的图标文件。
ICON图标在线制作
图片切圆角,可以使用这个网站:
在线对图片进行透明圆角处理
注意 Mac 端的图标需要使用苹果电脑才能生成。
首先我们切到png格式的图片所在的目录,执行下面三组命令即可生成Mac端的图标文件了。第一步创建输出文件夹:
输入这些命令来生成不同尺寸的图标:
sips -z 16 16 original.png --out MyIcon.iconset/icon_16x16.png
sips -z 32 32 original.png --out MyIcon.iconset/icon_16x16@2x.png
sips -z 32 32 original.png --out MyIcon.iconset/icon_32x32.png
sips -z 64 64 original.png --out MyIcon.iconset/icon_32x32@2x.png
sips -z 128 128 original.png --out MyIcon.iconset/icon_128x128.png
sips -z 256 256 original.png --out MyIcon.iconset/icon_128x128@2x.png
sips -z 256 256 original.png --out MyIcon.iconset/icon_256x256.png
sips -z 512 512 original.png --out MyIcon.iconset/icon_256x256@2x.png
sips -z 512 512 original.png --out MyIcon.iconset/icon_512x512.png
sips -z 1024 1024 original.png --out MyIcon.iconset/icon_512x512@2x.png
最后合成不同尺寸的图标:
iconutil -c icns MyIcon.iconset
之后就可以看到一个后缀为icns的文件了,将其复制到项目中,gradle脚本里配置为应用图标。
图标配置过程中的bug 目前还发现一个奇怪的bug,就是有的png图标经过转换,配置到项目中,打包exe出来是正常大小,大概90M。
有的图片生成完毕之后,Windows平台打包后的 EXE 安装包大小直接暴涨到了2个G,甚至3个G,目前不确定什么原因导致的。还在排查和寻求官方的帮助。
解决
经过几轮尝试排查,问题应该出在那个windows平台的转换网站上:
https://www.butterpig.top/icopro/
通过 IDE 打开生成的ico文件,发现其实际的文件类型是JPEG,并不是显示的ico文件。
“假icon!!”
目前怀疑图标类型错误,导致安装包暴涨。会产生这个现象的原因,可能是CMP所使用的Windows打包器的一个bug或者说一个规则吧。
使用Python的Pillow库来转换,发现生成的图标文件显示的是我需要的ICO类型了。
转换脚本很简单,如下:
from PIL import Image
def png_to_ico ( png_path , ico_path ):
# 打开PNG图像
image = Image . open ( png_path )
# 将图像转换为ICO格式
image . save ( ico_path , format = 'ICO' , sizes = [( image . width , image . height )])
# 调用函数并传入PNG图像路径和ICO文件路径
png_to_ico ( 'C: \\ Users \\ stephen \\ Desktop \\ logo.png' , 'output.ico' )
转换后的图标文件:
将这个 ico 文件配置到项目之后,打包的大小已经恢复正常的90余M。
开发Desktop跨平台碰到的的第一个问题,就是不同平台的路径连接符不一致:
在Windows上是反斜杠 \
在unix like的系统上是一个正斜杠 /
经过探索,JVM系的应用其实可以使用 File.separator 来获取这个连接符拼到路径字符串里。
而且关于平台类型的区分,Java也给我们提供了一个 System.getProperty 接口。
单例模式 在Windows平台上,多次通过入口来运行exe文件,会产生多个进程,对于本软件是没有必要的,甚至有可能导致bug。
所以需要像任务管理器那样,不管有多少次的打开动作,始终只有一个进程一个界面。
这里通过文件锁的方式来实现。
刚开启进程就创建一个文件,并将其锁定。在JVM关闭的时候,释放并删除这个文件。这样如果软件已经有一个进程在运行了,再次打开时尝试去获取这个文件的独占锁,如果获取不到,就说明已经有一个实例在运行,直接退出后打开的这个进程。
class SingleInstanceApp {
private var lock : FileLock ? = null
private var channel : FileChannel ? = null
fun initCheckFileLock ( lockFilePath : String ) {
LogUtils . printLog ( "initCheckFileLock" )
val file = File ( lockFilePath )
channel = RandomAccessFile ( file , "rw" ). getChannel ()
lock = channel ?. tryLock ()
if ( lock == null ) {
LogUtils . printLog ( "Another instance is already running." , LogUtils . LogLevel . ERROR )
exitProcess ( 1 )
}
// 添加JVM关闭时的钩子,释放锁
Runtime . getRuntime (). addShutdownHook ( Thread ( Runnable {
runCatching {
lock ?. let {
it . release ()
channel ?. close ()
file . delete ()
}
}. onFailure { e ->
e . printStackTrace ()
}
}))
}
}
通过依赖注入到平台化的管理类中去,init方法中,当配置文件夹一创建完毕,就进行获取锁的操作。
class PlatformAdapter ( private val singleInstanceApp : SingleInstanceApp ) {
init {
println ( "PlatformAdapter init" )
}
fun init () {
createInitTempFile ()
singleInstanceApp . initCheckFileLock ( lockFilePath )
}
}
平台渠道管理 首先,定义一个枚举类来设定平台类型:
enum class PlatformType {
UNKNOWN ,
WINDOWS ,
MAC ,
LINUX ,
}
在应用初始化时,通过接口获取平台名称,解析出哪一个平台:
/**
* 获取当前平台类型
*/
private fun getPlatformType (): PlatformType {
val osName = System . getProperty ( "os.name" ). lowercase ( Locale . getDefault ())
return when {
osName . contains ( "win" ) -> PlatformType . WINDOWS
osName . contains ( "mac" ) -> PlatformType . MAC
osName . contains ( "nix" ) || osName . contains ( "nux" ) || osName . contains ( "aix" ) -> PlatformType . LINUX
else -> PlatformType . UNKNOWN
}
}
后面在涉及平台差分化的时候,可以使用此方法来获取,执行不同操作。
比如打开不同平台上的文件管理器:
/**
* 打开一个文件夹
*/
fun openFolder ( path : String ) {
when ( getPlatformType ()) {
PlatformType . WINDOWS , PlatformType . UNKNOWN -> {
executeTerminalCommand ( "explorer.exe $path" )
}
PlatformType . MAC -> {
executeTerminalCommand ( "open $path" )
}
PlatformType . LINUX -> {
executeTerminalCommand ( "xdg-open $path" )
}
}
}
对于各个平台上执行终端命令,使用的两个方法是相同的,无需结果就直接exec(),需要执行结果就是用ProcessBuilder来执行,等待结果。
/**
* 执行终端命令
*/
fun executeTerminalCommand ( command : String ) {
runCatching {
Runtime . getRuntime (). exec ( command )
}. onFailure { e ->
LogUtils . printLog ( "执行出错:${e.message}" , LogUtils . LogLevel . ERROR )
}
}
/**
* 执行命令,获取输出
*/
suspend fun executeCommandWithResult ( command : String ) = withContext ( Dispatchers . IO ) {
val processBuilder = ProcessBuilder (* command . split ( " " ). toTypedArray ())
val process = processBuilder . start ()
val reader = BufferedReader ( InputStreamReader ( process . inputStream ))
val output = StringBuilder ()
var line : String ?
while ( reader . readLine (). also { line = it } != null ) {
output . append ( line ). append ( "\n" )
}
// 等待进程结束
process . waitFor ()
// 关闭输入流
reader . close ()
output . toString ()
}
窗口框架 新项目的应用入口如下:
fun main () = application {
Window (
onCloseRequest = {
},
title = "DebugManager" ,
undecorated = true ,
state = windowState ,
icon = painterResource ( "image/icon.png" ),
) {
....
}
}
我们主要的内容区就在Window这个 Composable 方法里。
通过 windowState ,我们可以设置窗口初始大小,窗口最大最小化。
undecorated 参数,这个可以配置软件界面是否选择系统默认的标题栏。由于我希望在三端上的设计语言都可以统一,都使用我自定义的标题栏,所以这里改为设置 true 。
有意思的一点是,在最开始将 undecorated 设为 true 后,我发现用上的Compose自定义的标题栏后,无法使用鼠标拖动窗口了,一度试了很多方案都不行。
这里最后还是咨询谷歌的 Gemini ,它给我展示了一个 WindowDraggableArea 组件,居然直接套用即可完美解决,里面的区域就是支持拖动移动的。把标题栏的 Composable 方法放在这个 WindowDraggableArea 可组合项里面,就可以鼠标拖动标题栏来移动窗口了。
WindowDraggableArea 源码方法签名如下:
@ androidx . compose . runtime . Composable
@ androidx . compose . runtime . ComposableInferredTarget
public fun androidx . compose . ui . window . WindowScope . WindowDraggableArea (
modifier : androidx . compose . ui . Modifier = COMPILED_CODE ,
content : @ androidx . compose . runtime . Composable () -> kotlin . Unit = COMPILED_CODE
): kotlin . Unit { /* compiled code */
}
关于各个页面之间的导航切换,我是使用的官方扩展的跨平台版本的 navigation 库。定义导航图,然后使用 navController 来切换页面。
val navController = rememberNavController ()
NavHost ( navController = navController , startDestination = "device_info" ) {
composable ( "device_info" ) {
DeviceInfoScreen ( navController = navController )
}
.. .
}
每次启动应用,DebugManager 应用开屏页面,做的简单的延时跳转,timeout后自动进入主页面。
功能划分 下面简单介绍下各个页面的调试功能有哪些。
在公司,一般的开发流程里有产品设计,有交互设计,UI设计,给我传达需求,输出资源。
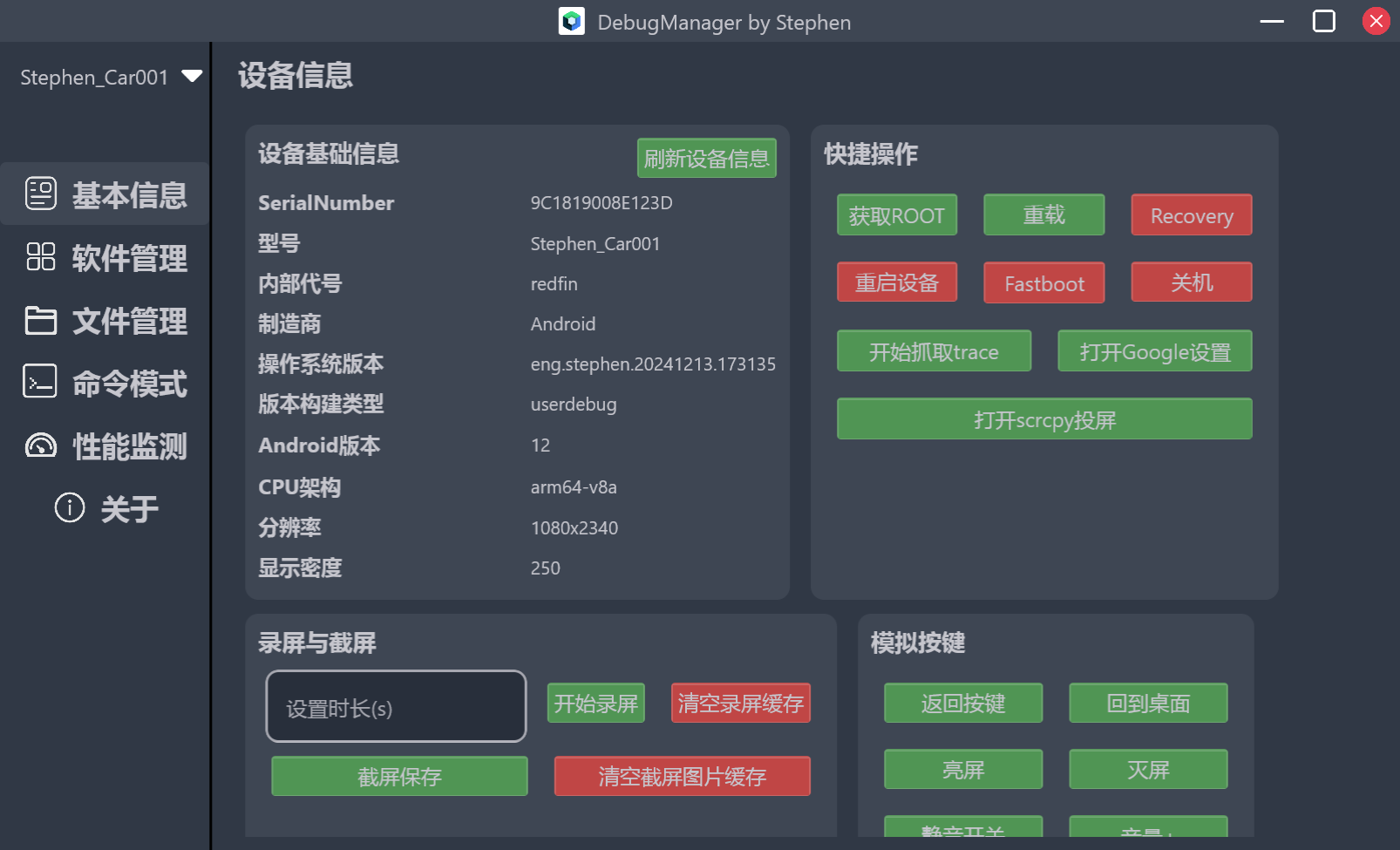
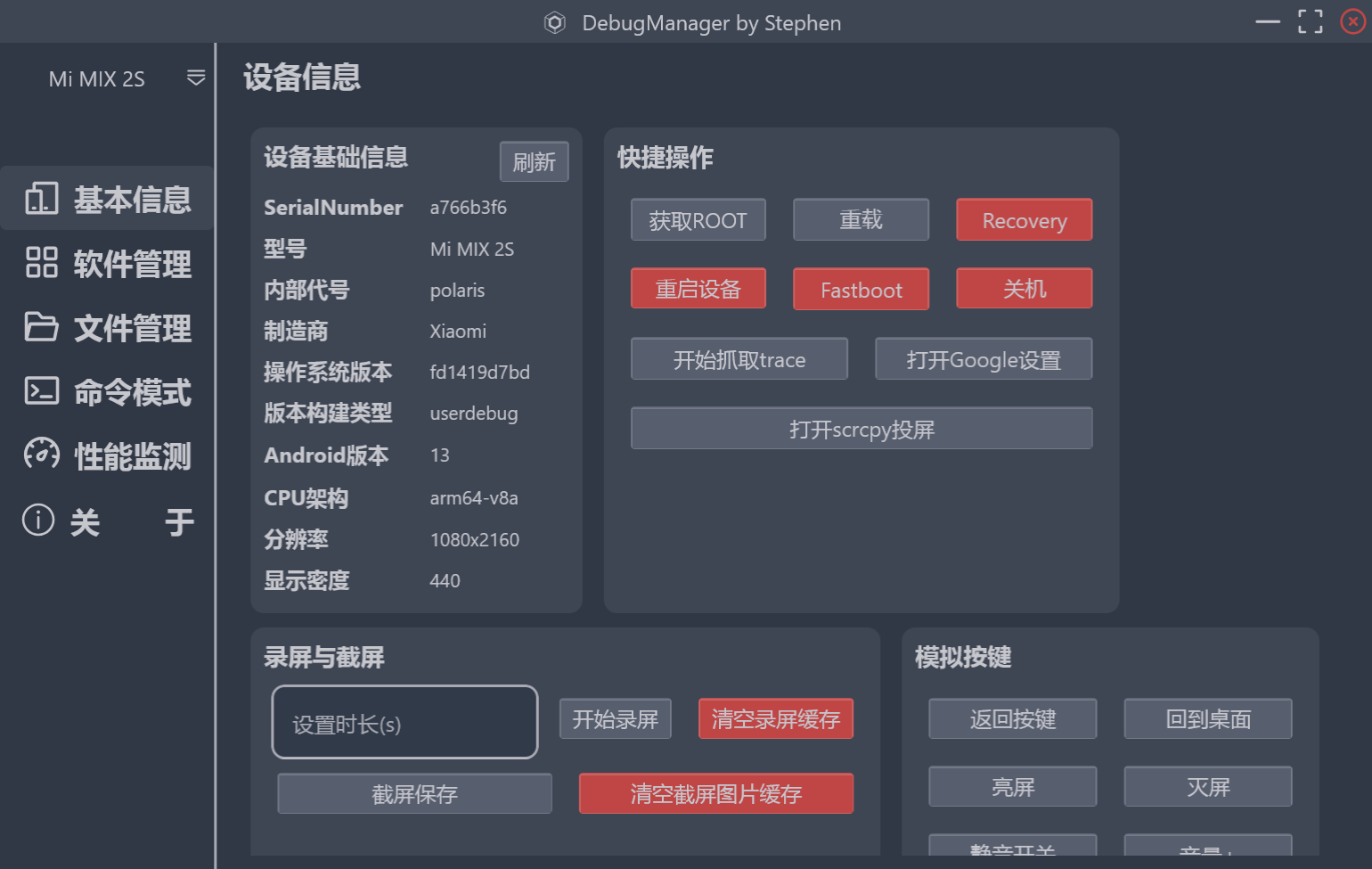
产品的功能设计上,这个软件自己心血来潮要做。我结合日常工作中的调试痛点,还参考了 adb 的命令介绍,选取了一些热门的组合功能和单次功能,分类添加到了界面内。 在界面UI设计风格上,我是直接参考了每天打开的 Android Studio 里的主题插件, Atom One Dark 的颜色风格。 设备信息展示 一进入界面,首页当然是所连接设备的基本信息展示。
大致的实现思路如下,关于界面状态,先定义 UiState :
data class DeviceState (
val name : String ? = null ,
val manufacturer : String ? = null ,
val sdkVersion : String ? = null ,
val systemVersion : String ? = null ,
val buildType : String ? = null ,
val innerName : String ? = null ,
val resolution : String ? = null ,
val density : String ? = null ,
val cpuArch : String ? = null ,
val serial : String ? = null ,
val isConnected : Boolean = false
) {
fun toUiState () =
DeviceState (
name = name ,
systemVersion = systemVersion ,
manufacturer = manufacturer ,
sdkVersion = sdkVersion ,
buildType = buildType ,
innerName = innerName ,
resolution = resolution ,
cpuArch = cpuArch ,
density = density ,
serial = serial ,
isConnected = isConnected
)
}
定义好界面所需要展示的字段,再在StateHolder里维护一个StateFlow,同时对界面层暴露一个只读的字段,用于刷新界面数据。
// 单个设备信息
private val _deviceState = MutableStateFlow ( DeviceState ())
val deviceStateStateFlow = _deviceState . asStateFlow ()
进来界面后,在协程中获取数据,界面拿到update后的数据之后自动更新信息:
CoroutineScope ( Dispatchers . IO ). launch {
prepareEnv ()
val deviceName = .... .
_deviceState . update {
it . copy (
name = deviceName ,
manufacturer = manufacturer ,
sdkVersion = sdkVersion ,
systemVersion = systemVersion ,
buildType = buildType ,
density = displayDensity ,
innerName = innerName ,
resolution = displayResolution ,
cpuArch = architecture ,
serial = serialNum
)
}
_deviceState . value = _deviceState . value . toUiState ()
// 初始化获取文件列表
getFileList ()
}
右侧的一堆按钮,是一些高频使用的功能。
简单的像reboot,root等,还有使用am打开隐藏app的界面,使用perfetto抓取trace,自动拉取到电脑端。
其中执行qnx命令为车机特有,现在市面上车机Android大多是运行在QNX系统上的子系统,DebugManager还可以直接桥接到QNX系统,执行更底层更精准的命令,比如执行reset重启整个IVI系统,而不只是reboot重启Android子系统。
录屏,截屏很实用,不用掏出手机到处找角度。我们提前设置好时长,通过自动执行多条指令,等操作完毕,可以直接将截屏录屏文件导出到电脑进行分享,也是我认为最好用的功能之一。
最下面还有一些基础的音量加减,模拟输入法输入等。
轮询查询机制 值得一提的是,我加入了循环获取连接设备数量和当前连接状态的机制,当电脑端的adb服务一初始化成功,就立即开启一个死循环的协程,每2s会查询一次当前设备的连接状态,设备数量。
private fun recycleCheckConnection () {
CoroutineScope ( Dispatchers . IO ). launch {
while ( true ) {
delay ( 2000L )
runCatching {
// 通过系统命令,检索连接设备的数量是否变化
val deviceCount = ....
if ( deviceCount != _deviceMapState . value . deviceMap . size ) {
getDeviceMap ()
MainScope (). launch {
delay ( 800L )
getCurrentDeviceInfo ()
}
}
// 检索当前设备连接状态
val result = ....
