在当今的物联网(IoT)时代,我们的智能手机早已不仅仅是通讯工具,更是连接和控制身边智能硬件的中枢 。无论是追踪你运动数据的智能手环,监测你睡眠质量的智能床垫,还是让你告别钥匙的智能门锁,它们与 Android 设备之间高效、可靠的通信桥梁,正是低功耗蓝牙 (Bluetooth Low Energy, BLE) 技术。
什么是 BLE?
BLE 低功耗蓝牙 (通常也被称为 Bluetooth Smart)是专为物联网应用设计的无线通信协议。它继承了传统蓝牙的可靠性,但在功耗上做到了极致优化 。不同于传统蓝牙需要持续、高带宽的数据流,BLE 的核心在于快速连接、发送少量数据后迅速休眠,这使得它成为电池供电的小型设备的首选。对于 Android 开发者来说,熟练掌握如何利用 Android 系统提供的 API 与这些 BLE 设备进行交互,是构建现代移动应用的关键技能。
丰富的应用场景
BLE 连接技术已经渗透到我们生活的方方面面,带来了无限的创新可能:
健康与运动追踪: 智能手表、心率带、运动传感器等将实时数据传输到你的 Android App,进行分析和可视化。智能家居与控制: 通过手机控制智能灯泡、温度计、门锁、以及各种传感器。资产定位与寻物: 利用 iBeacon 或 Eddystone 等技术实现室内导航、商家推送,以及通过小巧的蓝牙标签寻找丢失的物品。本篇博客将介绍Android设备和BLE设备通信的几个关键流程,扫描 、连接 、发现服务 ,并最终实现与 BLE 设备的高效数据交互 。
核心概念先行:
手机 (Central / 中心设备): 主动扫描并连接其他设备的设备,在BLE协议中称为 中心设备 。手机、电脑等通常扮演这个角色。 BLE设备 (Peripheral / 外围设备): 被动广播自身信息,等待被连接的设备,称为外围设备 。如智能手环、心率带、防丢器等。 GATT (Generic Attribute Profile): 这是连接建立后,双方通信所遵循的核心协议。它定义了一个 服务-特征值 的数据结构。服务: 一个独立的功能模块。例如,一个“心率服务”。 特征: 服务下的具体数据点。它是实际读写操作的对象。例如,在“心率服务”下,会有 “心率测量特征” (用于读取心率数据)和 “心率位置特征” (用于写入或通知佩戴位置)。 属性: 特征、服务等都被称为属性,每个属性都有一个唯一的标识符。 1. 寻找设备 广播与扫描 这个阶段的目标是让手机发现BLE设备的存在
1.1 外围设备广播 外围设备会周期性地(例如每秒100次)向周围环境 发送广播数据包 (Advertising Packets)。这些数据包包含少量信息,这就是广播报文。
广播报文内容:
设备地址: 类似MAC地址,是设备的唯一标识符。 设备名称: 可读的名称,如 “MI_Band”。 发射功率: 用于粗略的距离估算。 服务UUIDs: 设备所支持的主要服务的列表。这是手机判断设备类型的关键(例如,看到“心率服务”的UUID,就知道这是个心率设备)。 制造商特定数据: 设备厂商可以自定义放入一些数据,如电池电量、硬件版本等。 1.2 中心设备扫描 手机(通常作为中央设备 Central)处于扫描 状态,App通过操作系统提供的蓝牙API启动蓝牙扫描,手机的蓝牙芯片会监听来自周围 BLE 设备的广播数据包,在同样的广播通道上监听这些广播报文。
手机收到数据包后,会将其解析并回调 给应用程序,提取出上述广播的信息,并在App的扫描结果列表中显示出来(例如,显示“发现设备:MI_Band”)。
此时,手机知道了BLE设备的存在和基本信息,但双方还未建立正式连接。这是设备间建立联系的第一步。
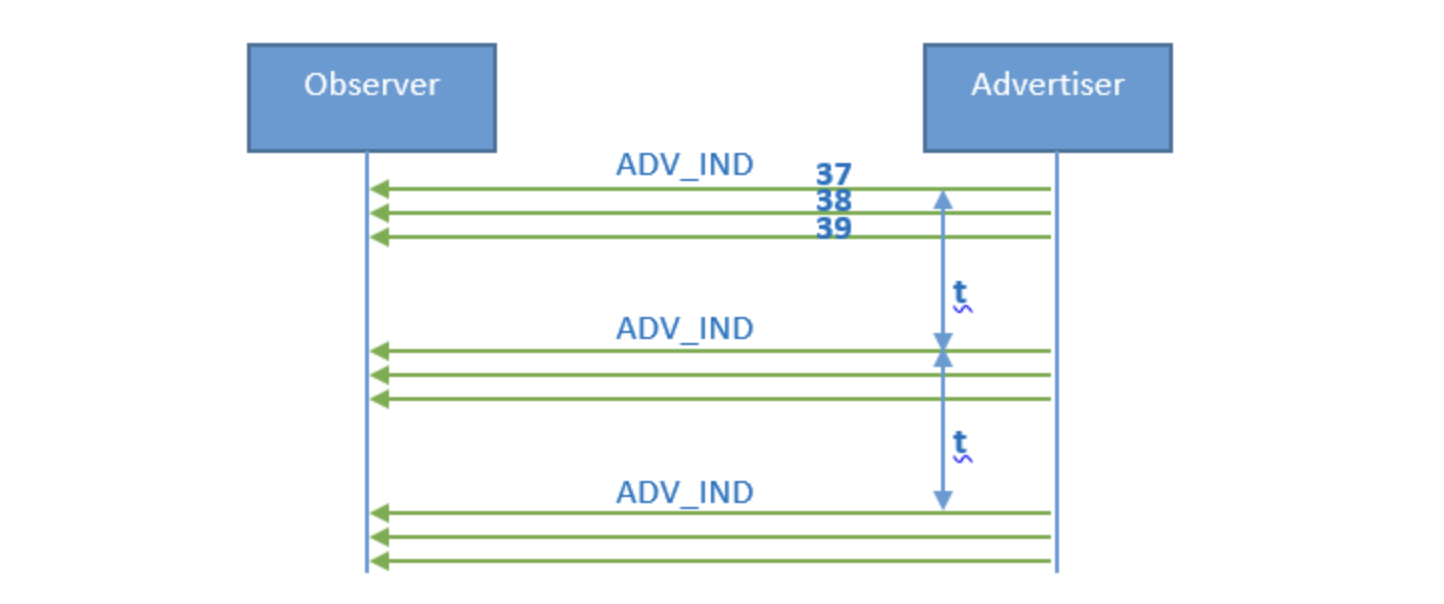
1.3 广播细节 在 手机(Observer) 跟 设备B(Advertiser) 建立连接之前,设备B需要先进行广播,即设备B不断发送如下广播信号,t 为广播间隔。
每发送一次广播包,我们称其为一次广播事件(advertising event),因此t也称为广播事件间隔。广播事件是有一个持续时间的,蓝牙芯片只有在广播事件期间才打开射频模块,这个时候功耗比较高,其余时间蓝牙芯片都处于idle状态,因此平均功耗非常低,以Nordic nRF52810为例,每1秒钟发一次广播,平均功耗不到11uA。
每一个广播事件包含三个广播包,即分别在37/38/39三个射频通道上同时广播相同的信息,即真正的广播事件是下面这个样子的。
设备B不断发送广播信号给手机(Observer),如果手机不开启扫描窗口,手机是收不到设备B的广播的,如下图所示,不仅手机要开启射频接收窗口,而且 只有手机的射频接收窗口跟广播发送的发射窗口匹配成功 ,而且 广播射频通道和手机扫描射频通道是同一个通道 ,手机才能收到设备B的广播信号。
也就是说,如果设备B在37通道发送广播包,而手机在扫描38通道,那么即使他们俩的射频窗口匹配,两者也是无法进行通信的。
由于这种匹配成功是一个概率事件,因此手机扫到设备B也是一个概率事件,也就是说,手机有时会很快扫到设备B,比如只需要一个广播事件,手机有时又会很慢才能扫到设备B,比如需要10个广播事件甚至更多。
避免信道干扰 为了避免与其他无线设备(主要是Wi-Fi)的干扰,BLE广播事件的三个广播包分别在 37/38/39 三个射频通道上广播,这三个通道分别避开了Wi-Fi信道 1/11/6 的下边缘和上边缘。
频率冲突:Wi-Fi主要工作在2.4GHz频段,而这个频段也正是蓝牙(包括BLE)的工作频段。Wi-Fi将其频段划分为多个信道,例如常用的1, 6, 11信道。Wi-Fi信道1 的中心频率是 2.412 GHz Wi-Fi信道6 的中心频率是 2.437 GHz Wi-Fi信道11 的中心频率是 2.462 GHz BLE信道的频率:BLE信道37: 2.402 GHz BLE信道38: 2.426 GHz BLE信道39: 2.480 GHz 你可能会注意到,BLE总共有40个物理信道(0-39)。37、38、39用于广播,那么剩下的0-36信道用于什么呢?
数据信道:在BLE连接建立之后,通信双方会使用 自适应跳频技术 ,在0-36这37个信道上进行数据传输。 跳频的意义:连接后使用跳频,是为了在数据传输阶段也能 动态地避开瞬时干扰 。主从设备会共同协商,跳过那些信噪比差、干扰大的信道,从而在连接状态下也能维持一个稳定、高效的数据链路。 2. 建立连接 当用户在手机 App 上选择一个设备后,就会开始连接过程。
手机请求:
动作: 手机 App 调用系统 API,向选定的 BLE 设备发送连接请求 (Connection Request)。信息: 请求中会包含连接参数 ,如连接间隔(Connection Interval)、从机延迟(Slave Latency)和超时时间(Supervision Timeout),这些参数定义了连接后数据交换的频率和容错能力。即双方会协商一套通信参数,如连接间隔(设备多久通信一次,影响功耗和响应速度)、从机延迟等。BLE 设备响应:
动作: BLE 设备从广播状态切换到连接 状态,并接受 连接请求。结果: 双方建立了一个双向的、独占的 连接。从此刻起,设备停止广播,并且只有这个手机能与它通信。双方进入链路层 (Link Layer)的数据交换阶段。在连接状态下,通信会从之前的3个广播通道切换到37个数据通道,并通过一种自适应跳频技术来避免无线干扰,保证通信稳定。3. 服务发现 连接建立后,手机需要知道设备上有什么功能。
BLE 使用 GATT (Generic Attribute Profile) 规范来组织数据。数据被组织成服务和特性,每个特性都有一个 UUID 标识。
手机作为 GATT 客户端 ,会自动向BLE设备发送一个 服务发现请求 。
BLE设备会将其内部的所有服务,以及每个服务下的所有特征,像一个文件目录一样完整地返回给手机。
手机端的蓝牙协议栈会解析这个“目录”,并建立一个本地的GATT数据库。手机 App 知道了设备的全部功能结构(UUID 和属性),就可以通过查询这个数据库来知道可以对设备进行哪些操作。
4. 配对绑定 安全校验和配对(Bonding/Pairing) 在手机和 BLE 设备之间的通信中不是必须的 。是否需要配对,完全取决于 BLE 设备上的特性(Characteristic) 的配置。
很多 BLE 服务中的特性(例如,电池电量、设备名称、简单的通知开关)被配置为可以进行未加密或无需身份验证的读取和写入操作。对于这些特性,手机可以直接在连接建立后进行服务发现,然后直接进行读写,不需要经过配对(Pairing)或绑定(Bonding)的复杂流程。
配对 是用于建立加密和身份验证的链路,它在以下情况是必须的:
敏感数据传输: 当传输的数据具有隐私性或敏感性时(如医疗数据、GPS 位置、个人运动记录)。 控制关键功能: 当手机需要控制设备的关键、有影响的功能时(如智能门锁的开关、支付授权、修改固件设置)。 需要用户身份确认: 设备的某个特性被配置为需要加密或身份验证权限才能访问。当手机尝试读写这个受保护的特性时,BLE 栈(Stack)会强制触发配对流程。 配对/绑定 流程 配对和绑定是为了建立信任 关系,并交换安全密钥 ,以便在后续连接中能进行加密通信 。安全性和配对通常发生在服务发现之后,或在第一次读写受保护的特性时触发。如访问加密、身份验证的特性时,系统会自动触发配对流程。
通信双方协商安全级别和配对方式(如 Just Works 、Passkey Entry 、Numeric Comparison 等)。配对过程中,手机可能会弹出配对请求框,显示一个随机生成的6位数字码。用户需要在设备上确认这个数字码,或者简单地点击 “配对” 按钮。然后双方会交换密钥,建立信任关系。
配对成功后,双方交换 长期密钥 (LTK) ,并将其存储起来(称为绑定 )。绑定后,后续连接可以直接使用 LTK 建立加密链路,无需重复配对。
5. 通信 - 基于GATT的数据交互 所有通信都是通过 对特征的读写 操作完成的。特征有不同的属性来控制其行为:
Read: 手机可以主动读取特征的值。例如,读取一次当前的电池电量 Write: 手机可以向特征写入数据(控制设备)。例如,向设备发送一个“寻找手环”的命令,手环收到之后就会震动 Notify / Indicate: 这是BLE通信中最重要、最节能的模式。设备可以在数据变化时,主动向手机推送数据,而手机无需不停地询问。Notify 通知: 不可靠通知,手机不回复确认。 Indicate 指示: 可靠通知,设备会等待手机的确认后再发送下一条。 这个流程是所有基于 BLE 的应用通信的基础。在 Android 平台,可以在 Android 的 BluetoothLeScanner 类中找到扫描相关的 API,在 BluetoothGatt 类中找到连接、服务发现和数据读写相关的 API。
如何传输大段数据 低功耗蓝牙 (BLE) 在设计之初是为了低功耗和传输少量 数据而优化的。因此,它在传输大段数据时会有一些限制和特定的处理方式。
BLE 数据传输基于 GATT (Generic Attribute Profile) ,数据是封装在 ATT (Attribute Protocol) 数据包中传输的。
ATT 最大传输单元 (ATT_MTU) 是应用层一次可以发送或接收的最大数据包大小。
在 BLE 4.0/4.1 中,默认的 ATT_MTU 是 23 字节。这意味着,在一个 Notification、Indication 或 Write 请求中,用户数据(特征值)部分最大只有 20 字节(因为 3 字节用于 ATT 头部, 23 - 3 = 20)。 在 BLE 4.2 及更高版本中,设备可以协商更大的 ATT_MTU(例如 250 字节以上),这显著提高了单次传输的效率。 物理层最大传输单元 (PDU) 的限制比 ATT_MTU 更底层。在 BLE 5.0 中,数据包的 PDU 最大可以达到 257 字节。
分包和重组 & 缩短传输间隔 由于单次 ATT 传输的有效载荷(Payload)有限(通常至少 20 字节,即使协商了更大的 MTU,也通常小于 512 字节),传输大段数据(如文件、图片等)就必须依赖应用层 进行分包和重组 。
a. 应用层分包 (Segmentation) 和重组 (Reassembly) 发送端分包 将完整的原始数据(例如 1MB 的文件)切分成多个小的分包。每个分包的大小取决于当前连接协商的 ATT_MTU 所允许的最大特征值大小。
1. 拆分小段数据 每一段数据包 添加头部 每个分包都需要添加一个自定义的应用层头部 (Header)。这个头部通常包含。
序号/索引 (Sequence Number) 用于接收端按正确顺序重组数据。总包数 (Total Packets) 或 数据长度 (Total Length) 帮助接收端判断是否接收完整。校验和 (Checksum) :用于验证分包数据的完整性。2. 逐包发送 发送端通过 BLE 的 Notification 或 Write Without Response (取决于你的设计)将这些分包一个接一个地发送出去。
3. 接收端重组 接收端根据每个分包中的 序号 ,将收到的数据段缓存并按照正确的顺序拼接起来,直到所有分包都收到,形成完整的原始数据。再做一次 完整性检查 通过头部中的 总包数/长度 和 校验和 来验证接收到的完整数据的正确性。
b. 提高传输效率的关键技术 为了加快传输速度,应该尽可能利用 BLE 协议栈提供的优化:
协商更大的 MTU :在连接建立后,立即 进行 MTU 协商(例如 Android/iOS 系统会自动进行,或者应用层手动触发)。将 MTU 增大到 256 甚至 517 字节,可以成倍减少分包的数量和 ATT 事务的次数。数据长度扩展 (DLE) :在 BLE 4.2 及更高版本中引入,它允许将物理层 PDU 的有效载荷从默认的 27 字节增加到 257 字节。这直接支持了 MTU 扩展。使用 Write Without Response 或 Notification :这两种方法是非确认机制,发送端发送数据后不需要等待接收端的确认 (ACK),因此可以连续快速发送。这是传输大段数据的首选方式,但需要应用层自行处理丢包或错误(通常通过重传机制)。优化连接间隔 (Connection Interval) :连接间隔越短,收发数据的频率越高,吞吐量也越大。但要注意,极短的连接间隔会增加功耗。你需要找到一个吞吐量和功耗之间的平衡点。Android项目简单实践 1.扫描设备 连接BLE设备,首先需要扫描。Android SDK中使用 BluetoothLeScanner 对象来执行扫描的动作:
private BluetoothLeScanner bluetoothLeScanner ;
bluetoothLeScanner = bluetoothAdapter . getBluetoothLeScanner ();
bluetoothLeScanner . startScan ( scanCallback );
由于扫描是一个异步的过程,所以这里需要传入一个回调接口,我们在回调接口去获取扫描的结果:
public ScanCallback scanCallback = new ScanCallback () {
@Override
public void onScanResult ( int callbackType , ScanResult result ) {
super . onScanResult ( callbackType , result );
ScanRecord record = result . getScanRecord ();
BluetoothDevice device = result . getDevice ();
String deviceName = record . getDeviceName ();
Log . d ( TAG , "record name:" + deviceName );
Log . d ( TAG , "ServiceUuids:" + record . getServiceUuids ());
if ( TextUtils . isEmpty ( deviceName )) {
return ;
}
if ( deviceName . startsWith ( "XX" )) { //这里我们可以找出设备名以XX开头的BLE设备
byte [] bytes = record . getBytes (); //这里可以获取整个广播的完整数据,包括协议头等
for ( int i = 0 ; i < bytes . length ; i ++) {
Log . d ( TAG , "[" + i + "]:" + bytes [ i ]);
}
bluetoothLeScanner . stopScan ( scanCallback ); //需要停止扫描
}
}
};
2.连接设备 在找到了“XX”名称的设备后,我们就可以发起GATT协议的连接了:
/**
*
* @param autoConnect Whether to directly connect to the remote device (false) or to automatically connect as soon as the remote device becomes available (true).
* @param callback GATT callback handler that will receive asynchronous callbacks.