// 从断开到成功连接,主动刷新一次设备信息
if (! isConnected ) {
getCurrentDeviceInfo ()
}
isConnected = true
_deviceState . update {
it . copy (
isConnected = true ,
)
}
_deviceState . value = _deviceState . value . toUiState ()
}. onFailure { error ->
LogUtils . printLog ( "${error.message}" , LogUtils . LogLevel . ERROR )
isConnected = false
_deviceState . update {
it . copy (
isConnected = false ,
)
}
_deviceState . value = _deviceState . value . toUiState ()
}
}
}
}
当增减设备时,刷新设备列表,左上角展开后可以选择不同的设备进行调试。 当现在操作的设备断开连接时,会自动切换成其他设备,如果没有其他设备,就弹出警告弹窗,不允许继续操作页面了。 这两个都是轮询的。所以在重新连接设备后,会将当前状态通过state发送到界面,警告弹窗会自动消失。
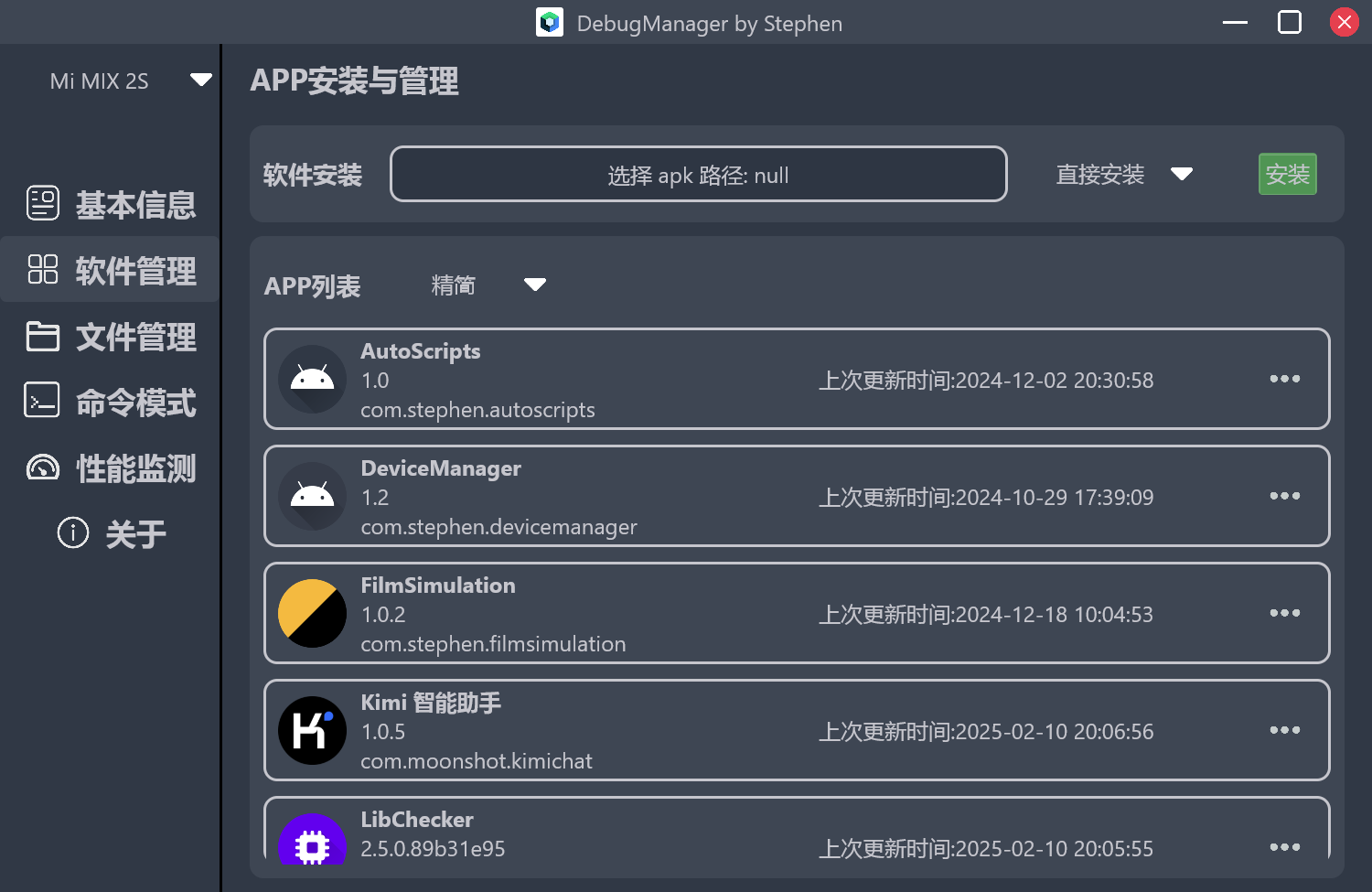
软件安装管理 这个功能是耗时最长的板块之一,主要是Android系统里面每个包的信息如何展示,如何进一步对其进行替换,结合工作中积累的命令,在全网收集了很多指令,来实现软件包的管理功能。
APP列表加入了全部包扫描和三方包扫描,对于公司定制的包,也添加到了单独的筛选规则,可以自由选择查看全量信息和精简信息。
最上面是安装功能,是使用adb install进行的操作,适合第三方app进行验证时,或者改bug进行非正式环境的验证时使用。下拉框展开后,可以选择覆盖安装,测试安装等,对应-r,-t等带参数的 install 操作。
界面展示了app的图标,版本号,包名,更新时间等。
应用图标怎么拿到的? 网上大多数的方案是说抠出apk,使用apktool解包,找到图标文件,再拿来显示。可行的确可行,但是这个速度要等到天荒地老了。
因为我之前做过一个Android端的简单的app管理应用,我选择的路线是,提前在AndroidStudio里开发一个服务app,里面设置一个Service,启动后扫描所有的已安装的app,将应用图标,应用label,包名都存到Android本地。再将这个apk内置到DebugManager安装目录的resources目录下,将其安装进系统,准备好资源后,通过adb pull拉出所需要的资源到电脑端,再读取png文件来显示到界面上。
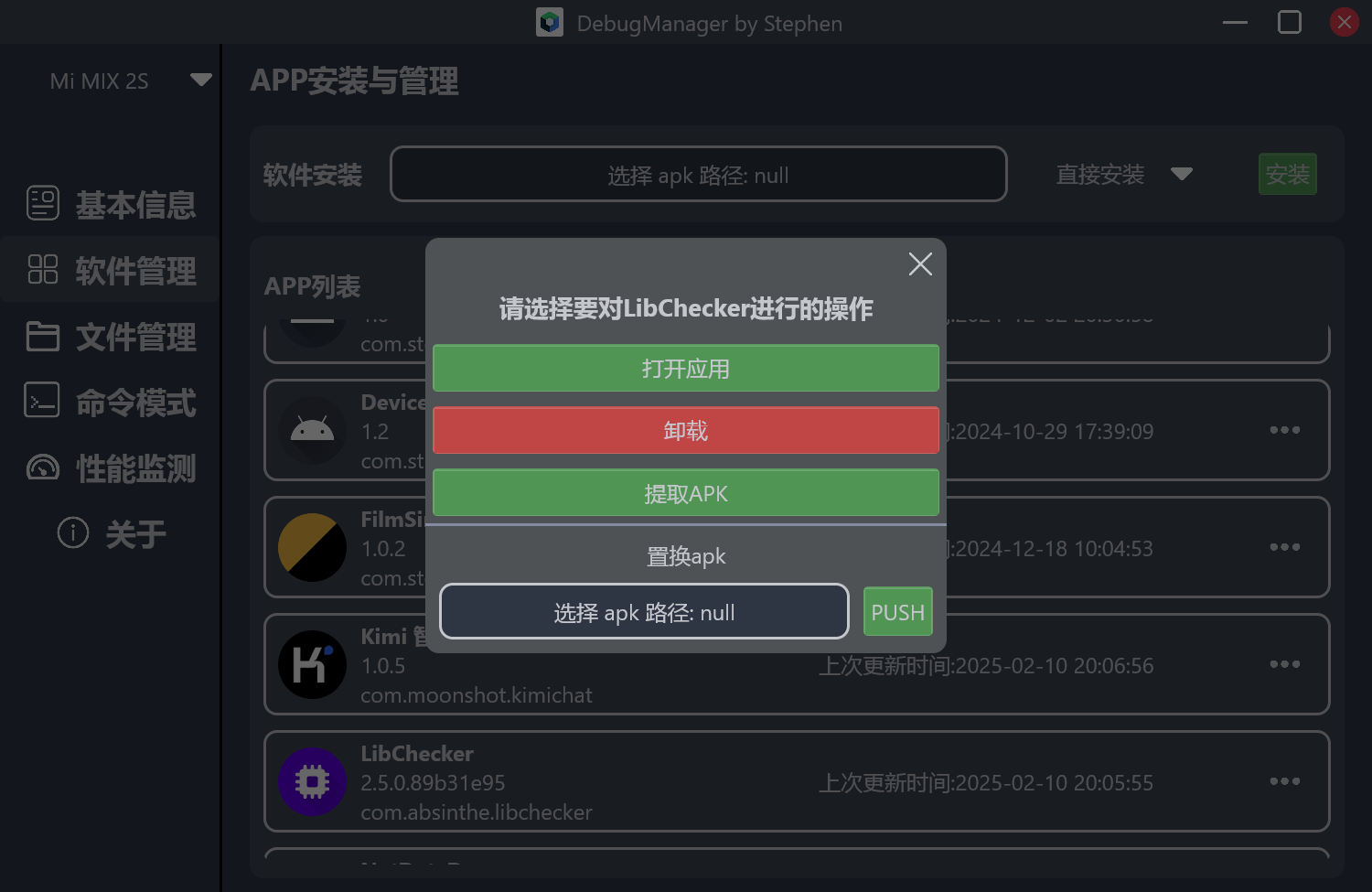
单个app的操作
对于选中的单个app,提供了打开应用界面,卸载,提取apk,对于系统应用,还可以push替换apk等操作。我们的测试同事在做非全量的发版验证时非常有用,不用再使用一条条繁琐的命令来替换apk升级了。
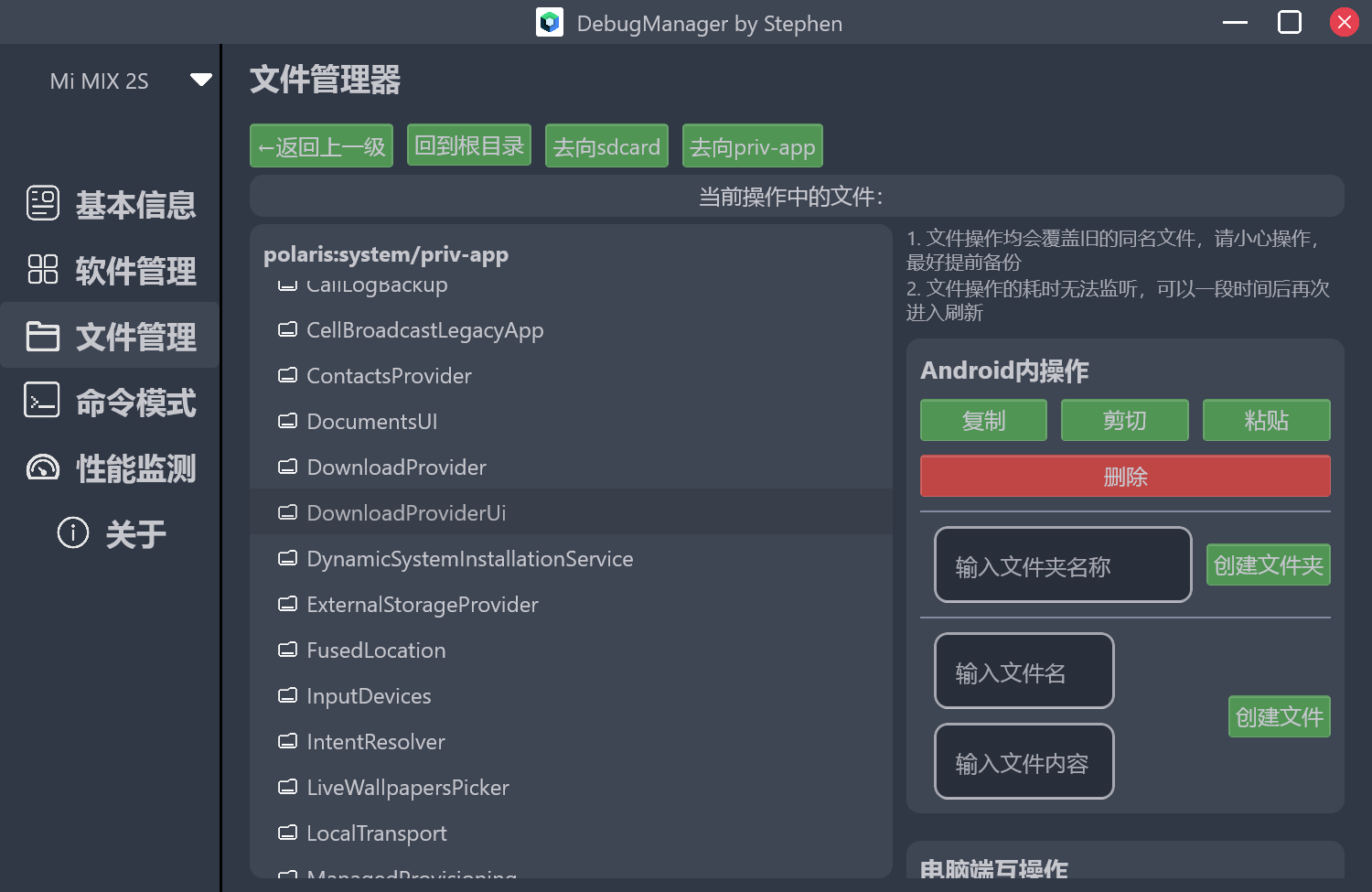
文件管理器 由于我在Android端也没有写过文件管理器应用,所以在这个页面,有些操作也是一拍脑袋想出来的,可能不算规范的解法。仍然是MVI架构,界面去监听StateHolder里面的UiState的Flow,切换目录时重新获取列表数据,update到界面来刷新UI。
最开始的展示列表我是直接执行了”ls /”将列表发送到界面,显示根目录,解析出其中的文件文件夹,继续往子目录的话就把路径拼接起来,比如进入sdcard,就执行”ls /sdcard”,继续深入则再次拼接。同时最上方设置了返回上级,回到根目录和priv-app快捷按钮。
展示文件列表的就是@Composable LazyComuln方法。
有意思的是,我在加入item的双击和单击的区分时,最初想给Modifier定义一个扩展方法,直接实现双击回调。但是发现必须经过clickable方法来实现,这样会把外部的单机的clickable给挤掉。所以双击判断还是写在了同一个clickable里面,通过时间间隔判断的工具类来区分,单击则选中对应的文件/文件夹,双击则进入文件夹。
modifier = Modifier . clickable {
// 点击则设置即将操作的path
MainStateHolder . setSelectedFilePath ( it . path )
androidSelectedFile = MainStateHolder . selectedFilePath
// 双击,执行操作
if ( DoubleClickUtils . isFastDoubleClick ()) {
if ( it . isDirectory )
destinationCall ( it . path )
else
println ( "点击文件:${it.path}" )
}
}
android内的文件操作也是使用命令行的形式,cp mv rm等。
还可以将文件pull到电脑端,将电脑端的文件推送到Android端等。
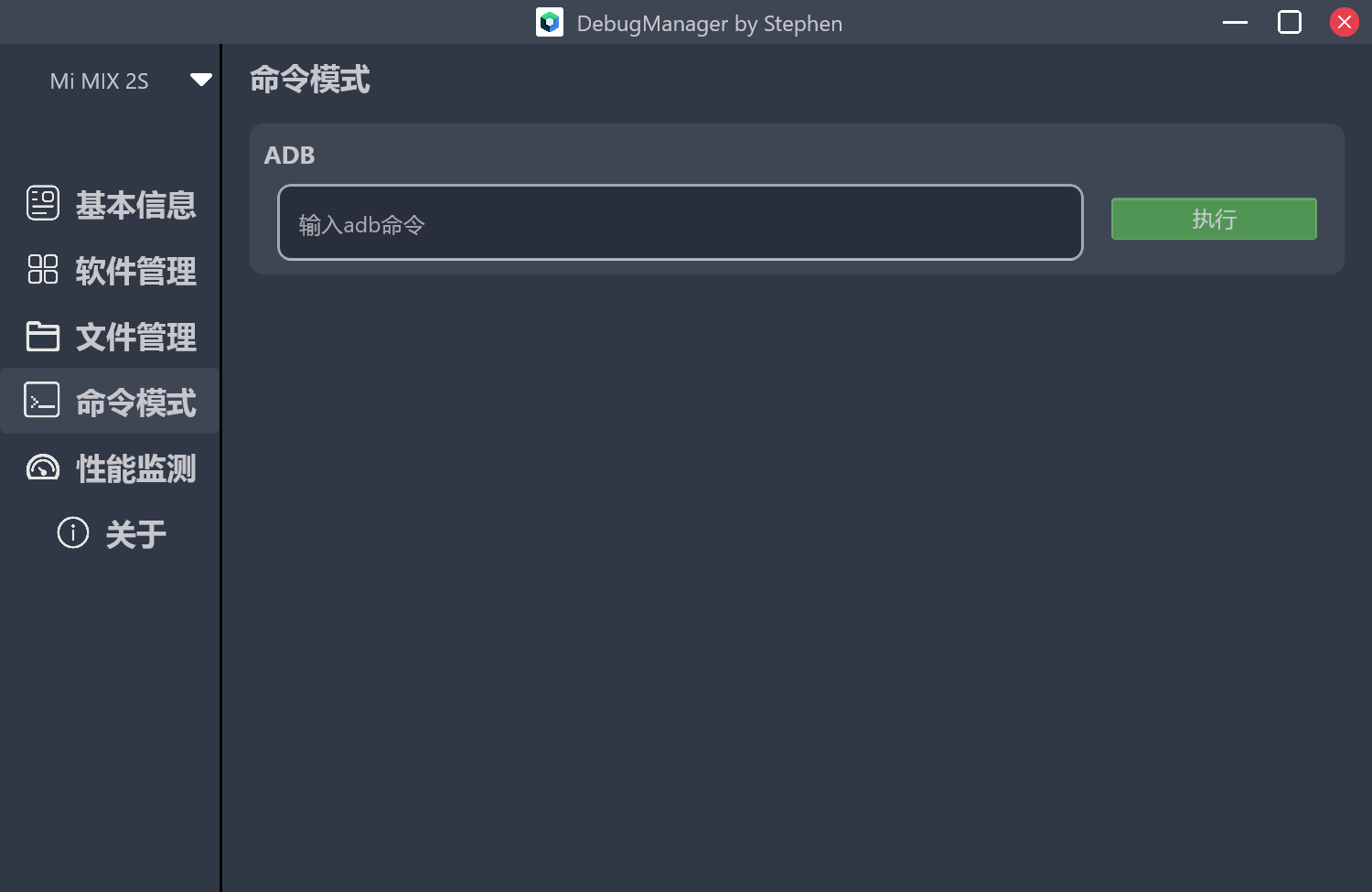
命令模式
这一页比较简单,大家看到的输入框也是Compose原生的TextField方法,还自带动画,性价比蛮高。
主要实现就是将输入框的内容,拼接后直接通过Runtime.getRuntime().exec(command)执行即可。
除了最基础的adb命令透传,配合系统厂商Android端的可执行二进制程序,可以模拟车载信号的回调操作。还有语音部门的通过广播来调试的路径,整合到了DebugManager里面,一键发送广播,模拟可见扫描的点击。
关于页
最后就是关于页了,显示软件版本,缓存文件目录等。通过PlatformAdapter工具类获取路径,执行打开界面即可。
开源计划 这个软件最初是基于公司业务来设计开发的,有关于公司内部的信息需要抹除。 等后续有时间我会将其功能进行略微删减,改成通用性质的Android调试工具之后,会开源到Github。对CMP跨平台感兴趣的朋友,可以加关注稍作等待,后面一起进行技术交流。
12月25日已完成剥离修改开源: DebugManager开源地址
Material Design主题切换 目前进一步导入了两套主题方案,深色和浅色。
将最高级的 Composable 可组合项使用 MaterialTheme 包裹起来,初始化获取theme的值。主题值的下发设置在了 关于页面 ,操作后的存储使用跨平台版本的 DataStore 来做键值对存储。
并通过StateHolder管理器来维护这个主题状态。在切换之后,最顶级的 Composable 组合项可以立即作出反应,切换色值资源。
MaterialTheme (
colors = when ( themeState . value ) {
ThemeState . DARK -> DarkColorScheme
ThemeState . LIGHT -> LightColorScheme
else -> if ( isSystemInDarkTheme ()) DarkColorScheme else LightColorScheme
}
) {
SplashScreen {
XXXXXXXXXXX
}
}
MainStateHolder.kt
// 主题
private val _themeState = MutableStateFlow ( ThemeState . DEFAULT )
val themeStateStateFlow = _themeState . asStateFlow ()
private val themePreferencesKey = stringPreferencesKey ( "ThemeState" )
/**
* 下发主题切换,存储在dataStore中
*/
fun setThemeState ( themeState : Int ) {
CoroutineScope ( Dispatchers . IO ). launch {
dataStoreHelper . dataStore . edit {
it [ themePreferencesKey ] = themeState . toString ()
}
}
_themeState . update {
themeState
}
}
/**
* 获取本地存储的主题
*/
fun getThemeState () {
CoroutineScope ( Dispatchers . IO ). launch {
dataStoreHelper . dataStore . data . collect {
val themeState = it [ themePreferencesKey ] ?. toInt () ?: ThemeState . DARK
LogUtils . printLog ( "getThemeState-> themeState:$themeState" , LogUtils . LogLevel . INFO )
_themeState . update {
themeState
}
}
}
}
DataStoreHelper.kt
class DataStoreHelper {
lateinit var dataStore : DataStore < Preferences >
fun init ( path : String ) {
dataStore = createDataStore ( path )
}
private fun createDataStore ( path : String ): DataStore < Preferences > {
return PreferenceDataStoreFactory . createWithPath (
corruptionHandler = null ,
migrations = emptyList (),
produceFile = { path . toPath () }
)
}
}
Main.kt
val themeState = mainStateHolder . themeStateStateFlow . collectAsState ()
LaunchedEffect ( Unit ) {
// 获取存储的主题设置
mainStateHolder . getThemeState ()
}
运行截图记录 开屏动画
设备信息
关于页
历史背景 Flutter Flutter的历史最早可以追溯到2014年10月,其前身是Google内部孵化的Sky项目。其是一款跨平台移动应用开发框架,它允许开发者使用单一代码库同时构建iOS和Android应用。Flutter采用了Dart编程语言,这是一种面向对象的、类型安全的编程语言,与JavaScript非常相似。Flutter的主要优势在于其快速的开发速度和流畅的用户体验。
具体的:
2014.10 - Flutter的前身Sky在GitHub上开源; 2015.10 - 经过一年的开源,Sky正式改名为Flutter; 2017.5 - Google I/O正式向外界公布了Flutter,这个时候Flutter才正式进去大家的视野; 2018.6 - 距5月Google I/O 1个月的时间,Flutter1.0预览版; 2018.12 - Flutter1.0发布,它的发布将大家对Flutter的学习和研究推到了一个新的起点; 2019.2 - Flutter1.2发布主要增加对web的支持。 React Native React Native是Facebook于2015年发布的一款跨平台移动应用开发框架,它允许开发者使用JavaScript和React来构建iOS和Android应用。React Native的主要优势在于其灵活的组件化开发方式和丰富的第三方库支持。
js语言和React JavaScript是一种动态类型的、解释型的、基于原型的、多范式的编程语言。它最初由Netscape公司开发,后来被许多公司采用,包括Google、Microsoft、Facebook等。JavaScript的主要优势在于其跨平台的特性和丰富的第三方库支持。
React是一种用于构建用户界面的JavaScript库,它采用了组件化的开发方式,使得开发者可以将用户界面分解为多个可重用的组件。React的主要优势在于其高效的渲染机制和灵活的组件化开发方式。
Compose Multiplatform是JetBrains于2021年发布的一款跨平台移动应用开发框架,它允许开发者使用Kotlin和Jetpack Compose来构建iOS和Android应用。Compose Multiplatform的主要优势在于其简洁的语法和强大的UI组件库。
Kotlin语言 Kotlin是一种静态类型的、基于JVM的编程语言,它与Java非常相似,但是它的语法更加简洁和灵活。Kotlin的主要优势在于其静态类型的特性和空安全的特性。Kotlin最强大的实际上是他的编译器,可以将Kotlin代码编译为Java字节码,从而可以在Java虚拟机上运行,也可以编译成js代码,从而可以在浏览器上运行等等。
开发流程 Flutter Flutter的开发流程,开发者需要使用Dart语言编写应用程序,然后使用Flutter SDK进行编译和打包。
Flutter的开发流程包括以下几个步骤:
编写Dart代码:开发者使用Dart语言编写应用程序的业务逻辑和界面。 编译和打包:开发者使用Flutter SDK进行编译和打包,生成iOS和Android应用程序。 运行应用程序:开发者可以使用模拟器或真机运行应用程序。 React Native React Native的开发流程相对复杂,开发者需要使用JavaScript和React编写应用程序,然后使用React Native CLI进行编译和打包。
React Native的开发流程包括以下几个步骤:
编写JavaScript代码:开发者使用JavaScript和React编写应用程序的业务逻辑和界面。 编译和打包:开发者使用React Native CLI进行编译和打包,生成iOS和Android应用程序。 运行应用程序 Compose Multiplatform的开发流程相对简单,开发者只需要使用Kotlin和Jetpack Compose编写应用程序,然后使用Compose Multiplatform CLI进行编译和打包。Compose Multiplatform的开发流程包括以下几个步骤:
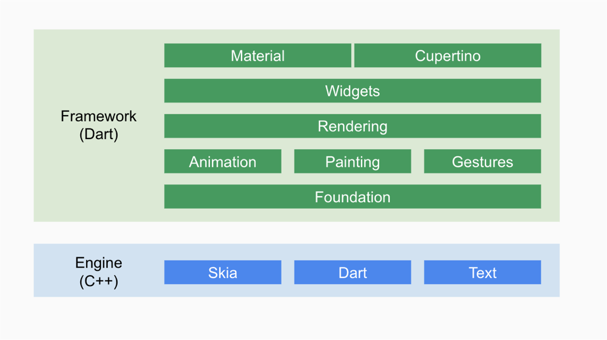
编写Kotlin代码:开发者使用Kotlin和Jetpack Compose编写应用程序的业务逻辑和界面。 编译和打包:开发者可以选择使用Android Studio或者IDEA ItelliJ进行编译和打包,生成iOS和Android应用程序。 运行应用程序 实现原理 Flutter Flutter的框架图如下:
FLutter Engine 这是一个纯 C++实现的 SDK,其中囊括了 Skia引擎、Dart运行时、文字排版引擎等。 简单来说它就是一个 dart 运行时,可以以 JIT(动态编译) 或者 AOT(静态编译) 的方式运行 dart 代码。
Flutter Framework 最上层应用,我们的应用都是围绕这层来构建,所以该层也是我们打交道最多的层。 改层是一个纯 Dart实现的 SDK,类似于 React在 JavaScript中的作用。它实现了一套基础库, 用于处理动画、绘图和手势。并且基于绘图封装了一套 UI组件库,然后根据 Material 和Cupertino两种视觉风格区分开来。
【Foundation】 在最底层,主要定义底层工具类和方法,以提供给其他层使用。 【Animation】是动画相关的类,一些动画相关的都在该类中定义。 【Painting】封装了 Flutter Engine 提供的绘制接口,例如绘制缩放图像、插值生成阴影、绘制盒模型边框等。 【Gesture】提供处理手势识别和交互的功能。 【Rendering】是框架中的渲染库。控件的渲染主要包括三个阶段:布局(Layout)、绘制(Paint)、合成(Composite)。 【Widget】控件层。所有控件的基类都是 Widget,Widget 的数据都是只读的, 不能改变。 【Material】&【Cupertino】这是在 Widget 层之上框架为开发者提供的基于两套设计语言实现的 UI 控件,可以帮助我们的 App 在不同平台上提供接近原生的用户体验。 Dart内存分配机制 DartVM的内存分配策略非常简单,创建对象时只需要在现有堆上移动指针,内存增长始终是线形的,省去了查找可用内存段的过程。
Dart中类似线程的概念叫做Isolate,每个Isolate之间是无法共享内存的,所以这种分配策略可以让Dart实现无锁的快速分配。
Dart单线程异步原理 对于移动端的交互来说,大多数情况下都是在等待状态,等待网络请求,等待用户输入等.那么设想一下,发起一个网络请求只在一个线程中可以进行吗?当然网络请求肯定是异步的(注意这里说的异步而多线程并非一个概念.),事实验证是可以的,Flutter就采用了Dart这种单线程机制,省去了多线程上下文切换带来的性能损耗.(对于高耗时操作,也同样支持多线程操作,通过Isolate开启,不过注意这里的多线程,内存是无法共享的.)
当一个Dart的方法开始执行时,他会一直执行直至达到这个方法的退出点。换句话说Dart的方法是不会被其他Dart代码打断的。 当一个Dart应用开始的标志是它的main isolate执行了main方法。当main方法退出后,main isolate的线程就会去逐一处理消息队列中的消息。
有了消息队列,然后有了循环去读取消息队列中的消息,就可以有单线程去执行异步消息的能力。一般的消息使用dart:async中使用Future来支持异步消息。
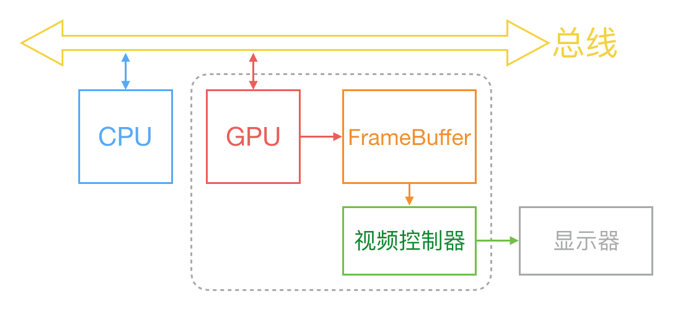
Flutter绘制 一般地来说,计算机系统中,CPU、GPU和显示器以一种特定的方式协作:CPU将计算好的显示内容提交给 GPU,GPU渲染后放入帧缓冲区,然后视频控制器按照 VSync信号从帧缓冲区取帧数据传递给显示器显示。
由于最终的图形计算和绘制都是由相应的硬件来完成 ,而直接操作硬件的指令通常都会有操作系统屏蔽,应用开发者通常不会直接面对硬件,操作系统屏蔽了这些底层硬件操作后会提供一些封装后的API供操作系统之上的应用调用。
但是对于应用开发者来说,直接调用这些操作系统提供的API是比较复杂和低效的,因为操作系统提供的API往往比较基础,直接调用需要了解API的很多细节。 正是因为这个原因,几乎所有用于开发GUI程序的编程语言都会在操作系统之上再封装一层,将操作系统原生API封装在一个编程框架和模型中,然后定义一种简单的开发规则来开发GUI应用程序。
例如:
Android SDK 正是封装了Android操作系统API,提供了一个“UI描述文件XML+Java操作DOM”的UI系统。iOS的UIKit 对View的抽象也是一样的,他们都将操作系统API抽象成一个基础对象(如用于2D图形绘制的Canvas),然后再定义一套规则来描述UI,如UI树结构,UI操作的单线程原则等。
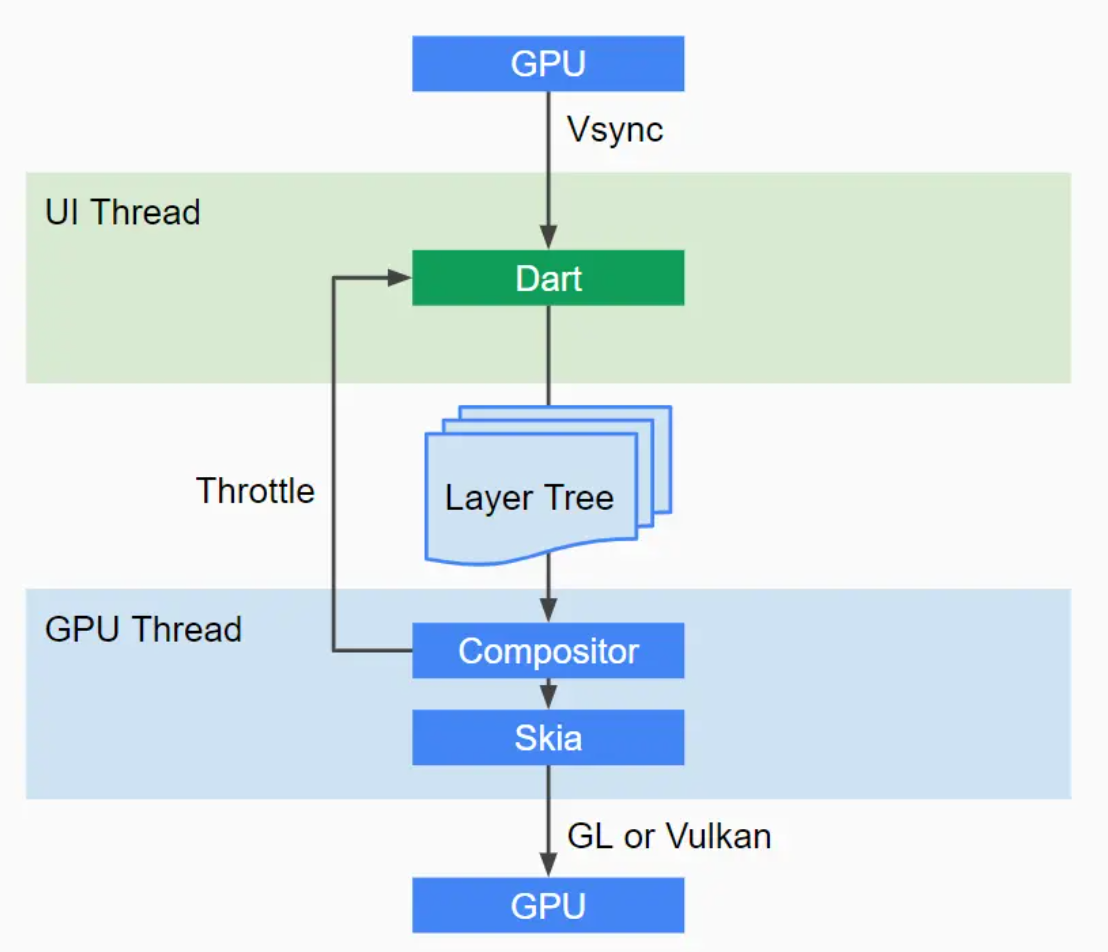
Flutter只关心向 GPU 提供视图数据 ,GPU的 VSync信号同步到 UI 线程,UI线程使用 Dart 来构建抽象的视图结构,这份数据结构在 GPU 线程进行图层合成,视图数据提供给 Skia 引擎渲染为 GPU 数据,这些数据通过 OpenGL或者 Vulkan提供给 GPU。
所以 Flutter 并不关心显示器、视频控制器以及 GPU 具体工作,它只关心 GPU发出的 VSync 信号,尽可能快地在两个 VSync 信号之间计算并合成视图数据,并且把数据提供给GPU。Flutter的原理正是如此,它提供了一套Dart API,然后在底层通过skia这种跨平台的绘制库(内部会调用操作系统API)实现了一套代码跨多端。因此,组件更新(例如,iOS 16)对 Flutter 应用程序没有任何影响,但对 React Native 应用程序有影响。
Google官网的渲染流程示意图:
Flutter的测量布局 Flutter 采用约束进行单次测量布局. 整个布局过程中只需要深度遍历一次,极大的提升效能。
渲染对象树中的每个对象都会在布局过程中接受父 对象的 Constraints 参数,决定自己的大小, 然后父对象 就可以按照自己的逻辑决定各个子对象的位置,完成布局过程. 子对象不存储自己在容器中的位置, 所以在它的位置发生改变时并不需要重新布局或者绘制. 子对象的位 置信息存储在它自己的 parentData 字段中,但是该字段由它的父对象负责维护,自身并不关心该字段的内容。 同时也因为这种简单的布局逻辑, Flutter 可以在某些节 点设置布局边界 (Relayout boundary), 即当边界内的任 何对象发生重新布局时, 不会影响边界外的对象, 反之亦然。
React Native DOM 文档对象模型(Document Object Model,DOM)是针对 HTML 和 XML 文档的一个编程接口。它将网页文档呈现为结构化的对象树,让程序和脚本能够动态地访问、修改文档的内容、结构和样式。
DOM 把整个文档看作是由节点(Node)构成的树形结构。每个节点代表文档中的一个部分,比如元素、属性、文本等,这些节点相互关联,形成了一个层次分明的树状结构。
在浏览器环境中,可以使用 JavaScript 来操作 DOM。以下是一些常见的 DOM 操作示例:
<!DOCTYPE html>
<html>
<head>
<title> DOM 操作示例</title>
</head>
<body>
<h1 id= "heading" > 原始标题</h1>
<button id= "changeBtn" > 修改标题</button>
<script>
// 获取元素节点
const heading = document . getElementById ( ' heading ' );
const changeBtn = document . getElementById ( ' changeBtn ' );
// 为按钮添加点击事件
changeBtn . addEventListener ( ' click ' , function () {
// 修改元素的文本内容
heading . textContent = ' 修改后的标题 ' ;
// 修改元素的样式
heading . style . color = ' red ' ;
});
</script>
</body>
</html>
在这个示例里,借助 document.getElementById 方法获取元素节点,再用 textContent 修改元素文本内容,style 修改元素样式,addEventListener 绑定点击事件。这些都是典型的 DOM 操作。
React库原理 先简单了解下 React 的工作原理。React 是一个用于构建用户界面的 JavaScript 库,核心工作原理可概括为组件化开发、虚拟 DOM 和协调算法三个方面。
React 采用组件化的开发方式,开发者能将用户界面拆分成多个可复用的组件。每个组件都有独立的状态(state)和属性(props),并且可以管理自身的逻辑和渲染。
虚拟 DOM(Virtual DOM) 是 React 的核心概念之一,它是真实 DOM 的轻量级副本,以 JavaScript 对象的形式存在于内存中。当组件的状态或属性发生变化时,React 会先在虚拟 DOM 上进行修改,计算出与之前虚拟 DOM 的差异(Diff)。React 利用 协调算法 对比新旧虚拟 DOM 的差异,找出需要更新的最小 DOM 操作集合,然后只对真实 DOM 进行这些必要的更新。这样可以减少直接操作真实 DOM 的次数 ,提高性能。
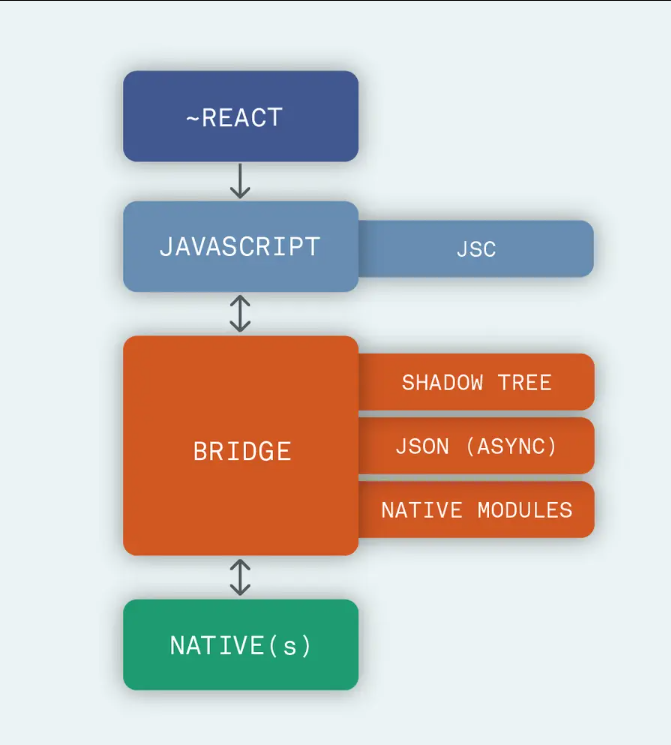
React Native架构 基于Bridge的架构 示意图:
在开发阶段仍然是聚焦于React Components的开发,Babel会将代码编译成浏览器可识别的表达式,并打包成jsbundle文件存储于App设备本地或者存储于服务器(热更新机制) 打开App后,加载并解析jsbundle文件,在JavascriptCore中进行运行,这个地方Android和IOS的差异就是,IOS原生就带有一个JavascriptCore,而Android中需要重新加载,所以这也造成了Android的初始化过程会比IOS慢一些。 运行时需要将前端的组件渲染成Native端的视图,首先如同React中的虚拟DOM一样,在Bridge中也会构造出一个Shadow Tree,然后通过Yoga布局引擎将Flex布局转换为Native的布局,最终交由UIManager在Native端完成组件的渲染。 Bridge架构对于开发者来说很好的屏蔽了各个平台之间的差异,相对于WebView也能够提供不错的近原生操作体验。但是Javascript与Native之间的通信过度的依赖Bridge,当交互频繁或数据量很大的时候可能造成白屏或事件阻塞。而且JSON的序列化操作的效率也比较低。 Bridge Bridge 顾名思义就是 JS 和 Native 通信的一个桥梁, 所有的本地存储、图片资源访问、图形绘制、3D加速、网络访问、震动效果、NFC、原生控件绘制、地图、定位、通知等等很多功能都是由 Bridge 封装成 JS 接口以后注入 JS Engine 供 JS 调用。
每一个支持 RN 的原生功能必须有同一个原生模块和一个 JS 模块, JS 模块方便调用其接口, 原生模块去根据接口调用原生功能实现原生效果。 Bridge 原生代码负责管理原生模块并能够方便的被 React 调用, 每个功能 JS 封装主要是对 React 做适配, JS 和 Native 之间不存在任何指针传递, 所有的参数均由字符串传递。
重要组件MessageQueue
RN 是不用 JS 引擎的 UI 渲染控件的, 但是会用到 JS 引擎的 DOM 操作管理能力来管理所有 UI 节点, 每次在写完 UI 组件代码后会交给 yoga 去做布局排版, 然后调用原生组件绘制 MessageQueue 负责跳出 JS 引擎, 记录原生接口的地址和对应的 JS 函数名, 然后在 JS 调用该函数的时候把调用转发给原生接口
双端差异:JS 和 IOS 通信用的是 JavaScript Core。 JS 和 Android 通信用的是 Hermes。
RN 主要有 3 个线程 JS Thread 执行线程, 负责逻辑层面的处理, Metro 将 React 源码打包成 bundle 文件, 然后传给 JS 引擎执行, 现在 IOS 和 Android 统一的是 JSC UI Thead 主要主责原生渲染 Native UI 和调用原生能力 (Native Module) Shadow Thead 这个线程主要创建 Shadow Tree 来模拟 React 结构树, RN 使用 Flexbox 布局, 但是原生不支持, Yoga 引擎就是将 Flexbox 布局转换为原生布局的。
基础概念
UIManager: 在 Native 里只有它才有权限调用客户端UI JS Thread: 运行打包好的 bundle 文件, 这个文件就是我们写完代码去进行打包的文件, 包含了业务逻辑, 交互和模块化组件 Shadow Node: Native 的一个组件树, 可以监听 App 里的 UI 变化, 类似于虚拟 DOM 和 DOM Yoga: Fackbook 开源的一个布局引擎, 用来把 Flexbox 的布局转换为 Native 的布局 运行流程 用户点击 App 图标 UIManager 线程: 加载所有 Native 库和 Native 组件比如 Images, View, Text 告诉 JS 线程, Native 部分准备好了, JS 侧开始加载 bundle 文件 JS 通过 Bridge 发送一条 Json 数据到 Native , 告诉 Native 怎么创建 UI, 所有的 Bridge 通信都是异步的, 为了避免阻塞 UI Shadow 线程最先拿到消息, 创建 UI 树 Yoga 引擎获取布局并转为 Native 的布局 之后 UI Manager 执行一些操作展示 Native UI Brige的缺点 有两个不同的领域 JS 和 Native, 他们彼此之间不能相互感知, 也并不能共享相同内存 通信基于 Bridge 的异步通信, 所以并不能保证数据百分百及时传达到另一侧 JSON 传输大数据非常慢, 内存不能共享, 所有的传输都是新的复制 无法同步更新 UI, 比方在渲染列表的时候, 滑动大量加载数据, 屏幕可能会发生卡顿或闪烁 RN 代码仓库很大, 库比较重, 所以修复 Bug 和开源社区贡献代码的效率也相应更慢
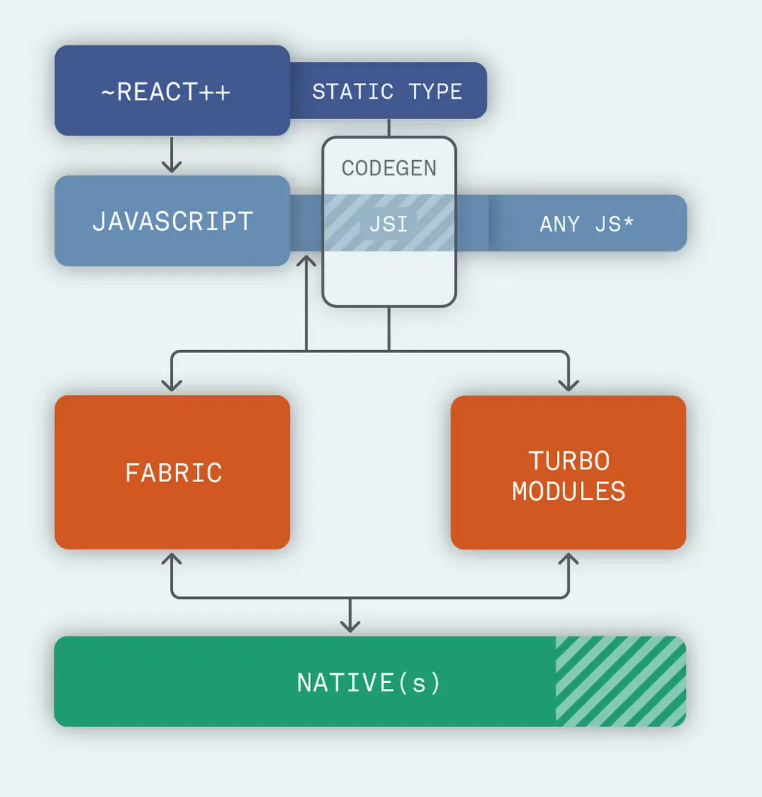
引入了JSI的新架构 上层 JavaScript 代码需要一个运行时环境,在 React Native 中这个环境是 JSC(JavaScriptCore)。不同于之前直接将 JavaScript 代码输入给 JSC,新的架构中引入了一层 JSI(JavaScript Interface),作为 JSC 之上的抽象,用来屏蔽 JavaScript 引擎的差异,允许换用不同的 JavaScript 引擎
RN的新版架构图:
JSI(Javascript Interface):JSI的作用就是让Javascript可以持有C++对象的引用,并调用其方法,同时Native端(Android、IOS)均支持对于C++的支持。从而避免了使用Bridge对JSON的序列化与反序列化,实现了Javascript与Native端直接的通信。 JSI还屏蔽了不同浏览器引擎之间的差异,允许前端使用不同的浏览器引擎,因此Facebook针对Android 需要加载JavascriptCore的问题,研发了一个更适合Android的开源浏览器引擎Hermes。
CodeGen:作为一个工具来自动化的实现Javascript和Native端的兼容性,它可以让开发者创建JS的静态类,以便Native端(Fabric和Turbo Modules)可以识别它们,并且避免每次都校验数据,将会带来更好的性能,并且减少传输数据出错的可能性。
新的 Bridge 层被划分成 Fabric 和 TurboModules 两部分
Fabric:相当于之前的UIManager的作用,不同之处在于旧架构下Native端的渲染需要完成一系列的”跨桥“操作,即React -> Native -> Shadow Tree -> Native UI,新的架构下UIManager可以通过C++直接创建Shadow Tree大大提高了用户界面体验的速度。
TurboModules:旧架构下由于端与端之间的隔阂,运行时即便没有使用的模块也会被加载初始化,TurboModules允许Javascript代码仅在需要的时候才去加载对应的Native模块并保留对其直接的引用缩短了应用程序的启动时间。
新架构的核心改变就是避免了通过Bridge将数据从JavaScript序列化到Native.
新架构下,打开 App 会发生什么
点击 App 图标 Fabric 加载 Native 侧 然后通知 JS 线程 Native 侧准备好了, JS 侧会加载所有的 bundle JS 文件, 里面包含了所有的 JS 和 React 逻辑组件 JS 通过一个 Native 函数的引用, 调用到 Fabric, 同时 Shadow Node 创建一个和以前一样的 UI 树 Yoga 进行布局计算, 把基于 Flexbox 的布局转化为 Native 端的布局 Fabric 执行操作并显示 UI 没有了 Bridge 提升了性能,可以用同步的方式进行操作, 启动时间也快, App 也将更小。
KMP 首先应该了解Kotlin Multiplatform.