*/
device . connectGatt ( context , false , gattCallback );
第二个参数 autoConnect 如果是false代表仅发起本次连接,如果连接不上则会反馈连接失败;如果是true则表示只要这个远程的设备可用,那么底层协议栈就会自动去连接,并且第一次连接不上,也会继续去连接。
第三个参数 callback 是一个 关于GATT协议相关的回调接口 ,主要有GATT连接状态的回调、发现Service服务的回调、特征值(Characteristic)发生改变的回调、最大传输单元(MTU)改变的回调、物理层发送模式(PHY)改变回调等,如下:
BluetoothGattCallback gattCallback = new BluetoothGattCallback () {
@Override
public void onPhyUpdate ( BluetoothGatt gatt , int txPhy , int rxPhy , int status ) {
super . onPhyRead ( gatt , txPhy , rxPhy , status );
Log . d ( TAG , "onPhyUpdate txPhy:" + txPhy + "; rxPhy:" + rxPhy );
}
@Override
public void onMtuChanged ( BluetoothGatt gatt , int mtu , int status ) {
super . onMtuChanged ( gatt , mtu , status );
Log . d ( TAG , "onMtuChanged mtu:" + mtu + "; status:" + status );
}
@Override
public void onConnectionStateChange ( BluetoothGatt gatt , int status , int newState ) {
super . onConnectionStateChange ( gatt , status , newState );
Log . d ( TAG , "onConnectionStateChange newState:" + newState );
if ( newState == BluetoothProfile . STATE_CONNECTED ) { //协议连接成功
Log . d ( TAG , "STATE_CONNECTED" );
bluetoothGatt = gatt ;
bluetoothGatt . discoverServices (); //发现service服务
} else if ( newState == BluetoothProfile . STATE_DISCONNECTED ) { //协议连接失败
Log . d ( TAG , "STATE_DISCONNECTED" );
}
}
}
3.获取服务和特征 在GATT协议连接成功之后,就可以去发现从设备端提供了哪些Service服务,如上代码。
这是一个异步的过程,待从设备反馈了自己提供的服务之后,Android框架层会通过BluetoothGattCallback回调通知,如下:
BluetoothGattCallback gattCallback = new BluetoothGattCallback () {
@Override
public void onServicesDiscovered ( BluetoothGatt gatt , int status ) {
super . onServicesDiscovered ( gatt , status );
List < BluetoothGattService > services = gatt . getServices ();
for ( BluetoothGattService service : services ) {
Log . d ( TAG , "UUID:" + service . getUuid (). toString ());
}
//1.根据UUID获取到服务
mGattService = gatt . getService ( UUID . fromString ( "0000ff00-0000-1000-8000-00805f9b34fb" ));
if ( mGattService == null ) {
Log . w ( TAG , "GattService is null!" );
} else {
Log . i ( TAG , "connect GattService" );
if ( writeCharacteristic == null ) {
//2.获取一个特征(Characteristic),这是从设备定义好的,我通过这个Characteristic去写从设备感兴趣的值
writeCharacteristic = mGattService
. getCharacteristic ( UUID . fromString ( "0000ff02-0000-1000-8000-00805f9b34fb" ));
}
if ( readCharacteristic == null ) {
//3.获取一个主设备需要去读的特征(Characteristic),获取从设备发送过来的数据
readCharacteristic = mGattService
. getCharacteristic ( UUID . fromString ( "0000ff01-0000-1000-8000-00805f9b34fb" ));
//4.注册特征(Characteristic)值改变的监听
bluetoothGatt . setCharacteristicNotification ( readCharacteristic , true );
List < BluetoothGattDescriptor > descriptors = readCharacteristic . getDescriptors ();
for ( BluetoothGattDescriptor descriptor : descriptors ) {
descriptor . setValue ( BluetoothGattDescriptor . ENABLE_NOTIFICATION_VALUE );
bluetoothGatt . writeDescriptor ( descriptor );
}
}
}
}
};
经过上述代码中的四个步骤,两个设备间已经可以发送和接收数据了。
4.通过特征(Characteristic)发送数据 把需要发送的数据设置到 writeCharacteristic,然后再调用 BluetoothGatt 的写入方法,即可完成数据的发送:
writeCharacteristic . setValue ( datas );
bluetoothGatt . writeCharacteristic ( writeCharacteristic );
5.读取数据 当从设备有数据发送到主设备之后,Android系统会回调 BluetoothGattCallback 的 onCharacteristicChanged 方法通知:
@Override
public void onCharacteristicChanged ( BluetoothGatt gatt , BluetoothGattCharacteristic characteristic ) {
super . onCharacteristicChanged ( gatt , characteristic );
UUID uuid = characteristic . getUuid ();
byte [] receiveData = characteristic . getValue ();
for ( byte b : receiveData ) {
Log . d ( TAG , "receiveData:" + Integer . toHexString ( b ));
}
}
三、注意事项 1.自动连接属性 connectGatt 方法的自动连接参数设置为true之后,连接建立了,这个时候如果是断开连接,如下:
bluetoothGatt . disconnect ();
虽然在Android层面的 BluetoothGattCallback 接口会立刻反馈一个 STATE_DISCONNECTED 信号值,但是在数据链路层却还是处于连接的状态,连接并没有断开。
2.开启定位功能 现在Android最新的版本,需要开启定位才能使用BLE功能。
判断定位功能是否开启:
private boolean isLocationEnable ( Context context ) {
LocationManager locationManager = ( LocationManager ) context . getSystemService ( Context . LOCATION_SERVICE );
boolean networkProvider = locationManager . isProviderEnabled ( LocationManager . NETWORK_PROVIDER );
boolean gpsProvider = locationManager . isProviderEnabled ( LocationManager . GPS_PROVIDER );
if ( networkProvider || gpsProvider ) {
return true ;
}
return false ;
}
开启定位功能的方法:
LocationManager locationManager = ( LocationManager ) context . getSystemService ( Context . LOCATION_SERVICE );
try {
Field field = UserHandle . class . getDeclaredField ( "SYSTEM" );
field . setAccessible ( true );
UserHandle userHandle = ( UserHandle ) field . get ( UserHandle . class );
Method method = LocationManager . class . getDeclaredMethod (
"setLocationEnabledForUser" ,
boolean . class ,
UserHandle . class );
method . invoke ( locationManager , true , userHandle );
} catch ( Exception e ) {
}
3.最大传输单元(MTU)的设置 Android默认的最大传输单元(MTU)是23个字节,除去报文头占用的3个字节,实际最大只能传递20个字节。当两个设备之间传递的数据长度超过20字节的时候,数据就会被截断,导致通信异常。
只有在GATT协议连接成功之后,才可以设置MTU值,最大MTU=512,如下:
bluetoothGatt . requestMtu ( 128 );
4.从设备广播间隔影响连接 当Android协议栈(Host)给蓝牙芯片Chip发送一个连接的指令,芯片在收到之后,会在一定的时间内去接收从设备的广播,在收到广播之后才会发送连接请求给从设备;如果从设备的广播间隔设置不合理,就会导致芯片无法在限定的时间内收到广播,导致无法发送连接请求。
对于安卓开发者来说,理解并熟练运用架构模式是提升代码质量、可维护性和可测试性的关键。
我们总是在追求编写更清晰、更健壮、更易于维护的代码。而选择一个合适的应用架构,正是实现这一目标的基石。从经典的 MVC,到后来的 MVP、MVVM,再到如今函数式思想影响下的 MVI,安卓的架构模式一直在演进。
为了方便对比,我们设定一个极其简单的业务场景:
一个登录界面,包含输入用户名、密码的输入框和一个登录按钮。点击按钮后,模拟一个网络请求,根据结果(成功/失败)更新 UI。
MVC (Model-View-Controller) MVC 是一个非常古老的 UI 架构模式,在安卓早期开发中,它是一种“天然”的结构。
Model (模型): 负责处理数据和业务逻辑。例如,网络请求、数据库操作、数据bean类。View (视图): 负责展示 UI 界面,并将用户的操作(点击、输入)传递出去。在安卓中,这通常由 XML 布局文件和 Activity/Fragment 扮演。Controller (控制器): 接收来自 View 的用户操作,调用 Model 处理业务逻辑,然后更新 View 的显示。Activity/Fragment 通常也承担了 Controller 的角色。MVC的问题 在安卓中,Activity/Fragment 的职责过重,它既是 View 的一部分,又是 Controller。这 导致 View 和 Controller 紧密耦合 ,业务 逻辑和 UI 代码混杂 在一起,使得代码难以测试和维护。这就是我们常说的超大型Activity和Fragment。
简单代码实现 UserModel.kt (Model)
// M - Model: 负责业务逻辑和数据
data class User ( val name : String )
object UserModel {
// 模拟登录网络请求
fun login ( username : String , callback : ( Result < User >) -> Unit ) {
// 模拟延时
Thread . sleep ( 1000 )
if ( username == "admin" ) {
callback ( Result . success ( User ( "Administrator" )))
} else {
callback ( Result . failure ( Exception ( "用户名或密码错误" )))
}
}
}
activity_login.xml (View)
<LinearLayout xmlns:android= "http://schemas.android.com/apk/res/android"
android:layout_width= "match_parent"
android:layout_height= "match_parent"
android:orientation= "vertical"
android:padding= "16dp" >
<EditText
android:id= "@+id/et_username"
android:layout_width= "match_parent"
android:layout_height= "wrap_content"
android:hint= "Username" />
<Button
android:id= "@+id/btn_login"
android:layout_width= "match_parent"
android:layout_height= "wrap_content"
android:text= "Login" />
<ProgressBar
android:id= "@+id/progress_bar"
android:layout_width= "wrap_content"
android:layout_height= "wrap_content"
android:layout_gravity= "center"
android:visibility= "gone" />
</LinearLayout>
LoginActivity.kt (View & Controller)
// V & C: Activity 同时扮演视图和控制器的角色
class LoginActivity : AppCompatActivity () {
private lateinit var usernameEditText : EditText
private lateinit var loginButton : Button
private lateinit var progressBar : ProgressBar
override fun onCreate ( savedInstanceState : Bundle ?) {
super . onCreate ( savedInstanceState )
setContentView ( R . layout . activity_login )
usernameEditText = findViewById ( R . id . et_username )
loginButton = findViewById ( R . id . btn_login )
progressBar = findViewById ( R . id . progress_bar )
loginButton . setOnClickListener {
handleLogin ()
}
}
private fun handleLogin () {
showLoading ()
val username = usernameEditText . text . toString ()
// 控制器直接调用模型
// 注意:这里为了简化在主线程调用,实际开发应使用协程或线程池
Thread {
UserModel . login ( username ) { result ->
runOnUiThread {
hideLoading ()
result . onSuccess { user ->
showSuccess ( "欢迎, ${user.name}!" )
}. onFailure { error ->
showError ( error . message ?: "登录失败" )
}
}
}
}. start ()
}
private fun showLoading () {
progressBar . visibility = View . VISIBLE
}
private fun hideLoading () {
progressBar . visibility = View . GONE
}
private fun showSuccess ( message : String ) {
Toast . makeText ( this , message , Toast . LENGTH_SHORT ). show ()
}
private fun showError ( message : String ) {
Toast . makeText ( this , message , Toast . LENGTH_SHORT ). show ()
}
}
MVP (Model-View-Presenter) 为了解决 MVC 中 Controller 和 View 的过度耦合问题,MVP 诞生了。它引入了一个新的角色:Presenter。
Model: 职责不变,处理数据和业务逻辑。View: 职责更纯粹,只负责 UI 的渲染和事件的传递。Activity/Fragment 属于 View 层。它通常会实现一个接口,供 Presenter 调用。Presenter: 作为 View 和 Model 之间的桥梁。它从 Model 获取数据,然后调用 View 接口的方法来更新 UI。Presenter 不持有任何 Android 框架的引用 ,这使得它很容易进行单元测试。解决了一些MVC的痛点,View 和 Presenter 通过接口进行通信,实现了彼此的解耦。Presenter 持有 View 的接口引用,但不关心 View 的具体实现。
MVP的问题 主要有两点:
接口爆炸: 为了清晰地定义View和Presenter之间的契约,你需要为每一个界面(或功能模块)定义至少两个接口: IView 和 IPresenter 。随着项目模块的增加,接口数量会急剧膨胀,导致代码文件数量非常多。 繁琐的绑定与解绑: Presenter 需要持有 View 的引用,为了避免内存泄漏(尤其是在异步任务回调时),你必须在View(如Activity/Fragment)的生命周期方法(onCreate, onDestroy)中手动进行 attachView() 和 detachView() 操作。这个过程是重复且容易出错的。 代码实现 LoginContract.kt (契约接口)
// 定义 View 和 Presenter 之间的契约
interface LoginContract {
// View 必须实现的接口
interface View {
fun showLoading ()
fun hideLoading ()
fun showLoginSuccess ( message : String )
fun showLoginError ( message : String )
}
// Presenter 必须实现的接口
interface Presenter {
fun login ( username : String )
fun onDestroy ()
}
}
LoginPresenter.kt (Presenter)
// P - Presenter: 不含任何 Android SDK 代码,纯 Kotlin/Java
class LoginPresenter ( private var view : LoginContract . View ?) : LoginContract . Presenter {
// Presenter 持有 Model 的引用
private val model = UserModel
override fun login ( username : String ) {
view ?. showLoading ()
// 同样,这里简化处理,实际应在子线程
Thread {
model . login ( username ) { result ->
// 回到主线程更新 UI
( view as ? AppCompatActivity ) ?. runOnUiThread {
view ?. hideLoading ()
result . onSuccess { user ->
view ?. showLoginSuccess ( "欢迎, ${user.name}!" )
}. onFailure { error ->
view ?. showLoginError ( error . message ?: "登录失败" )
}
}
}
}. start ()
}
// 防止内存泄漏
override fun onDestroy () {
view = null
}
}
LoginActivity.kt (View)
// V - View: 只负责 UI 展示和用户事件传递
class LoginActivity : AppCompatActivity (), LoginContract . View {
private lateinit var presenter : LoginContract . Presenter
// ... UI 控件声明 ...
override fun onCreate ( savedInstanceState : Bundle ?) {
super . onCreate ( savedInstanceState )
setContentView ( R . layout . activity_login )
presenter = LoginPresenter ( this )
// ... findViewById ...
loginButton . setOnClickListener {
presenter . login ( usernameEditText . text . toString ())
}
}
override fun showLoading () {
progressBar . visibility = View . VISIBLE
}
override fun hideLoading () {
progressBar . visibility = View . GONE
}
override fun showLoginSuccess ( message : String ) {
Toast . makeText ( this , message , Toast . LENGTH_SHORT ). show ()
}
override fun showLoginError ( message : String ) {
Toast . makeText ( this , message , Toast . LENGTH_SHORT ). show ()
}
override fun onDestroy () {
presenter . onDestroy ()
super . onDestroy ()
}
}
MVVM (Model-View-ViewModel) MVVM 是 Google 官方推荐的架构模式,也是 Jetpack 组件(如 ViewModel, LiveData, DataBinding)的核心思想。
Model: 职责不变。View: 职责依然是 UI 展示。但它不再被动地等待 Presenter 调用,而是主动观察 (Observe) ViewModel 中的数据变化来更新自己。ViewModel: 类似于 Presenter,负责处理业务逻辑并持有数据。但它不直接引用 View。它通过暴露可观察的数据(如 LiveData或 StateFlow)来通知 View 更新。ViewModel 的生命周期与 UI 控制器(Activity/Fragment)的配置更改无关,因此在屏幕旋转时数据不会丢失。解决前面两代主流架构的痛点: 数据绑定 (Data Binding) 和 生命周期感知 (Lifecycle-Aware) 。View 和 ViewModel 通过可观察的数据流进行单向或双向绑定,实现了比 MVP 更彻底的解耦。
MVVM的问题 状态管理的复杂性(Lack of Unidirectional Data Flow):
虽然 MVVM 实现了视图和数据之间的双向绑定,但在复杂的场景下,这可能导致数据流变得难以追踪。当一个数据模型在多个视图或组件之间共享时,任何一方的修改都可能影响到其他部分,使得状态的来源和变化路径变得模糊不清。 不一致的状态(Inconsistent State):
在某些情况下,视图可能会从多个地方接收数据更新(例如,网络请求、本地数据库更新、用户输入)。当这些更新并非同步发生时,视图可能会进入一种不一致的状态,导致用户界面出现意料之外的行为或显示错误。 代码实现 LoginViewModel.kt (ViewModel)
// VM - ViewModel: 持有数据和业务逻辑,通过 LiveData 通知 View
class LoginViewModel : ViewModel () {
private val model = UserModel
// UI 状态的 LiveData
private val _loginState = MutableLiveData < LoginUiState >()
val loginState : LiveData < LoginUiState > = _loginState
fun login ( username : String ) {
_loginState . value = LoginUiState . Loading
// 使用 ViewModelScope 协程来处理异步操作
viewModelScope . launch ( Dispatchers . IO ) {
model . login ( username ) { result ->
val newState = result . fold (
onSuccess = { user -> LoginUiState . Success ( "欢迎, ${user.name}!" ) },
onFailure = { error -> LoginUiState . Error ( error . message ?: "登录失败" ) }
)
// 切换回主线程更新 LiveData
withContext ( Dispatchers . Main ) {
_loginState . value = newState
}
}
}
}
}
// 定义 UI 状态的密封类
sealed class LoginUiState {
object Loading : LoginUiState ()
data class Success ( val message : String ) : LoginUiState ()
data class Error ( val message : String ) : LoginUiState ()
}
LoginActivity.kt (View)
// V - View: 观察 ViewModel 中的数据变化来更新 UI
class LoginActivity : AppCompatActivity () {
// 通过 ktx 库轻松获取 ViewModel
private val viewModel : LoginViewModel by viewModels ()
// ... UI 控件声明 ...
override fun onCreate ( savedInstanceState : Bundle ?) {
super . onCreate ( savedInstanceState )
setContentView ( R . layout . activity_login )
// ... findViewById ...
loginButton . setOnClickListener {
viewModel . login ( usernameEditText . text . toString ())
}
// 观察 LiveData 的变化
viewModel . loginState . observe ( this ) { state ->
when ( state ) {
is LoginUiState . Loading -> showLoading ()
is LoginUiState . Success -> {
hideLoading ()
showSuccess ( state . message )
}
is LoginUiState . Error -> {
hideLoading ()
showError ( state . message )
}
}
}
}
// ... UI 更新方法 ...
}
别忘了在 build.gradle 文件中添加 ViewModel 和 LiveData 的依赖。
MVI (Model-View-Intent) MVI 是一种更现代的架构模式,深受函数式编程思想的影响,它强调单向数据流 和状态的唯一可信源 。
Model: 在 MVI 中,Model 通常指UI 状态 (State) 。它是一个不可变的数据结构,代表了 UI 在某一时刻的所有状态。View: 负责渲染 UI 状态,并捕获用户意图 (Intent) ,将其发送出去。Intent: 不要和安卓的 Intent 组件混淆。这里的 Intent 指的是用户的操作意图,例如 LoginClickedIntent、UsernameChangedIntent 等。环形单向数据流: View 发送 Intent (用户意图)。 ViewModel (或类似角色) 接收 Intent,处理业务逻辑。 ViewModel 生成一个新的 State (UI 状态)。 View 订阅 State 的变化,并用新状态渲染自己。 唯一数据源: UI 的所有状态都由一个 State 对象管理,任何对 UI 的更新都必须通过生成一个新的 State 来实现。这使得状态变化变得可预测和易于调试。这一定程度上解决了 MVVM 架构的多数据来源导致UI变化难以追踪的问题。代码实现 LoginContract.kt (State, Intent, Effect)
// M - State: UI 的状态,必须是不可变的
data class LoginViewState (
val isLoading : Boolean = false ,
val errorMessage : String ? = null
)
// I - Intent: 用户的意图
sealed class LoginIntent {
data class LoginClicked ( val username : String ) : LoginIntent ()
}
// Side Effect: 一次性事件,如 Toast 或导航
sealed class LoginEffect {
data class ShowSuccessToast ( val message : String ) : LoginEffect ()
}
LoginViewModel.kt (处理 Intent,生成 State)
// ViewModel: 处理 Intent,更新 State,发送 Effect
class LoginViewModel : ViewModel () {
private val model = UserModel
private val _state = MutableStateFlow ( LoginViewState ())
val state : StateFlow < LoginViewState > = _state . asStateFlow ()
private val _effect = MutableSharedFlow < LoginEffect >()
val effect : SharedFlow < LoginEffect > = _effect . asSharedFlow ()
// 统一处理所有 Intent
fun processIntent ( intent : LoginIntent ) {
when ( intent ) {
is LoginIntent . LoginClicked -> login ( intent . username )
}
}
private fun login ( username : String ) {
viewModelScope . launch {
_state . value = _state . value . copy ( isLoading = true , errorMessage = null )
// 使用 Coroutine + Flow
kotlin . runCatching {
// 模拟异步调用
withContext ( Dispatchers . IO ) { model . performLogin ( username ) }
}. onSuccess { user ->
_state . value = _state . value . copy ( isLoading = false )
_effect . emit ( LoginEffect . ShowSuccessToast ( "欢迎, ${user.name}!" ))
}. onFailure { error ->
_state . value = _state . value . copy ( isLoading = false , errorMessage = error . message )
}
}
}
}
// 可以在 Model 中提供一个挂起函数
suspend fun UserModel . performLogin ( username : String ): User {
delay ( 1000 )
if ( username == "admin" ) return User ( "Administrator" )
else throw Exception ( "用户名或密码错误" )
}
LoginActivity.kt (View)
// V - View: 发送 Intent,订阅 State 和 Effect
class LoginActivity : AppCompatActivity () {
private val viewModel : LoginViewModel by viewModels ()
// ... UI 控件 ...
override fun onCreate ( savedInstanceState : Bundle ?) {
super . onCreate ( savedInstanceState )
// ... setContentView, findViewById ...