Kotlin 在 Android 世界中广受欢迎,但它并非专为 Android 设计的技术。
Kotlin 的初衷是创建一种通用语言,能够与其他编程语言兼容 ,从而用于构建不同平台(而非仅限于 Android)的应用程序。
所以,Kotlin 从设计上来说就是一门多平台语言。
Kotlin Multiplatform是一种跨平台开发技术,它允许开发者使用Kotlin语言编写代码,并在多个平台上运行,包括iOS、Android、Web、桌面等。不同的平台可以共享相同的代码库,从而减少了开发成本和维护成本。
Kotlin 编译器在Android和IOS上生成对应平台特有文件的流程,它包含以下两部分:
前端- 它将 Kotlin 代码转换为 IR(中间表示)。该 IR 能够通过下文所述的后端转换为机器可执行的原生代码。 后端- 它将 IR 转换为机器可执行的原生代码。这得益于 JetBrains 构建的 Kotlin/Native 基础架构。对于 Android,它将 IR 转换为 Java 字节码;对于 iOS,它将 IR 转换为 iOS 原生机器可执行代码。 支持转译成哪些语言? Kotlin 编译器将源代码作为输入,并生成一组特定于平台的二进制文件。在编译多平台项目时,它可以从同一份代码生成多个二进制文件。例如,编译器可以从同一个 Kotlin 文件生成 JVM 文件和原生可执行文件。
目前,其中三种语言的支持最为成熟, JetBrains 正在不断努力扩展支持范围。
Java:这就是 Kotlin 在Android设备上运行的方式,转为class文件,在JVM平台上运行,但我们也可以在桌面或服务器应用程序中使用它。 JavaScript :对js语言的支持,使我们能够在Web应用程序中使用 Kotlin ,包括前端和后端应用程序。 C / Objective-C:这样,我们就可以访问所有基于Linux的平台和 Apple 操作系统,例如iOS设备、iPadOS、macOS、tvOS和watchOS 。而且由于 Objective-C 可以与 Swift 兼容,因此我们也可以在Swift项目中使用 Kotlin 。 并非所有 Kotlin 代码都能编译到所有平台。Kotlin 编译器会阻止您在通用代码中使用特定于平台的函数或类,因为这些代码无法编译到其他平台。
例如,您无法使用java.io.File公共代码中的依赖项。它是 JDK 的一部分,而公共代码也会编译为本机代码,而 JDK 类在本机代码中不可用。
Kotlin的业务逻辑代码向目标平台的代码转换,是在编译器中进行的。所以在应用程序上架之前,用于分发的软件包里面,实际上和目标平台的Native应用程序没有任何区别。
KMP开发模式 如果某些功能无法在通用代码中实现,可以使用KMP独特的 expect / actual 声明机制,在commonMain中声明需要实现的功能,在原生平台的代码中使用系统特有的实现。
如果我们想使用某些系统 API 或原生工具,我们也可以直接到原生文件夹中写native平台代码。这种高度灵活性使得 KMP 的风险比其他解决方案更低。
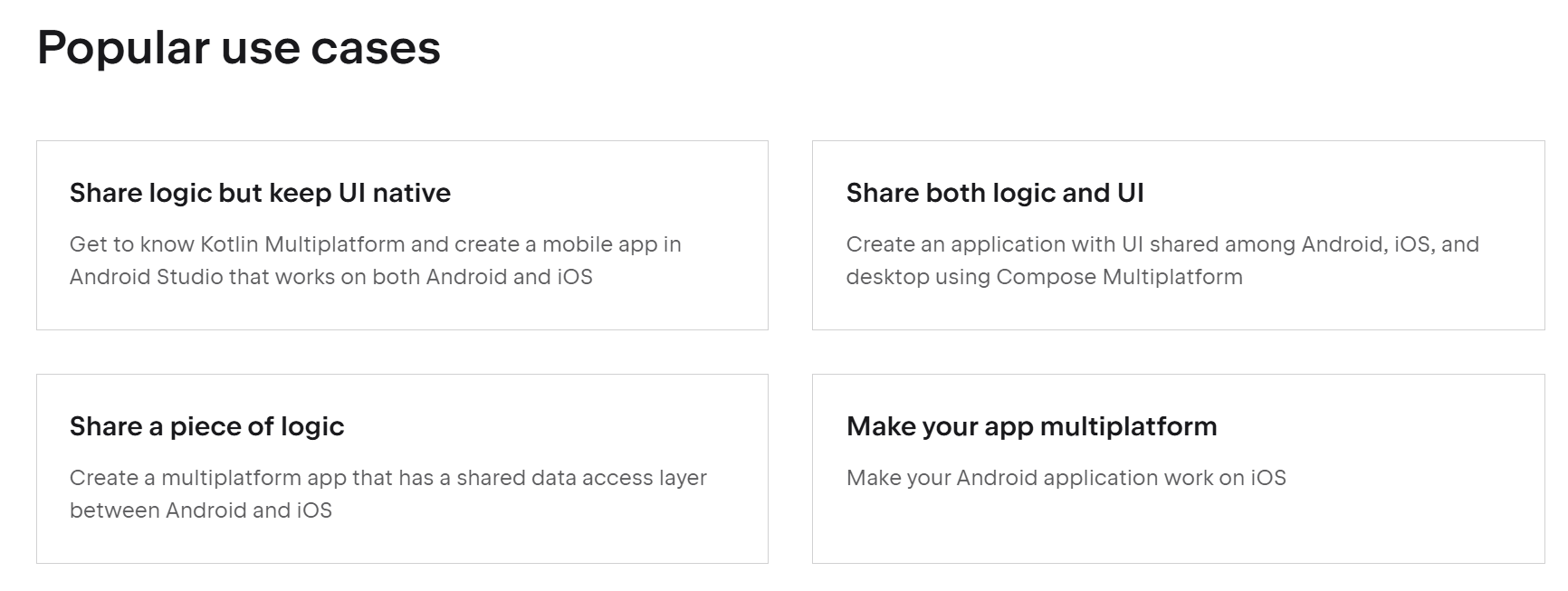
Kotlin官方文档推荐的几种usecases
比较流行KMP应用模式一般是将网络请求,数据库存储等使用KMP改写,在UI逻辑上仍然使用之前的代码来实现,这样可以减少重复代码的编写,提高开发效率。有最大限度保留旧的用户交互逻辑和功能。
Skia引擎 Skia 是一个用C++编写的开源高性能二维图形库。它本质上是一个图形引擎,为在各种硬件和软件平台上绘制文本、几何图形(形状)和图像提供了通用的 API。
Skia 库的主要特点有:
二维图形:专门绘制二维图形。 跨平台:Skia 可在各种操作系统上无缝运行,包括 Windows、macOS、iOS、Android、Linux(Ubuntu、Debian、openSUSE、Fedora),甚至网络浏览器(通过 WebAssembly)。 开源:由谷歌赞助和管理,Skia 采用 BSD 自由软件许可证,允许任何人使用和贡献。 核心图形引擎:它是许多流行产品的基本图形引擎,包括谷歌浏览器和 ChromeOS 安卓系统 Flutter(谷歌用于构建本地应用程序的用户界面工具包) 火狐浏览器 LibreOffice(从 7.0 版开始) 以及其他各种应用程序和框架。 Skia 的核心优势 在于它能在各种硬件上高效地渲染这些图形。它通过支持各种后端渲染技术来实现这一目标:
GPU 加速: 对于现代设备,Skia 可以利用图形处理器(GPU)进行硬件加速渲染。为此,Skia 可将其内部绘图命令转换为对 GPU 应用程序接口的调用,例如:OpenGL ES / OpenGL: 一种广泛应用于 2D 和 3D 图形的 API。AGLE: 兼容性层,可将 OpenGL ES 调用转换为特定供应商的本地 API(如 Windows 上的 Direct3D 或 macOS 上的 Metal),以获得一致的性能。Vulkan: 一种现代高性能图形和计算 API。Metal: 苹果用于 iOS 和 macOS 的底层图形 API。CPU 软件光栅化: 在 GPU 加速不可用或不可取的情况下(如某些服务器或特定的渲染需求),Skia 可以退回到 CPU 上的软件渲染。这包括直接在 CPU 上将矢量图形光栅化为像素。PDF/SVG 输出: Skia 还可以渲染成 PDF 或 SVG 等格式,这些格式基于矢量,可按比例缩放而不会降低质量。CMP的绘制 这是 Skia 发挥关键作用的地方。Compose Multiplatform 不会直接使用每个平台原生的 UI 组件(例如 Android 上的 View 或 iOS 上的 UIKit 控件)来绘制 。相反,它采取了像素渲染 (pixel-painting) 的方式,这与 Flutter 的工作方式类似。
JetBrains 开发了一个名为 Skiko 的 Kotlin Multiplatform 库。Skiko 是 Skia 的 Kotlin 包装器,它提供了 Kotlin API 来与底层的 Skia 图形库进行交互。
在绘制阶段,Compose Multiplatform 会将布局阶段计算出的 UI 元素的形状、颜色、文本、图片等信息,转化为一系列 Skia 绘制命令 。这些命令包括:
绘制矩形、圆形、线条、路径等几何图形。 绘制文本(包括字体、大小、颜色等)。 绘制图片。 应用变换(平移、旋转、缩放)和滤镜效果。 无论是在桌面、iOS 还是 Web 上,Compose Multiplatform 都会将这些 Skia 绘制命令传递给 Skia 库。Skia 再根据目标平台的不同,选择最合适的底层图形 API 进行渲染:
桌面 (Windows, macOS, Linux): , Skia 可以直接利用 OpenGL、Direct3D 或 Vulkan (如果可用) 等 GPU API 进行硬件加速渲染。
iOS: ,Compose Multiplatform 在 iOS 上也使用 Skia 进行画布渲染。这意味着它不会使用 iOS 原生的 UIKit 视图,而是直接通过 Skia 绘制到屏幕上。Skia 会利用 Metal (Apple 的图形 API) 或 OpenGL ES (较旧的 API) 进行渲染。
Android: ,Jetpack Compose (Compose Multiplatform 的 Android 部分) 本身就使用 Skia 作为其底层的渲染引擎。所以,这部分是无缝衔接的。
Web: ,在 Web 平台上,Compose Multiplatform 通常会利用 WebAssembly 和 HTML Canvas 元素。Skia 编译为 WebAssembly 并在 Canvas 上绘制像素。
CMP特有性能优化:
增量渲染: Compose 只有在 UI 状态发生变化时才会重新执行受影响的 Composable 函数,并只更新屏幕上发生变化的部分。GPU 加速: 通过 Skia 及其对底层图形 API 的支持,Compose Multiplatform 能够充分利用 GPU 进行硬件加速渲染,从而实现流畅的动画和高性能的 UI。缓存: Skia 会在内部进行各种优化,例如图形指令的缓存,以减少重复计算。总结来说,Compose Multiplatform 绘制组件的流程是:
开发者通过 Kotlin 的 Composable 函数声明 UI。 Compose 运行时构建 UI 元素的组合树。 Compose 进行测量和布局,确定每个元素的尺寸和位置。 将 UI 元素转换为 Skia 绘制命令。 通过 Skiko 库,这些 Skia 绘制命令被传递给底层的 Skia 图形库。 Skia 根据目标平台的特性,利用 GPU (通过 OpenGL/Direct3D/Vulkan/Metal 等) 或 CPU 进行像素渲染,最终将 UI 呈现在屏幕上。 这种方法使得 Compose Multiplatform 能够提供一致的 UI 外观和行为,无论应用程序运行在哪个平台上,同时也能利用平台原生的图形性能。
性能 在比较 Flutter、React Native 和 Compose Multiplatform (CMP) 的性能时,需要考虑它们各自的架构和设计哲学,因为这直接影响了它们的运行时性能。以下是这三者在性能方面的对比:
1. Flutter 架构核心: Flutter 使用 Dart 语言 ,并拥有自己的渲染引擎,该引擎直接通过 Skia 图形库(在最新版本中,桌面和移动端已逐步转向 Impeller 渲染引擎)绘制 UI。这意味着 Flutter 不依赖于平台原生的 UI 组件。Dart 代码在发布时会被编译为原生机器码 (ahead-of-time, AOT) 。
性能特点:
接近原生性能: 由于直接编译为机器码并使用自己的渲染引擎,Flutter 在 UI 渲染和动画方面通常能达到与原生应用非常接近的性能。它能够以 60 FPS (甚至 120 FPS) 的流畅度运行复杂动画和高负载 UI。无桥接开销: Flutter 消除了 JavaScript 桥接的开销,因为 Dart 代码直接与底层平台通信,避免了在 JavaScript 和原生代码之间进行序列化和反序列化的性能瓶颈。启动时间: 相对于原生应用,Flutter 应用的启动时间可能会略长,因为它需要初始化 Flutter 引擎。然而,Google 正在不断优化这方面。内存占用: 在某些基准测试中,Flutter 应用的内存占用可能略高于原生应用,因为它捆绑了自己的引擎和渲染器。包大小: Flutter 应用的包大小通常比原生应用大,因为它包含了 Flutter 引擎和 Dart 运行时。总结: Flutter 在 UI 渲染和动画流畅度方面表现出色,适合需要复杂、高度定制 UI 和高性能动画的应用。
2. React Native 架构核心: React Native 使用 JavaScript/TypeScript 。它不直接绘制 UI,而是通过一个 JavaScript 桥接 (Bridge) 与平台原生的 UI 组件进行通信。当 JavaScript 端更新状态时,通过桥接将指令发送到原生 UI 线程,由原生组件进行渲染。
性能特点:
有桥接开销: 传统的 React Native 架构中,JavaScript 线程和原生 UI 线程之间的通信需要通过桥接,这会引入一定的序列化和反序列化开销,尤其是在频繁更新 UI 或进行大量数据传输时,可能导致性能瓶颈和 UI 卡顿。原生组件渲染: 优势在于使用原生 UI 组件,能够提供原生的外观和感觉,但在需要高度定制的 UI 或跨平台像素级一致性时,可能需要额外的努力。新架构 (Fabric & TurboModules): React Native 正在积极推广其“新架构”,其中包含 Fabric 渲染系统 和 TurboModules 。Fabric: 旨在解决旧桥接的性能问题,通过 C++ 层实现 JavaScript 和原生之间的同步通信,减少了桥接开销,提高了 UI 响应速度和动画流畅度。它也支持并发渲染。TurboModules: 允许原生模块按需加载,从而改善了应用启动时间。JSI (JavaScript Interface): 替换了旧的桥接,允许 JavaScript 直接调用 C++ 代码,从而实现更高效的通信。启动时间: 相对于原生应用,React Native 应用的启动时间可能较长,尤其是在加载 JavaScript 包时。新架构旨在改善这一点。内存占用: 内存占用通常介于原生和 Flutter 之间,因为需要 JavaScript 运行时和原生组件。总结: React Native 在性能方面受 JavaScript 桥接的限制,但在新架构(Fabric、TurboModules、JSI)的推动下,其性能正在显著提升,尤其是在复杂 UI 和动画方面。对于需要快速开发、且对绝对原生性能要求不那么极致的应用,React Native 仍是一个强有力的选择。
架构核心: Compose Multiplatform 基于 Kotlin Multiplatform (KMP) 技术,使用 Kotlin 语言。它在 Android 上复用 Google 的 Jetpack Compose,而在其他平台(iOS、桌面、Web)上,通过 Skiko (Skia 的 Kotlin 包装器) 直接调用 Skia 图形库进行 UI 绘制,与 Flutter 的像素渲染方式类似。Kotlin 代码会编译为原生二进制文件。
性能特点:
接近原生性能: Android: 直接使用 Jetpack Compose,其性能与原生 Android UI 相当,并受益于 Android 系统内置的 Skia 库。iOS/桌面: 通过 Skiko/Skia 直接绘制 UI,避免了桥接开销,因此在 UI 渲染和动画方面能达到接近原生应用的性能。AOT 编译: Kotlin 代码可以编译为原生机器码(AOT 编译),进一步提升了运行时性能。启动时间: 在 Android 上,与 Jetpack Compose 应用类似,启动时间通常良好。在 iOS 上,由于需要捆绑 Skia 库(不像 Android 可以依赖系统内置),可能会增加一点启动时间,但总体上仍然表现优秀。内存占用: 通常表现良好,与原生应用或 Jetpack Compose 应用类似。包大小: 在 Android 上,CMP 应用的包大小与 Jetpack Compose 应用类似。在 iOS 和桌面端,由于需要捆绑 Skia 库,包大小会比原生应用略大,但通常比 Flutter 应用小。总结: Compose Multiplatform 在性能上非常具有竞争力。它在 Android 上直接受益于 Jetpack Compose 的原生整合,而在其他平台则通过 Skia 提供了高性能的像素渲染。对于追求原生性能和统一代码库的 Kotlin 开发者来说,CMP 是一个非常吸引人的选择。
适用场景 对极致性能要求高、或拥有复杂定制 UI 的应用: Flutter 和 Compose Multiplatform 通常是更好的选择。它们通过直接绘制像素来绕过原生组件的限制,提供高度优化的渲染管道。
对开发速度和 Web 开发者友好度有高要求、或希望逐步迁移现有原生应用: React Native (尤其是新架构下) 仍是强有力的竞争者。其庞大的社区和成熟的生态系统也是巨大优势。
对于 Kotlin 开发者、希望最大化代码共享并获得接近原生性能,同时能够方便地与现有原生代码互操作的项目: Compose Multiplatform 提供了非常吸引人的平衡点。
最终的选择取决于你的 项目需求、团队技术栈、以及对性能、开发速度和原生体验 的优先级。随着这三个框架的不断发展和优化,它们之间的 性能差距也在逐渐缩小 。
外部讨论 在热门论坛Reddit上,某篇帖子如下: Compose Multiplatform 与 Flutter
您好,我正在决定将我的事业重心放在这两者之间: Dart(Flutter)VS Kotlin(KMP 和 CMP) 因为我也想做独立移动应用程序,但同时也想担任移动工程师一职。 我的工作地点在美国,所以这里的 Flutter 职位比较少。 我知道 CMP 在 iOS 上还不稳定,但它是未来的趋势吗? 我喜欢在 Ktor 的后端也可以使用 Kotlin。 但 Flutter 有生态系统和热重载功能,所以我很纠结到底要继续使用哪一种……
网友1:
您正在询问 kotlin Reddit,所以这里会有一些偏见。 但抛开这些不谈,学习 KMP 比学习 Flutter 更接近学习原生 Android。这就是关键优势。安卓开发者可以轻松地将他们的知识迁移到 Kotlin Multiplatform,Compose 与他们在安卓中使用的完全相同,因此可以相互映射 与 KMP 相比,Flutter 有 2-3 年的先发优势,而且拥有更成熟的生态系统。但是,您将在 Android 和 iOS SDK 的基础上学习 Flutter SDK,而原生开发人员的知识迁移学习曲线更大。
网友2:
使用 Compose 的 Kotlin 多平台令人惊叹。不过我不确定是否有适合它的工作,如果你正在考虑的话。这是更新颖的技术。但通过它,会有 Android 的机会。
网友3:
我使用过 jetpack compose 和 flutter,flutter 非常缺乏优秀的库,而且创建一个小部件需要大量的模板,令人厌恶。 你最好还是学习这两个平台的真正原生程序,我发现 Flutter 从未真正解决开发 iOS 应用程序的痛苦。 从安全角度来看,Flutter 也有点弱,因为你无法真正控制许多东西与操作系统的交互方式(如安全存储)或字符串的永久性,而且大多数代码扫描程序都不包括 dart 或 pub 包。 你也得不到一个合适的集成开发环境,flutter 支持是在 android studio 上附加的。 试着在 flutter 中做一个懒列表,然后再在 jetpack compose 中做,这就是它们生态系统的完美体现。
Me: 就我个人的情况,专业为Android开发,对于Kotlin和Jetpack Compose的写法,架构设计,已经是比较熟悉了,如果有做跨平台的需求,在业务不是太复杂的情况下,使用CMP几乎是最佳选择。所以这个跨平台的能力对于熟悉这两个技术的Android开发可以说是买一送一,拿起电脑,稍微看看文档就可以写功能。
国内已经有Bilibili,快手在使用KMP来重构自己的产品,腾讯甚至基于CMP自己改了一套Kuikly来适配鸿蒙平台,所以站在发展的角度看,我认为CMP日后的成熟度和公司接受度,说不定可以超过Flutter。
此前发过一篇文章介绍了我开发的Desktop端端跨平台Android设备调试软件——DebugManager。
包含了基础设备信息,应用管理,文件管理,性能监测,主题切换等。
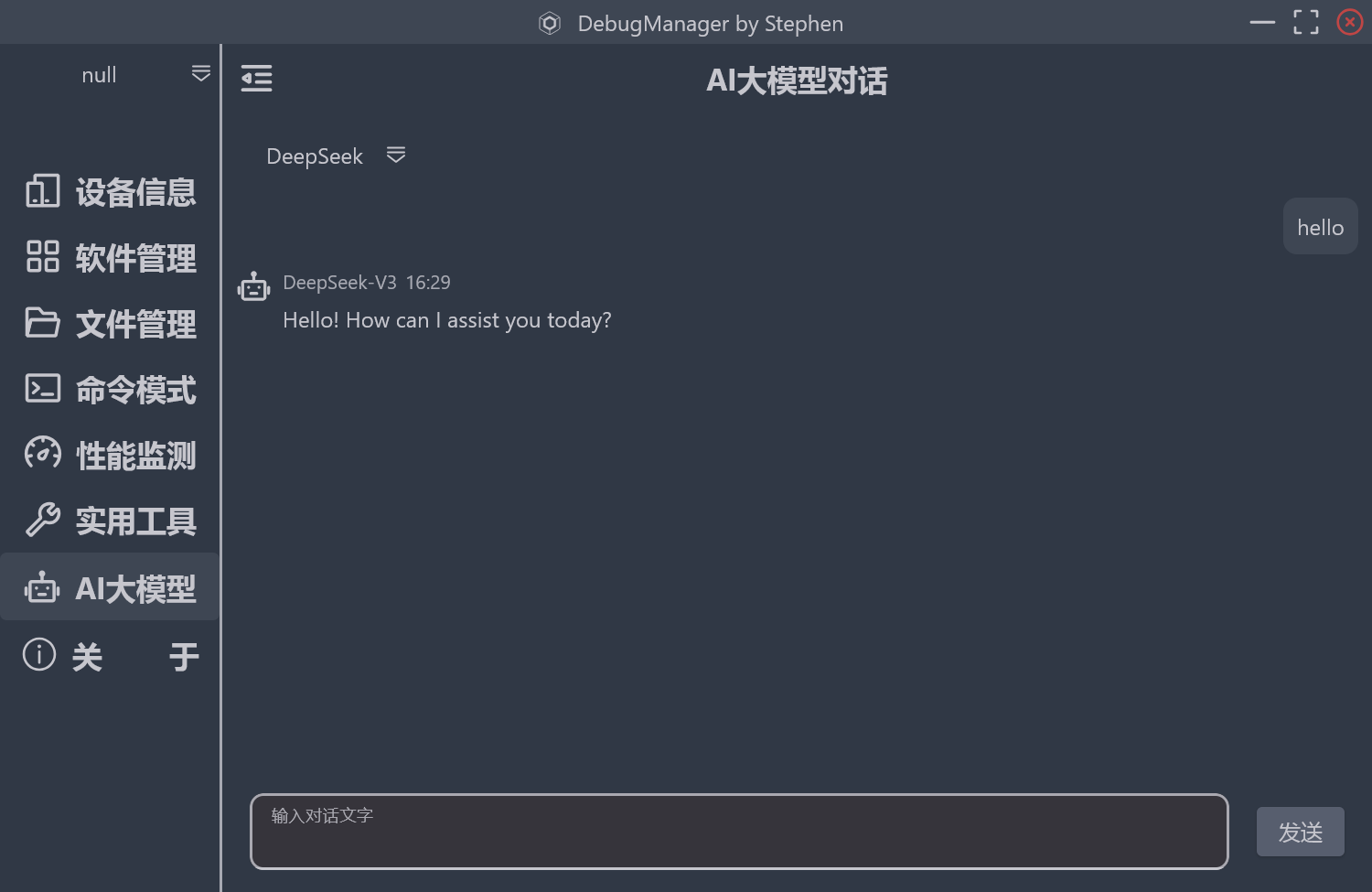
本次记录问题点 记录为开发AI大模型对话功能页面中,对TextField输入框回车键监听问题的解决。
页面如下:
普通用户在电脑程序中对于输入框的期望,就是按Enter键可以直接确认,按Alt+Enter可以输入换行符。
第一版——基础输入功能 对 Compose 官方的 TextField 可组合项进行简单封装:
@Composable
fun WrappedEditText (
value : String ,
onValueChange : ( String ) -> Unit ,
tipText : String ,
modifier : Modifier = Modifier
) {
TextField (
value = value ,
textStyle = infoText ,
colors = TextFieldDefaults . textFieldColors (
textColor = MaterialTheme . colors . onPrimary ,
cursorColor = MaterialTheme . colors . onPrimary ,
focusedIndicatorColor = MaterialTheme . colors . onPrimary ,
unfocusedIndicatorColor = MaterialTheme . colors . onSecondary
),
label = { Text ( tipText , color = MaterialTheme . colors . onSecondary ) },
onValueChange = { onValueChange ( it ) },
modifier = modifier
. widthIn ( max = 200 . dp , min = 100 . dp )
. clip ( RoundedCornerShape ( 10 . dp ))
. background ( MaterialTheme . colors . secondary )
. border ( 2 . dp , MaterialTheme . colors . onSecondary , RoundedCornerShape ( 10 . dp )),
)
}
外部调用的时候,通过维护一个mutableStringState,和这里的onValueChange配合,来进行TextField显示内容和实际字符串变量的更新。
@Composable
fun AiModelPage () {
BasePage ( "AI大模型对话" ) {
val mainStateHolder by remember { mutableStateOf ( GlobalContext . get (). get < MainStateHolder >()) }
val toastState = rememberToastState ()
val userInputSting = remember { mutableStateOf ( "" ) }
WrappedEditText (
value = userInputSting . value ,
tipText = "输入对话文字" ,
onValueChange = { userInputSting . value = it },
modifier = Modifier . padding ( start = 10 . dp , end = 10 . dp ). weight ( 1f ),
)
CommonButton (
"发送" , onClick = {
if ( userInputSting . value . isEmpty ()) {
toastState . show ( "请先输入对话内容" )
} else {
mainStateHolder . chatWithAI ( userInputSting . value )
userInputSting . value = ""
}
},
modifier = Modifier . padding ( 10 . dp )
)
}
}
只有点击来发送按钮后,才会将对话内容发给大模型。
第二版——加入Enter事件回调 为了实现按下 Enter 按键就可以发送消息,我在Modifier修饰符参数里加入了对Enter的 KeyEvent 监听:
@Composable
fun WrappedEditText (
value : String ,
onValueChange : ( String ) -> Unit ,
tipText : String ,
modifier : Modifier = Modifier ,
onEnterPressed : () -> Unit = {}
) {
val focusRequester = remember { FocusRequester () }
TextField (
value = value ,
textStyle = infoText ,
colors = TextFieldDefaults . colors (
focusedTextColor = MaterialTheme . colorScheme . onPrimary ,
cursorColor = MaterialTheme . colorScheme . onPrimary ,
focusedIndicatorColor = MaterialTheme . colorScheme . onPrimary ,
unfocusedIndicatorColor = MaterialTheme . colorScheme . onPrimary
),
label = { Text ( tipText , color = MaterialTheme . colorScheme . onSecondary ) },
onValueChange = { onValueChange ( it ) },
modifier = modifier
. widthIn ( max = 200 . dp , min = 100 . dp )
. clip ( RoundedCornerShape ( 10 . dp ))
. background ( MaterialTheme . colorScheme . secondary )
. border ( 2 . dp , MaterialTheme . colorScheme . onSecondary , RoundedCornerShape ( 10 . dp ))
. focusRequester ( focusRequester )
. onKeyEvent {
if ( it . key == Key . Enter ) {
onEnterPressed ()
return onKeyEvent true
}
false
},
)
}
在监测到Enter键按下时,执行外部的onEnterPressed这个Lambda块,外部调用配置的时候,在这里执行和点击右侧的发送按钮一样的逻辑。
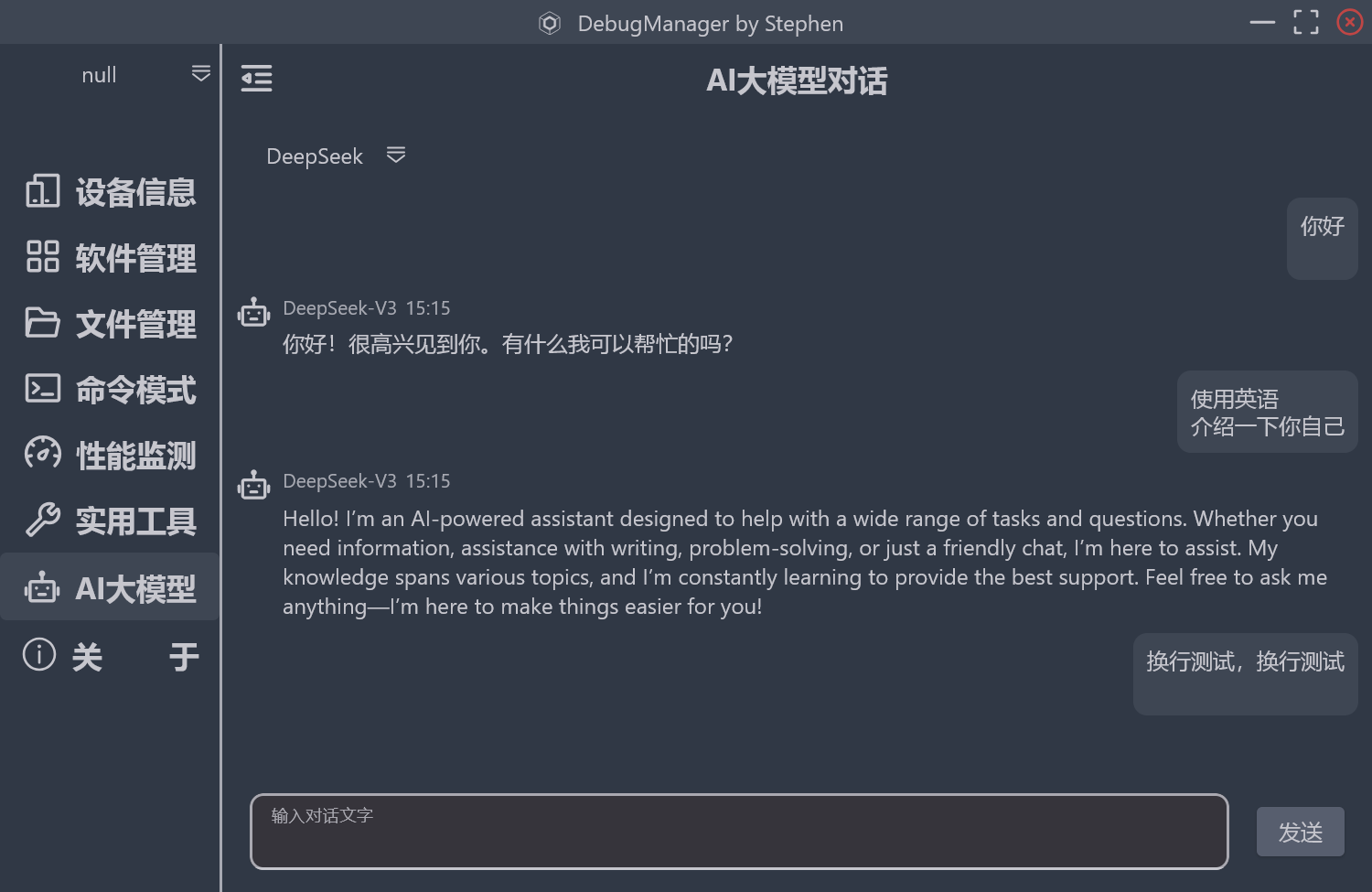
问题就是,最后的这个换行符,连同输入的内容一起被添加到了输入框的UI,还有对话气泡中去了。
第三版——AI提供的传参数方案 查看官方文档,提供的几个api都会和上面那个按键监听策略一样的问题,换行符和内容混到了一起。
询问Gemini给出了一个方法,通过自定义 keyboardOptions 和 keyboardActions 两个参数,并在keyboardActions的onDone回调里调用onEnterPressed代码块。
@Composable
fun WrappedEditText (
value : String ,
onValueChange : ( String ) -> Unit ,
tipText : String ,
modifier : Modifier = Modifier ,
onEnterPressed : () -> Unit = {}
) {
val focusRequester = remember { FocusRequester () }
TextField (
value = value ,
textStyle = infoText ,
colors = TextFieldDefaults . colors (
focusedTextColor = MaterialTheme . colorScheme . onPrimary ,
cursorColor = MaterialTheme . colorScheme . onPrimary ,
focusedIndicatorColor = MaterialTheme . colorScheme . onPrimary ,
unfocusedIndicatorColor = MaterialTheme . colorScheme . onPrimary
),
label = { Text ( tipText , color = MaterialTheme . colorScheme . onSecondary ) },
onValueChange = { onValueChange ( it ) },
keyboardOptions = KeyboardOptions ( imeAction = ImeAction . Done ),
keyboardActions = KeyboardActions (
onDone = {
onEnterPressed ()
}
),
modifier = modifier
. widthIn ( max = 200 . dp , min = 100 . dp )
. clip ( RoundedCornerShape ( 10 . dp ))
. background ( MaterialTheme . colorScheme . secondary )
. border ( 2 . dp , MaterialTheme . colorScheme . onSecondary , RoundedCornerShape ( 10 . dp ))
. focusRequester ( focusRequester ),
)
}
实测发现并没有成功监听到Enter键的事件。
为了搞清楚按键的顺序,恢复到第二版的方案后,通过在 onValueChange 和 onKeyEvent 里打印log看到:
在普通按键按下时,KeyEvent可以拦截,先手回调。 然而按下Enter键时,KeyEvent却在onValueChange的后面回调,即输入框的内容已经吃掉了换行符,这样就无法提前对onValueChange回调之前进行操作。 第四版——使用内部状态来多重判断 先上代码:
@Composable
fun WrappedEditText (
value : String ,
onValueChange : ( String ) -> Unit ,
tipText : String ,
modifier : Modifier = Modifier ,
onEnterPressed : () -> Unit = {}
) {
val focusRequester = remember { FocusRequester () }
var ctrlPressed by remember { mutableStateOf ( false ) }
var altPressed by remember { mutableStateOf ( false ) }
TextField (
value = value ,
textStyle = infoText ,
colors = TextFieldDefaults . colors (
focusedTextColor = MaterialTheme . colorScheme . onPrimary ,
cursorColor = MaterialTheme . colorScheme . onPrimary ,
focusedIndicatorColor = MaterialTheme . colorScheme . onPrimary ,
unfocusedIndicatorColor = MaterialTheme . colorScheme . onPrimary
),
label = { Text ( tipText , color = MaterialTheme . colorScheme . onSecondary ) },
onValueChange = {
// 如果此时使用了ctrl或者alt键,那么就不做处理
// 否则就处理,丢弃掉最后一个换行符
onValueChange ( if (! ctrlPressed && ! altPressed ) it . processText () else it )
},
modifier = modifier
. widthIn ( max = 200 . dp , min = 100 . dp )
. clip ( RoundedCornerShape ( 10 . dp ))
. background ( MaterialTheme . colorScheme . secondary )
. border ( 2 . dp , MaterialTheme . colorScheme . onSecondary , RoundedCornerShape ( 10 . dp ))
. focusRequester ( focusRequester )
. onKeyEvent {
// 只有单独按下enter键才触发,其余组合键只换行
if ( it . isCtrlPressed ) {
ctrlPressed = true
return onKeyEvent false
} else {
ctrlPressed = false
}
if ( it . isAltPressed ) {
altPressed = true
return onKeyEvent false
} else {
altPressed = false
}
if ( it . key == Key . Enter ) {
onEnterPressed ()
return onKeyEvent true
}
false
},
)
}
/**
* 用来兜底TextField的bug,暂时没有找到更好的解决方案
* 手动丢弃掉最后一个换行符
*/
private fun String . processText (): String {
return if ( this . endsWith ( "\n" )) {
// 如果是单一个换行符,直接置空
// 如果非单换行符,就丢弃最后一个字符
if ( this . length == 1 ) ""
else this . dropLast ( 1 )
} else this
}
KeyEvent里面提供了几个重要按键按下的状态回调,我使用内部State来记录Ctrl和Alt这两个按键的按键状态,isPressed时置为true,没有按下时置为false,这样就可以在onValueChange时对回调过来的字符串进行加工处理。即,在Ctrl按键和Alt按键按下时,如实地回调键盘事件给输入框,这两个按键都没有按时,对字符串的最后一个字符进行检查。
处理方法如 String.processText(),如果以换行符结尾,再判断这个字符串是不是就只有一个换行符,这种情况就直接置为空字符串,如果有多个字符,就把最后一个换行符给去掉,再传递给外部的调用方,保证了输入框的UI和实际的字符串里都不会显示异常。
最终实现组合按键正常换行,单独换行键直接发送对话。后续计划持续跟进,看看这里是不是跨平台库中的一个BUG,还有就是有没有官方封装完善的方案来直接使用。
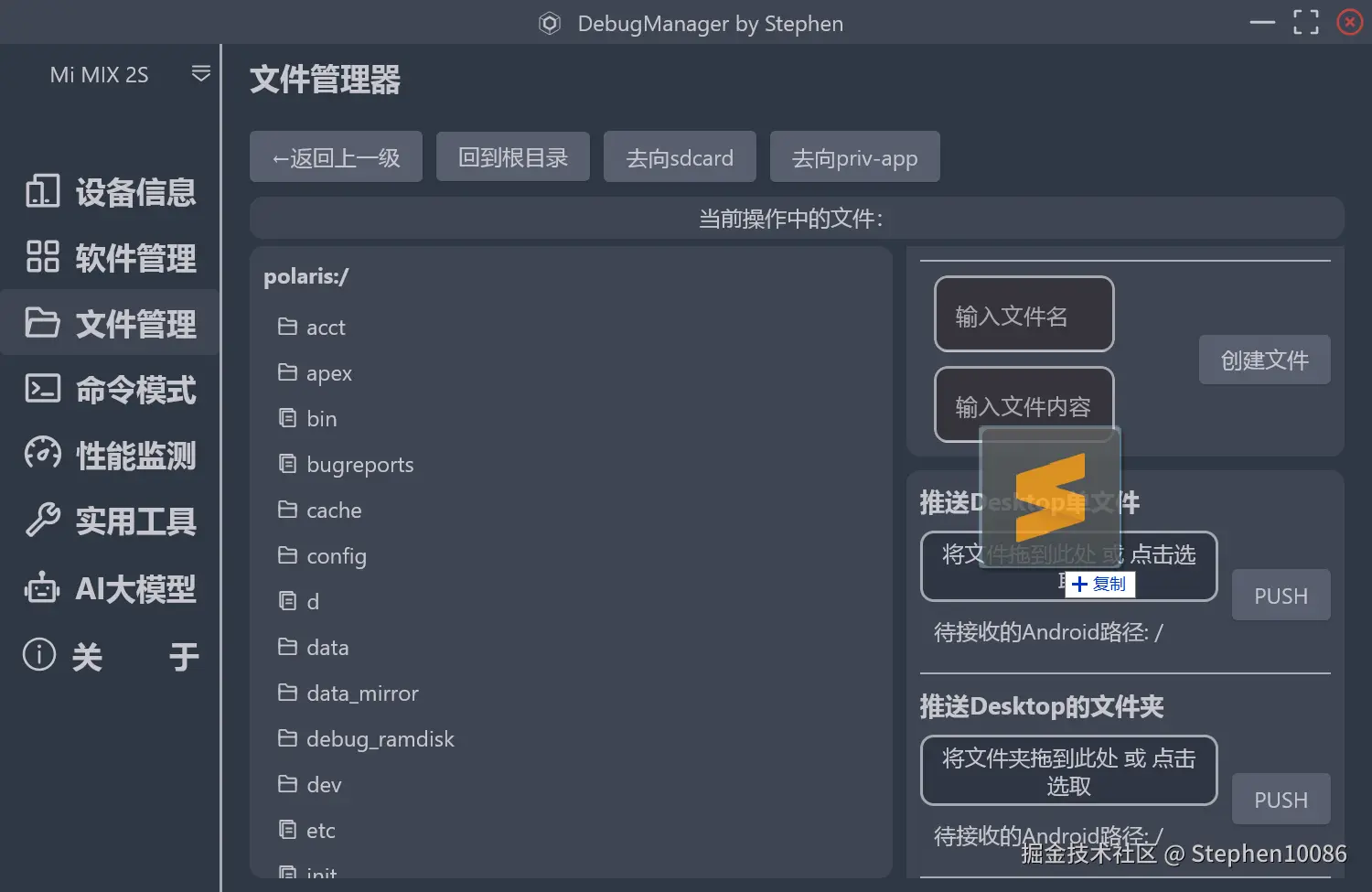
刚刚写完一篇TextField输入框按键监听的文章,趁热打铁,记录一下我简单封装桌面端的的文件选择器组件。依然是来自于跨平台Android设备调试软件DebugManager里的功能。这里相关的是apk文件的选取安装,电脑文件的推送,日志文件的选取自动分析等。
文件选择 文件选择为java.awt包下的FileDialog组件,初始化显示完,直接通过实例化的 FileDialog 对象来获取最终的文件选择路径。有directory和file两部分。
val fileChooser = FileDialog (
Frame (),
"Select a file" ,
FileDialog . LOAD
). apply {
file = fileType
}
fileChooser . isVisible = true
// 判断是否未选文件
if ( fileChooser . file != null ) {
onPathSelect ( fileChooser . directory + fileChooser . file )
}
文件夹选择器 文件夹这里用的是swing包下的 JFileChooser ,用法几乎和上面的 FileDialog 一样。
// 选择文件夹
val fileChooser = JFileChooser ()
fileChooser . fileSelectionMode = JFileChooser . DIRECTORIES_ONLY
// 显示对话框并等待用户选择
val result = fileChooser . showOpenDialog ( null );
// 如果用户选择了文件夹
if ( result == JFileChooser . APPROVE_OPTION ) {
// 获取用户选择的文件夹
onPathSelect ( fileChooser . selectedFile . absolutePath )
}
这两种选取电脑文件的方法,之前都是在一个Text组件的 clickable 回调里面来配置的,把结果赋值给一个String泛型的State,再执行文件的推送或者apk的安装。
拖动选择文件 之前看另一位博主也提供了个拖拽的方法 onExternalDrag ,可惜已经严重过期了,弃用无法使用。
@Deprecated (
level = DeprecationLevel . ERROR ,
message = "Use the new drag-and-drop API: Modifier.dragAndDropTarget"
)
@Suppress ( "DEPRECATION_ERROR" )
@ExperimentalComposeUiApi
@Composable
fun Modifier . onExternalDrag (
enabled : Boolean = true ,
onDragStart : ( ExternalDragValue ) -> Unit = {},
onDrag : ( ExternalDragValue ) -> Unit = {},
onDragExit : () -> Unit = {},
onDrop : ( ExternalDragValue ) -> Unit = {},
)
根据这里的提示“Use the new drag-and-drop API: Modifier.dragAndDropTarget”
@ExperimentalFoundationApi
fun Modifier . dragAndDropTarget (
shouldStartDragAndDrop : ( startEvent : DragAndDropEvent ) -> Boolean ,
target : DragAndDropTarget ,
): Modifier {
return this then DropTargetElement (
target = target ,
shouldStartDragAndDrop = shouldStartDragAndDrop ,
)
}
根据官方文档和方法签名,了解到这个方法的具体用法。
第一个参数为一个 DragAndDropEvent 类型的参数,并返回一个布尔值。 作用:这个函数允许可组合项(Composable)根据启动拖放会话的 DragAndDropEvent 来决定是否要参与该拖放会话。当一个拖放操作开始时,系统会调用这个函数,传入表示拖放开始事件的 DragAndDropEvent 对象。如果该函数返回 true,则表示当前可组合项愿意参与这个拖放会话;如果返回 false,则表示不参与。
作用:这个对象是拖放会话的目标,它将接收与拖放会话相关的事件。当拖放操作发生在当前可组合项上时,系统会将相关的拖放事件发送给这个 DragAndDropTarget 对象,以便进行相应的处理。
可以理解为一个enable开关,一个callback回调。我们的关注度应该放到calllback回调事件上,主要目的就是需要拖动过来的文件路径。
val callback = remember {
object : DragAndDropTarget {
override fun onDrop ( event : DragAndDropEvent ): Boolean {
val dragData = event . dragData ()
if ( dragData is DragData . FilesList ) {
dragData . readFiles (). firstOrNull () ?. let { filePath ->
val file = File ( URI . create ( filePath ))
LogUtils . printLog ( "选取文件:${file.absolutePath}" )
if ( fileType . isNotEmpty () && fileType . split ( '.' ). last () != file . extension ) {
onErrorOccur ( "请选择正确的文件类型" )
return false
}
onPathSelect ( file . absolutePath )
}
}
return true
}
}
}
在 onDrop 即鼠标拖动松手后,解析文件路径出来,判断是否是我们需要的。
三合一封装 为了统一设计,并且使用一个组件支持以上三种文件功能,对一个Text组件进行包装。
配置的几个参数如下代码所示,一个提示语字段,一个string类型的文件路径和其更改的lambda,一个变量用来判断是需要接受文件还是文件夹,一个为需要的文件类型。最后的onError代码块为拖动来的文件不符合要求时,供调用方弹出Toast所用。
/**
* @param tintText 提示文本
* @param path 路径
* @param onPathSelect 路径选择回调
* @param isChooseFile 是否选择文件,默认为 false
* @param fileType 文件类型
* @param onErrorOccur 错误消息回调
*/
@OptIn ( ExperimentalFoundationApi :: class , ExperimentalComposeUiApi :: class )
@Composable
fun FileChooseWidget (
tintText : String ,
path : String ,
modifier : Modifier = Modifier ,
isChooseFile : Boolean = false ,
fileType : String = "" ,
onErrorOccur : ( String ) -> Unit = {},
onPathSelect : ( String ) -> Unit ,
) {
val callback = remember {
object : DragAndDropTarget {
override fun onDrop ( event : DragAndDropEvent ): Boolean {
val dragData = event . dragData ()
if ( dragData is DragData . FilesList ) {
dragData . readFiles (). firstOrNull () ?. let { filePath ->
val file = File ( URI . create ( filePath ))
LogUtils . printLog ( "选取文件:${file.absolutePath}" )
if ( fileType . isNotEmpty () && fileType . split ( '.' ). last () != file . extension ) {
onErrorOccur ( "请选择正确的文件类型" )
return false
}
onPathSelect ( file . absolutePath )
}
}
return true
}
}
}
CenterText (
text = path . ifEmpty { tintText },
style = defaultText ,
modifier = modifier . border ( 2 . dp , MaterialTheme . colorScheme . onSecondary , RoundedCornerShape ( 10 . dp ))
. clip ( RoundedCornerShape ( 10 . dp ))
. background ( MaterialTheme . colorScheme . secondary ). clickable {
// 选择文件
if ( isChooseFile ) {
val fileChooser = FileDialog (
Frame (),
"Select a file" ,
FileDialog . LOAD
). apply {
file = fileType
}
fileChooser . isVisible = true
// 判断是否未选文件
if ( fileChooser . file != null ) {
onPathSelect ( fileChooser . directory + fileChooser . file )
}
} else {
// 选择文件夹
val fileChooser = JFileChooser ()
fileChooser . fileSelectionMode = JFileChooser . DIRECTORIES_ONLY
// 显示对话框并等待用户选择
val result = fileChooser . showOpenDialog ( null );
// 如果用户选择了文件夹
if ( result == JFileChooser . APPROVE_OPTION ) {
// 获取用户选择的文件夹
onPathSelect ( fileChooser . selectedFile . absolutePath )
}
}
}. dragAndDropTarget (
shouldStartDragAndDrop = { event -> true },
target = callback
). padding ( 10 . dp )
)
}
实现的效果如下所示 拖动文件
点击触发选择窗
Android trace 文件 (也常被称为 Systrace 文件 或 Perfetto trace 文件 )是 Android 系统生成的一种包含详细性能事件数据的文件。它记录了设备在特定时间段内 CPU、线程、进程、函数调用、Binder 通信、I/O 操作、SurfaceFlinger 帧渲染等 各个层面的活动。
可以把它想象成一个高性能的“黑匣子记录仪”,它在系统运行时不断记录各种事件,当出现性能问题时,我们可以回放这些记录,了解系统当时到底发生了什么。
一般用来分析性能相关的问题:
识别性能瓶颈 :找出导致应用卡顿、响应慢、启动慢、耗电、UI 渲染不流畅等问题的根本原因。分析系统行为 :深入了解应用与系统服务、框架层、硬件之间的交互。优化代码逻辑 :定位到具体耗时函数或线程阻塞点,从而优化算法或并行处理。调试复杂问题 :对于一些难以复现的性能问题,trace 文件能提供宝贵的线索。采集方式 随着 Android 版本的迭代,trace 文件的生成和分析工具也在不断发展。
Systrace (旧版) Systrace 是 Android 早期最常用的性能分析工具,它通过 Ftrace(Linux 内核中的一个跟踪工具)收集系统事件,并结合用户空间事件(由应用程序或系统服务通过 Trace 类或 ATrace 宏记录)生成 HTML 报告。可以配置一系列参数,如:
gfx:图形 (Graphics) 相关事件;
input:输入 (Input) 事件,例如触摸、按键等;
view:视图系统 (View System) 事件;
wm:窗口管理器 (Window Manager) 事件;
am:Activity 管理器 (Activity Manager) 事件;
audio:音频 (Audio) 事件,与音频播放和录制相关;
...
可以直接从命令行使用,无需修改代码(针对系统事件)。但是其生成的报告可视化能力有限,且没有包名,只有进程id,对大型 trace 文件分析效率不高。现在逐渐被 Perfetto 取代。
Perfetto (新版 & 推荐) Perfetto 是 Google 开发的新一代系统级性能分析工具,它旨在替代和增强 Systrace。它是atrace的超集,除了应用层还可以抓取内核等底层的一些信息,提供了更丰富的数据源(包括 Ftrace、Perf、ftrace-events、Android events 等)。
还有更灵活的查询能力,以及更强大的 Web UI (UI 网址:ui.perfetto.dev )。
更全面 :收集的数据类型更多,覆盖面更广。更灵活 :可以通过 protobuf 配置数据源。更强大 :Web UI 交互性强,支持 SQL 查询,方便深度分析。可编程 :可以通过 Python SDK 进行自动化分析。可以使用 adb shell perfetto 命令来采集:
emu64xa:/ $ perfetto -h
Usage: perfetto
--background -d : Exits immediately and continues in the background.
Prints the PID of the bg process. The printed PID
can used to gracefully terminate the tracing
session by issuing a `kill -TERM $PRINTED_PID`.
...