loginButton . setOnClickListener {
viewModel . processIntent ( LoginIntent . LoginClicked ( usernameEditText . text . toString ()))
}
// 订阅 State 变化来更新持久性 UI
lifecycleScope . launch {
viewModel . state . collect { state ->
progressBar . visibility = if ( state . isLoading ) View . VISIBLE else View . GONE
state . errorMessage ?. let { Toast . makeText ( this @LoginActivity , it , Toast . LENGTH_SHORT ). show () }
}
}
// 订阅 Effect 来处理一次性事件
lifecycleScope . launch {
viewModel . effect . collect { effect ->
when ( effect ) {
is LoginEffect . ShowSuccessToast -> {
Toast . makeText ( this @LoginActivity , effect . message , Toast . LENGTH_SHORT ). show ()
}
}
}
}
}
}
从 MVC 到 MVI,我们可以清晰地看到一个趋势:职责分离越来越明确,耦合度越来越低,代码的可测试性和可维护性越来越强 。特别是从 MVVM 到 MVI,我们开始更多地借鉴函数式编程 的思想,通过管理不可变的状态和单向数据流来构建更加稳健和可预测的应用。
Clean Architecture 相比于 MVC、MVP、MVVM 这些主要关注于 UI层 的架构模式外,Clean Architecture(整洁架构)是一个更高层次、更宏观的架构思想。
简单来说,如果把 MVP/MVVM 看作是如何组织一个具体页面的代码(View、Presenter/ViewModel、Model),那么 Clean Architecture 就是如何组织整个 App 所有模块代码的宏伟蓝图 。
Clean Architecture 由 Robert C. Martin (人称 “Uncle Bob”) 提出,其核心目标是 “分离关注点” (Separation of Concerns) ,通过将软件系统划分成不同的层次,来创建一个易于维护、独立于框架、可测试性极强的系统。
核心思想:依赖关系原则 (The Dependency Rule) 这是 Clean Architecture 最最核心的一条规则:
源代码的依赖关系,只能从外层指向内层。
想象一个洋葱或一组同心圆,内层代码对任何外层代码都一无所知。
这些层次通常代表什么呢?从内到外:
Entities (实体层) 这是最核心的内层。 定义了整个应用的核心业务对象和规则。在安卓中,这通常是你的数据模型类(例如 User, Product, Order 等),它们是纯粹的 Kotlin/Java 对象 (POJO/POKO),不应该包含任何与安卓框架、数据库或网络相关的代码。极度稳定,变动最少。它不知道任何其他层的存在。
Use Cases / Interactors (用例层 / 交互器) 这是应用的业务逻辑层。封装并实现了应用的所有业务用例。例如 LoginUseCase (处理登录逻辑)、GetUserProfileUseCase (获取用户信息)、PlaceOrderUseCase (下单逻辑) 等。它们会协调 Entities 来完成具体的业务操作。这一层同样是纯 Kotlin/Java 代码,不依赖任何外层。它知道 Entities,但不知道谁会来调用它,也不知道数据从哪里来(是从网络还是数据库)。
Interface Adapters (接口适配器层) 这是数据转换层。负责将 Use Cases 和 Entities 层的数据,转换成适合外层(如UI、数据库)使用的格式,反之亦然。你熟悉的 MVP 中的 Presenter 和 MVVM 中的 ViewModel 就生活在这一层 。此外,还包括数据库的数据映射器 (Mappers)、网络请求返回的数据模型 (DTOs) 等。
它的作用就像一个双向翻译官。例如,ViewModel 调用 Use Case,获取到纯业务数据 (Entity),然后 ViewModel 将这个 Entity 转换成 UI 可以直接显示的格式 (UI Model)。
Frameworks & Drivers (框架与驱动层) 这是最外层,也是最不稳定的一层。包含所有具体的实现细节。例如:
UI: Activities, Fragments, Jetpack Compose UI数据库: Room, Realm 的具体实现网络: Retrofit, Volley 的具体实现安卓框架: 各种 Android SDK 的调用这一层是所有东西粘合在一起的地方,依赖关系都指向内部。比如,Activity 持有 ViewModel 的引用,但 ViewModel 对 Activity 一无所知。
Clean Architecture 与 MVP/MVVM 的关系 很多人会误解 Clean Architecture 是 MVP/MVVM 的替代品,其实不是。它们是互补关系:
Clean Architecture 是一个宏观的、全局的架构设计。 它定义了整个应用的模块划分和依赖方向,比如把业务逻辑 (domain 模块) 和数据获取 (data 模块) 以及界面展示 (presentation 模块) 分开。MVP/MVVM 是一个微观的、专注于 UI 层的设计模式。 它通常被应用在 Clean Architecture 的最外两层(Interface Adapters 和 Frameworks & Drivers)来组织 UI 代码。可以这样理解一个典型的请求流程:
View (Activity/Fragment) 在最外层,它接收到用户操作。View 通知 ViewModel (位于接口适配器层)。 ViewModel 调用相应的 Use Case (位于用例层) 来执行业务逻辑。 Use Case 可能会通过一个 Repository 接口 (接口定义在 Use Case 层) 来请求数据。 这个接口的具体实现 RepositoryImpl (位于框架驱动层或接口适配器层) 会决定是从网络 (Retrofit) 还是从本地数据库 (Room) 获取数据。 数据从内层一步步返回,经过适配器层的转换,最终由 ViewModel 提供给 View 进行展示。 在这个流程中,Use Case 层根本不关心数据是来自网络还是数据库,也不关心数据最终是显示在 Activity 上还是一个 Compose 屏幕上。这就实现了彻底的解耦。
优点总结 独立于框架 (Framework Independent): 核心业务逻辑不依赖于安卓 SDK,可以轻松迁移到其他平台(如桌面应用)。可测试性强 (Testable): 内层的业务逻辑 (Use Cases, Entities) 是纯粹的 Kotlin/Java 代码,可以进行非常快速的单元测试,无需启动模拟器。独立于 UI (UI Independent): 你可以随意更换你的 UI 实现(比如从 XML 布局换成 Jetpack Compose),而无需改动任何业务逻辑。独立于数据库 (Database Independent): 你可以从 Room 切换到其他数据库,只需要改动最外层的具体实现,核心逻辑不受影响。代码结构清晰 (Maintainable): 尤其在大型复杂项目中,严格的分层让代码职责分明,新人更容易上手,代码也更容易维护。Android平台常见动效 现在市面上的形形色色Android客户端,为了更优的用户体验,我们开发的上游产品和交互往往会在界面里设计很多动效。传统的一页页的静态展示页面已经不足以满足用户的审美需求了。
而动效的分类也是花样百出的,以播放时机来说有点击触发,打开页面触发,还有可跟随手指的交互持续触发的等等。有时候一些和数据耦合性较大的动效甚至需要我们自己来手写复杂的自定义View,比如曲线图、图表类型。
而我日常碰到的大部分的动效需求,还是依赖UI设计的同时来制作提供的,像那些短时间单次的展示类动效,往往实现方式比较随意,对资源的格式要求也不太严苛。
简单动画 帧动画,在Android中,帧动画是通过Drawable动画实现的。你可以创建一个AnimationDrawable对象,然后在XML中定义一系列的帧(frames),每帧可以是一个Drawable资源。然后在代码中启动这个动画。注意确保你的每个Drawable资源的尺寸是一致的,以便在动画过程中保持帧的正确显示。 PAG动画,pag相较于上面的帧动画对性能更加友好。PAG是腾讯公司自主研发的一套完整动画工作流解决方案。最初的原因是为了解决更为复杂的视频编辑场景下动画渲染问题,同时又覆盖了UI动画和直播场景,于2022年1月在Github开源。其使用方法可以说相当简单,只需要先从github主页确定版本,到gradle里引入依赖,然后在我们应用的xml布局中放置pagView,没有额外的属性需要配置。最后在代码里设置其文件源,循环方式,调用播放即可。 MP4动画,比较直接,将动画导出为视频格式,直接获取mediaplayer实例,绑定surfaceView或者TextureView,再填文件,播放视频即可。需要关注的是surfaceView播放视频一开始可能会有黑屏问题,可以用静态图占位。 可交互3D动效 Kanzi动效 跟手可互动的动效,也不得不谈kanzi动效。以下介绍来自百科与官网:
Kanzi产品是行业领先的3D引擎和UI开发工具,支持高效率沉浸式3D效果,跨系统多屏互联并能与安卓生态完美融合,已经成为全球主流车厂智能座舱首选的UI开发工具和引擎。更新后的Kanzi架构可与安卓操作系统、生态系统深度兼容。Kanzi可基于安卓的任何功能提供强大的图形设计支持,确保高质量的图像效果。
对于Kanzi动效的集成使用方式,因为没有自己从头开始对接,我只按照顺序一笔带过,有不对的地方欢迎指正。首先我们集成kanzi运行所需的Runtime.aar,kanziJava支持库aar,资源文件,资源列表的txt等等,还需要在gradle里写明不可压缩的文件类型,以防止无法加载资源。
在使用上,我们先在XML布局中声明,同时通过属性填入asstes里的资源名,和资源文件绑定:
<com.rightware.kanzi.KanziTextureView
android:id= "@+id/tx_KanziSurfaceView"
android:layout_width= "@dimen/dp_2560"
android:layout_height= "@dimen/dp_1190"
app:clearColor= "@android:color/transparent"
app:kzbPathList= "climate.kzb"
app:layout_constraintTop_toTopOf= "parent"
app:name= "climate"
app:startupPrefabUrl= "kzb://climate/StartupPrefab"
tools:ignore= "MissingConstraints" />
在Java代码里我们需要设置通信的工具类,在里面添加监听器来接收和上行下行信号的交互:
// 数据接口定义
public interface AndroidNotifyListener {
void notifyDataChanged ( String name , String value );
void dataSourceFinish ();
}
// 添加数据接收监听和下行通信
AndroidUtils . setListeners ( this );
AndroidUtils . removeListeners ( this );
AndroidUtils . setValue ( SourceData . RightMidMove_up2down , y );
Unity动效 本文重点,Unity的大名在游戏界可谓如雷贯耳,记得小时候玩的很多游戏的开屏界面即有一个大大的 Unity 字样和图标。
Unity是实时3D互动内容创作和运营平台。包括游戏开发、美术、建筑、汽车设计、影视在内的所有创作者,借助Unity将创意变成现实。Unity平台提供一整套完善的软件解决方案,可用于创作、运营和变现任何实时互动的2D和3D内容,支持平台包括手机、平板电脑、PC、游戏主机、增强现实和虚拟现实设备。Unity作为全球领先的 3D 引擎之一,团结引擎可以为 3D HMI提供全栈支持。即为从概念设计到量产部署的整个 HMI 工作流程提供创意咨询、性能调优、项目开发等解决方案,从而为车载信息娱乐系统和智能驾驶座舱打造令人惊叹的交互式体验。
其实在第一版我们项目集成的是上面的Kanzi方案,其性能表现较Unity要差一些。性能还是其次,发起替换的主要原因还是在项目推进的过程中,对方工程师对动效样式的优化达不到评测部门的要求,后来更新迭代就更换了Unity方案。
而本文的重点也是在于Unity3D动效的使用,案例为车载IVI系统空调app的风向调节,交互逻辑比上面举的例子更加复杂,需要实时跟手,在交互热区范围内需要不断变化动效形态,并完成双向通信,保证动效和车载信号的一致性。
Android应用对接Unity集成的两种方案 以下提到的集成方案均可以在Unity的官方网站进行更加详细的查阅:
团结引擎 手册
通信协议制定 集成的第一步,要提前根据APP产品交互逻辑,来指定和Unity之间的通信协议。有哪些功能是开关,需要调整哪些属性。例如空调app里就涉及几个出风口的打开关闭,可以以0/1来区分。还有风口的方向调节,需要互传x,y坐标值。Android和Unity之间一般是采用JSON字符串来通信的。
而且,两方通信链路和Unity的集成方式还有关,像下面要谈到的第一种进程隔离方案,就是通过集成全量的Unity依赖包,利用aar内部JNI接口来通信的,而第二种Client/Server架构就是通过Android的AIDL接口来和单独的Unity服务端进程通信的。
进程隔离方案-UAAL(Render As Library) 基于UAAL(Render As Library),支持把渲染服务嵌入原生安卓APP。
Tuanjie 引擎可作为 Render Service,嵌入原生 Android APP,为原生 Android APP 提供 3D 内容 支持多个 view,支持非全屏渲染,每个 APP 仅需集成 View 组件,脱离 Activity 支持加载多个 Tuanjie 实例 Tuanjie Editor 打包出的 Android Studio 工程或 APK 包括 Client 和 Service 两部分。
UAAL 方案的优势在于,Unity 渲染服务和原生 APP 之间的通信链路是独立的,原生 APP 可以通过 JNI 接口和 Unity 渲染服务进行通信,而 Unity 渲染服务也可以通过 JNI 接口和原生 APP 进行通信。
这种方式集成的话,Unity会将渲染引擎,资源文件,和Android上层的通信代码都打包导出到一个aar中,其体积随动效的复杂程度而变化,同时会使集成方的apk包体积增加。而且项目里有多少方要使用Unity动效,就需要多少份的渲染引擎。这个方案由客户端来负责Unity控件的创建销毁,显示隐藏,一般适用一对一,通信链路简单的,即项目中可能只有一个模块需要使用Unity动效的情况。在多模块需要使用Unity的情况下,进程隔离的方案对性能的占用也比较高。
上层使用到的控件——UnityPlayer,它是一个Unity自定义的FrameLayout,里面有他们自己实现的一系列添加view,显示,和渲染逻辑。资源文件均存在于Unity打的依赖包中,对外不开放。
集成步骤 第一步,将Unity提供的aar放置于libs文件夹中,并在gradle里添加其编译引用。
implementation files ( 'libs/UnityAnimation_0321V4.aar' )
第二步,gradle中配置Unity所需的NDK版本,配置abifilters,设置要将哪些架构的动态库打包到apk中,对于车机项目来说只需要固定的某一种架构即可。还有设置不压缩的文件类型,使Unity可以顺利找到资源使用。
ndkVersion "23.1.7779620"
aaptOptions {
noCompress = [ '.tj3d' , '.ress' , '.resource' , '.obb' , '.bundle' , '.tuanjieexp' , 'global-metadata.so' ] + tuanjieStreamingAssets . tokenize ( ', ' )
ignoreAssetsPattern = "!.svn:!.git:!.ds_store:!*.scc:!CVS:!thumbs.db:!picasa.ini:!*~"
}
ndk {
abiFilters 'arm64-v8a'
}
有一点需要注意,我们还需要在项目的string.xml资源文件中添加Unity所需的一条 String 资源,否则Unity侧会空指针。
<string name= "game_view_content_description" > Game view</string>
第三步,将要显示Unity动效的页面 Activity 改为继承自 UnityPlayerActivity ,Unity的核心显示控件是 UnityPlayer ,它的创建销毁,显示隐藏,由 UnityPlayerActivity 来统一管理,项目中集成这个 Activity 的子类再将 mUnityPlayer 通过 addView() 添加到自己的根布局 ViewGroup 中当背景即可,而且可以在xml上面继续增加其他View控件。
第四步,封装Unity通信工具类,Android给Unity发消息可以直接通过 UnityPlayer 的 sendMessage() 静态方法,传入Unity通信协议中指定的类名。
UnityPlayer . UnitySendMessage ( OBJ_NAME , METHOD_NAME , communicateMessage )
Unity使用C#开发,其给 Android 上层发消息则是通过反射回调信号类里的方法实现的,所以我们最好将信号管理类做成单例的,并给其Unity留下一个方法或者成员,可以拿到我们类的实例,顺利反射回调。我这里使用的是一个Kotlin类声明,并对外暴露一个公开的 unityInstance 成员。而这个方法 onReceiveMsgFromUnity ,即是Unity的反射调用,我们在其中进行信号的解析,并传到View中去,注意这个方法不是在主线程中反射的,所以后面需要优化一波。
object UnityMessageHelper {
val unityInstance = this
// Unity给Android的消息回调
fun onReceiveMsgFromUnity ( msg : String ) {
LogUtils . d ( TAG , "onReceiveMsgFromUnity: $msg" )
if ( listenerList . size > 0 ) {
listenerList . forEach {
it . onReceiveUnityMessage ( msg )
}
}
}
}
信号类UnityMessageHelper的优化 由于我们的目标工程是空调app,在用户调节风向时的回调频率相当高,而自动扫风模式下,底层上传的数据频率也相当高,所以不适合到主线程中操作这么多的数据,我们用协程,配合Default调度器来处理这种CPU密集型的任务。两条链路,用户手指的拖动操作时,Unity反射回调的线程本身都是工作线程了,所以我们在使用自定义的接口回调到View类的时候,使用MainScope.launch包一层,确保是到主线程更新我们的UI。而自动扫风模式从域控制器接收到风口点击的坐标值时,我们拿到数据后给Unity下发信号,更新动效的指向位置。可以使用协程上下文切换,withContext(Dispatcher.Default)将其切到工作线程里发送给Unity。
遇到的问题 Unity方给的aar里的基类Activity适用与绝大多数的普通应用,但是我这里空调app的定位是一个高层级的悬浮窗,我的工程里压根就没有Activity。
这个时候我们用不上他们定义的 UnityPlayerActivity ,只能使用原生Raw的UnityPlayer,自己管理其创建,销毁,resume和pause。这里需要注意的是,UnityPlayer的创建需要传一个Context上下文,而应用里又没有Activity类型的Context,故只能使用非Activity类型的Context,在实践中发现,这个UnityPlayer的实例必须是我们的应用拿到可用的窗口 token 句柄之后,才能被成功创建,否则就会报错。
所以正确的创建与初始化顺序是先使用WindowManager添加一个xml布局inflate来的ViewGroup,在其onAttachToWindow的方法回调之后,再创建UnityPlayer的实例,并添加到这个ViewGroup的布局中去,调用其resume方法。
这样添加的UnityPlayer有一个无法解决的黑屏问题,因为Unity的渲染加载至少都需要4,5秒,期间我们只能在更上层的View里设置静态背景图覆盖上去,等Unity加载完毕,发送ready的回调之后,我们移除掉这个占位的静态图,展示Unity动效的界面。这也是进程隔离的方案的一个很棘手的问题。我的解决方案是在开机的时候往屏幕外添加一个View专门来初始化加载Unity,加载完毕后,再将UnityPlayer给从里面remove掉,重新添加到实际的要展示的窗口中去,这样打开界面的时候可以略去加载的耗时,稍微减少页面僵直的时间。
单进程-URAS(Render As Service) 一个渲染服务 Service 支持多个 Client APP 运行,且每个 Client APP 相互独立、互不干扰、可自更新。
仅需一个 Service,多个工程共用同一个 Service,每个工程均正常运行且互不干扰 一个新 Client 集成到已运行 Service 中,新 Client 可正常运行和渲染,已运行的 Client 和 Service 均不受干扰。 已运行的 Service 和 Client 中,关闭一个 Client,不影响其他 Client 和 Service 的正常运行 每个 Client 可通过 OTA 单独更新,更新后可正常运行,且不影响其他 Client 和 Service Unity Rendering as Service(简称URAS) 的渲染方案是团结引擎特有的,无需在多个安卓应用中集成多个Unity 3D player,而是后台运行,前端应用可直接调用,节省系统资源,更适合多应用动效一镜到底的设计。
相较进程隔离方案的优势 这个方案是在UAAL方案的基础上升级的,所以有一些前期工作是重复的,不作重复的阐述。
它是将要显示的几个Unity引擎都打包到同一个Server服务端去统一管控。其实服务端的apk打包也是拿到Unity提供的服务端AAR打进一个空工程,内部逻辑也隐藏到了AAR中。服务端和客户端的通信采用我们熟知的AIDL接口来实现。而且这个服务端我们需要设置为persistent应用,使其能开机自启,自动执行渲染等工作,其他应用有显示需求可以秒开,并且长时间不显示也不会自己回收资源了,客户端的黑屏问题也可以解决了。
相比于UAAL方案,客户端需要集成的是一个体积很小的Client.aar,对于客户端apk的体积控制是有优势的。
URAS渲染原理 BufferQueue BufferQueue 机制 是 Android 图形系统中最核心、最重要的底层机制之一,它实现了图形数据的生产者(Producer)和消费者(Consumer)之间的高效、零拷贝 的通信。
它可以将一个组件(生产者 )生成的图形数据缓冲区,安全、高效地传递给另一个组件(消费者 )以供显示或进一步处理。 关键点是零拷贝,数据在生产者和消费者之间是通过内存句柄 (Handle) 传递的,而不是通过 CPU 复制实际的像素数据。这对于高性能的图形(如视频、3D)渲染至关重要。
BufferQueue 本质上是一个队列,但它管理的不是数据本身,而是图形缓冲区 (Graphic Buffers) 的句柄。
生产者调用 dequeueBuffer() 从队列中获取一个空闲 的缓冲区。将图形数据(例如一帧画面)绘制到这个缓冲区中。调用 queueBuffer():将填充好的缓冲区排入队列 ,通知消费者数据已准备好。 消费者是需要使用图形数据进行显示的组件,调用 acquireBuffer(),从队列中获取 一个生产者刚刚填充好的缓冲区。使用缓冲区中的数据进行合成、显示或进一步处理。调用 releaseBuffer() 将缓冲区释放 回队列,使其再次变为空闲 ,供生产者重复使用。 BufferQueue 的工作流程 初始化: 生产者和消费者通过 Binder IPC 建立连接,并协商 BufferQueue 的参数(例如最大缓冲区数量)。BufferQueue 会根据需求,通过 Gralloc生产者获取缓冲区: 生产者调用 dequeueBuffer(),从 BufferQueue 中拿到一个空闲的缓冲区句柄(ID = n)。生产者渲染: 生产者(通常是 GPU)将一帧画面渲染到缓冲区 n 中。生产者入队: 生产者调用 queueBuffer(),将缓冲区 n 放入待消费队列。消费者通知: BufferQueue 通知消费者(例如 SurfaceFlinger),新数据已到达。消费者获取缓冲区: 消费者调用 acquireBuffer(),从队列中取出缓冲区 n 的句柄。消费者处理/显示: 消费者(例如 SurfaceFlinger)使用缓冲区 n 的数据进行合成,最终交给硬件显示。消费者释放: 消费者完成对缓冲区 n 的使用后,调用 releaseBuffer(),将缓冲区 n 返回给空闲列表。循环: 缓冲区 n 再次变为“空闲”,生产者可以再次获取并重复使用。跨进程渲染 使用 Surface / SurfaceTexture / SurfaceView,这是Android中实现跨进程图形数据共享和渲染的最核心机制,尤其适用于高性能的3D渲染(如游戏、AR/VR、视频播放、复杂图形引擎等)。
Android的图形系统基于 BufferQueueSurface 本质上就是 BufferQueue 的生产者(Producer)端。当进程B将渲染好的图形数据(例如,一个OpenGL ES的帧)放入 BufferQueue 后,进程A的 SurfaceView 或 TextureView(它们是 BufferQueue 的消费者 Consumer)就可以从队列中取出并直接显示。
当客户端的 SurfaceView 创建时,会向系统请求一个 Surface 对象,这个 Surface 就关联了一个 BufferQueue。通过 Binder IPC 将 Surface 对象的句柄(或一个包装了 Surface 的特殊对象)传递给Unity服务端。
服务端在接收到 Surface 句柄后,将其作为 渲染目标 (例如,作为 OpenGL ES 的 EGL 窗口)。将图形数据(如 glSwapBuffers())渲染到这个 Surface 关联的 BufferQueue 中。一旦服务端将渲染数据提交到 BufferQueue,系统会自动将这些数据交给客户端的 SurfaceView 进行合成和显示,绕过了传统的Android View绘制流程 (即 onDraw)。
这种渲染方式性能极高,因为数据传输是在底层图形缓冲区级别完成,无需CPU进行像素拷贝,适用于视频流、3D渲染等对帧率要求高的场景。
也可以使用 TextureView + SurfaceTexture + Binder IPC,这是一种特殊的组合,TextureView 将内容渲染到一个 SurfaceTexture 上,而 SurfaceTexture 也可以跨进程共享,通常用于更灵活的纹理操作(例如对渲染内容进行旋转、缩放等 View 级别的变换)。它的底层原理与 SurfaceView 类似,也是基于 BufferQueue 。
URAS集成与使用方式 我们只需要在 gradle 里引入这个客户端aar。在gradle sync之后,将远程的 UnityView 添加到自己的布局中去,配置好display参数(用来给服务端区分是哪个引擎的内容),并指定服务端的包名。承载的View类型有 SurfaceView 和 TextureView 两种,而我的应用界面因为是一个悬浮窗口,设计有进出场的渐隐渐出动效,而 SurfaceView 不可以线性地设置alpha动画,所以选取 TextureView 来当作容器。
<com.unity3d.renderservice.client.TuanjieView
android:id= "@+id/unityview"
android:layout_width= "match_parent"
android:layout_height= "match_parent"
app:tuanjieDisplay= "2"
app:tuanjieServicePkgName= "com.tuanjie.renderservice"
app:tuanjieViewType= "TextureView" />
剩余的代码逻辑仅仅是服务端 Service 的启动,添加服务连接的回调,消息回调。由于服务端为若干个 Client 的公共引擎,所以连 resume 和 pause 都不需要处理,因为这两个操作会对所有的客户端都生效。我们只需要确保启动服务,并使用正确的display即可,面板退到后台可以使用 setVisbility 来控制其显示隐藏。
除此之外,我们的通信工具类, UnityMessageHelper 还需要实现两个接口,一个服务连接状态接口,一个业务数据的消息回调接口,代码如下:
object UnityMessageHelper : TuanjieRenderService . Callback , SendMessageCallback {
override fun onServiceConnected () {
LogUtils . w ( TAG , "onUnityRenderServiceConnected" )
}
override fun onServiceDisconnected () {
LogUtils . w ( TAG , "onUnityRenderServiceDisConnected" )
.. .