比较重要的参数有:
-t <duration> :指定持续时间,例如 -t 10s 表示持续 10 秒。
-b <buffer-size> :指定缓冲区大小,单位为 MB,例如 -b 128 表示 128 MB。
-c <config> :指定配置文件,例如 -c my_config.pb 表示使用 my_config.pb 作为配置文件。
--output <file> :指定输出文件,例如 --output my_trace.pb 表示将结果输出到 my_trace.pb 文件。
可以抓取的tag配置有如下:
emu64xa:/sys/kernel/tracing/events $ ls
alarmtimer devfreq gadget irq_vectors mt76 printk spi virtio_gpu
asoc devlink gpio jbd2 mt76_usb qdisc spmi vmalloc
avc dma_fence gpu_mem kmem mt76x02 ras swiotlb vmscan
binder drm header_event kvm napi raw_syscalls synthetic vsock
block dwc3 header_page kvmmmu neigh rcu task vsyscall
bpf_test_run enable huge_memory kyber net regmap tcp watchdog
bpf_trace erofs i2c lock netlink regulator thermal wbt
bridge error_report initcall mac80211 nmi rpm thp workqueue
cfg80211 exceptions interconnect maple_tree notifier rtc timer writeback
cgroup ext4 io_uring mdio nvme sched tlb x86_fpu
cma f2fs iocost migrate oom scsi ucsi xdp
compaction fib iomap mmap page_isolation sd udp xhci-hcd
cpuhp fib6 iommu mmap_lock page_pool signal ufs
csd filelock ipi mmc pagemap skb uvcg
damon filemap irq module percpu smbus v4l2
dev ftrace irq_matrix msr power sock vb2
我们还可以在新版的perfetto网站上直接采用图形化的方式去生成配置文件的代码:
CPU信息配置界面:
抓取GPU的配置页面:
选取要抓取的信息之后,到 cmdline tab那里复制下来:
buffers {
size_kb: 65536
fill_policy: DISCARD
}
buffers {
size_kb: 4096
fill_policy: DISCARD
}
data_sources {
config {
name: "linux.ftrace"
ftrace_config {
ftrace_events: "sched/sched_process_exit"
ftrace_events: "sched/sched_process_free"
ftrace_events: "task/task_newtask"
ftrace_events: "task/task_rename"
ftrace_events: "sched/sched_switch"
ftrace_events: "power/suspend_resume"
ftrace_events: "sched/sched_blocked_reason"
ftrace_events: "sched/sched_wakeup"
ftrace_events: "sched/sched_wakeup_new"
ftrace_events: "sched/sched_waking"
ftrace_events: "sched/sched_process_exit"
ftrace_events: "sched/sched_process_free"
ftrace_events: "task/task_newtask"
ftrace_events: "task/task_rename"
ftrace_events: "power/cpu_frequency"
ftrace_events: "power/cpu_idle"
ftrace_events: "power/suspend_resume"
symbolize_ksyms: true
disable_generic_events: true
}
}
}
data_sources {
config {
name: "linux.process_stats"
process_stats_config {
scan_all_processes_on_start: true
}
}
}
data_sources {
config {
name: "linux.sys_stats"
sys_stats_config {
stat_period_ms: 250
stat_counters: STAT_CPU_TIMES
stat_counters: STAT_FORK_COUNT
cpufreq_period_ms: 250
}
}
}
duration_ms: 10000
直接粘贴到本地 txt 文档里,更名为 pbtx 后缀,推送到设备中,就可以使用命令来使用这个配置文件采集对应的trace数据。
值得注意的是 Perfetto 从 Android 9(P)开始集成,从 Android 11(R)开始默认开启。在 Android 9(P)和 Android 10(Q)上需要先确保开启 Trace 服务
adb shell setprop persist.traced.enable 1
上述从网站点选的配置内容,复制到本地 pbtx 文件之后,再通过 adb 把配置推送到手机:
adb push ~/Desktop/perfetto.pbtx /data/local/tmp/perfetto.pbtx
使用 adb 让手机以指定配置抓 Perfetto Trace:
adb shell 'cat /data/local/tmp/perfetto.pbtx | perfetto --txt -c - -o /data/misc/perfetto-traces/trace'
结束抓取:
adb shell 'perfetto --attach=perf_debug --stop'
Android Studio CPU Profiler Android Studio 中已经自带了一个 Profiler 性能分析工具,它集成了 CPU、内存、网络和电量分析功能。其中的 CPU Profiler 实际上在幕后使用了 Perfetto 或 ART (Android Runtime) 的采样/插桩机制来生成 trace 文件。
集成度高 :与开发环境无缝集成,操作简便。可视化强 :提供了图形化的界面来展示 CPU 使用率、线程状态、方法调用栈等。多种记录模式 :支持 Sampled (采样)、Instrumented (插桩)、System Trace (系统跟踪,即 Perfetto)。可以直接在 Android Studio 中点击 Run -> Profile ‘your app’,然后选择 CPU Profiler 并开始录制。
Python 脚本抓取 最后介绍下使用 python 脚本来抓取trace,这个也是 Google 官方推出的一种方案。在使用 python 脚本抓取到 Trace 后,会把 Trace 文件保存到本地,也会自动在浏览器通过 Perfetto UI 直接打开 Trace 文件,我们直接进行分析。
使用 python 脚本抓取时需要满足以下几个条件:
Android 设备通过 adb 连接到电脑。 把 python 脚本保存在本地,在本地运行 python 脚本。 把抓 Trace 的配置保存在本地,运行 python 脚本时需要指定配置文件。 python 脚本在 GitHub 上的开源地址:
https://github.com/google/perfetto/blob/main/tools/record_android_trace
现在我们把 python 脚本和抓 Trace 的配置放在桌面,命名和目录结构如下:
~/Desktop$
├── perfetto.py
├── perfetto.pbtx
此时我们手机与电脑通过 adb 连接,然后运行以下命令抓取 Trace:
python3 perfetto.py -c perfetto.pbtx -o trace_file.perfetto-trace
上述命令中,-c 是指定配置文件位置, -o 是指定 trace 文件保存位置。
运行命令后,我们开始操作 App,然后觉得抓取到目标 Trace 了,按下ctrl + c 手动结束即可,此时 Trace 文件会被放在 -o 指定的位置,且 Perfetto UI 会被自动打开,直接进行分析即可。
Trace中的重要信息 Trace记录文件,实际上就是系统提前设置好的一些打点记录,我们自己也可也可以手动调用 Trace.beginSection() 来进行标记的。
Trace . beginSection ( "Choreographer#doFrame" );
...
Trace . endSection ();
在分析 trace 文件时,通常需要关注以下几个核心信息:
CPU 使用率 (CPU Usage) :显示每个 CPU 核的负载情况,以及进程和线程在 CPU 上的调度。线程状态 (Thread States) :每个线程在时间轴上的状态,如 Running (运行中)、Sleeping (休眠)、Runnable (可运行,等待 CPU)、Blocked (阻塞)。这对于识别线程阻塞和死锁非常关键。函数调用 (Method Calls) :如果使用采样或插桩模式,可以看到函数调用栈,帮助你识别耗时函数。Binder Transactions :进程间通信的事件,显示 Binder 调用的发起和接收,以及耗时。这是你刚才提到的重点。I/O 操作 (Disk I/O) :文件读写操作,过多的 I/O 会导致性能下降。SurfaceFlinger & VSync :显示帧的渲染过程,对于分析 UI 卡顿 (Jank) 至关重要。你可以看到 VSync 信号、应用绘制耗时、GPU 渲染耗时等。内存事件 (Memory Events) :虽然 CPU trace 主要关注 CPU,但有时也会包含一些内存分配/回收事件,帮你发现内存抖动。自定义事件 (Custom Trace Events) :你可以在自己的代码中插入 Trace.beginSection() / Trace.endSection() 或 ATrace 宏,在 trace 文件中标记出特定代码块的执行时间,这对于追踪应用内部逻辑的耗时非常有用。注意在采集时,选择合适的 TAG 对于生成有效且不过大的 trace 文件至关重要。你需要根据你想要分析的性能问题来选择:
UI 卡顿 / 渲染问题:gfx, view, wm, sched,以及你的 app 类别(用于自定义事件)。 App 启动耗时:am, dalvik (或 ART), app, sched, disk, binder_driver。 耗电问题:power, sched, network, audio, video, camera, disk。 内存抖动 / GC 问题:dalvik (或 ART), app。 文件 I/O 性能:disk, sched, app。 Binder IPC 问题:binder_driver, binder_lock, app, sched。 选择的类别越多,生成的 trace 文件就越大,分析起来也可能越慢,所以建议只选择你真正需要关注的类别。
分析流程 trace文件里面记录的信息是非常详细的,但是如果直接看这些信息,可能很难分析出问题所在。所以,我们需要分析trace文件里面的信息,得到我们想要的信息。并且根据所分析的问题不同,入手的地方也都不一样。常见的需要分析trace文件的场景有以下几个。
一、冷启动分析 Perfetto在线网站比较智能了,有冷启动发生的话,在 startup 一行里就会显示出来了。
首先,可以到 system_server 进程下面,找到iq(Incoming Queue) 事件。
system_server 进程中的 iq 事件是 Binder 请求进入 system_server 传入队列的标记。它是衡量 system_server 处理 Binder 请求的负载和效率的关键指标。
再搜索 launching 事件,就可以找到应用启动的起始点。
从iq到整个launching,就是应用的整体启动耗时。
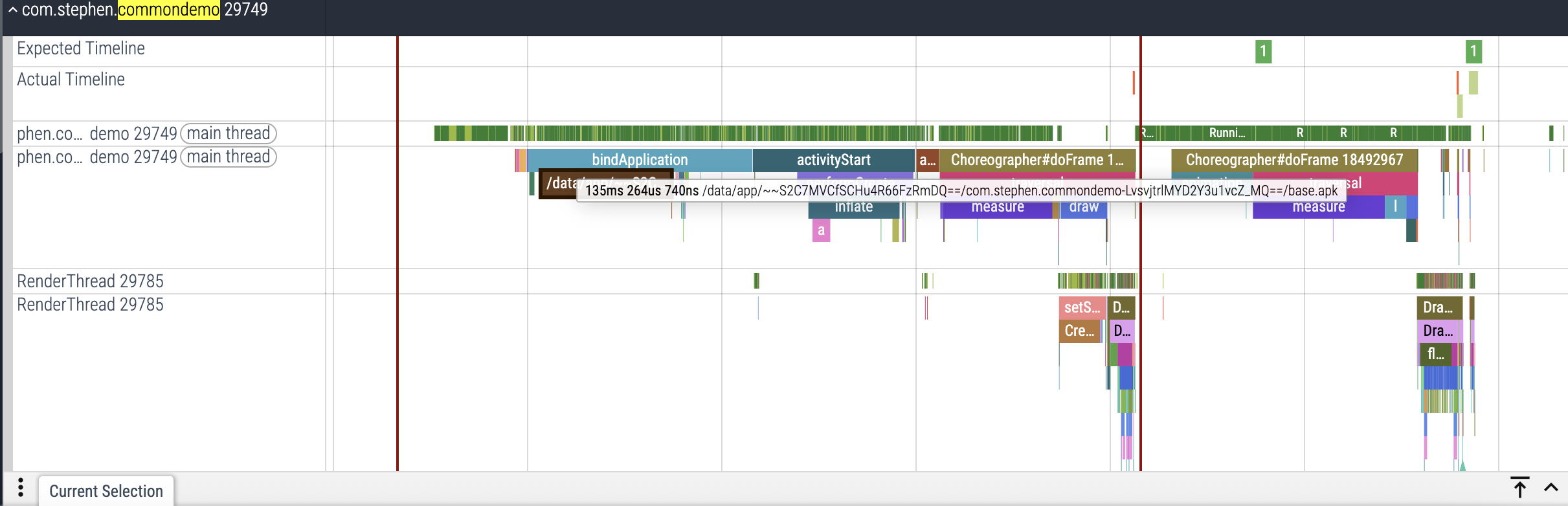
如上图,应用 com.stephen.commondemo 的启动耗时就是 760ms 。
应用内部耗时分析 确定整体的加载时长后,我们找到应用内部的 trace 切片,分析整个冷启动过程中各个阶段耗时分别是多少。
首先要看的第一个阶段,即为bindApplication 阶段,这是一个至关重要的环节。它发生在应用进程已经被系统创建之后,但在任何Activity的生命周期方法(如onCreate)被调用之前。
这个阶段的任务是确保所有基础设置都已就绪,以便你的应用可以正式开始运行。
bindApplication 具体来说,在 bindApplication 阶段会完成以下几件核心事情:
实例化 Application 对象,系统会查找你的应用在 AndroidManifest.xml 文件中声明的 android:name 属性所指向的 Application 类(如果没有指定,则使用默认的 android.app.Application)。然后,系统会创建这个 Application 类的实例 。这个实例是整个应用进程的全局单例,通常用于存放应用级别的状态或进行全局初始化。 Application 对象被实例化后,系统就会立即调用其 onCreate() 方法 。开发者一般在这里执行一些全局性的、只需要执行一次的初始化操作 ,例如初始化第三方SDK(如统计SDK、推送SDK等);初始化全局配置管理器或数据存储(如SharedPreferences、数据库);设置全局崩溃捕获器;初始化一些单例对象。需要注意的是Application.onCreate() 是在主线程(UI线程)中调用的。因此,在这个方法中执行耗时操作是导致应用冷启动慢的常见原因之一 。系统会从设备存储中找到并加载你的应用 APK 文件 。具体的会加载 APK 中的 DEX(Dalvik Executable)文件 。DEX 文件包含了你的应用程序编译后的字节码。ART(Android Runtime)虚拟机需要这些字节码才能执行你的Java/Kotlin代码。这个过程包括从磁盘读取APK文件;将所需的类加载到内存中;ART可能会进行即时编译(JIT)或在安装时进行的预先编译(AOT)相关的操作,以优化代码执行效率。 设置应用程序的运行时环境,系统会为新创建的应用进程配置一系列运行时环境。这包括:配置类加载器: 确保应用可以正确地加载和找到所有需要的类。初始化资源管理器: 设置 Resources 对象,以便应用可以访问其所有资源文件(如布局XML、字符串、图片等)。设置默认的线程和 Looper: 为主线程(UI线程)准备好消息循环(Looper),以便处理UI事件和消息。初始化上下文: 为 Application 对象设置上下文(Context),使其能够访问系统服务。 activityStart activityStart 阶段系统主要负责将一个 Activity 从其创建或重新启动的状态推进到用户可以与之交互的可见状态。标志着特定 Activity 生命周期的正式开始。 activityStart 阶段通常会执行以下任务:
Activity.onCreate()生命周期,开发者通常会在这里使用 setContentView() 方法加载 Activity 的 UI 布局 XML 文件。通过 findViewById() 或数据绑定/视图绑定获取对 UI 元素的引用。设置点击监听器、适配器、初始化列表、RecyclerView 等。在这里或 onRestoreInstanceState() 中恢复之前保存的状态。初始化与此 Activity 关联的 ViewModel。启动一些初始化显示所需要的数据的加载。Activity.onStart()周期,这个方法表示 Activity 即将变得可见。开发者一般会在这里 注册广播接收器或监听器 启动需要 Activity 可见时才能进行的系统广播监听或传感器监听。启动一些与 UI 可见性相关的动画或轻量级资源加载。重新连接到一些系统服务。在 onStart() 之后,onResume() 会被调用,表示 Activity 已经位于 Activity 栈的顶部,并且即将与用户交互 。启动或恢复与用户交互密切相关的动画。获取相机、音频焦点等需要独占的资源。确保 UI 显示的是最新数据。 视图树的测量、布局和绘制 (Measure, Layout, Draw),这是 activityStart 阶段中非常耗时且关键的视觉准备工作 。执行 测量 (Measure) ,布局 (Layout) ,绘制 (Draw) 。这个过程如果复杂或有深层次的视图嵌套,会消耗大量时间,直接影响用户看到第一个可交互画面的速度。 Choreographer#doFrame Choreographer#doFrame 是 Android trace 文件中一个非常重要的事件,特别是在分析 UI 渲染性能 时。简单来说,它表示了 Android 系统中 “编舞者”(Choreographer) 完成了一帧画面的绘制工作 。
Choreographer 是 Android 系统中一个核心组件,它的职责是协调和同步应用程序的动画、输入事件和 UI 绘制。它的目标是确保所有这些操作都能在 16.67 毫秒 内完成(对于 60fps 的屏幕刷新率),从而实现流畅的 60 帧每秒的用户体验。如果一帧的绘制时间超过了这个阈值,用户就会感觉到卡顿(jank)。
当 Choreographer#doFrame 事件在 trace 文件中出现时,它代表了系统为了 准备和绘制屏幕上的一帧画面 所执行的所有关键任务。它内部通常会包含以下几个主要阶段:
处理输入事件 (Input Handling):检查并分发所有待处理的输入事件,如触摸、按键等。 这是确保 UI 响应用户操作的第一步。 处理动画 (Animation Handling):更新所有正在进行的动画状态(例如,属性动画、视图动画等)。 根据动画的当前进度计算视图的新位置、大小、透明度等。 回调 View.onDraw / performTraversals / 视图绘制 (View Drawing):这是 Choreographer#doFrame 中最关键也是最耗时 的部分之一。 它会触发整个视图层次结构的测量 (Measure) 、布局 (Layout) 和绘制 (Draw) 过程。 测量 (Measure): 计算视图的尺寸。布局 (Layout): 确定视图在屏幕上的位置。绘制 (Draw): 将视图的内容(文本、图片、背景等)渲染到对应的 Surface 上。这个过程涉及到 CPU 和 GPU 的协同工作,最终将像素数据写入帧缓冲区。 同步和提交 (Sync and Submit): 在所有绘制命令都发出后,将这些命令提交给 GPU 进行实际渲染。 SurfaceFlinger 会将各个应用程序的 Surface 合成到最终的屏幕缓冲区,然后显示出来。在 trace 文件中分析 Choreographer#doFrame 事件时,
持续时间 (Duration) 应该小于 16.67 毫秒 (对于 60fps),首帧应该在200ms左右。
耗时最多的子事件是瓶颈所在。 如果 View#draw 或 performTraversals 耗时很长,说明是视图绘制复杂或视图层级过深导致的问题。如果 Input 或 Animation 耗时较长,则可能是输入处理或动画计算的问题。频繁的 GC (垃圾回收) 事件也会导致 doFrame 延迟。密集的磁盘 I/O 或网络请求(如果它们意外地发生在主线程)也可能阻塞 doFrame。
展开 Choreographer#doFrame 并查看其内部的调用栈,可以帮助你精确定位是哪个方法 、哪个组件 导致了耗时。 特别关注那些在 onCreate、onStart、onResume 中被调用,并且在 Choreographer#doFrame 范围内占用大量主线程时间的自定义方法或第三方 SDK 初始化。
滑动卡顿分析 滑动卡顿的本质是 UI 渲染跟不上屏幕的刷新率,导致丢帧。目标是让每帧的绘制时间保持在 16.67 毫秒 (60fps) 或更低。
抓取时,可以使用 adb shell perfetto 命令。确保包含以下关键类别:
gfxinputviewwmamscheddalvikmemory示例命令(可能需要调整时间 -t 和输出路径 -o):
perfetto -o /data/misc/perfetto-traces/trace_log -t 120s -b 100mb -s 150mb sched freq idle am wm gfx view input dalvik memory
然后将 trace 文件拉取到电脑并导入 ui.perfetto.dev 进行分析。
分析 Trace 文件中的滑动卡顿 查找 Choreographer#doFrame 事件: 在 Trace 的时间轴上,重点关注 Choreographer#doFrame
正常情况: 对于 60fps,Choreographer#doFrame 的持续时间应该接近 16.67 毫秒 。卡顿迹象: 如果你看到 Choreographer#doFrame 事件的持续时间远超 16.67 毫秒 (例如 30ms, 50ms 甚至 100ms+),这表明发生了一帧的渲染超时,即掉帧 ,用户就会感觉到卡顿。确定卡顿发生的时间点:
在时间轴上找到滑动操作开始和结束的区域。 在滑动过程中,特别留意那些持续时间异常长的 Choreographer#doFrame 事件。这些就是卡顿发生的精确时刻。 展开耗时长的 Choreographer#doFrame: 点击这些异常长的 Choreographer#doFrame 事件,展开它们的内部细节。你需要深入查看是哪个子事件导致了大部分的耗时。常见的罪魁祸首包括:
View#draw 或 ViewRootImpl#performTraversals:视图层级过于复杂 ,或者在绘制阶段做了大量耗时操作。检查 布局(Layout) 阶段:视图的测量和布局是否复杂,是否存在过度嵌套。 检查 绘制(Draw) 阶段:是否存在大量自定义绘制逻辑、图片加载或不必要的重绘。 Input 处理:GC (Garbage Collection):你的应用程序代码: 主线程 I/O: 文件读写、数据库操作、网络请求等如果意外地发生在主线程,会严重阻塞 UI 渲染。复杂计算: 任何在主线程进行的复杂数据处理、图片处理或算法计算。RecyclerView/ListView 适配器优化不足: onCreateViewHolder() 或 onBindViewHolder() 中进行了耗时操作。没有正确使用 ViewHolder 复用机制。 列表项布局过于复杂。 图片加载没有异步处理或优化。 第三方 SDK 调用: 有些 SDK 可能会在不经意间在主线程执行耗时操作。结合 CPU Profiler 的调用栈分析: 如果你使用的是 Android Studio CPU Profiler 的 “System Trace” 模式,并同时捕获了方法追踪数据(或者在 Perfetto 中启用了 CPU 采样),你可以:
选择 Choreographer#doFrame 事件卡顿发生的时间段。 查看下方的 “Flame Chart” (火焰图) 。火焰图会直观地显示在此期间 CPU 花费在哪些函数上。 识别最宽的“火焰”: 这就是 CPU 耗时最多的函数。沿着调用链向上追溯: 从底层函数追溯到你的应用代码,找出是哪个方法导致了性能瓶颈。例如,你可能会看到你的 Adapter.onBindViewHolder() 或一个自定义 View 的 onDraw() 方法占据了大量时间。针对性优化 根据 Trace 分析的结果,进行针对性优化:
将耗时操作移出主线程: 任何不涉及 UI 更新的耗时操作(网络请求、数据库查询、复杂计算、大文件读写)都应该在后台线程 进行。 使用 Kotlin 协程、ThreadPoolExecutor 或 AsyncTask (不推荐新项目) 等异步机制。 优化 UI 布局和绘制: 扁平化视图层级: 使用 ConstraintLayout 减少嵌套。避免过度绘制: 检查并移除不必要的背景、减少重叠视图。使用开发者选项中的 “Debug GPU Overdraw” 帮助发现。优化自定义 View: 确保 onDraw() 方法高效,不创建新对象,不执行复杂计算或 I/O。使用 Canvas.clipRect() 限制绘制区域。优化列表性能 (RecyclerView/ListView): 高效的 ViewHolder: 确保 ViewHolder 正确复用,并且 onCreateViewHolder() 和 onBindViewHolder() 方法执行高效,不进行耗时操作。异步图片加载: 使用 Glide、Coil 或 Picasso 等库异步加载和缓存图片,避免在主线程加载大图。避免复杂布局: 列表项布局尽量简洁,减少层级和复杂计算。减少内存抖动和 GC 频率: 避免在循环或频繁调用的方法中创建大量临时对象。 使用对象池或缓存来重用对象。 延迟初始化: 对于某些组件或数据,可以考虑懒加载,即只在需要时才进行初始化。 腾讯的 Bugly 是一款专注于移动端和 PC 端应用的 线上崩溃监控、性能监控与异常分析 的一站式工具,广泛应用于移动应用(Android/iOS)以及小游戏、小程序等平台。它帮助开发者实时发现、定位和修复线上应用中的崩溃、卡顿、ANR(Application Not Responding)、内存泄漏等问题,从而提升应用稳定性与用户体验。
一、Bugly 数据采集原理 Bugly 的核心功能依赖于对应用运行时数据的 实时采集与上报 。
当应用发生 未捕获的异常(如 Java 的 Throwable、Objective-C 的 NSException、C++ 的 Signal/Exception) 时,Bugly SDK 会通过 全局异常捕获机制 拦截这些异常。
捕获到的异常信息包括:
- 崩溃堆栈(Call Stack)
- 崩溃类型(Java Crash / Native Crash / ANR / OOM 等)
- 崩溃线程信息
- 设备信息(型号、系统版本、CPU 架构等)
- 应用信息(版本号、渠道、包名等)
- 用户信息(可选,如用户 ID、登录态)
在 Android 上,Bugly 通过监听 /data/anr/traces.txt 文件或使用 FileObserver 监听 ANR 日志文件变化,或者通过 Looper 监听主线程卡顿超时 来检测 ANR。在 iOS 上,通过监控主线程 RunLoop 状态,判断是否长时间未响应。
开发者也可以手动调用 Bugly SDK 接口,上报自定义的异常、业务错误或关键日志,便于排查特定业务问题。
2. 数据传输与上报机制 本地缓存 + 批量上报 :SDK 会将采集到的数据先缓存在本地(如 SQLite 或文件),在网络可用时(如 Wi-Fi 或移动网络)进行批量压缩加密后上传到 Bugly 服务器。断点续传 & 异常重试 :如果上传失败,数据会在下次启动或网络恢复时自动重试,确保数据不丢失。实时性 :大部分崩溃数据可在 几分钟内 展示在 Bugly 后台,供开发者及时查看与分析。3. 符号化(Symbolication) 对于 Native 崩溃(C/C++) ,崩溃堆栈通常是经过编译器优化的地址,无法直接阅读。Bugly 通过上传 符号表文件(如 dSYM / SO 符号文件) ,在服务端进行 符号还原(Symbolication) ,将地址转换为具体的函数名、文件名与行号,极大地方便定位问题。
开发者需要在每次发布新版本时,上传对应的符号表 ,否则 Native 崩溃堆栈可能难以解析。 二、Bugly 设计架构 Bugly 的整体架构可以分为 客户端 SDK、数据传输层、服务端平台 三大部分:
1. 客户端 SDK(集成在 App 中) 负责在用户设备上 实时监控、采集各种异常和性能数据 ,包括:
崩溃捕获模块 ANR 监控模块 卡顿检测模块 内存监控模块 数据本地存储与上报模块 用户行为与自定义事件上报接口 SDK 具有如下特点:
轻量级、低侵入、高性能 :对应用本身的性能影响极小,启动速度快,运行时 CPU/内存开销低。多平台支持 :支持 Android、iOS、微信小程序、Unity、Cocos 等平台。灵活配置 :开发者可以控制监控粒度,比如是否开启卡顿监控、ANR 监控,设置卡顿阈值等。2. 数据传输层 负责将客户端采集的数据安全、可靠地传输到 Bugly 云端服务器。 包括数据加密、压缩、断点续传、重试机制等。 支持离线缓存,在网络恢复后自动同步。 3. 服务端平台(Bugly 控制台)
这是开发者日常使用 Bugly 的主要后台入口,提供以下功能:
崩溃分析实时展示 Crash 数量、影响用户数、崩溃率等关键指标。 提供详细的崩溃堆栈、设备信息、用户信息、出现趋势图等。 支持按版本、时间、设备等维度筛选与分析。 支持 Native 崩溃符号化展示 ,精准定位问题代码。 ANR 分析展示 ANR 发生次数、影响用户、堆栈信息等。 支持 ANR 日志下载与分析。 报警与通知支持设置崩溃率、ANR 阈值等报警策略,通过邮件、企业微信、钉钉等方式通知开发者。 多团队协作与权限管理支持不同团队成员拥有不同权限,如只读、上传符号表、管理项目等。 三、Bugly 接入方式 Bugly 提供了非常便捷的 SDK 接入流程,支持主流开发语言与平台。
(1) Android 接入 Android 平台的接入,首先需要在项目的 build.gradle 中引入 Bugly SDK 依赖。
下载Bugly SDK:
Bugly SDK
添加Bugly SDK依赖:
dependencies {
implementation files('libs/Bugly_sdk.aar')
}
腾讯也提供了 Maven 仓库的在线接入方式,具体查看 Bugly SDK Andoid 接入文档
在代码中初始化 Bugly(一般在 Application 的 onCreate 方法中):
CrashReport . initCrashReport ( getApplicationContext (), "你的AppID" , false );
第三个参数 false 表示是否开启 Debug 模式,开启后会在 Logcat 中打印详细的日志,方便调试。
(2)IOS 接入 聚焦于Swift项目,使用Framework包管理接入Bugly SDK。
下载Bugly SDK Framework包:
Bugly SDK Framework
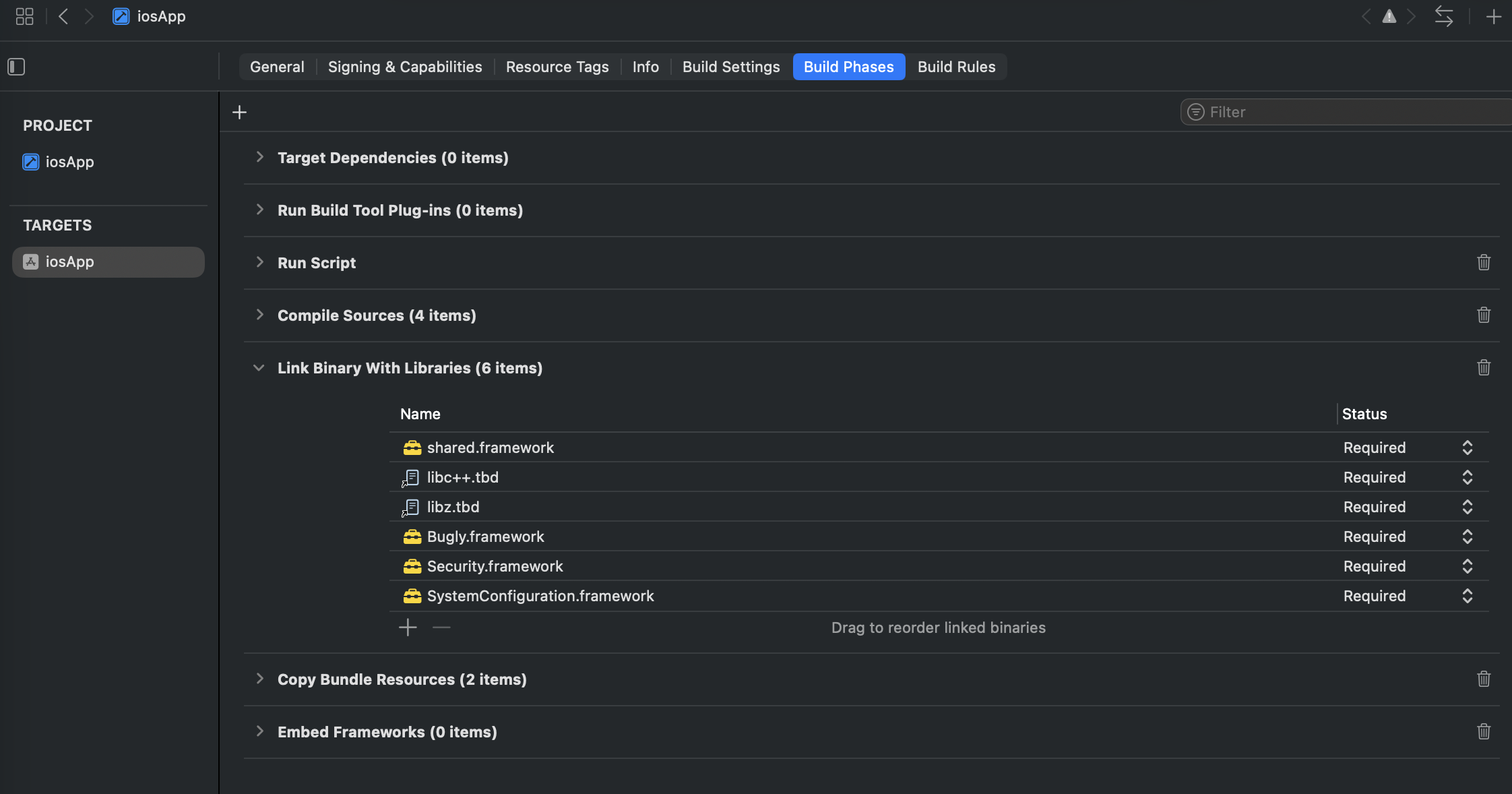
拖拽Bugly.framework文件到Xcode工程内(请勾选Copy items if needed选项)
然后在项目的 build phase 板块的 Link Binary With Libraries 中添加 Bugly.framework。还有:
- SystemConfiguration.framework
- Security.framework
- libz.dylib 或 libz.tbd
- libc++.dylib 或 libc++.tbd
然后右键创建一个空的OC文件,XCode会提示自动创建一个对应的 Bridge-Header.h 文件,创建后在这个头文件中添加以下代码:
注意在项目配置中添加这个头文件的相对路径。
在工程 AppDelegate.m 的 application:didFinishLaunchingWithOptions: 方法中初始化:
func application (
_ application : UIApplication ,
didFinishLaunchingWithOptions launchOptions : [ UIApplication . LaunchOptionsKey : Any ]?
) -> Bool {
// 应用程序启动完成后调用
print ( "✅ 应用已启动" )
// 1. 创建一个 BuglyConfig 实例
let config = BuglyConfig ()
// 2. 设置一些自定义配置(可选)
config . debugMode = true // 开启 Debug 模式,查看 SDK 内部日志
config . channel = "AppStore" // 自定义渠道,比如 "AppStore", "Test", "Internal"
config . version = "1.0.0" // 自定义版本号(如果和 Xcode 的不一致)
config . blockMonitorEnable = true // 开启卡顿监控
config . blockMonitorTimeout = 2.0 // 卡顿超时时间(秒)
config . unexpectedTerminatingDetectionEnable = true // 开启非正常退出检测
config . viewControllerTrackingEnable = true // 开启页面信息记录(默认开启)
// 如果你想接收回调,比如崩溃时带上额外信息,可以实现 BuglyDelegate
// config.delegate = self // (需遵循 BuglyDelegate 协议)
// 3. 使用配置启动 Bugly
Bugly . start ( withAppId : "5875922631" ,
developmentDevice : true ,
config : config )
return true
}
注意在新项目中,一般都直接使用App作为项目入口了:
@main
struct iOSApp : App {
// 注入 UIKit 的 AppDelegate,使其仍然可以响应系统事件
@UIApplicationDelegateAdaptor ( AppDelegate . self ) var appDelegate
var body : some Scene {
WindowGroup {
ContentView ()
}
}
}
需要去掉AppDelegate的main注解,使用 UIApplicationDelegateAdaptor 来注入 AppDelegate。
崩溃上报测试:
struct ContentView : View {
let greet = Greeting () . greet ()
var body : some View {
Text ( greet )
. onTapGesture {
print ( "文字被点击了!" )
fatalError ( "这是一个手动的error测试" )
// BugCreate_iosKt.createACrash()
}
}
}
struct ContentView_Previews : PreviewProvider {
static var previews : some View {
ContentView ()
}
}
在文字被点击时,会触发fatalError,从而上报一个崩溃。也可以使用KMP内部实现的 BugCreate_iosKt.createACrash() 方法来手动上报一个崩溃。
(3)其他平台 Unity、Cocos、微信小程序、H5 等平台均有对应的接入文档与 SDK。 2. 符号表上传 Android :需要上传 dSYM 文件(或对应映射文件) ,通常从构建系统中自动上传(如 Jenkins 插件、Gradle 脚本)。iOS :必须上传 dSYM 文件 ,每次 App 发布新版本后都要上传,否则 Native 崩溃无法解析。Bugly 提供了 自动符号表上传脚本 / 插件 ,也支持手动上传。 3. 控制台使用 在报错,ANR,崩溃发生之后,过一段时间才能在 Bugly 控制台看到。
登录 Bugly 官方网站:腾讯Bugly 一种愉悦的开发方式
选择对应的项目(App)。 查看 崩溃、ANR、卡顿、性能 等核心监控数据。 点击某个崩溃,可查看:崩溃概览(影响用户数、次数、版本分布等) 堆栈详情(支持符号化) 设备信息、用户信息 时间趋势图 使用筛选、搜索功能快速定位问题。 配置报警、用户反馈、自定义监控等高级功能。 滑动掉帧监控 另一个比较影响体验的性能问题就是滑动卡顿。滑动的卡顿一般都在长列表进行交互时发生,要监控应用内部滑动组件(如 RecyclerView 等)的卡顿,主要有以下几种方案:
方案 1:基于 Choreographer 帧回调监控主线程卡顿 这是目前最常用、性能开销较低、可控性高的方式,可以用来监控全局或指定区域的主线程卡顿(包括滑动卡顿)。
Android 系统通过 Choreographer 类调度每一帧的 UI 渲染。它提供了一个回调:Choreographer.FrameCallback,在每一帧即将渲染时触发。我们可以记录每帧的时间戳,如果发现两次回调之间的时间间隔超过 16ms(或者自定义阈值,比如 30ms),则认为发生了卡顿。
只需要注册一个 Choreographer.FrameCallback,计算相邻两帧的时间差。如果时间差超过设定的阈值(如 32ms 表示掉帧 2 帧),则认为发生卡顿。在卡顿发生时,可以收集如下信息:
- 卡顿时长
- 当前主线程堆栈(找出耗时操作)
- 当前 Activity / Fragment / View 信息
- 是否在滑动状态(如 RecyclerView 是否正在滚动)
示例:
Choreographer . getInstance (). postFrameCallback ( object : FrameCallback {
private var lastFrameTimeNanos : Long = 0
override fun doFrame ( frameTimeNanos : Long ) {
if ( lastFrameTimeNanos != 0L ) {
val elapsedNanos = frameTimeNanos - lastFrameTimeNanos
val elapsedMillis : Long = TimeUnit . NANOSECONDS . toMillis ( elapsedNanos )
// 设定卡顿阈值为 32ms(约两帧丢失)
if ( elapsedMillis > 32 ) {
// 发生了卡顿,可以打印堆栈或上报
Log . e ( "卡顿监控" , "检测到卡顿: " + elapsedMillis + "ms" )
BuglyLog . e ( "卡顿监控" , "检测到卡顿: " + elapsedMillis + "ms" )
}
}
lastFrameTimeNanos = frameTimeNanos
Choreographer . getInstance (). postFrameCallback ( this )
}
})
方案 2:基于 Looper 日志打印 BlockCanary 是一个著名的开源卡顿检测库,其核心原理是在主线程的 Looper 处理消息前后打点,计算每个 Message 的处理耗时。
如果某个消息处理时间超过阈值(如 16ms 或 500ms),则认为发生卡顿,此时 dump 线程堆栈等信息用于分析。
通过替换 Looper.getMainLooper().setMessageLogging(),监听主线程消息的执行。记录每条消息的开始和结束时间,如果执行时间过长,就触发卡顿分析。
可以能精准捕捉主线程耗时操作。输出卡顿时的堆栈、线程状态、内存等信息,方便定位问题。
但是对性能有一定影响(但通常可接受,尤其只在调试时使用)。
下面的这段代码实现了两个方法,一个是开启检测,一个是关闭检测。
以LazyColumn为例,在 scrollState.isScrollInProgress 为true时开启检测,在 scrollState.isScrollInProgress 为 false 时关闭检测。
object LooperMsgListener {
private var lastFrameTime : Long = 0
fun startCheckFrameTime () {
Log . i ( "卡顿监控" , "startCheckFrameTime" )
lastFrameTime = System . currentTimeMillis ()
Looper . getMainLooper (). setMessageLogging { msg ->
val currentTime = System . currentTimeMillis ()
if ( lastFrameTime != 0L ) {
val diffTime = currentTime - lastFrameTime
if ( diffTime > 16 ) {
Log . d ( "卡顿监控" , "卡顿检测: $diffTime ms" )
}
}
lastFrameTime = currentTime
}
}
fun stopCheckFrameTime () {
Log . i ( "卡顿监控" , "stopCheckFrameTime" )
Looper . getMainLooper (). setMessageLogging ( null )
}
}
方案 3: 基于trace文件 可以先采集trace文件,再上传到服务器上再分析。
可以 查找 Choreographer#doFrame 事件 ,在 Trace 的时间轴上,重点关注 Choreographer#doFrame
正常情况: 对于 60fps,Choreographer#doFrame 的持续时间应该接近 16.67 毫秒 。卡顿迹象: 如果你看到 Choreographer#doFrame 事件的持续时间远超 16.67 毫秒 (例如 30ms, 50ms 甚至 100ms+),这表明发生了一帧的渲染超时,即掉帧 ,用户就会感觉到卡顿。还要确定卡顿发生的时间点 ,在时间轴上找到滑动操作开始和结束的区域。在滑动过程中,特别留意那些持续时间异常长的 Choreographer#doFrame 事件。这些就是卡顿发生的精确时刻。
Google官方的分析网站地址为: https://ui.perfetto.dev/
ANR是Android系统上,应用交互过程中可能出现的最差的体验了,它代表了应用程序已经经历了 长时间无响应,并导致崩溃 。
当应用程序的主线程被冻结,导致应用程序无法响应用户输入时,就会发生 ANR。届时,系统将弹出一个 ANR对话框 ,提示用户是等待还是强制关闭应用程序。
ANR本身是一套兜底机制,它监控Android应用响应是否及时。
我们可以把发生ANR比作是引爆炸弹,那么整个流程包含三部分组成:
埋定时炸弹:中控系统(system_server进程)启动倒计时,在规定时间内如果目标(应用进程)没有干完所有的活,则中控系统会定向炸毁(杀进程)目标。 拆炸弹:在规定的时间内干完工地的所有活,并及时向中控系统报告完成,请求解除定时炸弹,则幸免于难。 引爆炸弹:中控系统立即封装现场,抓取快照,搜集目标执行慢的罪证(traces),便于后续的案件侦破(调试分析),最后是炸毁目标。 常见的ANR类型有service、broadcast、provider以及input.
各个ANR类型的超时时间阈值如下:
可以看到,ANR的判定时间和前台后台强相关,差距很大,通常在前台的app会有更严格的限制。
那么Android系统是如何划分前台后台应用的?
前台后台 如果满足以下任一条件,则进程会被认为位于前台。
正在用户的互动屏幕上运行一个 Activity(其 onResume() 方法已被调用)。 有一个 BroadcastReceiver 目前正在运行(其 BroadcastReceiver.onReceive() 方法正在执行) 有一个 Service 目前正在执行其某个回调(Service.onCreate()、Service.onStart() 或 Service.onDestroy())中的代码。 输入事件耗时 Google总结有如下几种常见的情况:
原因 出现的情况 建议的解决方法 binder 调用缓慢 主线程 binder 调用缓慢 将该调用移出主线程或尝试优化该调用(如果您拥有该 API)。 连续多次进行 binder 调用 主线程连续多次进行 binder 调用 请勿在紧密循环中执行 binder 调用。 阻塞 I/O 主线程阻塞 I/O,例如数据库或网络访问。 将所有阻塞 IO 移出主线程。 锁争用 主线程处于阻塞状态,正在等待获取锁。 减少主线程和其他线程之间的锁争用。 优化其他线程中运行缓慢的代码。 耗用大量资源的帧 单个帧中的渲染工作量太大,导致严重卡顿。 减少帧渲染工作。请勿使用 n2 算法。使用高效的组件实现滚动或分页等操作,例如使用 Jetpack Paging 库。 被其他组件阻塞 另一个组件(如广播接收器)正在运行并阻塞主线程。 尽可能将非界面工作移出主线程。在其他线程上运行广播接收器。 GPU 挂起 GPU 挂起是系统或硬件问题,会导致渲染被阻塞,进而导致输入调度 ANR。 遗憾的是,通常无法在应用端解决这些问题。如有可能,请与硬件团队联系来排查问题。
例如:
System.Settings系统数据库的写操作 System.Settings 涉及到对系统级配置的修改,这些操作可能需要:
磁盘 I/O 操作: 写入设置需要将数据持久化到存储中。磁盘 I/O 可能是阻塞性的,尤其是在设备性能不佳、存储空间紧张或有其他高负载操作时。 进程间通信 (IPC): System.Settings 的修改通常需要通过 Binder 机制与系统服务进行通信。如果系统服务繁忙或响应缓慢,主线程可能会被阻塞。 并发访问: 如果有多个线程或进程同时尝试写入或读取 System.Settings,可能会导致锁竞争,从而阻塞主线程。 权限检查: 写入某些 System.Settings 值需要特定的权限(例如 WRITE_SETTINGS),系统在执行操作前会进行权限验证,这也会占用一定时间。 生命周期回调里做了耗时操作 Android 的生命周期函数(如 onCreate()、onResume()、onPause()、onDestroy() 等)都是在主线程上调用的。它们的职责是快速完成 UI 初始化、数据加载、状态保存等轻量级任务,以便应用能够迅速响应用户操作并呈现界面。如果在这些函数中执行以下类型的耗时操作,就会阻塞主线程,导致 ANR。
常见的可能导致ANR的操作:
1. onCreate() 中进行耗时操作 场景: 在 onCreate() 中加载大量数据、进行复杂的数据库查询、或执行网络请求。ANR 原因: 应用启动时,onCreate() 需要快速完成,才能显示第一个界面。如果耗时过长,用户将看到黑屏或卡顿,并最终收到 ANR 提示。解决方案: 数据加载和网络请求: 将这些操作移动到后台线程 中执行。Kotlin Coroutines (协程): 推荐使用,利用 Dispatchers.IO 或 Dispatchers.Default。Java ExecutorService / Thread: 手动管理线程池。Android Architecture Components (如 Room, ViewModel): 配合 LiveData 或 Flow,在 ViewModel 中处理数据逻辑,然后在 UI 线程观察数据变化。UI 初始化: 仅在 onCreate() 中进行必要的 UI 视图膨胀和组件绑定。2. onResume() 中进行耗时操作 场景: 在 onResume() 中刷新大量数据、注册耗时监听器。ANR 原因: 当 Activity 从后台回到前台,或从部分遮盖状态恢复时,会调用 onResume()。如果这里有耗时操作,用户会感到界面卡顿,无法立即与应用交互。解决方案: 同 onCreate(),将耗时操作放到后台线程 。 考虑使用 懒加载 (Lazy Loading) 或按需加载 策略,只加载屏幕可见部分的数据。 3. onPause() / onStop() 中进行耗时操作 场景: 在 onPause() 或 onStop() 中保存大量数据到磁盘、执行复杂的数据库事务。ANR 原因: 当用户离开当前 Activity (例如,按下 Home 键、切换到其他应用、或者启动新的 Activity) 时,系统会调用 onPause() 和 onStop()。这些方法需要迅速完成,以便系统能够释放资源或切换到其他应用。如果耗时过长,系统可能认为当前应用卡死,导致 ANR。解决方案: 数据保存: 将耗时的数据持久化操作(如数据库写入、文件写入)移至后台线程 。小量数据: 对于少量非关键数据,可以使用 SharedPreferences.apply() (异步写入) 而不是 SharedPreferences.commit() (同步写入)。复杂的保存逻辑: 考虑使用 WorkManager 来调度后台任务进行数据同步或上传。注意: 尽管 onPause() 和 onStop() 应该快速完成,但它们是保存用户状态的关键时机。务必确保重要数据的保存,即使将其推迟到后台线程,也要确保任务的可靠性。4. onDestroy() 中进行耗时操作 场景: 在 onDestroy() 中释放大量资源、关闭文件句柄、清理缓存等。ANR 原因: 当 Activity 被销毁时调用。虽然此时应用可能即将退出,但如果 onDestroy() 阻塞,也可能导致系统资源长时间不释放,甚至在特定情况下触发 ANR。解决方案: 资源释放: 大多数资源释放(如 MediaPlayer.release()、大图片 Bitmap 释放)可以放在主线程,但如果涉及到大量文件 I/O 或网络断开连接的阻塞,仍应考虑放在后台线程 。清理工作: 确保清理工作简洁高效。广播接收器超时 接收到广播之后,如果在一定时间内没有执行完onReceive,也会被判定为ANR。
goAsync的作用 广播接收器 goAsync() 的用处,简单说就是手动地拖延onReceive执行的时间到子线程结束后。
所以使用的时机就是我们需要在接收到广播之后,开子线程处理耗时任务的时候。广播接收器接收到广播后,开始执行onReceive的方法,这时候进程是前台状态,一旦走完,又会恢复到后台的状态。如果在onReceive回调里直接开子线程,那么onReceive走完后,进程优先级较低,其内的线程优先级也较低,可能任务没有执行完就结束了。分析onReceive源码,可以看到在其结束时,会检查 PendingResult 的状态,如果不为空就表明任务执行完毕。也就恢复到了后台状态。
goAsync() 方法就是将 PendingResult设置为 null,也就不会马上结束掉当前的广播,相当于 “延长了广播的生命周期”,让广播依然处于活跃状态。在子线程的任务执行完毕,再调用一次 PendingResult.finish(),结束onReceive方法的计时。
所以广播接收器ANR的情况就是onReceive方法超时,或者goAsync方法调用完之后,超时时间内没有调用finish。
Service执行超时 onCreate(),onStartCommand(),onBind() 等生命周期在20s内没有处理完成,就会发生ANR。
ANR日志分析 原生位置一般在 /data/anr/ 目录下:
husky:/ $ cd data/anr
husky:/data/anr $ ls
anr_2025-06-25-15-48-12-221 anr_2025-06-25-15-54-17-222 anr_2025-06-25-16-51-03-671 anr_2025-06-25-16-52-33-144
anr_2025-06-25-15-50-25-017 anr_2025-06-25-16-14-41-452 anr_2025-06-25-16-51-21-354
anr_2025-06-25-15-51-11-474 anr_2025-06-25-16-15-16-616 anr_2025-06-25-16-51-58-524
husky:/data/anr $
基于AOSP定制后的系统,如果对ANR日志输出位置有优化,可能为其自定的位置。
一般来说,文件首行就会表明ANR的类型:
输入事件超时未处理
Subject: Input dispatching timed out 。。。。
广播接收器处理超时
Subject: Broadcast of Intent { act=android.intent.action.SCREEN_ON flg=0x50200010 }
Service超时
Subject: executing service com.stephen.commondemo/.anr.AnrService
ContentProvider超时
日志关键字:timeout publishing content providers
分析步骤 首先我们搜索am_anr,找到出现ANR的时间点、进程PID、ANR类型、然后再找搜索PID,找前5秒左右的日志。 过滤ANR IN 查看CPU信息 接着查看traces.txt,找到java的堆栈信息定位代码位置,最后查看源码,分析与解决问题。 分析举例
场景一 07-20 15:36:36.472 1000 1520 1597 I am_anr : [0,1480,com.xxxx.moblie,952680005,Input dispatching timed out (AppWindowToken{da8f666 token=Token{5501f51 ActivityRecord{15c5c78 u0 com.xxxx.moblie/.ui.MainActivity t3862}}}, Waiting because no window has focus but there is a focused application that may eventually add a window when it finishes starting up.)]