}
override fun onServiceStartRenderView ( p0 : Int ) {
LogUtils . i ( TAG , "onServiceStartRenderView" )
}
override fun onClientRecvMessage ( message : String ?) = null
// 服务端的消息回调
override fun onClientRecvMessageWithNoRet ( msg : String ?) {
// 回调消息的解析
}
}
可以说URAS方案由于其统一管控,一对多的特点,在性能和客户端的易集成性方面,是优于UAAL方案的。另外,还可以从架构层面上,联动更多的动效使用模块,实现一镜到底的丝滑转场。
Android UI 更新是线程不安全的,也就是说,你不能直接在子线程中操作 UI。所有 UI 操作都必须在主线程(或称 UI 线程) 中进行,Activity的所有生命周期回调和UI更新操作都发生在应用程序的主线程中。
这就引出了一个问题:如果后台线程完成了数据加载或计算,怎么才能通知主线程更新 UI 呢?答案就是 Handler 消息机制。
简单来说, Handler 消息机制 是一套允许你将任务(消息或可运行对象)发送到另一个线程的消息队列中,并在该线程中执行这些任务的框架。
使用场景 UI 线程更新 安卓规定,所有对 UI 的操作都必须在主线程(UI 线程)中进行。当你在子线程中执行耗时操作(如网络请求、数据库查询)并需要更新 UI 时,就不能直接在子线程操作 UI 元素。这时,Handler 就派上了用场。你可以在子线程中发送一个 Message 或 Runnable 到主线程的 Handler,然后 Handler 会在主线程中处理这个消息或运行这个 Runnable,从而安全地更新 UI。
线程间通信 除了 UI 更新,Handler 机制也是实现线程间通用通信的重要方式。例如两个子线程之间的消息传递,还有Service与其他组件的通信,或者单个组件内部的消息处理。
延迟任务和定时任务 Handler 提供了 postDelayed() 和 sendMessageDelayed() 等方法,可以让你在指定的时间后执行某个任务或发送某个消息。例如,等待某个界面加载完成后再开始播放动画。每隔一段时间从服务器获取最新数据。应用发送验证码后的倒计时。还可以用于防抖过滤,在短时间内多次点击某个按钮时,可以使用 Handler 延迟处理点击事件,只响应第一次点击。
异步任务的封装 许多安卓框架和库在底层也利用了 Handler 机制来处理异步任务,例如AsyncTask,虽然已被官方标记为 deprecated,但其内部实现就包含了 Handler 来处理子线程与主线程的通信。
其他特定场景 当用户在 EditText 中输入时,系统会通过 Handler 将输入事件传递给对应的 View。另外,部分动画框架会使用 Handler 来调度动画的每一帧。还有安卓系统内部的很多事件(如触摸事件、生命周期事件)的分发都可能间接涉及到 Handler 机制。
可以看出,Handler最主要的任务就是实现线程间的消息传递和处理。这其中的核心需求,就是就是如何 高效地等待消息 。
在 Android 应用中,主线程(UI 线程)负责处理用户界面更新和所有用户输入事件。一旦系统检测到主线程发生了长时间的阻塞,就会弹出ANR(Application Not Responding)弹窗并终结应用。为了避免ANR, 主线程不能被耗时的操作阻塞 。
Looper 与 Handler 协同工作,为每个线程维护一个消息队列。Looper 会不断检查这个队列是否有新消息需要处理。
这里的关键挑战在于:Looper 如何 在没有消息时高效地等待 ,而不是持续消耗 CPU 资源进行busy-waiting。传统的 忙等待 会极大地浪费电量并降低系统性能。因此,需要一种能够让线程在无事可做时进入睡眠状态,并在有新事件发生时被唤醒的机制。
Linux体系和文件描述符简介 Linux系统中,应用程序到系统内核的体系架构:
Linux 操作系统的体系架构分为用户态和内核态 (用户空间和内核空间),内核本质上可以说属于一种桥接软件,往下控制着计算机的硬件资源,往上又给上层应用程序提供运行的环境。
而平常所说的 用户态 就是上层应用程序的活动空间,应用程序的执行又依托于内核提供的资源,包括 CPU 资源、存储资源、I/O 资源 等,为了让上层应用能够访问这些资源,内核必须为上层应用提供访问的接口,也就是 系统调用(system call) 。
系统调用 是受控的内核入口,借助这一机制,进程可以请求内核以自己的名义去执行某些动作,以 API 的形式,内核提供有一系列服务供程序访问,包括创建进程、执行 I/O 以及为进程间通信创建管道等。
文件描述符 Linux 继承了 UNIX 一切皆文件 的思想,在 Linux 中,所有执行 I/O 操作的系统调用都以文件描述符指代已打开的文件,包括管道(pipe)、FIFO、Socket、终端、设备和普通文件等 。
文件描述符(File Descriptor) 是 Linux 中的一个索引值,系统在运行时有大量的文件操作,内核为了高效管理已被打开的文件会 创建索引 ,用于 指向被打开的文件 ,这个索引就是文件描述符。
文件描述符往往是数值很小的非负整数,获取文件描述符一般是通过系统调用 open() 韩素, 在参数中指定 I/O 操作目标文件的路径名 。
事件文件描述符enevtfd eventfd 可以用于线程或父子进程间通信,内核通过 eventfd 也可以向用户空间发送消息,其核心实现是 在内核空间维护一个计数器 ,向用户空间暴露一个与之关联的匿名文件描述符,不同线程通过 读写该文件描述符通知或等待对方 ,内核则通过写该文件描述符通知用户程序。
在 Linux 中,很多程序都是事件驱动的,也就是通过 select/poll/epoll 等系统调用在一组文件描述符上进行监听,当文件描述符的状态发生变化时,应用程序就调用对应的事件处理函数,有的时候需要的 只是一个事件通知 ,没有对应具体的实体,这时就可以使用 eventfd 。
与 管道(pipe) 相比,管道是 半双工 的传统 IPC 方式,两个线程就需要两个 pipe 文件,而 eventfd 通信只需要打开一个文件。文件描述符又是非常宝贵的资源,Linux 默认也只有 1024 个。
eventfd 非常节省内存,可以说就是一个计数器,是 自旋锁 + 唤醒队列 来实现的,而管道一来一回在用户空间有多达 4 次的复制,内核还要为每个 pipe 至少分配 4K 的虚拟内存页,就算传输的数据长度为 0 也一样。这就是为什么只需要通知机制的时候优先考虑使用eventfd 。
插入 自旋锁 概念 自旋锁(Spinlock)是计算机科学中用于多线程同步的一种锁机制。
当一个线程尝试获取一个已经被其他线程持有的自旋锁时,它不会立即被操作系统挂起(阻塞)并切换到其他任务。相反,它会进入一个循环(即“自旋”),反复地检查锁是否已经被释放。
常规的互斥锁(如Mutex)在锁被占用的情况下,会使请求锁的线程进入休眠状态,这涉及上下文切换(Context Switch):
将当前线程的状态保存起来。 将CPU调度给另一个准备运行的线程。 上下文切换是需要消耗CPU时间的。自旋锁通过“忙等待”的方式, 避免了这种上下文切换的开销 。
这里是用来保护 eventfd 内部的计数器,确保在多线程环境下对计数器的操作是原子的。即当Looper线程 B 正在读取计数器的值时,Looper线程 A 不能修改计数器的值,否则会导致计数器的值不一致。
eventfd具体工作流程 eventfd 它创建了一个内核维护的 64 位计数器,并将其关联到一个文件描述符。这个文件描述符可以像普通文件描述符一样进行读写操作,并支持 select() 、poll() 和 epoll() 等 I/O 多路复用机制,从而实现事件的等待和通知。
使用 eventfd() 系统调用可以创建一个 eventfd 对象,并返回一个文件描述符。你可以指定一个初始值 initval 来初始化计数器。
#include <sys/eventfd.h>
int eventfd ( unsigned int initval , int flags );
核心机制:读写计数器 写入 (write) :当你向 eventfd 对应的文件描述符写入一个 8 字节的 uint64_t 值时,这个值会被加到 eventfd 内部的计数器上。 如果写入会导致计数器溢出(超过 uint64_t 的最大值),write() 操作会阻塞,直到有 read() 操作消耗了计数器的一部分值,或者如果文件描述符是非阻塞模式,则会立即失败并返回 EAGAIN。 读取 (read) :当你从 eventfd 对应的文件描述符读取一个 8 字节的 uint64_t 值时,会发生以下情况:非信号量模式(默认) : read() 操作会返回当前计数器的值,并将计数器重置为 0。信号量模式(使用 EFD_SEMAPHORE 标志创建) : read() 操作会返回 1,并将计数器减 1。 如果计数器为 0,read() 操作会阻塞,直到有 write() 操作增加计数器的值,或者如果文件描述符是非阻塞模式,则会立即失败并返回 EAGAIN。 eventfd 的强大之处在于 它与 Linux 的 I/O 多路复用机制(如 select()、poll() 和 epoll())的集成 。
当 eventfd 计数器 大于 0 时,它被认为是 可读的 。这意味着你可以使用 select()、poll() 或 epoll() 监测这个文件描述符的读事件,当事件发生时(计数器非零),你的程序就会被唤醒。 当 eventfd 计数器 小于 0xfffffffffffffffe (即 uint64_t 的最大值 - 1) 时,它被认为是 可写的 。这意味着你可以安全地向它写入一个 1 而不会导致溢出。 总的来说,eventfd 提供了一种简单、高效且灵活的事件通知机制,特别适用于需要通过文件描述符进行事件等待和信号传递的场景。
epoll机制 如何实现上述这种高效地等待呢? 需要先了解下Linux上的三种IO机制:select,poll和epoll 。
在Linux中,poll 、 select 和 epoll 都是用于I/O多路复用(I/O Multiplexing)的机制。它们的主要作用是让一个进程/线程能够 同时监控多个文件描述符 (File Descriptors,FDs),比如套接字(sockets)、管道(pipes)等,以判断这些描述符是否可读、可写或发生异常,从而高效地处理多个I/O事件,而无需为每个FD创建单独的线程或进程。
这三种机制的核心目标都是:
避免阻塞 :当一个进程需要同时监听多个I/O操作(如多个socket连接)时,不用为每个连接创建一个线程或进程,从而节省系统资源。 提高效率 :通过一次系统调用,就可以检查多个FD的状态,而不是对每个FD逐一调用read/write等函数。 1. select
程序将自身所关注的 文件描述符(FD) 集合传给内核,内核检查这些FD是否有事件(可读、可写、异常),然后返回。由于FD集合大小有限(通常1024),且每次调用都需要重新传入FD集合,效率较低。主要缺点有三点,FD数量受限。每次调用都要传递整个FD集合,即使只有一个FD发生变化。内核使用线性扫描判断FD状态,效率低。
2. poll
工作原理与select类似,但使用pollfd结构体数组来表示FD集合,不再有1024的限制。可以支持更多的FD。缺点就是每次调用仍然需要传递整个FD集合 。内核依然使用线性扫描,效率没有本质提升。
epoll:可扩展的 I/O 事件监控器Android Native 层的 Looper 实现利用了 Linux 内核提供的 epollepoll 是一种高级的 I/O 事件通知机制,允许一个线程高效地 监控多个文件描述符 ,以判断它们是否准备好进行 I/O 操作。
在 Looper 的上下文中,epoll_wait()select 和 poll,epoll 具有显著的优势:
可扩展性(Scalability) :epoll 的性能随着被监控文件描述符数量的增加而保持良好。与 select 和 poll 每次调用都需要内核遍历所有文件描述符列表不同,epoll 在内核中维护了一个 “兴趣列表” 。当事件发生时,内核直接提供一个已就绪的文件描述符的列表 ,避免了昂贵的线性扫描。这对于 Android 这样复杂的系统至关重要,因为一个线程可能需要等待各种不同的事件源。效率(Efficiency) :通过将监控任务委托给内核,线程可以在不需要时保持低功耗的睡眠状态,直到真正需要被唤醒,从而节省电量并提高系统性能。触发模式(Trigger Modes) :epoll 支持边沿触发(Edge-Triggered, ET)和水平触发(Level-Triggered, LT)两种模式,为事件处理提供了更精细的控制。水平触发通知就是文件描述符上可以非阻塞地执行 I/O 调用,这时就认为它已经就绪。边缘触发通知就是文件描述符自上次状态检查以来有了新的 I/O 活动,比如新的输入,这时就要触发通知。epoll 机制最大的优化,其实就是 避免了对整个“兴趣列表”的轮询(遍历),转而依赖内核的主动通知来获取“就绪列表”。
eventfd:轻量级的唤醒信号尽管 epoll 提供了高效的等待机制,但当另一个线程向目标线程的消息队列发送新消息时,需要一种方式来唤醒处于睡眠状态的 Looper 线程。这就是 eventfd
上文介绍过,eventfd被创建时,会维护一个64位的计数器,当线程向eventfd写入数据时,会将计数器加1,当线程从eventfd读取数据时,会将计数器减1。当这个值大于0,就说明是可读状态,当这个值小于溢出的最大值就认为其处于可写状态。
而在 Android Handler 框架中,eventfd 的工作原理如下:
创建 :当一个 Looper 在线程上初始化时,它的底层原生实现会创建一个 eventfd 文件描述符。监控 :这个 eventfd 文件描述符随后被添加到 Looper 的 epoll 实例中,epoll_wait() 将会监控它。唤醒 :当另一个线程向目标线程的 MessageQueueMessageQueue 代码会向 eventfd 写入一个 1。这个写入操作会触发 eventfd,使其变为“可读”状态。解除阻塞 :阻塞 Looper 线程的 epoll_wait() 调用会立即返回,表明 eventfd 上有事件发生。消息处理 :Looper 随后从其队列中检索并处理新消息。epoll实例及其核心api epoll API 的核心数据结构称为 epoll 实例 ,它与一个 打开的文件描述符 关联,这个文件描述符不是用来做 I/O 操作的,而是内核数据结构的句柄 ,这些内核数据结构实现了记录兴趣列表和维护就绪列表两个目的。
那么这两个列表里面都是一些什么内容呢?
兴趣列表 (Interest List) 兴趣列表 是 epoll 实例维护的、内核中的一个数据结构。它记录了 Looper 线程想要监听的所有文件描述符及其对应的事件类型 。
当 Looper 被创建时,或者添加新的监听事件源时,它会通过 epoll_ctl() 系统调用,将对应的文件描述符及其感兴趣的事件(例如读事件 EPOLLIN)添加到 epoll 实例的兴趣列表中。
在 Android Looper 的实现中,兴趣列表 里主要包含两种类型的数据:
核心就是 用于唤醒 Looper 的 eventfd 事件文件描述符 。当其他线程(比如通过 Handler.sendMessage())向 Looper 的消息队列发送消息时,最终会在底层向这个 eventfd 写入数据。这个写入操作会触发 eventfd 上的可读事件。epoll 就会监测到这个事件,从而唤醒正在 epoll_wait() 的 Looper 线程。这是 Looper 从睡眠中醒来处理新消息的核心机制。
另外还可能有被监听的其他文件描述符 ,这些可以是其他 I/O 源的文件描述符,例如管道 (pipes) ,可能用于更复杂的 IPC 场景。 socket 文件描述符 :如果 Looper 线程也负责网络通信。各种 Linux 特殊文件 :如 inotify (文件系统事件通知)、timerfd (定时器事件) 等,如果应用有特殊需求,都可以将其文件描述符添加到 Looper 的 epoll 监听中。
因为 Looper 不仅仅处理 Java 层面的消息,它 在原生层也可以监听和处理各种系统事件 。通过将这些文件描述符加入兴趣列表,Looper 能够在一个统一的事件循环中同时处理 Java 消息和原生系统事件。
每个被添加到兴趣列表的文件描述符,通常还会附带一个与之关联的 用户数据(user data) 。在 epoll 中,这个用户数据通常是一个 epoll_data_t 联合体,它可以是一个指针或一个整数 。在 Android Looper 中,它通常被用来指向一个内部结构体,该结构体包含了与这个文件描述符相关的回调函数或上下文信息,以便在事件发生时能够正确地对应处理。
就绪列表 (Ready List) 就绪列表 也是 epoll 实例维护在内核中的一个数据结构。它记录了当前已经发生事件、可以进行 I/O 操作的文件描述符 。
当 Looper 线程调用 epoll_wait() 时,如果兴趣列表中的任何文件描述符上发生了它所关注的事件,内核就会将这些“就绪”的文件描述符及其发生的事件类型填充到就绪列表中。epoll_wait() 随即返回,Looper 线程就可以遍历这个就绪列表,对每个就绪的描述符执行相应的处理逻辑。
就绪列表中的数据通常包含:
就绪的文件描述符 (File Descriptor): 即兴趣列表中发生了事件的那个文件描述符。发生的事件类型 (Events): 描述该文件描述符上发生了什么类型的事件,例如 EPOLLIN(有数据可读)、EPOLLOUT(可以写入数据)、EPOLLERR(发生错误)等。对应的用户数据 (User Data): 这是在将文件描述符添加到兴趣列表时一同传入的那个用户数据。Looper 会利用这个用户数据来识别事件源,并执行对应的回调函数来处理事件。例如,如果是 eventfd 就绪,它就知道有新消息需要处理;如果是其他文件描述符就绪,它就知道对应的原生 I/O 事件发生了。总结就是兴趣列表让 Looper 可以声明它关注的所有事件源,而就绪列表则让 Looper 能够精确地知道哪些事件已经发生 ,从而避免了不必要的轮询,实现了响应式和低功耗的事件驱动模型。
epoll四个主要的api epoll API 由以下 4 个系统调用组成。
epoll_create() 创建一个 epoll 实例,返回代表该实例的文件描述符,有一个 size 参数,该参数指定了我们想通过 epoll 实例检查的文件描述符个数。
epoll_creaet1() 的作用与 epoll_create() 一样,但是去掉了无用的 size 参数,因为 size 参数在 Linux 2.6.8 后就被忽略了,而 epoll_create1() 把 size 参数换成了 flag 标志,该参数目前只支持 EPOLL_CLOEXEC 一个标志。
epoll_ctl() 操作与 epoll 实例相关联的列表,通过 epoll_ctl() ,我们可以增加新的描述符到列表中,把已有的文件描述符从该列表中移除,以及修改代表文件描述符上事件类型的掩码。
epoll_wait() 用于获取 epoll 实例中处于就绪状态的文件描述符。
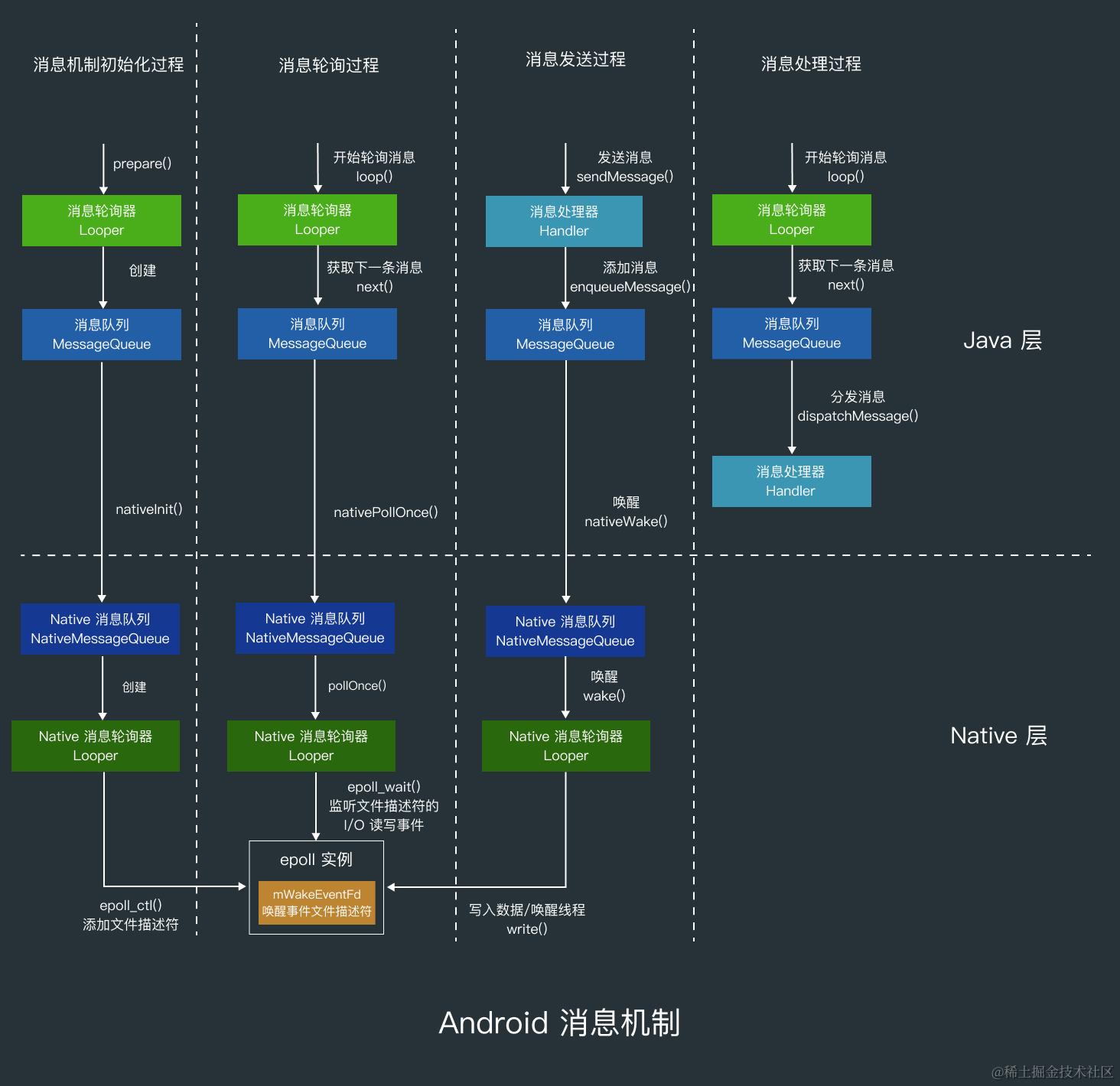
Handler完整链路 Android消息机制流程图:
消息机制初始化 消息机制初始化流程就是 Handler、Looper 和 MessageQueue 三者的初始化流程,Handler 的初始化流程比较简单.