ANR时间:07-20 15:36:36.472 进程pid:1480 进程名:com.xxxx.moblie ANR类型:KeyDispatchTimeout
我们已经知道了发生KeyDispatchTimeout的ANR是因为 input事件在5秒内没有处理完成。那么在这个时间07-20 15:36:36.472 的前5秒,也就是(15:36:30 ~15:36:31)时间段左右程序到底做了什么事情?
场景二 07-20 15:36:58.711 1000 1520 1597 E ActivityManager: ANR in com.xxxx.moblie (com.xxxx.moblie/.ui.MainActivity) (关键字ANR in + 进程名 + Activity名称)
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: PID: 1480 (进程pid)
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: Reason: Input dispatching timed out (AppWindowToken{da8f666 token=Token{5501f51 ActivityRecord{15c5c78 u0 com.xxxx.moblie/.ui.MainActivity t3862}}}, Waiting because no window has focus but there is a focused application that may eventually add a window when it finishes starting up.)(ANR的原因,输入分发超时)
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: Load: 0.0 / 0.0 / 0.0 (Load表明是1分钟,5分钟,15分钟CPU的负载)
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: CPU usage from 20ms to 20286ms later (2018-07-20 15:36:36.170 to 2018-07-20 15:36:56.436):
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 42% 6774/pressure: 41% user + 1.4% kernel / faults: 168 minor
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 34% 142/kswapd0: 0% user + 34% kernel
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 31% 1520/system_server: 13% user + 18% kernel / faults: 58724 minor 1585 major
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 13% 29901/com.ss.android.article.news: 7.7% user + 6% kernel / faults: 56007 minor 2446 major
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 13% 32638/com.android.quicksearchbox: 9.4% user + 3.8% kernel / faults: 48999 minor 1540 major
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 11% (CPU的使用率)1480/com.xxxx.moblie: 5.2%(用户态的使用率) user + (内核态的使用率) 6.3% kernel / faults: 76401 minor 2422 major
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 8.2% 21000/kworker/u16:12: 0% user + 8.2% kernel
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 0.8% 724/mtd: 0% user + 0.8% kernel / faults: 1561 minor 9 major
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 8% 29704/kworker/u16:8: 0% user + 8% kernel
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 7.9% 24391/kworker/u16:18: 0% user + 7.9% kernel
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 7.1% 30656/kworker/u16:14: 0% user + 7.1% kernel
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 7.1% 9998/kworker/u16:4: 0% user + 7.1% kernel
通过上面所提供的案例我们可以分析出以下几点:
ANR发生的位置是:com.xxxx.moblie/.ui.MainActivity com.xxxx.moblie 占用了11%的CPU,CPU的使用率并不是很高,基本可以排除CPU负载的原因 Reason提示我们是输入分发超时导致的ANR 通过上面几点我们虽然排除了CPU过度负载的可能,但我们并不能准确定位出ANR的确切位置,要想准确定位出ANR发生的确切位置,就要借助系统为了解决ANR问题而提供的终极大杀器——traces.txt文件了。 找到anr目录下的trace.txt trace:
Cmd line:com.xxxx.moblie
"main" prio=5 tid=1 Runnable
| group="main" sCount=0 dsCount=0 obj=0x73bcc7d0 self=0x7f20814c00
| sysTid=20176 nice=-10 cgrp=default sched=0/0 handle=0x7f251349b0
| state=R schedstat=( 0 0 0 ) utm=12 stm=3 core=5 HZ=100
| stack=0x7fdb75e000-0x7fdb760000 stackSize=8MB
| held mutexes= "mutator lock"(shared held)
// java 堆栈调用信息,可以查看调用的关系,定位到具体位置
at ttt.push.InterceptorProxy.addMiuiApplication(InterceptorProxy.java:77)
at ttt.push.InterceptorProxy.create(InterceptorProxy.java:59)
at android.app.Activity.onCreate(Activity.java:1041)
at miui.app.Activity.onCreate(SourceFile:47)
at com.xxxx.moblie.ui.b.onCreate(SourceFile:172)
at com.xxxx.moblie.ui.MainActivity.onCreate(SourceFile:68)
at android.app.Activity.performCreate(Activity.java:7050)
at android.app.Instrumentation.callActivityOnCreate(Instrumentation.java:1214)
at android.app.ActivityThread.performLaunchActivity(ActivityThread.java:2807)
at android.app.ActivityThread.handleLaunchActivity(ActivityThread.java:2929)
at android.app.ActivityThread.-wrap11(ActivityThread.java:-1)
at android.app.ActivityThread$H.handleMessage(ActivityThread.java:1618)
at android.os.Handler.dispatchMessage(Handler.java:105)
at android.os.Looper.loop(Looper.java:171)
at android.app.ActivityThread.main(ActivityThread.java:6699)
at java.lang.reflect.Method.invoke(Native method)
at com.android.internal.os.Zygote$MethodAndArgsCaller.run(Zygote.java:246)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:783)
这里详细解析一下traces.txt里面的一些字段,看看它到底能给我们提供什么信息.
main:main标识是主线程,如果是线程,那么命名成“Thread-X”的格式,x表示线程id,逐步递增。 prio:线程优先级,默认是5 tid:tid不是线程的id,是线程唯一标识ID group:是线程组名称 sCount:该线程被挂起的次数 dsCount:是线程被调试器挂起的次数 obj:对象地址 self:该线程Native的地址 sysTid:是线程号(主线程的线程号和进程号相同) nice:是线程的调度优先级 sched:分别标志了线程的调度策略和优先级 cgrp:调度归属组 handle:线程处理函数的地址。 state:是调度状态 schedstat:从 /proc/[pid]/task/[tid]/schedstat读出,三个值分别表示线程在cpu上执行的时间、线程的等待时间和线程执行的时间片长度,不支持这项信息的三个值都是0; utm:是线程用户态下使用的时间值(单位是jiffies) stm:是内核态下的调度时间值 core:是最后执行这个线程的cpu核的序号。 Java的堆栈信息是我们最关心的,它能够定位到具体位置。从上面的traces,我们可以判断ttt.push.InterceptorProxy.addMiuiApplicationInterceptorProxy.java:77 导致了com.xxxx.moblie发生了ANR。这时候可以对着源码查看,找到出问题,并且解决它。
综合考虑系统侧原因 很多开发者认为,ANR就是耗时操作导致,全部是app应用层的问题。实际上,线上环境大部分ANR由系统原因导致。
应用层导致ANR(耗时操作)
函数阻塞:如死循环、主线程IO、处理大数据 锁出错:主线程等待子线程的锁 内存紧张:系统分配给一个应用的内存是有上限的,长期处于内存紧张,会导致频繁内存交换,进而导致应用的一些操作超时 系统导致ANR
CPU被抢占:一般来说,前台在玩游戏,可能会导致你的后台广播被抢占CPU 系统服务无法及时响应:比如获取系统联系人等,系统的服务都是Binder机制,服务能力也是有限的,有可能系统服务长时间不响应导致ANR 其他应用占用的大量内存 日志案例分析 下列案例信息来自vivo团队 ,原文:
干货:ANR日志分析全面解析
堆栈信息:主线程未卡死 "main" prio=5 tid=1 Native
| group="main" sCount=1 dsCount=0 flags=1 obj=0x74b38080 self=0x7ad9014c00
| sysTid=23081 nice=0 cgrp=default sched=0/0 handle=0x7b5fdc5548
| state=S schedstat=( 284838633 166738594 505 ) utm=21 stm=7 core=1 HZ=100
| stack=0x7fc95da000-0x7fc95dc000 stackSize=8MB
| held mutexes=
kernel: __switch_to+0xb0/0xbc
kernel: SyS_epoll_wait+0x288/0x364
kernel: SyS_epoll_pwait+0xb0/0x124
kernel: cpu_switch_to+0x38c/0x2258
native: #00 pc 000000000007cd8c /system/lib64/libc.so (__epoll_pwait+8)
native: #01 pc 0000000000014d48 /system/lib64/libutils.so (android::Looper::pollInner(int)+148)
native: #02 pc 0000000000014c18 /system/lib64/libutils.so (android::Looper::pollOnce(int, int*, int*, void**)+60)
native: #03 pc 00000000001275f4 /system/lib64/libandroid_runtime.so (android::android_os_MessageQueue_nativePollOnce(_JNIEnv*, _jobject*, long, int)+44)
at android.os.MessageQueue.nativePollOnce(Native method)
at android.os.MessageQueue.next(MessageQueue.java:330)
at android.os.Looper.loop(Looper.java:169)
at android.app.ActivityThread.main(ActivityThread.java:7073)
at java.lang.reflect.Method.invoke(Native method)
at com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:536)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:876)
上述主线程堆栈就是一个很正常的空闲堆栈,表明 主线程正在等待新的消息 。可能为CPU抢占或内存问题导致的,等抓取trace时已经恢复正常。
堆栈信息:主线程执行耗时操作 "main" prio=5 tid=1 Runnable
| group="main" sCount=0 dsCount=0 flags=0 obj=0x72deb848 self=0x7748c10800
| sysTid=8968 nice=-10 cgrp=default sched=0/0 handle=0x77cfa75ed0
| state=R schedstat=( 24783612979 48520902 756 ) utm=2473 stm=5 core=5 HZ=100
| stack=0x7fce68b000-0x7fce68d000 stackSize=8192KB
| held mutexes= "mutator lock"(shared held)
at com.example.test.MainActivity$onCreate$2.onClick(MainActivity.kt:20)——关键行!!!
at android.view.View.performClick(View.java:7187)
at android.view.View.performClickInternal(View.java:7164)
at android.view.View.access$3500(View.java:813)
at android.view.View$PerformClick.run(View.java:27640)
at android.os.Handler.handleCallback(Handler.java:883)
at android.os.Handler.dispatchMessage(Handler.java:100)
at android.os.Looper.loop(Looper.java:230)
at android.app.ActivityThread.main(ActivityThread.java:7725)
at java.lang.reflect.Method.invoke(Native method)
at com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:526)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:1034)
上述日志表明,主线程正处于执行状态,看堆栈信息可知不是处于空闲状态,发生ANR是因为一处click监听函数里执行了耗时操作。
堆栈信息:主线程被锁阻塞 "main" prio=5 tid=1 Blocked
| group="main" sCount=1 dsCount=0 flags=1 obj=0x72deb848 self=0x7748c10800
| sysTid=22838 nice=-10 cgrp=default sched=0/0 handle=0x77cfa75ed0
| state=S schedstat=( 390366023 28399376 279 ) utm=34 stm=5 core=1 HZ=100
| stack=0x7fce68b000-0x7fce68d000 stackSize=8192KB
| held mutexes=
at com.example.test.MainActivity$onCreate$1.onClick(MainActivity.kt:15)
- waiting to lock <0x01aed1da> (a java.lang.Object) held by thread 3 ——————关键行!!!
at android.view.View.performClick(View.java:7187)
at android.view.View.performClickInternal(View.java:7164)
at android.view.View.access$3500(View.java:813)
at android.view.View$PerformClick.run(View.java:27640)
at android.os.Handler.handleCallback(Handler.java:883)
at android.os.Handler.dispatchMessage(Handler.java:100)
at android.os.Looper.loop(Looper.java:230)
at android.app.ActivityThread.main(ActivityThread.java:7725)
at java.lang.reflect.Method.invoke(Native method)
at com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:526)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:1034)
........省略N行.....
"WQW TEST" prio=5 tid=3 TimeWating
| group="main" sCount=1 dsCount=0 flags=1 obj=0x12c44230 self=0x772f0ec000
| sysTid=22938 nice=0 cgrp=default sched=0/0 handle=0x77391fbd50
| state=S schedstat=( 274896 0 1 ) utm=0 stm=0 core=1 HZ=100
| stack=0x77390f9000-0x77390fb000 stackSize=1039KB
| held mutexes=
at java.lang.Thread.sleep(Native method)
- sleeping on <0x043831a6> (a java.lang.Object)
at java.lang.Thread.sleep(Thread.java:440)
- locked <0x043831a6> (a java.lang.Object)
at java.lang.Thread.sleep(Thread.java:356)
at com.example.test.MainActivity$onCreate$2$thread$1.run(MainActivity.kt:22)
- locked <0x01aed1da> (a java.lang.Object)————————————————————关键行!!!
at java.lang.Thread.run(Thread.java:919)
这是一个典型的主线程被锁阻塞的例子;
其中等待的锁是 <0x01aed1da> ,这个锁的持有者是线程 3。进一步搜索 “tid=3” 找到线程3, 发现它正在TimeWating。
那么ANR的原因找到了:线程3持有了一把锁,并且自身长时间不释放,主线程等待这把锁发生超时。在线上环境中,常见因锁而ANR的场景是SharePreference写入。比如两个线程都在等待另一个写入完成释放自己需要的锁,导致死锁。
CPU被抢占 CPU usage from 0ms to 10625ms later (2020-03-09 14:38:31.633 to 2020-03-09 14:38:42.257):
543% 2045/com.alibaba.android.rimet: 54% user + 89% kernel / faults: 4608 minor 1 major ————关键行!!!
99% 674/android.hardware.camera.provider@2.4-service: 81% user + 18% kernel / faults: 403 minor
24% 32589/com.wang.test: 22% user + 1.4% kernel / faults: 7432 minor 1 major
........省略N行.....
如上日志,第二行是钉钉的进程,占据CPU高达543%,抢占了大部分CPU资源,因而导致发生ANR。
内存紧张导致ANR 如果有一份日志,CPU和堆栈都很正常(不贴出来了),仍旧发生ANR,考虑是内存紧张。
从CPU第一行信息可以发现,ANR的时间点是2020-10-31
22:38:58.468—CPU usage from 0ms to 21752ms later (2020-10-31 22:38:58.468 to 2020-10-31 22:39:20.220)
接着去logcat里搜索am_meminfo, 这个没有搜索到。再次搜索onTrimMemory,果然发现了很多条记录;
10-31 22:37:19.749 20733 20733 E Runtime : onTrimMemory level:80,pid:com.xxx.xxx:Launcher0
10-31 22:37:33.458 20733 20733 E Runtime : onTrimMemory level:80,pid:com.xxx.xxx:Launcher0
10-31 22:38:00.153 20733 20733 E Runtime : onTrimMemory level:80,pid:com.xxx.xxx:Launcher0
10-31 22:38:58.731 20733 20733 E Runtime : onTrimMemory level:80,pid:com.xxx.xxx:Launcher0
10-31 22:39:02.816 20733 20733 E Runtime : onTrimMemory level:80,pid:com.xxx.xxx:Launcher0
可以看出,在发生ANR的时间点前后,内存都处于紧张状态,level等级是80,查看Android API 文档;
可知80这个等级是很严重的,应用马上就要被杀死,被杀死的这个应用从名字可以看出来是桌面,连桌面都快要被杀死,那普通应用能好到哪里去呢?
一般来说,发生内存紧张,会导致多个应用发生ANR,所以在日志中如果发现有多个应用一起ANR了,可以初步判定,此ANR与你的应用无关。
系统服务超时导致ANR 系统服务超时一般会包含BinderProxy.transactNative关键字,请看如下日志:
"main" prio=5 tid=1 Native
| group="main" sCount=1 dsCount=0 flags=1 obj=0x727851e8 self=0x78d7060e00
| sysTid=4894 nice=0 cgrp=default sched=0/0 handle=0x795cc1e9a8
| state=S schedstat=( 8292806752 1621087524 7167 ) utm=707 stm=122 core=5 HZ=100
| stack=0x7febb64000-0x7febb66000 stackSize=8MB
| held mutexes=
kernel: __switch_to+0x90/0xc4
kernel: binder_thread_read+0xbd8/0x144c
kernel: binder_ioctl_write_read.constprop.58+0x20c/0x348
kernel: binder_ioctl+0x5d4/0x88c
kernel: do_vfs_ioctl+0xb8/0xb1c
kernel: SyS_ioctl+0x84/0x98
kernel: cpu_switch_to+0x34c/0x22c0
native: #00 pc 000000000007a2ac /system/lib64/libc.so (__ioctl+4)
native: #01 pc 00000000000276ec /system/lib64/libc.so (ioctl+132)
native: #02 pc 00000000000557d4 /system/lib64/libbinder.so (android::IPCThreadState::talkWithDriver(bool)+252)
native: #03 pc 0000000000056494 /system/lib64/libbinder.so (android::IPCThreadState::waitForResponse(android::Parcel*, int*)+60)
native: #04 pc 00000000000562d0 /system/lib64/libbinder.so (android::IPCThreadState::transact(int, unsigned int, android::Parcel const&, android::Parcel*, unsigned int)+216)
native: #05 pc 000000000004ce1c /system/lib64/libbinder.so (android::BpBinder::transact(unsigned int, android::Parcel const&, android::Parcel*, unsigned int)+72)
native: #06 pc 00000000001281c8 /system/lib64/libandroid_runtime.so (???)
native: #07 pc 0000000000947ed4 /system/framework/arm64/boot-framework.oat (Java_android_os_BinderProxy_transactNative__ILandroid_os_Parcel_2Landroid_os_Parcel_2I+196)
at android.os.BinderProxy.transactNative(Native method) ————————————————关键行!!!
at android.os.BinderProxy.transact(Binder.java:804)
at android.net.IConnectivityManager$Stub$Proxy.getActiveNetworkInfo(IConnectivityManager.java:1204)—关键行!
at android.net.ConnectivityManager.getActiveNetworkInfo(ConnectivityManager.java:800)
at com.xiaomi.NetworkUtils.getNetworkInfo(NetworkUtils.java:2)
at com.xiaomi.frameworkbase.utils.NetworkUtils.getNetWorkType(NetworkUtils.java:1)
at com.xiaomi.frameworkbase.utils.NetworkUtils.isWifiConnected(NetworkUtils.java:1)
从堆栈可以看出获取网络信息发生了ANR: getActiveNetworkInfo
前文有讲过:系统的服务都是Binder机制(16个线程),服务能力也是有限的,有可能系统服务长时间不响应导致ANR。如果其他应用占用了所有Binder线程,那么当前应用只能等待。
可进一步搜索:blockUntilThreadAvailable关键字:
at android.os.Binder.blockUntilThreadAvailable(Native method)
如果有发现某个线程的堆栈,包含此字样,可进一步看其堆栈,确定是调用了什么系统服务。此类ANR也是属于系统环境的问题,如果某类型机器上频繁发生此问题,应用层可以考虑规避策略。
冷启动概念和流程 在 Android 应用开发中,冷启动(Cold Start) 是指应用从完全关闭状态(进程不存在)到用户看到第一个界面(通常是 Launcher 或 SplashActivity)的启动过程。
冷启动是用户感知应用性能的关键环节之一,如果冷启动时间过长,会导致用户流失或体验下降。一般的测试流程里,将手指点击图标后,应用首帧显示到屏幕上的时长作为指标,这个比较符合用户的真实体验。
因此,冷启动优化是 Android 性能优化的重要部分。以下是常见的冷启动优化手段,按优化方向分类进行详细说明。
简单来说,冷启动可以分为以下几个阶段:
应用进程创建,系统接收到启动应用的请求后,首先会创建应用的进程(Zygote 进程 fork 出新进程)。应用进程创建后,会初始化 Application 对象,执行 Application.onCreate() 方法。如果在 Application 的 onCreate 中执行了耗时操作(如初始化第三方库、加载大量数据等),会导致冷启动时间变长。然后系统会创建目标 Activity 的实例,并调用其生命周期方法(如 onCreate()、onStart()、onResume())。然后是Activity 的布局加载、视图测量与绘制(Measure、Layout、Draw)。
详细流程可以看这一篇:
Android 冷启动流程分析
优化手段 分析trace文件 首先,采集trace性能文件,查看主要耗时在哪里。
具体的分析流程可以参考:
Android trace文件分析
减少 Application.onCreate() 和 Activity.onCreate() 中的工作量 Application 是应用的入口点,很多开发者会在 Application.onCreate() 中初始化各种第三方库、框架或服务。如果这些初始化操作耗时较长,会直接影响冷启动时间。有些第三方库或服务并不需要在应用启动时立即初始化(如统计 SDK、日志 SDK、推送 SDK 等),可以在应用启动后,真正需要使用这些库时再进行初始化。也可以将非关键的初始化操作移到后台线程中执行。
异步加载,将数据加载、图片处理、网络请求等耗时操作放到后台线程中执行,避免阻塞主线程。可以使用 Kotlin Coroutines、RxJava 或 Executor 来处理异步任务。
优化数据加载,如果需要从本地存储或网络加载数据,只加载初始屏幕所需的数据,而不是一次性加载所有数据。可以考虑分页加载或按需加载。
优化布局和视图层次结构 减少布局的嵌套层级。过深的视图层次会增加测量和绘制时间。
对于简单的线性布局,LinearLayout 和 FrameLayout 通常比 ConstraintLayout 更快。对于复杂布局,ConstraintLayout 可以帮助减少嵌套,从而提升性能。
对于不经常显示或在启动时不需要显示的 UI 部分,可以使用 ViewStub 作为占位符,在需要时再动态加载。这可以减少初始布局的膨胀时间。
同时,减少不必要的背景、重叠视图等,这些都会增加 GPU 的绘制负担。
利用 Android 平台提供的优化工具 Baseline Profiles (基线配置文件),这是 Google 推荐的重要优化手段。Baseline Profiles 可以在首次启动时将代码执行速度提高 30%,使应用启动、屏幕导航、内容滚动等用户交互更加流畅。它通过在编译时优化 DEX 布局来提高启动速度。 App Startup 库,这个库允许你定义一个内容提供者来统一初始化多个组件,而不是为每个组件都定义一个单独的内容提供者,从而显著提高应用启动时间。 R8 优化编译器,启用 R8 的完整模式可以进行更激进的代码优化,包括代码缩减、资源优化、DEX 布局优化等,从而减少应用大小并提高运行时性能,包括启动速度。 图片和资源优化 确保图片大小合适,并进行有效压缩。对于显示在 ImageView 中的图片,将其尺寸调整为与 ImageView 匹配,避免加载过大的图片。
考虑使用 WebP 等高效的图片格式。 使用 Glide、Picasso 等图片加载库在后台线程加载和缓存图片。 如果应用包含大量功能,可以考虑将其拆分为动态模块,按需下载和安装,从而减小初始安装包大小,加快启动速度。 其他技巧 闪屏页优化: 如果使用 Splash 闪屏页,可以在闪屏页显示期间进行一些必要的初始化工作,从而充分利用用户等待的时间。如果应用中注册了多个 ContentProvider,系统会在应用启动时初始化这些 ContentProvider,可能导致冷启动时间变长。可以保留必要的 ContentProvider,移除不必要的 ContentProvider。 同样的,如果应用注册了大量的广播接收器(尤其是静态注册的广播接收器),系统会在应用启动时加载这些接收器,可能导致冷启动时间变长。尽量使用动态注册的广播接收器,避免静态注册。只注册必要的广播接收器,移除不必要的广播接收器。 在冷启动时,如果频繁调用系统服务(如 LocationManager、SensorManager 等),可能会导致系统资源竞争,增加冷启动时间。可以延迟调用系统服务,避免在 Application.onCreate() 或 Activity.onCreate() 中立即调用。或者使用缓存机制,避免重复调用系统服务。 需要注意的是
冷启动优化不能以牺牲功能为代价。例如,延迟初始化某些 SDK 可能会导致功能不可用,需要根据实际场景权衡。 还有,冷启动时间可能因设备性能、系统版本等因素而异。建议在多种设备上进行测试,确保优化效果。 冷启动优化的最终目标是提升用户体验。可以通过启动主题、加载动画等方式掩盖部分初始化时间,提高用户感知的流畅性。 Pagination © 2024. All rights reserved. LICENSE | NOTICE | CHANGELOG
Powered by Hydejack v9.2.1