当你直接在 Activity 的 onCreate() 或其他 UI 线程回调中创建一个 Handler 时,通常不需要显式地初始化 Looper,因为系统已经为你做好了。安卓应用的入口点是 ActivityThread ,当应用进程启动时,ActivityThread 会被创建。在 ActivityThread 的 main() 方法中,它会调用 Looper.prepareMainLooper()。
Looper.prepareMainLooper()
这个静态方法是主线程 Looper 初始化的关键。它会检查当前线程是否已经有 Looper(避免重复创建)。
如果当前线程没有 Looper ,则先创建一个新的 MessageQueue 。再创建一个 Looper 对象,并将 MessageQueue 关联到 Looper 上。 将 Looper 存储到当前线程的 ThreadLocal 中(确保每个线程有自己的 Looper)。 当我们通过 Java 层的 Looper.prepare() 或 Looper.prepareMainLooper() 方法初始化 Looper 时,它会触发 Native 层的对应操作。简而言之,Native层的初始化过程 主要涉及以下几个关键步骤:
创建 Native MessageQueue 对象:这是消息的实际存储和管理容器。 创建 Native Looper 对象:它将与 MessageQueue 关联,并负责消息的调度和分发。 初始化 epoll 实例:这是 Looper 高效等待消息的关键。 初始化 eventfd :作为唤醒 Looper 的信号机制。 Native层的prepare方法:
// Native层 Looper.cpp (简化版)
void Looper :: prepare () {
// 1. 获取或创建 Looper 的 ThreadLocal 存储
// Looper::TLS_KEY 是一个线程局部存储键,确保每个线程拥有独立的Looper实例
// 如果当前线程已经有一个Looper,则会报错,因为一个线程只能有一个Looper。
// Looper::gLooper 实际上是一个TLS (Thread Local Storage) 变量,
// 它在每个线程中保存一个 Looper 指针。
if ( gLooper != nullptr ) {
// ... 抛出异常:一个线程只能prepare一次Looper
}
// 2. 创建 Native MessageQueue 对象
// 这个MessageQueue对象是Handler消息的实际存储队列
sp < MessageQueue > messageQueue = new MessageQueue ();
// 3. 创建 Native Looper 对象
// Looper::create() 内部会完成 Looper 对象的核心创建和 epoll/eventfd 的初始化
sp < Looper > looper = Looper :: create ( messageQueue );
// 4. 将 Looper 对象存储到当前线程的 ThreadLocal
// 这样,在当前线程中,任何Handler的构造函数都能通过Looper::getForThread()获取到它。
gLooper = looper ;
}
通过Looper::create方法来创建Looper对象:
// Native层 Looper.cpp (简化版)
sp < Looper > Looper :: create ( sp < MessageQueue > messageQueue ) {
// 1. 创建 Looper 实例
sp < Looper > looper = new Looper ( messageQueue );
// 2. 初始化 epoll 实例
// looper->mEpollFd = epoll_create1(EPOLL_CLOEXEC);
// epoll_create1() 返回一个 epoll 实例的文件描述符 (mEpollFd)。
// EPOLL_CLOEXEC 标志确保这个文件描述符在执行 execve() 系统调用时会被关闭,防止子进程意外继承。
looper -> mEpollFd = epoll_create1 ( EPOLL_CLOEXEC );
if ( looper -> mEpollFd < 0 ) {
// ... 错误处理
}
// 3. 初始化 eventfd
// looper->mWakeEventFd = eventfd(0, EFD_CLOEXEC | EFD_NONBLOCK);
// eventfd() 创建一个 eventfd 文件描述符 (mWakeEventFd)。
// 初始值为0。
// EFD_CLOEXEC 同样确保 execve() 时关闭。
// EFD_NONBLOCK 表示这是一个非阻塞的eventfd,写入操作不会阻塞。
looper -> mWakeEventFd = eventfd ( 0 , EFD_CLOEXEC | EFD_NONBLOCK );
if ( looper -> mWakeEventFd < 0 ) {
// ... 错误处理
}
// 4. 将 eventfd 添加到 epoll 的兴趣列表
// looper->addFd() 是一个内部方法,用于将文件描述符添加到 epoll 监听列表。
// 它通过 epoll_ctl(EPOLL_CTL_ADD, ...) 实现。
// 监听 EPOLLIN 事件,表示 eventfd 有数据可读(即被写入了)。
// 第四个参数 (LOOPER_ID_WAKE) 是一个标识符,用于在 epoll_wait 返回时识别是哪个文件描述符触发了事件。
int result = looper -> addFd ( looper -> mWakeEventFd , LOOPER_ID_WAKE , EPOLLIN , nullptr );
if ( result != 0 ) {
// ... 错误处理
}
return looper ;
}
Looper 的构造函数中会调用 epoll_create1() 创建一个 epoll 实例,然后再调用 epoll_ctl() 给 epoll 实例添加一个唤醒事件文件描述符,把唤醒事件的文件描述符和监控请求的文件描述符添加到 epoll 的兴趣列表中。到这里消息机制的初始化就完成了。
消息轮询机制建立 在 ActivityThread 的 main() 方法的最后,会调用 Looper.loop()。这个方法会使当前线程(主线程)进入一个无限循环。
这个循环中会调用 MessageQueue 的 next() 方法获取下一条消息,获取到消息后,loop() 方法就会调用 Message 的 target 的 dispatchMessage() 方法,target 其实就是发送 Message 的 Handler 。最后就会调用 Message 的 recycleUnchecked() 方法回收处理完的消息。
如果消息队列为空,Looper 线程会进入休眠状态(这正得益于底层 epoll 和 eventfd 的机制),直到有新消息到来。
这个循环就是安卓 UI 线程保持“存活”和响应用户事件的基础。
在 MessageQueue 的 next() 方法中,首先会调用 nativePollOnce() 这个JNI方法,检查队列中是否有新的消息要处理 。
如果没有,那么当前线程就会在执行到 Native 层的 epoll_wait() 时阻塞 。 如果有消息,而且消息是同步屏障 ,那就会找出或等待需要优先执行的异步消息。调用完 nativePollOnce() 后,如果没有同步屏障,或者取到到了异步或非异步消息,就会判断消息是否到了要执行的时间 ,是的话则返回消息给 Looper 处理准备分发,不是的话就重新计算消息的执行时间(when)。 在把消息返回给 Looper 后,下一次执行 nativePollOnce() 的 timeout 参数的值是默认的 0 ,所以进入 next() 方法时,如果没有消息要处理,next() 方法中还可以执行 IdleHandler 。在处理完消息后, next() 方法最后会遍历 IdleHandler 数组,逐个调用 IdleHandler 的 queueIdle() 方法。
IdleHandler 可以用来做一些在主线程空闲的时候才做的事情,通过 Looper.myQueue().addIdleHandler() 就能添加一个 IdleHandler 到 MessageQueue 中。
以Java 层的 Looper.loop() 和 MessageQueue 的 next() 方法为入口,这个消息循环的建立,就是 android::Looper 利用 epoll 高效地等待并处理事件的过程。
在 Native 层,消息循环的建立主要围绕着 android::Looper 类的 loop() 方法和其内部调用的 pollOnce() 方法展开。
1. Looper::loop() - 消息循环的入口 当你在 Java 层调用 Looper.loop() 方法时,它会通过 JNI(Java Native Interface) 机制,最终调用到 Native 层的 android::Looper::loop() 方法。
// Native层 Looper.cpp (简化版)
void Looper :: loop () {
// 确保当前线程已经准备好了一个Looper
sp < Looper > me = Looper :: getForThread (); // 获取当前线程的Looper实例
if ( me == nullptr ) {
// 错误处理:当前线程没有调用 Looper.prepare()
return ;
}
// 这是一个无限循环,Looper 会一直在这里运行,直到被 quit() 终止
for (;;) { // 无限循环,除非 Looper 被终止
// 核心:调用 pollOnce() 等待并处理事件
int result = me -> pollOnce ( - 1 ); // -1 表示无限等待,直到有事件发生
switch ( result ) {
case POLL_WAKE : // 由 wake() 方法唤醒,通常表示有新消息或Runnable
// 如果是Looper被唤醒,但还没消息,则会在这里继续循环
break ;
case POLL_MESSAGE : // 收到了要处理的消息
// pollOnce 内部会处理 MessageQueue 中的消息
break ;
case POLL_TIMEOUT : // 超时 (如果 pollOnce 设置了超时时间)
break ;
case POLL_ERROR : // 发生错误
break ;
}
// 如果 Looper 被终止 (调用了 quit() 或 quitSafely())
if ( me -> mExitWhenIdle ) { // mExitWhenIdle 是一个标志,表示Looper是否应该退出
break ; // 退出循环
}
}
}
从代码中可以看出,Looper::loop() 的核心就是在一个 无限 for 循环 中不断地调用 me->pollOnce(-1)。这个 pollOnce 方法才是 真正执行阻塞、等待和初步事件处理 的地方。
2. Looper::pollOnce() - 阻塞、唤醒与事件分发 pollOnce() 方法是 Looper 消息循环的精髓所在。它利用了 epoll 来高效地等待事件,避免了忙等待。
// Native层 Looper.cpp (简化版)
int Looper :: pollOnce ( int timeoutMillis ) {
// 1. 处理待处理的消息 (如果有)
// 首先检查 MessageQueue 中是否有即将到期或已经到期的消息需要处理。
// 如果有,它会计算下一个消息的到期时间,并可能调整 epoll_wait 的超时时间。
// 如果有立即需要处理的消息,直接返回 POLL_MESSAGE,不进入 epoll_wait。
if ( mMessageQueue -> mNextBarrierToken != 0 || mMessageQueue -> hasMessages ( now )) {
// 如果有消息,并且没到等待时间,会直接处理
// 或者处理屏障消息,清理掉同步消息
// ...
timeoutMillis = 0 ; // 不阻塞,立即返回
}
// 2. 调用 epoll_wait 等待事件
// mEpollFd 是在 Looper 初始化时创建的 epoll 实例文件描述符
// events 是一个用于接收就绪事件的数组
// EPOLL_MAX_EVENTS 是最大事件数
// timeoutMillis 是等待的超时时间(-1 表示无限等待)
int result = epoll_wait ( mEpollFd , events , EPOLL_MAX_EVENTS , timeoutMillis );
// 3. 处理 epoll_wait 返回的事件
if ( result < 0 ) { // epoll_wait 失败
if ( errno == EINTR ) { // 被信号中断,继续循环
return POLL_WAKE ; // 被唤醒但没有明确事件
}
return POLL_ERROR ; // 其他错误
}
// 4. 遍历就绪列表,处理事件
for ( int i = 0 ; i < result ; i ++ ) {
epoll_event & event = events [ i ];
int ident = event . data . u32 ; // 获取事件标识符 (Looper::addFd 时传入的)
if ( ident == LOOPER_ID_WAKE ) { // 这是由 eventfd 触发的唤醒事件
// 清除 eventfd 上的信号,以准备下一次唤醒
uint64_t counter ;
ssize_t nread = read ( mWakeEventFd , & counter , sizeof ( uint64_t ));
// 唤醒通常意味着有新消息到达 MessageQueue,但具体消息由后续处理
result = POLL_WAKE ;
} else if ( ident == LOOPER_ID_MESSAGE ) { // 这是由 MessageQueue 自身触发的消息事件(不常用)
// Android Looper主要通过 LOOPER_ID_WAKE 来感知消息,此分支较少触发
result = POLL_MESSAGE ;
} else { // 处理其他文件描述符上的自定义事件
// 如果Looper监听了其他自定义文件描述符(如管道、Socket),会在这里处理
// 通常会调用与该fd关联的回调函数
// ...
}
}
// 5. 处理消息队列中的消息
// 无论是否被 epoll 唤醒,都会再次检查并分发 MessageQueue 中的消息
// 这是真正将消息从队列中取出并分发给对应 Handler 的地方。
// 可能会调用 MessageQueue::next() 获取下一个消息,并调用 Handler 的 dispatchMessage()。
if ( mMessageQueue -> hasMessages ( now )) { // 再次检查是否有消息
result = POLL_MESSAGE ;
}
mMessageQueue -> dispatchMessages ( this , now ); // 分发消息
return result ;
}
根据上面代码可以看出,调用了 Looper::loop() 后,即进入一个无限循环,在循环内部,不断调用 Looper::pollOnce(-1)。
pollOnce() 函数 首先检查 MessageQueue 中是否有立即需要处理的消息。如果有,会立即处理而不阻塞。
核心逻辑 为调用 epoll_wait(mEpollFd, ...)。此时,Looper 线程会进入 睡眠状态 ,等待 mEpollFd 监听的任何文件描述符上发生事件。
如果消息队列中有新消息,MessageQueue 会向 mWakeEventFd 写入一个字节。这会触发 mWakeEventFd 上的 EPOLLIN 事件。 epoll_wait() 检测到 mWakeEventFd 事件,并立即返回。pollOnce() 遍历 epoll_wait() 返回的就绪事件列表。如果检测到 LOOPER_ID_WAKE 事件(即 mWakeEventFd 被写入),它知道 Looper 被唤醒了,通常意味着有新的消息需要处理。它会读取 eventfd 的值来清除信号。 最后,pollOnce() 调用 mMessageQueue->dispatchMessages(),真正地从消息队列中取出消息,并通过 Handler.dispatchMessage() 分发给相应的 Handler 进行处理。 通过这种方式,在 Native 层构建了一个高效的事件循环。 利用 epoll 集中监听各种 I/O 事件,并用 eventfd 作为轻量级的内部唤醒信号 ,确保了在没有任务时线程可以休眠,而在有任务时能够被迅速、精确地唤醒,从而实现安卓系统流畅且低功耗的响应。
消息发送 插入:Message对象 Message 的实现。 Message 中的 what 是消息的标识符。而 arg1 、 arg2 、 obj 和 data 分别是可以放在消息中的整型数据、Object 类型数据和 Bundle 类型数据。 when 则是消息的发送时间。
sPool 是全局消息池,最多能存放 50 条消息,一般建议用 Message 的 obtain() 方法复用消息池中的消息,而不是自己创建一个新消息。如果在创建完消息后,消息没有被使用,想回收消息占用的内存,可以调用 recycle() 方法回收消息占用的资源。如果消息在 Looper 的 loop() 方法中处理了的话, Looper 就会调用 recycleUnchecked() 方法回收 Message 。
消息发送 当我们用 Handler 的 sendMessage() 、 sendEmptyMessage() 和 post() 等方法发送消息时,首先会创建或者复用一个 Message 对象。这个 Message 对象包含了消息类型、数据以及目标 Handler 等信息。
这几个发送消息的方法最终都会走到 Handler 的 enqueueMessage() 方法。 Handler 的 enqueueMessage() 又会调用 MessageQueue 的 enqueueMessage() 方法。
enqueueMessage() 首先会判断,当没有更多消息、消息不是延时消息、消息的发送时间早于上一条消息 这三个条件其中一个成立时,就会把当前消息作为链表的头节点,然后如果 IdleHandler 都执行完的话,就会调用 nativeWake() JNI 方法唤醒消息轮询线程。
如果上述三个条件都不成立 ,就会遍历消息链表,当遍历到最后一个节点,或者发现了一条早于当前消息的发送时间的消息,就会结束遍历,然后把遍历结束的最后一个节点插入到链表中。如果在遍历链表的过程中发现了一条异步消息,就不会再调用 nativeWake() JNI 方法唤醒消息轮询线程。
这一步可以确定当前发送的消息应该放到消息链表的哪个位置 。
消息处理 从 MessageQueue 中取出消息 一旦 pollOnce() 被唤醒并返回,Native Looper 会调用 Native MessageQueue 的相应方法(例如 next() )。MessageQueue 会:
加锁保护: 同样,在访问消息队列时会进行加锁操作(例如 pthread_mutex_lock),确保线程安全。 遍历链表: 从内部的链表结构中取出最需要处理的那个消息(即 when 值最小且已到期的消息)。 移除消息: 将取出的消息从队列中移除。 解锁: 释放锁。 将 Native 消息转回 Java Message Native Looper 取出 Native Message 对象后,需要将其封装回 Java 层的 Message 对象,以便 Java 层的 Handler 能够理解和处理。这通常通过 JNI 调用来实现,将 Native Message 的数据(如 what, arg1, arg2, obj 指针等)填充到 Java Message 对象中。
派发消息到 Java 层 一旦 Java Message 对象准备好,Native 层会再次通过 JNI 调用 Java Message 对象的 target (也就是 Handler) 的 dispatchMessage() 方法。
// 简化示意,非完整代码
// 在 Native Looper 的 C++ 代码中,执行类似以下的操作
jniEnv -> CallVoidMethod ( javaMessageObj , dispatchMessageMethodID );
dispatchMessage 最后,消息回到了 Java 层,由目标 Handler 的 dispatchMessage() 方法接收。dispatchMessage() 方法会根据消息的 callback (通过 post() 方法发送的 Runnable) 或 what 值,最终调用重写的 handleMessage() 方法来处理具体的业务逻辑。
此前在 Handler 的 enqueueMessage() 方法中,会设置 Message 的 target 为当前 Handler 对象。
Handler 的 dispatchMessage() 方法的优先级顺序:
如果 Message.callback(即 post(Runnable) 的 Runnable)不为空,执行 callback.run()。 如果 Handler.mCallback(Handler 的构造函数传入的 Callback 对象)不为空,调用 mCallback.handleMessage(msg)。 否则调用 Handler.handleMessage(msg)。 经典问题点 postDelay消息是如何实现的? 当你使用 Handler.postDelayed(Runnable r, long delayMillis) 或 Handler.sendMessageDelayed(Message msg, long delayMillis) 发送延时消息时,Handler 机制会利用底层的一些巧妙设计来确保消息在指定的时间后才被处理。其核心在于 消息队列的排序 和 Looper 的休眠/唤醒机制 。
下面我们来深入了解一下 postDelayed 的底层实现原理:
消息的封装与时间戳 当你调用 postDelayed 时,Handler 会创建一个 Message 对象(如果是 postDelayed(Runnable r, ...),Runnable 会被封装到 Message 的 callback 字段中)。这个 Message 对象会被赋予一个关键属性:when
when 字段表示的是消息应该被处理的 绝对时间 ,计算方式是:
when = SystemClock.uptimeMillis() + delayMillis
SystemClock.uptimeMillis():返回系统开机以来的毫秒数,不包括深度睡眠的时间。这是一个稳定的、适合计算延时的时钟源。delayMillis就是你指定的延时时长。
所以,when 字段就存储了这条延时消息的“到期时间”。
消息入队与排序 MessageQueue 并不是一个简单的 FIFO (先进先出)队列,它实际上是一个 有序队列 ,消息会根据它们的 when 值进行插入,确保队列中的消息始终按 when 值从小到大(即按到期时间从早到晚)的顺序排列。
当一个延时消息被发送并准备入队时,MessageQueue 会遍历现有消息,将其插入到正确的位置 ,以保持队列的有序性 。这意味着,到期时间最早的消息总是在队列的头部。
Looper 的休眠与唤醒 这是实现延时消息的关键部分。Looper 在它的无限循环中,会不断地调用 MessageQueue.next() 方法来获取下一个要处理的消息。此方法会检查队列头部的消息。
如果队列头部有消息,并且该消息的 when 值已经小于或等于当前 SystemClock.uptimeMillis()(即消息已到期),那么 next() 方法会立即返回该消息,Looper 会立即处理它。 如果队列头部有消息,但它的 when 值大于当前时间(即消息还未到期),next() 方法会计算一个 nextPollTimeoutMillis nextPollTimeoutMillis = 队列头部消息的when - SystemClock.uptimeMillis()
Native 层的阻塞 :计算出 nextPollTimeoutMillis 后,MessageQueue.next() 会调用到其 Native 层的实现。在 Native 层,Looper 会利用 Linux 内核的 epoll_waitnextPollTimeoutMillis 作为超时参数。
如果 nextPollTimeoutMillis 大于 0 : Looper 线程会进入阻塞状态,最长休眠 nextPollTimeoutMillis 毫秒。这意味着线程会暂停执行,不会消耗 CPU 资源,直到:指定的时间过去(消息到期)。 有新的消息入队(新的消息可能到期时间更早,需要提前唤醒)。 有其他文件描述符事件发生(例如,用户输入、网络数据到达等)。 如果 nextPollTimeoutMillis 小于或等于 0 : 说明队列头部的消息已经到期或没有延时,Looper 会立即返回并处理消息,不会阻塞。唤醒与消息处理 当 Looper 休眠的时间达到 nextPollTimeoutMillis 后,它会自动被系统唤醒(系统直接写eventfd描述符,通过epoll链路通知)。唤醒后,它会再次调用 MessageQueue.next(),此时原先的延时消息应该已经到期,于是被取出并分发处理。
新消息提前唤醒 : 如果在 Looper 休眠期间,有新的消息入队,并且这个新消息的 when 值比当前队列头部消息的 when 值更早(即新消息需要更早处理),或者 Looper 根本就没有休眠,那么 MessageQueue 会通过直接写入数据的方式,立即 唤醒 正在休眠的 Looper 线程。Looper 线程被唤醒后,会重新计算下一次休眠时间,或者直接处理更早到期的消息。
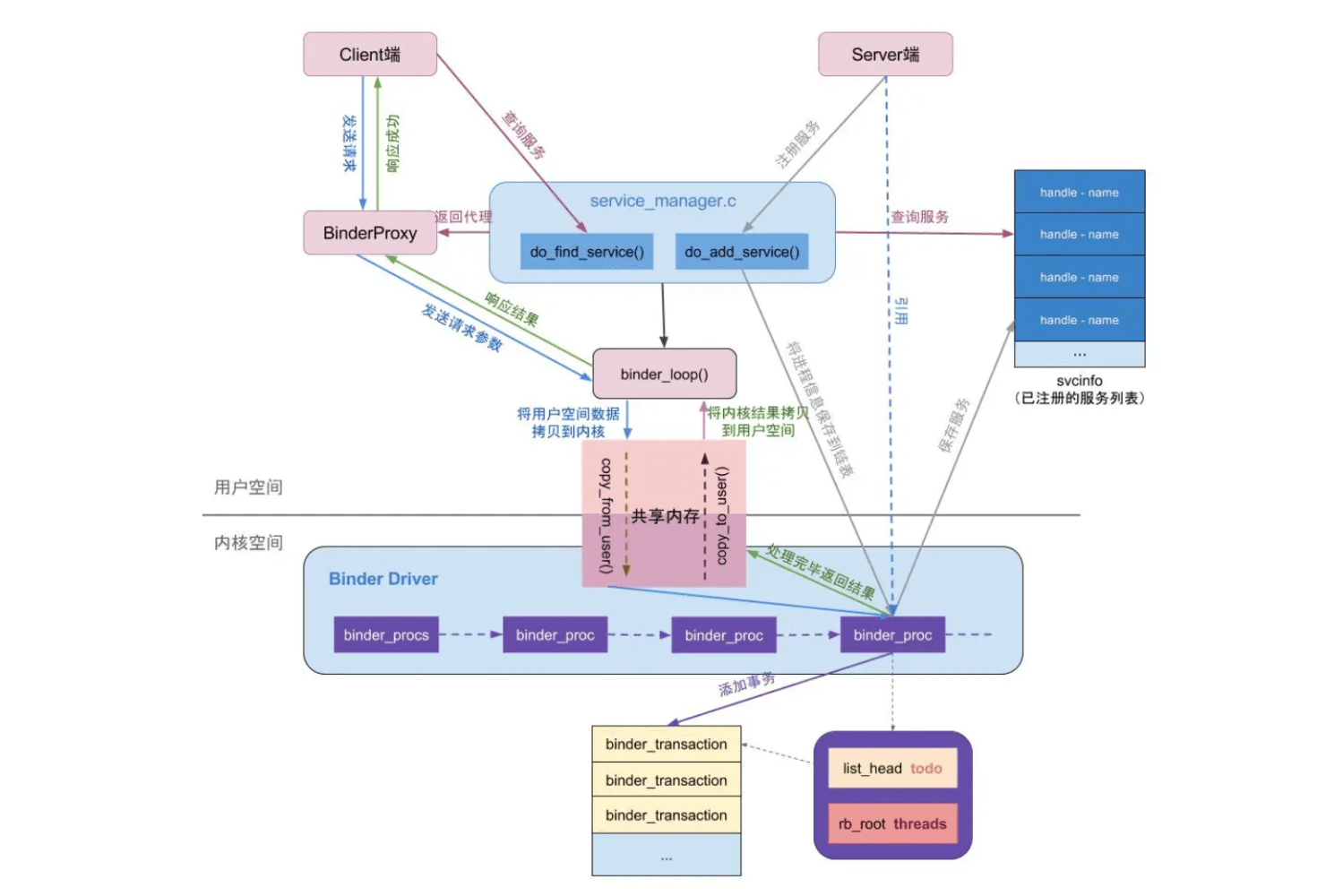
Android Binder 机制是 Android 系统中非常核心的 进程间通信(IPC)机制 ,它在 Android 各种组件之间的通信中扮演着至关重要的角色,比如 App和系统服务之间 的通信、两个App之间 的通信等。理解 Binder 机制是深入学习 Android 系统的重要一步。
此前对于Binder的了解仅仅停留在使用层面 ,没有去了解其背后的原理,现对其更加深入地学习一下,本文将介绍Android Binder机制通信流程和背后的原理。
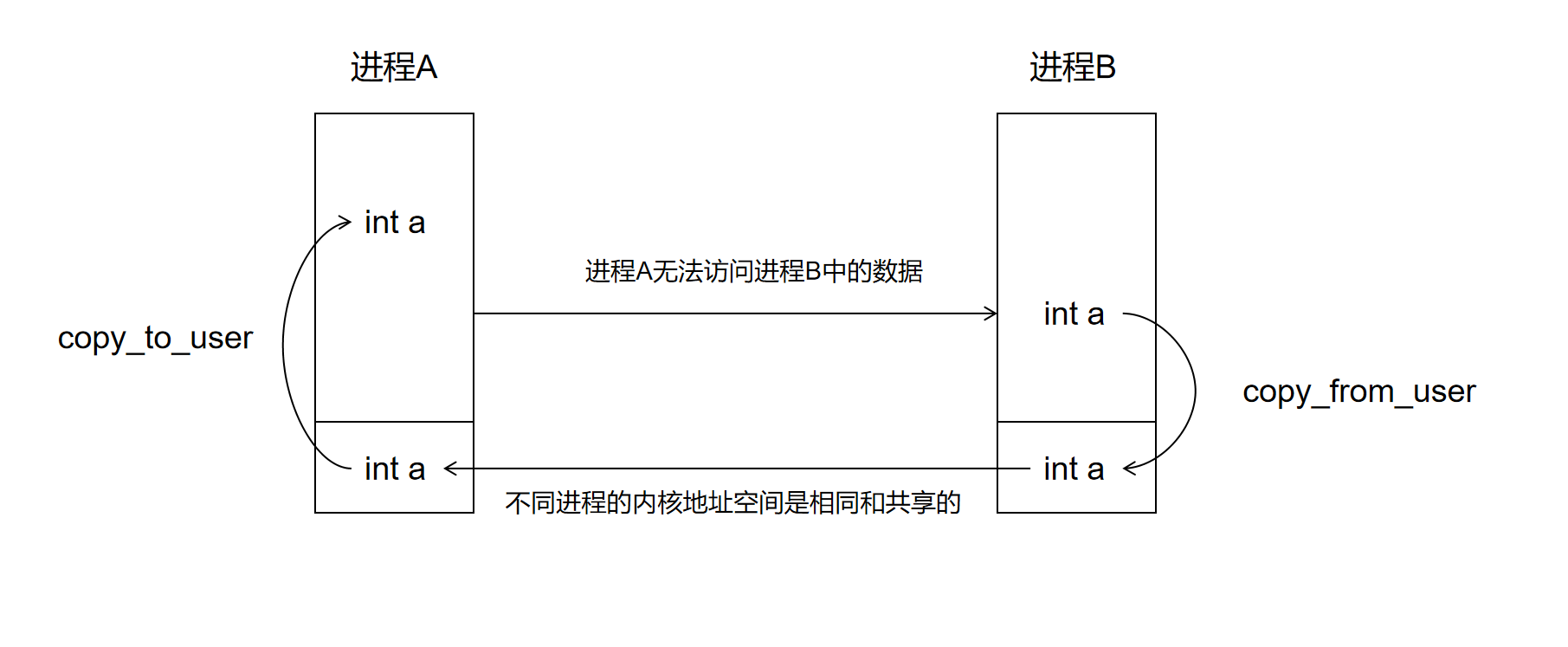
进程间通信需求由来 Android系统是基于Linux系统而开发的,也继承了Linux的 进程隔离机制 。进程之间是无法直接进行交互的,每个进程内部各自的数据无法直接访问。
操作系统层面上,系统为了防止上层进程直接操作系统资源,造成数据安全和系统安全问题,系统内核空间和用户空间也是分离开来的,保证用户程序进程崩溃时不会影响到整个系统。简单的说就是,分离后,内核空间(Kernel)是系统内核运行的空间,用户空间(UserSpace)是用户程序运行的空间。
两个用户空间的进程,要进行数据交互,也需要通过内核空间来驱动整个过程。进程间的通信,即 Inter-Process Communication(IPC) 。
在 Linux 系统中,常见的 IPC 方式有管道、消息队列、共享内存、信号量和Socket 等。然而,Android 并没有直接使用这些机制作为主要的 IPC 方式,而是选择了 Binder。这主要是出于以下几点考虑:
性能优化: Binder 机制在设计上针对移动设备进行了优化,相比 Socket 等方式,其数据拷贝次数更少,效率更高 。传统的 IPC 方式(如管道、消息队列)通常需要两次内存复制 ,而 Binder只需要一次复制 (从用户空间写到内核空间,目标用户空间可以直接通过内核缓冲区读取)。安全性: Binder 机制从底层提供 UID/PID 认证,可以方便地进行权限控制,确保通信的安全性。这对于 Android 这种多应用、多用户环境非常重要。架构优势: Binder 机制基于 C/S (Client/Server) 架构,使得服务提供者和使用者之间解耦,更容易进行系统设计和扩展。内存管理: Binder 机制在内核层实现了内存的映射和管理,能够更好地处理大块数据的传输。内存映射 虽然用户地址空间是不能互相访问的,但是不同进程的内核地址空间是映射到相同物理地址 的,它们是相同和共享的,我们可以借助内核地址空间作为中转站来实现进程间数据的传输。
进程 B 通过 copy_from_user 往内核地址空间里写值,进程 A 通过 copy_to_user 来获取这个值。可以看出为了共享这个数据,需要两个进程拷贝两次数据。
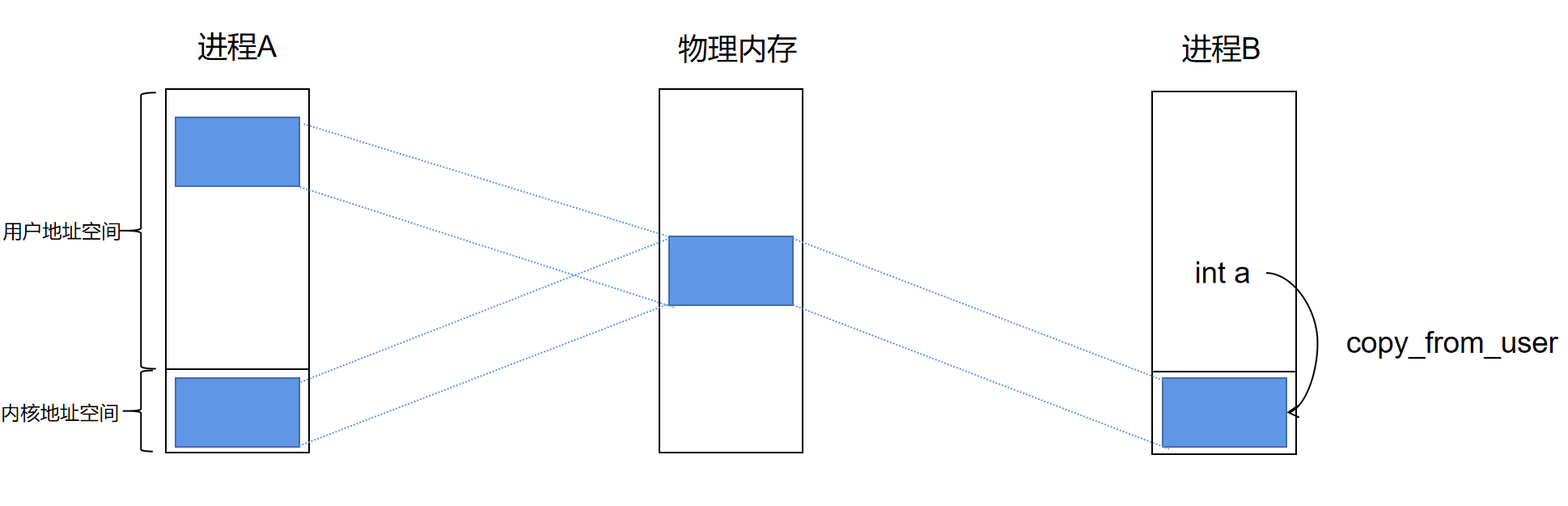
我们可以通过 mmap 将 进程 A 的用户地址空间与内核地址空间进行映射 ,让他们指向相同的物理地址空间,这样就只需要进行一次拷贝。
当进程 B 调用一次 copy_from_user 时,会将数据从用户空间拷贝到内核空间,而进程 A 和这个内核空间映射了同一个物理地址,故进程 A 可以直接使用这个数据,而无需再次拷贝。
Binder通信的内存映射机制 每个使用 Binder 的进程在启动时,会通过 mmap() 系统调用,向 Binder 驱动申请一块内存映射区域。驱动响应这个调用, 在内核空间分配一块物理页面,同时将其映射到该进程的用户空间和内核空间 。这样,每个进程都有自己对应的 Binder 映射缓冲区。
这块内核缓冲区会被 mmap() 映射到该进程的用户空间地址。
通信开始时,客户端进程将要发送的数据(Parcel)写入其用户空间中映射的这块共享内存区域(实际是写入到 Binder 驱动分配的内核缓冲区)。数据从客户端的用户空间拷贝到Binder 驱动的内核缓冲区,这是第一次拷贝。
由于数据已经在内核缓冲区中。Binder 驱动并不需要将数据从内核缓冲区再次拷贝到目标进程的用户空间。驱动程序通过 页表机制(Page Table) 的调整,将内核缓冲区中的数据直接映射到服务端进程的用户空间。
服务端返回数据时同理。
Binder通信过程的四个主要角色 Server,服务的提供者,实现具体的业务逻辑。 Client,客户端, 服务的使用者。 Service Manager ,负责注册和查找服务。当服务端启动 时,会向 Service Manager 注册 自己的 Binder 对象。在客户端需要查找服务时,则通过 Service Manager 获取对应服务的 Binder 代理对象。Binder 驱动,这是整个 Binder 机制的核心,它是 Linux 内核中的一个字符设备驱动程序。它负责完成进程间的数据传输和进程线程的调度。所有 Binder 通信都必须通过 Binder 驱动。Service Manager介绍 ServiceManager 是 Android Binder 进程间通信(IPC)机制的核心组成部分之一。简单来说,它就像一个服务注册中心 或黄页 。当系统中的各种服务(例如 ActivityManagerService、PackageManagerService 等)启动时,它们会将自己注册到 ServiceManager 中 。其他进程如果需要使用这些服务,就可以通过 ServiceManager 查询并获取 到对应的 Binder 代理对象,进而与服务进行通信。
在 Android 早期版本中,ServiceManager 是一个独立的进程,但在现代 Android 版本中,它通常被集成在 init 进程中,作为 servicemanager 可执行文件运行。它监听一个固定的 Binder 端口(通常是 0),作为所有其他 Binder 通信的入口。
它为所有系统服务提供了一个统一的查找和访问入口,简化了服务的管理和调用。在 Android 系统的启动过程中, ServiceManager 是最先启动的核心服务之一,因为它为后续其他关键服务的启动和交互提供了基础。
Binder驱动介绍 Binder 驱动在通信过程中主要扮演了以下几个关键角色:
第一点就是刚刚提到的 分配共享缓冲区 。当任何一个用户进程(客户端或服务端)第一次打开 Binder 设备时,Binder 驱动会通过 mmap() 系统调用,为这个进程在内核中分配一块连续的物理内存作为共享缓冲区 。
驱动程序会将这块内核缓冲区分别映射到该进程的用户空间 。这样,数据在客户端和驱动之间、以及驱动和服务端之间传输时,就可以通过共享内存 机制实现高效的传输。
第二点为路由和转发 ,驱动程序维护着所有使用 Binder 的进程、这些进程中的 Binder 线程池、以及所有 Binder 实体(服务对象)的内部映射表 。
当客户端通过 ioctl() 系统调用向驱动发送请求时,它会携带一个表示目标服务对象的句柄 (Handle) 。驱动程序根据这个句柄,查询内部映射表,精确地找到对应的目标服务端进程 和目标 Binder 实体(Stub) ,然后将请求数据转发给该进程。
第三是线程管理和调度 ,每个服务端进程都会向 Binder 驱动“注册”一组专用于处理 IPC 请求的线程(即 Binder 线程池)。当驱动程序接收到发往某个服务端的请求时,它会唤醒服务端进程中空闲的 Binder 线程,让它去处理这个请求。如果所有 Binder 线程都在忙碌,驱动可能会指示服务端创建 一个新的 Binder 线程来处理请求(直到达到最大线程数限制)。驱动确保每个传入的请求都能被服务端的某个 Binder 线程排队和处理 。
最后一点为安全管理 ,驱动程序在处理事务时,会记录并传递调用进程的 UID/PID 等身份信息。这为上层(如 Android Framework)进行权限检查(例如,判断调用者是否有权限调用某个服务)提供了底层信任的基础数据。
两个关键自动生成类 Stub 和 Proxy aidl接口声明示例文件:
package com.stephen.commondebugdemo ;
interface ICalculateTest {
void setRemoteValue ( int value );
int getRemoteValue ();
}
在定义完了AIDL文件,确定好方法之后,编译器会根据AIDL文件自动生成 Stub 和 Proxy 类。
Stub类 Stub 类是 AIDL 封装机制中的服务端核心 ,它承担了将底层 IPC 机制与上层业务逻辑连接起来的全部工作。它是一个抽象的内部类 ,其完整声明通常是:
public static abstract class Stub extends android . os . Binder implements com . stephen . commondebugdemo . ICalculateTest
可以看到,Stub 类继承自 android.os.Binder,这赋予了它作为 Binder 实体对象 的能力。当服务进程将 Stub 的实现对象注册给 ServiceManager 后,它就代表了服务端的具体功能。当客户端发起 IPC 调用时,请求会直接被路由到这个 Binder 对象上。
实现预定义的 CalculateTest 接口,要求所有继承 Stub 的具体服务类必须实现 AIDL 接口中定义的所有业务方法。
Stub 核心工作:处理客户端请求(onTransact 方法) Stub 类最重要、最复杂的工作就是重写了 Binder 类的 onTransact() 方法 。这是所有远程调用请求进入服务端的唯一入口。
/**
* 处理客户端请求的核心方法。
* @Param code 客户端请求的方法标识符
* @Param data 包含客户端传递过来的方法参数的 `Parcel` 对象。
* @Param reply 用于将服务端方法返回值或异常信息打包回客户端的 `Parcel` 对象。
* @Param flags 用于控制 IPC 调用行为的标志位(例如 `FLAG_ONEWAY` 表示异步调用)。
*
*/
@Override public boolean onTransact (
int code ,
android . os . Parcel data ,
android . os . Parcel reply ,
int flags ) throws android . os . RemoteException
详细代码如下:
@Override
public boolean onTransact ( int code , android . os . Parcel data , android . os . Parcel reply , int flags ) throws android . os . RemoteException {
java . lang . String descriptor = DESCRIPTOR ;
// 检查调用是否来自预期的接口
if ( code >= android . os . IBinder . FIRST_CALL_TRANSACTION && code <= android . os . IBinder . LAST_CALL_TRANSACTION ) {
data . enforceInterface ( descriptor );
}
// 处理特殊的接口查询事务
if ( code == INTERFACE_TRANSACTION ) {
reply . writeString ( descriptor );
return true ;
}
// 处理具体的业务方法调用
switch ( code ) {
case TRANSACTION_setRemoteValue: {
int _arg0 ;
// 从 data 中读取客户端传递的参数 _arg0
_arg0 = data . readInt ();
// 调用服务端内部的 setRemoteValue 方法,将客户端传递的参数 _arg0 设置为服务端的状态
this . setRemoteValue ( _arg0 );
// 写入无异常标志位,通知客户端调用成功
reply . writeNoException ();
break ;
}
case TRANSACTION_getRemoteValue: {
// 获取数据写入到 reply 中
int _result = this . getRemoteValue ();
reply . writeNoException ();
reply . writeInt ( _result );
break ;
}
default : {
return super . onTransact ( code , data , reply , flags );
}
}
return true ;
}
onTransact 方法的工作流如下:
方法识别 (code): 根据传入的 code(一个整数标识符,对应 AIDL 中的方法),判断客户端想调用哪个方法。数据解包 (data): 从输入的 Parcel 对象 (data) 中,按照约定的顺序和类型,逐一读取客户端传递过来的方法参数。调用业务逻辑: 调用开发者在 Stub 子类中实现的对应方法(例如 this.methodA(...))。结果打包 (reply): 将业务方法返回的结果(以及可能的异常信息)写入到输出的 Parcel 对象 (reply) 中。返回结果: reply 对象通过 Binder 驱动回传给客户端进程。Parcel 是 Android 工程师为了解决 IPC 效率问题而专门设计的一种序列化容器 。它牺牲了通用性,换来了极高的性能,成为 Android Binder 机制中不可或缺的基石。在 AIDL 中,Proxy 和 Stub 所做的大量工作,就是围绕 Parcel 的读写来进行的。
asInterface() 连接客户端与服务(asInterface 静态方法)/**
* Cast an IBinder object into an com.stephen.commondebugdemo.ICalculateTest interface,
* generating a proxy if needed.
*/
public static com . stephen . commondebugdemo . ICalculateTest asInterface ( android . os . IBinder obj )
{
if (( obj == null )) {
return null ;
}
android . os . IInterface iin = obj . queryLocalInterface ( DESCRIPTOR );
if ((( iin != null )&&( iin instanceof com . stephen . commondebugdemo . ICalculateTest ))) {
return (( com . stephen . commondebugdemo . ICalculateTest ) iin );
}
return new com . stephen . commondebugdemo . ICalculateTest . Stub . Proxy ( obj );
}
这个方法是客户端获取服务端代理对象的桥梁 。客户端通过 ServiceConnection 的 onServiceConnected() 拿到一个原始的 IBinder 对象。
如果传入的 obj 是一个 Stub 实例(即客户端和服务端在同一个进程),则直接返回这个 Stub 实例本身。
远程调用 (跨进程),如果传入的 obj 来自另一个进程,它会创建并返回一个 Proxy 代理对象 ,将这个远程 IBinder 封装起来。
这样,客户端调用者无需关心目标对象是否在本地,只需调用 asInterface() 即可得到一个统一的 IMyAidlInterface 接口对象。
服务端使用Stub的示例代码 class CalculateTestService : Service () {
private var internalTestValue = 0
private val binder = object : CalculateTest . Stub () {
override fun setRemoteValue ( value : Int ) {
internalTestValue = value
}
override fun getRemoteValue (): Int {
return internalTestValue
}
}
override fun onBind ( intent : Intent ) = binder
}
Proxy类 Proxy 类是 AIDL 封装机制中的客户端核心 ,它负责将客户端对接口方法的调用,转化为底层 Binder 机制所需的 IPC 请求。
它通常是 Stub 类内部的一个静态私有子类,其结构通常是下面这样,实现了所定义的AIDL服务接口。
private static class Proxy implements com . stephen . commondebugdemo . ICalculateTest {
private android . os . IBinder mRemote ;
Proxy ( android . os . IBinder remote ) {
mRemote = remote ;
}
@Override
public android . os . IBinder asBinder () {
return mRemote ;
}
public java . lang . String getInterfaceDescriptor () {
return DESCRIPTOR ;
}
...
}
它的核心工作可以分为以下几个方面:
结构与初始化:持有远程引用 实现 ICalculateTest 接口,这使得 Proxy 实例可以被客户端代码当作真正的 AIDL 接口对象来调用,从而实现了透明代理 。
Proxy 持有 IBinder 对象 (mRemote字段)。这个 IBinder 对象是客户端通过 ServiceConnection 类,在服务连接成功后,调用 asInterface() 传入构造函数的。它代表了服务端的那个真正的 Stub 实体在客户端进程中的引用(Binder Token) 。所有的 IPC 通信都是通过这个 mRemote 对象进行的。
核心工作:发起远程调用(transact 方法) Proxy 类实现了 AIDL 接口中定义的所有方法,但这些实现方法的内部是统一的 IPC 封装逻辑 ,直接调用 transact() 方法。
例如 setRemoteValue() :
@Override
public void setRemoteValue ( int value ) throws android . os . RemoteException {
// 后面将方法参数写入 _data 中
android . os . Parcel _data = android . os . Parcel . obtain ();
// 从reply中读取异常信息和返回值
android . os . Parcel _reply = android . os . Parcel . obtain ();
try {
_data . writeInterfaceToken ( DESCRIPTOR );
_data . writeInt ( value );
boolean _status = mRemote . transact ( Stub . TRANSACTION_setRemoteValue , _data , _reply , 0 );
_reply . readException ();
} finally {
// 回收 Parcel 对象
_reply . recycle ();
_data . recycle ();
}
}
各实现方法简单来说就是数据的打包和发送。等待服务端处理完毕后,从返回的 Parcel 中读取服务端的执行结果(返回值或异常信息)。
辅助验证方法 getInterfaceDescriptor getInterfaceDescriptor()
客户端获取AIDL服务实例代码 object ClientProxy {
private lateinit var calculateTest : ICalculateTest
private val serviceConnection = object : ServiceConnection {
override fun onServiceConnected (
name : ComponentName ?,
service : IBinder ?
) {
calculateTest = ICalculateTest . Stub . asInterface ( service )
}
override fun onServiceDisconnected ( name : ComponentName ?) {
infoLog ( "onServiceDisconnected" )
}
}
.. .
// connect and call methods
}
Binder通信简化流程 通信架构示意图:
Binder 通信的流程可以分为以下几步:
注册服务: Server 服务端 在启动时,会向 Service Manager 注册自己提供的服务及其对应的 Binder 对象。这个注册过程其实也是一次 Binder 通信,Server 作为 Client 向 Service Manager 发送注册请求。 获取服务: Client 端 (例如:某个 App)需要使用某个服务时,会通过 Service Manager 查询对应的服务,获取其 Binder 代理对象。这个获取过程也是一次 Binder 通信,Client 作为 Client 向 Service Manager 发送查询请求。 Client 调用服务: Client 获取到服务的 Binder 代理对象后,就可以通过这个代理对象调用服务端的具体方法。 当 Client 调用代理对象的方法时,实际是把请求数据打包(marshalling )并通过 Binder 驱动 发送给 Server 端。 Binder 驱动将数据从 Client 进程的用户空间拷贝到内核空间,然后根据目标进程的 Binder 对象,再将数据从内核空间映射到 Server 进程的用户空间。 Server 端收到请求后,会解包(unmarshalling )数据,然后执行对应的服务方法,并将结果返回给 Client。这个返回过程也是通过 Binder 驱动进行的。 一般来说,Client 进程访问 Server 进程函数,我们需要在 Client 进程中 按照固定的规则打包数据 ,这些数据包含了:
数据发给哪个进程,Binder 中是一个整型变量 Handle 要调用目标进程中的那个函数,Binder 中用一个整型变量 Code 表示目标函数的参数 要执行具体什么操作,也就是 Binder 协议 Client 进程通过 IPC 机制将数据传输给 Server 进程。当 Server 进程收到数据,按照固定的格式解析出数据,调用函数,并使用相同的格式将函数的返回值传递给 Client 进程。
通信关系图:
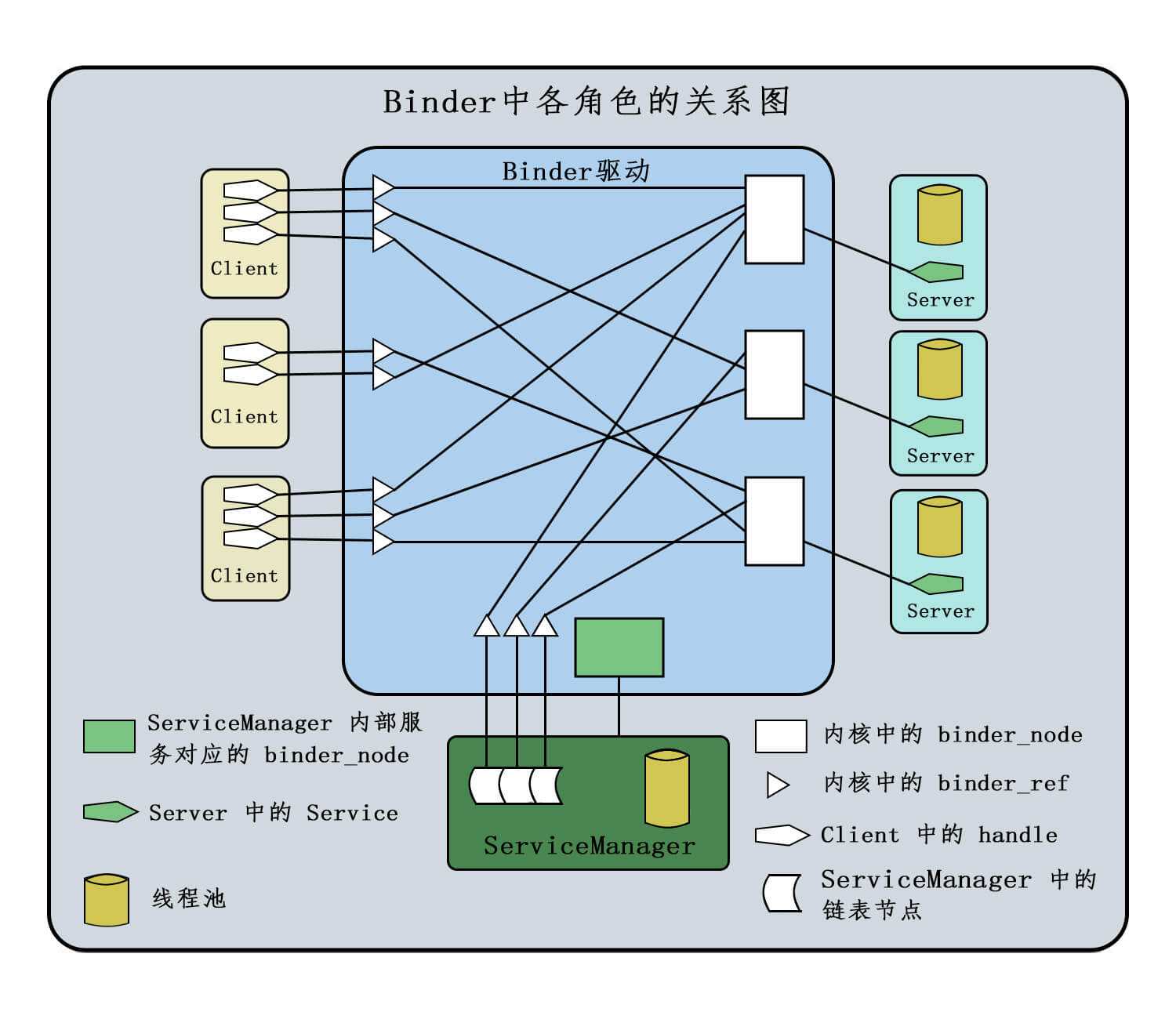
binder_node binder_node 是应用层的 service 在内核中的存在形式 ,是内核中对应用层 service 的描述,在内核中具体表现为 binder_node 结构体。
在上图中,ServiceManager 在 Binder 驱动中有对应的的一个 binder_node(Binder 实体) 。
每个 Server 在 Binder 驱动中也有对应的的一个 binder_node(Binder 实体) 。
这里假设每个 Server 内部仅有一个 service,内核中就只有一个对应的 binder_node(Binder 实体),实际可能存在多个。
binder_node 结构体中存在一个指针 struct binder_proc *proc; ,指向 binder_node 对应的 binder_proc 结构体。
// binder_node 是内核中对应用层 binder 服务的描述
struct binder_node {
//......
struct binder_proc * proc ;
//......
}
binder_proc binder_proc 是内核中对应用层进程 的描述,内部有众多重要数据结构。
// binder_proc 是内核中对应用层进程的描述
struct binder_proc {
//......
struct binder_context * context ;
//......
}
binder_ref(Binder 引用) 所谓 binder_ref(Binder 引用) ,实际上是内核中 binder_ref 结构体的对象,它的作用是在表示 binder_node(Binder 实体) 的引用。
换句话说,每一个 binder_ref(Binder 引用) 都是某一个 binder_node (Binder实体)的引用 ,通过 binder_ref(Binder 引用) 可以在内核中找到它对应的 binder_node(Binder 实体)。
寻址 Binder 是一个 RPC 框架,最少会涉及两个进程。那么就涉及到寻址问题,所谓寻址就是当 A 进程需要调用 B 进程中的函数时,怎么找到 B 进程。
Binder 中寻址分为两种情况:
ServiceManager 寻址,即 Client/Server 怎么找到 ServiceManager,对应于内核,就是找到 ServiceManager 对应的 binder_proc 结构体实例 Server 寻址,即 Client 怎么找到 Server,对应于内核,就是找到 Server 对应的 binder_proc 结构体实例 如何找到ServiceManager 系统启动时,Service Manager 启动并注册自身:
在 Android 系统启动初期,servicemanager 进程(一个守护进程)会首先启动。 它会打开 /dev/binder 设备文件,获取一个文件描述符 (fd)。 *然后,它会通过一个特殊的 ioctl 系统调用 BINDER_SET_CONTEXT_MGR 将自己注册为 Binder 驱动的 “上下文管理器” 。这个操作会告诉 Binder 驱动,Service Manager 是那个负责管理所有其他 Binder 服务的特殊实体。 在这个注册过程中,Binder 驱动会为 Service Manager 分配句柄 0。从此以后,Service Manager 就成为了 Binder 驱动中唯一拥有句柄 0 的实体 。 每个使用 binder 的进程,在初始化时,会在内核中将 binder_device 的 context 成员赋值给 binder_proc->context 。
binder_proc -> context = binder_device -> context ;
binder_device 指的是 Binder 驱动程序在 Linux 内核中提供的设备文件,而 binder_device是全局唯一变量,这样的话,所有进程的 binder_proc->context 都指向同一个结构体实例。
当 ServiceManager 调用 binder_become_context_manager 后,会陷入内核,在内核中会构建一个 binder_node 结构体实例,构建好以后,会将他保存到 binder_proc->context->binder_context_mgr_node 中。
也就是说,任何时候我们都可以通过 binder_proc->context->binder_context_mgr_node 获得 ServiceManager 对应的 binder_node 结构体实例。 binder_node 结构体中有一个成员 struct binder_proc *proc;,通过这个成员我们就能找到 ServiceManager 对应的 binder_proc.
当任何其他 Binder 进程(Client 或 Server,在向 Service Manager 注册服务时,它也充当 Service Manager 的 Client)需要与 Service Manager 通信时,它们并不需要“查找” Service Manager。
它们可以直接通过 Binder 框架提供的 API 获取一个代表 Service Manager 的 IBinder 代理对象 。 这个代理对象内部封装的 Binder 句柄值就是 0。
如何找到Server 服务注册阶段 Server 端向 ServiceManager 发起注册服务请求 时(svcmgr_publish),会陷入内核,首先通过 ServiceManager 寻址方式找到 ServiceManager 对应的 binder_proc 结构体,然后在内核中构建一个代表待注册服务的 binder_node 结构体实例,并插入服务端对应的 binder_proc->nodes 红黑树中 。
接着会构建一个 binder_ref 结构体 , binder_ref 会引用到上一阶段构建的 binder_node ,并插入到 ServiceManager 对应的 binder_proc->refs_by_desc 红黑树 中,同时会计算出一个 desc 值(1,2,3 ….依次赋值)保存在 binder_ref 中。
最后服务相关的信息(主要是名字和 desc 值)会传递给 ServiceManager 应用层,应用层通过一个链表将这些信息保存起来。
服务获取阶段 Client 端向 ServiceManager 发起获取服务请求时(svcmgr_lookup,请求的数据中包含服务的名字),会陷入内核, 通过 binder_proc->context->binder_context_mgr_node 寻址到 ServiceManager,接着通过分配映射内存,拷贝数据后,将 “获取服务请求” 的数据发送给 ServiceManager 。
ServiceManager 应用层收到数据后,会遍历内部的链表 ,通过传递过来的 name 参数,找到对应的 handle,然后将数据返回给 Client 端,接着陷入内核,通过 handle 值在 ServiceManager 对应的 binder_proc->refs_by_desc 红黑树中查找到服务对应 binder_ref ,接着通过 binder_ref 内部指针找到服务对应的 binder_node 结构。
接着 创建出一个新的 binder_ref 结构体 实例,内部 node 指针指向刚刚找到的服务端的 binder_node,接着再 将 binder_ref 插入到 Client 端的 binder_proc->refs_by_desc ,并计算出一个 desc 值(1,2,3 ….依次赋值),保存到 binder_ref 中。desc 值也会返回给 Client 的应用层。
Client 应用层收到内核返回的这个 desc 值,改名为 handle ,接着向 Server 发起远程调用,远程调用的数据包中包含有 handle 值,接着陷入内核,在内核中首先根据 handle 值在 Client 的 binder_proc->refs_by_desc 获取到 binder_ref ,通过 binder_ref 内部 node 指针找到目标服务对应的 binder_node,然后通过 binder_node 内部的 proc 指针找到目标进程的 binder_proc ,这样就完成了整个寻址过程。
oneway机制 简单来说,oneway 是一种异步调用机制。当你通过Binder调用远程进程中的方法时,如果该方法被标记为 oneway,那么:
调用者(Client)会立即返回,而不会等待被调用者(Server)执行完方法并返回结果。 调用请求会被发送到远程进程,但调用者线程不会被阻塞。 被调用者(Server)会在一个单独的Binder线程池中处理这个 oneway 请求。 这意味着 oneway 调用不会阻塞服务端的UI线程或其他重要线程。 oneway 方法不能有返回值。 因为调用者不会等待结果,所以也就没有返回值的意义。如果需要执行结果,可以设置一个callback。
在声明AIDL接口时,将返回值类型设置为oneway既可。
// IMyService.aidl
package com.example.myapp ;
interface IMyService {
// 同步方法,会等待返回值
int add ( int a , int b );
// oneway 方法,客户端不会等待其执行完成
oneway void doSomethingAsync ( String message );
// 如果整个接口都是oneway的,也可以直接在接口前面声明
// oneway interface IAnotherService {
// void notifyEvent(int eventCode);
// }
}
Binder 通信大小限制 Binder 调用中同步调用优先级大于 oneway(异步)的调用,为了充分满足同步调用的内存需要,所以将 oneway 调用的内存限制到申请内存上限的一半。
Android系统 中大部分IPC场景是使用 Binder 作为通信方式,在进程创建的时候会为 Binder 创建一个1M 左右的缓冲区用于跨进程通信时的数据传输,如果超过这个上限就就会抛出这个异常,而且这个缓存区时当前进程内的所有线程共享的,线程最大数量为16(线程池 15 个子线程 + 1 个主线程)个,如同时间内总传输大小超过了1M,也会抛异常。
另外在 Activity 启动的场景比较特殊,因为 Binder 的通信方式为两种,一种是异步通信,一种是同步通信,异步通信时数据缓冲区大小被设置为了原本的1半。
Material Design(材料设计) 是由 Google 在 2014 年推出的设计语言,旨在为多平台(包括移动端、Web、桌面端等)提供统一、直观且具有物理感的视觉与交互体验。它融合了现实世界的物理规律(如阴影、层次感)与数字交互的灵活性,强调“材料”作为设计的基本单元,通过清晰的视觉层次、响应式动画和一致的交互逻辑,提升用户对产品的认知效率与情感共鸣。
目前已经不仅仅在 Android 系统上应用,还扩展至 Web(Material Web)、Flutter(跨平台开发框架)、iOS(通过 Material Components for iOS)等平台,实现真正的“一次设计,多端适配”。
共推出过三个大版本:
Material Design 1.0(2014) :奠定基础,强调卡片、阴影和动效。Material Design 2.0(2018,Material Theming) :引入动态主题(Dynamic Color),支持品牌个性化定制。Material Design 3(2021,Material You) :以用户为中心的设计,核心是“自适应色彩”(用户可基于壁纸提取主色,系统自动适配界面配色),增强个性化与无障碍体验。Google 提供了丰富的设计资源(如 Material Design Guidelines 、Figma 组件库),开发者社区(如 GitHub)也有大量开源实现。
对于设计师,设计工具诸如 Adobe XD、Sketch等,也可以集成 Material 插件,支持快速原型设计。
Material Design以其统一的设计语言降低开发与设计成本,提升跨团队协作效率。同时,自适应设计与动态主题的特点,可以满足多设备、个性化需求。
但是,也有一大部分设计师和开发者认为其规范过于严格,可能限制创新设计。而且过度依赖阴影和层次感可能导致界面视觉复杂度增加(尤其在低配设备上)。
一、核心理念:数字世界的“材料”隐喻 Material Design 的核心是将数字界面类比为现实世界中的“材料”(如纸张、墨水),但赋予其数字化特性(如无限延展性、动态响应)。这种隐喻并非追求完全模拟物理世界,而是通过“材料”的抽象化表达(如阴影表示层次、颜色传递状态),让用户快速理解界面元素的逻辑关系,降低认知成本。
二、设计原则:四大支柱 真实感与层次感(Material as Metaphor) 以“材料”为基本单元,通过阴影深度(elevation)表现元素的层级关系(如卡片浮于背景之上)。 颜色、形状和动效模拟现实中的光影变化,增强界面的物理真实感,但避免过度拟物化。 直观的动效(Bold, Graphic, Intentional) 动效不仅是装饰,而是传递信息的工具。例如,按钮点击时的微缩反馈、页面切换时的滑动过渡,均需明确提示用户操作结果。 动效需符合物理规律(如惯性、缓动),避免突兀变化。 响应式交互(Motion Provides Meaning) 界面元素需对用户操作(点击、滑动、拖拽)做出即时反馈,例如输入框获得焦点时的放大效果、列表项拖动时的实时位置更新。 动效需引导用户注意力,帮助理解界面状态的变化(如加载中的进度指示)。 跨平台一致性(Adaptive Design) 通过统一的视觉语言(颜色、排版、图标)和交互模式,确保在不同设备(手机、平板、桌面、可穿戴设备)和场景(横屏、竖屏、暗黑模式)下保持体验连贯性。 支持自适应布局,根据屏幕尺寸动态调整组件排列(如网格系统的灵活适配)。 三、关键设计元素 材料(Material Surfaces) 界面由多层“材料”构成,每层具有独立的阴影深度(elevation),通过阴影差表现叠加关系(如对话框浮于卡片之上)。 材料可伸缩、变形,但不可穿透(遵循现实世界的物理规则)。 颜色与排版 颜色 :以主色(Primary Color)和强调色(Accent Color)为核心,搭配中性色(黑白灰)构建层次。Google 提供了一套标准色板(如 Material Color System),支持动态配色(Dark Theme)。排版 :基于 Roboto 字体(后扩展至其他开源字体),通过字号、字重(Bold/Light)和行高构建清晰的文本层级,确保可读性与信息密度平衡。图标与图形 使用线性图标(Material Icons)和填充图标,强调简洁性与符号化表达。图标需符合用户认知习惯(如“菜单”用三条横线表示)。 图形设计注重几何形状(圆形、矩形)的组合,通过圆角、边框和阴影增强视觉层次。 动效系统(Motion System) 容器变换(Container Transform) :元素变形时保持视觉连续性(如卡片展开为详情页)。共享轴(Shared Axis) :通过共用的运动方向(如左右滑动切换标签页)传递元素关联性。淡入淡出(Fade) :用于非关联元素的切换(如提示信息消失)。Google 提供了 Lottie 等工具支持复杂动效的实现。 四、应用场景与组件库 Material Design 提供了一套完整的组件库(Material Components),涵盖常用 UI 元素的设计规范与代码实现,开发者可直接调用。核心组件包括:
导航 :底部导航栏(Bottom Navigation)、抽屉菜单(Drawer)、顶部应用栏(AppBar)。输入与反馈 :文本框(Text Field)、按钮(Button)、滑块(Slider)、对话框(Dialog)、Snackbar(轻量提示)。数据展示 :卡片(Card)、列表(List)、网格(Grid)、表格(Table)、图表(Charts)。高级组件 :底部表单(Bottom Sheets)、模态抽屉(Modal Drawer)、悬浮操作按钮(FAB)。这些组件均遵循设计规范,支持跨平台适配(Android、iOS、Web),开发者可通过 Material Components 库(如 Android 的 Material Components for Android、Web 的 Material UI)快速集成。
Compose项目使用 Material Design 的官网也可以自己选取设计元素,作为一个压缩包下载下来,里面有Color,Style等文件,放到项目中就可以直接使用。
也可以一步步地自己配置每一个参数的色值,集成 ColorScheme 即可。内部可配置的参数非常多,根据名字也可以猜到其使用场景。
@Immutable
class ColorScheme (
val primary : Color ,
val onPrimary : Color ,
val primaryContainer : Color ,
val onPrimaryContainer : Color ,
val inversePrimary : Color ,
val secondary : Color ,
val onSecondary : Color ,
val secondaryContainer : Color ,
val onSecondaryContainer : Color ,
val tertiary : Color ,
val onTertiary : Color ,
val tertiaryContainer : Color ,
val onTertiaryContainer : Color ,
val background : Color ,
val onBackground : Color ,
val surface : Color ,
val onSurface : Color ,
val surfaceVariant : Color ,
val onSurfaceVariant : Color ,
val surfaceTint : Color ,
val inverseSurface : Color ,
val inverseOnSurface : Color ,
val error : Color ,
val onError : Color ,
val errorContainer : Color ,
val onErrorContainer : Color ,
val outline : Color ,
val outlineVariant : Color ,
val scrim : Color ,
val surfaceBright : Color ,
val surfaceDim : Color ,
val surfaceContainer : Color ,
val surfaceContainerHigh : Color ,
val surfaceContainerHighest : Color ,
val surfaceContainerLow : Color ,
val surfaceContainerLowest : Color ,
)
ColorScheme 类定义了 MaterialTheme 里所有命名颜色参数,这些参数在设计应用界面时,用于确保颜色和谐、文字可读,并且能区分不同的 UI 元素和表面。
主要颜色相关 primary:主色,在应用的屏幕和组件里出现频率最高的颜色。 onPrimary:主色上显示的文字和图标的颜色。 primaryContainer:容器首选的色调颜色。 onPrimaryContainer:显示在 primaryContainer 之上的内容颜色(及其状态变体)。 inversePrimary:在需要反色方案的地方作为“主色”使用的颜色,例如 SnackBar 上的按钮。 次要颜色相关 secondary:次要颜色,用于突出和区分产品,适用于浮动操作按钮、选择控件、高亮选中文本、链接和标题等。 onSecondary:次要颜色上显示的文字和图标的颜色。 secondaryContainer:用于容器的色调颜色。 onSecondaryContainer:显示在 secondaryContainer 之上的内容颜色(及其状态变体)。 第三颜色相关 tertiary:第三颜色,可用于平衡主色和次要颜色,或突出显示输入框等元素。 onTertiary:第三颜色上显示的文字和图标的颜色。 tertiaryContainer:用于容器的色调颜色。 onTertiaryContainer:显示在 tertiaryContainer 之上的内容颜色(及其状态变体)。 背景和表面颜色相关 background:可滚动内容后面显示的背景颜色。 onBackground:背景颜色上显示的文字和图标的颜色。 surface:影响组件表面(如卡片、工作表和菜单)的颜色。 onSurface:表面颜色上显示的文字和图标的颜色。 surfaceVariant:与 surface 用途类似的另一种颜色选项。 onSurfaceVariant:可用于 surface 之上内容的颜色(及其状态变体)。 surfaceTint:用于应用色调高程的组件,叠加在 surface 之上。高程越高,该颜色的使用比例越大。 inverseSurface:与 surface 形成强烈对比的颜色,适用于位于 surface 颜色表面之上的表面。 inverseOnSurface:与 inverseSurface 对比度良好的颜色,适用于位于 inverseSurface 容器之上的内容。 错误颜色相关 error:错误颜色,用于指示组件中的错误,例如文本字段中的无效文本。 onError:错误颜色上显示的文字和图标的颜色。 errorContainer:错误容器首选的色调颜色。 onErrorContainer:显示在 errorContainer 之上的内容颜色(及其状态变体)。 边框和遮罩颜色相关 outline:用于边界的微妙颜色,为了可访问性增加对比度。 outlineVariant:用于装饰元素边界的实用颜色,在不需要强对比度时使用。 scrim:遮挡内容的遮罩颜色。 表面变体颜色相关 surfaceBright:surface 的变体,无论在浅色还是深色模式下,始终比 surface 亮。 surfaceDim:surface 的变体,无论在浅色还是深色模式下,始终比 surface 暗。 surfaceContainer:影响组件容器(如卡片、工作表和菜单)的 surface 变体。 surfaceContainerHigh:比 surfaceContainer 强调程度更高的容器 surface 变体,用于需要更多强调的内容。 surfaceContainerHighest:比 surfaceContainerHigh 强调程度更高的容器 surface 变体,用于需要更多强调的内容。 surfaceContainerLow:比 surfaceContainer 强调程度更低的容器 surface 变体,用于需要较少强调的内容。 surfaceContainerLowest:比 surfaceContainerLow 强调程度更低的容器 surface 变体,用于需要较少强调的内容。 使用colorscheme 一般来说,如果只要求适配系统自带的深浅两色,可以直接使用 darkColorScheme() 和 lightColorScheme() 这两个顶层方法创建即可,配置好其中需要的各个参数。
例如:
val DarkColorScheme = darkColorScheme (
primary = Color ( 0xff484848 ),
background = Color ( 0xFF010101 ),
surface = Color ( 0xff303030 ),
surfaceVariant = Color ( 0xff1d1d1d ),
onPrimary = Color ( 0xffffffff ),
secondary = Color ( 0xFF1a1a1a ),
tertiary = Color ( 0xff3d77c2 ),
onSecondary = Color ( 0x99ffffff ),
error = Color ( 0x99e53c3c ),
errorContainer = Color ( 0xcce53c3c ),
onBackground = Color ( 0xff323232 ),
onSurface = Color ( 0xff404040 ),
)
传到 MaterialTheme 可组合项内:
MaterialTheme (
colorScheme = when ( themeState . value ) {
ThemeState . DARK -> DarkColorScheme
ThemeState . LIGHT -> LightColorScheme
else -> if ( isSystemInDarkTheme ()) DarkColorScheme else LightColorScheme
}
) {
// ...
}
如果需要自定义颜色,或者需要适配更多的颜色,也可以使用 ColorScheme 类。
切换主题时,动态更改 MaterialTheme 的参数,触发其重组,内部的所有子可组合项就会跟随刷新自己的样式。
在Android 8 及以后,可以使用 WallpaperManager 来获取壁纸的主颜色,应用到自己APP的界面上,下面是一段简单的测试代码。(应用版本低,使用的不是Material3)
object WallPagerThemeManager {
private lateinit var wallpaperManager : WallpaperManager
private var wallpaperColors : WallpaperColors ? = null
var DynamicColorScheme = darkColors ()
fun init () {
wallpaperManager = WallpaperManager . getInstance ( appContext )
wallpaperColors = wallpaperManager . getWallpaperColors ( WallpaperManager . FLAG_SYSTEM )
val primaryColor = wallpaperColors ?. primaryColor ?. toArgb ()
val secondaryColor = wallpaperColors ?. secondaryColor ?. toArgb ()
primaryColor ?. let {
DynamicColorScheme = darkColors (
primary = Color ( it ),
secondary = Color ( secondaryColor ?: it ),
)
}
}
}
我入行的时候,手机端最新版本是Android 13,车机使用的是Android 11。
而今年2025年都出到16预览版了,看到掘金上有一个总结性的帖子,基于这一篇来扩展下,回顾下有哪些重点特性改动:
Android 各个版本的新增特性
Android 5.0 Lollipop (API 21 & 22) Material Design 在设计语言上引入了Material Design,这是一种全新的视觉、运动和交互设计规范,旨在为用户提供直观且一致的体验。全新的用户界面,色彩鲜明,动画流畅,阴影和层级感更强。
Android Runtime (ART) 默认运行时从 Dalvik 切换到 ART (Android Runtime),带来更好的应用性能和更长的电池续航。ART 的新功能有:
预先 (AOT) 编译 改进的垃圾回收 (GC) 改进的调试支持 通知改进 在 Android 5中,通知可以在锁屏时出现,同时来电等重要通知提醒会显示在浮动通知中,这是一个小浮动窗口,让用户无需离开当前应用即可响应或关闭通知。对于媒体播放和通知跳转等功能增加了 Notification.MediaStyle 模块。
“概览”屏幕 支持了显示多个来做同一个应用的activity。“最近使用的应用”屏幕,也称为“概览”屏幕,表示近期任务 或“最近用过的应用”屏幕,这是系统级界面,其中会列出 activity 和 tasks。 用户可以浏览列表、选择某个任务 恢复任务,或者通过滑开任务将其从列表中移除。
在 Android 5 中,我们可以通过 documentLaunchMode 属性来让最近屏幕显示多个来做同一个应用的activity。如上图所示,Google 云端硬盘应用的两个 Activity 显示在最近屏幕上,并且每个 Activity 展示不同的内容。
Android NDK 支持 64 位支持 Android 5.0 引入了对 64 位系统的支持。64 位增强功能可增加地址空间并提升性能,同时仍完全支持现有的 32 位应用。
OpenGL ES 3.1 的支持 Android 5.0 添加了 Java 接口和对 OpenGL ES 3.1 的原生支持。
引入了新的 Camera2 API Android 5.0 引入了新的 android.hardware.camera2 API 来简化精细照片采集和图像处理。
多用户支持(平板电脑) 允许在同一设备上创建多个用户配置文件。还有访客模式,方便他人临时使用你的设备。
Android 6 Marshmallow (API 23) 运行时权限 应用不再在安装时请求所有权限,而是在需要时向用户动态请求。用户可以在运行时授予或拒绝权限。checkSelfPermission() 方法用来确定应用是否已获得权限; requestPermissions() 方法用于请求权限。即使应用并不以 Android 6.0(API 级别 23)为目标平台,我们也应该在新权限模式下测试应用。
休眠(Doze)模式和应用待机模式 在 Android 6.0 开始引入了两项省电功能,分别是休眠和应用待机。其中休眠是针对系统的,触发条件是设备静止、屏幕关闭、未连接电源;而应用待机则是针对应用的,触发条件是当用户有一段时间未触摸应用。
在休眠(Doze)模式下,系统会尝试通过限制应用对网络和 CPU 密集型服务的访问来节省电量。它还会阻止应用访问网络,并延迟其作业、同步和标准闹钟。
这两个措施可以优化电池续航,当设备长时间处于静止状态时,Doze 模式会降低后台活动;App Standby 则限制不常用应用的后台活动。
支持文本选择 当用户在应用中选择文本时,可以在浮动工具栏中显示文本选择操作。
指纹身份验证 Android 6 中引入了指纹认证API,提供标准化的指纹识别支持。该 api 的相关示例可以见 BiometricAuthentication
USB Type-C 支持 官方支持 USB Type-C 接口。
Google Now on Tap 长按 Home 键即可根据屏幕内容提供相关信息。
Android 7 Nougat (API 24 & 25) Android 7.0 Nougat 提升了多任务处理能力和通知系统,并引入了 Vulkan API。
多窗口支持 在 Android 7中,引入了多窗口的支持,允许用户屏幕上同时弹出两个应用。(Multi-window)
增强了通知的功能 在 Android 7中重新设计了通知,让其变得更简单。更新功能有:
直接回复,可以添加直接在通知中回复消息或输入其他文字的操作。 系统可以将消息分组 (例如按消息主题),以及显示相应群组 重新设置了通知模板样式 加强了休眠模式 Doze on the Go 在 Android 6中,需要设备处于静止状态才会进入休眠模式。而在 Android 7中,只要屏幕关闭一段时间且设备未接通电源,就会进入休眠模式,并对应用施加 CPU 和网络限制。 这意味着,即使用户随身携带设备,也可以节省电量 。
移除 CONNECTIVITY_ACTION、ACTION_NEW_PICTURE 和 ACTION_NEW_VIDEO 三个隐式广播 后台进程可能会耗费大量内存和电池电量。例如,某一隐式广播可能会启动许多已注册监听它的后台进程,即使这些进程可能并没有执行很多任务。这会对设备性能和用户体验产生重大影响。
因此在 Android 7 中移除了 CONNECTIVITY_ACTION(用于通知网络连接状态的变化)、ACTION_NEW_PICTURE(用于通知新图片的添加) 和 ACTION_NEW_VIDEO(用于通知新视频的添加) 这三个隐式广播。其中 CONNECTIVITY_ACTION 可以通过动态注册广播接收到,其他两个则静态和动态注册的都无法收到。
SurfaceView 在 Android 7中,对 SurfaceView 做了优化,让其电量的消耗更少。因此从 Android 7开始,建议使用 SurfaceView 而不是 TextureView。
Vulkan Vulkan 是新一代的 3D 渲染库,提供了更高性能的3D图形渲染。在 Android 7 中我们可以使用它来代替 OpenGL ES。
Art 支持 AOT 和 JIT 混合编译 JIT 是一种动态编译技术,在应用运行时将字节码编译为机器码。AOT 是一种预先编译技术,在应用安装时将字节码(DEX 文件)直接编译为机器码
在 Android 5 以前,Dalvik 虚拟机使用 JIT。而在 Android 5 中,替换成了 ART 虚拟机,ART 虚拟机则依赖 AOT 编译。 在 Android 7 及其以后,支持 AOT 与 JIT 结合使用。即安装时部分代码进行 AOT 编译,加快启动速度。运行时 JIT 编译热点代码。设备空闲时,ART会根据 JIT 的热点代码进行 AOT 编译。
AOT 与 JIT 结合使用的最大好处是,加快了应用程序安装和系统更新的速度。比如之前大型应用在 Android 6中需要几分钟安装,而现在只需要几秒即可。
支持应用快捷方式 支持签名方案 v2 Android 7.0 引入了 APK Signature Scheme v2,这是一种新的应用签名方案, 可缩短应用安装时间,增强防范未经授权的行为 对 APK 文件的更改。
Android 8 Oreo (API 26 & 27) Android 8 有两个版本,分别是 8.0 和 8.1,分别对应 API 26 和 API 27。Android 8.0 Oreo 专注于后台管理、通知系统和画中画模式。
画中画模式 允许应用在小窗口中继续播放视频,同时用户可以进行其他操作。Android 8.0 支持 activity 在画中画(PIP)模式中运行,主要应用于视频播放。
通知优化 Android 8.0 中对通知进行了重新设计,通知修改有:
通知渠道:是一种将通知分类管理的机制。开发者可以为不同类型的通知创建不同的渠道,用户可以根据渠道单独管理通知的行为(如声音、振动、重要性等)。 通知圆点:提醒用户有未读通知,提升通知的可见性。 通知延后:通知延后允许用户将某个通知暂时隐藏,并在指定的时间后重新显示。 通知超时:允许开发者设置通知的显示时间,超过时间后通知会自动消失。 在 Android 8.1 中,应用每秒只能发出一次通知提醒。如果一秒内有两次通知,那么只有第一次的通知会有提示音提醒一次,后面的会正常通知但是没有提示音提醒。
可下载字体 Android 8.0 允许开发者从供应商获取可下载字体资源,而无需将字体绑定到 APK 中。供应商和 Android 支持库负责下载字体,并将这些字体分享到各个 App 中。同样的操作也可用于获取表情资源,让应用不再止步于设备内置表情包。 由于国内手机厂商比较多,没有一个统一的Android手机生态(众所周知的原因,Google Play服务国内无法使用),所以必须自己搭建一套字体提供程序,因此比较麻烦。
自适应图标 自适应图标是 Android 8.0 引入的一项重要特性,其主要作用是:统一应用图标的外观,确保在不同设备上显示一致;支持动态效果,提升用户体验;提升主屏幕的视觉一致性。效果如下所示:
固定快捷方式 在 Android 8中可以把快捷方式固定在桌面上。
Neural Networks API Android 8.1 推出了神经网络 API,具体可以看Neural Networks API
SharedMemory API SharedMemory 是 Android 8.1 中新引入的 api,用于在进程之间共享内存。相对 MemoryFile ,SharedMemory 能更灵活地访问和控制共享内存区域。更多关于 SharedMemory ,可以看 Ashmem(Android共享内存)使用方法和原理
Bitmap内存的存放位置变更 在Android 8.0以前,图片的宽高数据和像素数据都保存在Java层。从Android 8.0开始,Java层只保存图片的宽高数据,图片的像素数据保存在Native层,不再占用Java Heap内存。
后台执行限制 Android 8.0 会限制后台应用可以执行的操作。应用在两个方面受到限制:
后台服务限制:当应用处于空闲状态时,其对后台服务的使用受到限制。这不适用于对用户更明显的前台服务。 广播限制:除了少数例外情况外,应用无法使用其清单注册隐式广播。它们仍然可以在运行时注册这些广播,并且可以使用清单注册显式广播和专门针对其应用的广播。 后台位置限制 为降低耗电量,Android 8.0 会对应用在后台运行时检索用户当前位置信息的频率进行限制。在这些情况下,应用每小时只能接收几次位置信息更新。
自动填充框架 方便用户快速填充表单信息。
Android 9.0 Pie (API 28) 室内定位 在 Android 9 中添加了 Wifi RTT 的支持,应用可以使用 RTT API 来实现室内定位的功能。
刘海屏支持 在 Android 9中提供了无边框屏幕、刘海屏的支持。我们可以提供 getDisplayCutout 来确定是否有刘海屏的存在。使用 DisplayCutout 类则可以让我们找出非功能区域的位置和形状。
通知增强 在 Android 9 之前,已暂停的应用发出的通知会被取消。 从 Android 9 开始,已暂停的应用发出的通知将一直隐藏,直到 应用恢复运行。
多摄像头支持 在 Android 9 中,支持同时访问多个摄像头。
针对非 SDK 接口的限制 从 Android 9(API 级别 28)开始,Android 平台对应用能使用的非 SDK 接口实施了限制。只要应用引用非 SDK 接口或尝试使用反射或 JNI 来获取其句柄,这些限制就适用。 更多信息可以看 针对非 SDK 接口的限制
签名方案v3 Android 9 增加了对 APK 签名方案 v3 的支持。v3支持密钥轮换,并增强了安全性。V3 签名方案与 V1 和 V2 完全兼容,即使设备不支持 V3,仍然可以使用 V1 或 V2 进行验证
旋转锁定 Android 9 增加了新的旋转锁定的旋转模式。
ImageDecoder Android 9 引入了 ImageDecoder 类,它提供了一种现代化的图像解码方法。
改进了 PrecomputedText 类 提供了Magnifier,用于实现放大镜功能 Android 9 增强了 TextClassifier 类,该模型利用机器学习来识别所选文本中的某些实体, 提供操作建议。例如,TextClassifier 可让应用检测用户已选择电话号码。这样应用就可以让用户使用该号码拨打电话。
前台服务 在 Android 9中,前台服务需要申请 FOREGROUND_SERVICE 权限
隐私权变更 为了加强用户隐私保护,Android 9 引入了多项行为变更,例如限制后台应用对设备传感器的访问权限、限制从 Wi-Fi 扫描检索的信息,以及与通话、手机状态和 Wi-Fi 扫描相关的新权限规则和权限组。
电源管理 在 Android 9中,引入了应用待机分组机制,将应用根据用户的使用模式分为不同的优先级组(Buckets),每个组有不同的资源限制和唤醒策略。
同时 Android 9 对省电模式进行了改进,比如系统会更积极地将应用置于应用待机模式,而不是等待应用进入空闲状态。
应用待机分组包括:
活跃(Active) :用户正在使用的应用。 工作集(Working Set) :用户经常使用但当前未在前台的应用。 常用(Frequent) :用户定期使用但不频繁的应用。 罕见(Rare) :用户很少使用的应用。 限制(Restricted) :长时间未使用且可能被限制后台活动的应用。 Android 10 (API 29) 可折叠设备的支持 在 Android 10 中,提供了对可折叠设备的支持。我们可以使用 Jetpack WindowManager 库为可折叠设备的窗口功能(如折叠边或合页)提供了一个 API surface,让应用具备折叠感知能力。 关于折叠屏的适配具体可见 了解可折叠设备
5G Android 10 新增了针对 5G 的平台支持。可以使用 ConnectivityManager 来检测设备是否具有高带宽连接,还可以检查连接是否按流量计费。
深色主题 Android 10 新增了一个系统级的深色主题,非常适合光线较暗的场景并能帮助节省电量。
手势导航 Android 10 引入了全手势导航模式,该模式不显示通知栏区域,允许应用使用全屏来提供更丰富、更让人沉浸的体验。它通过边缘滑动(而不是可见的按钮)保留了用户熟悉的“返回”“主屏幕”和“最近用过”导航。
Thermal API 当设备过热时,会可能影响到 CPU 和 GPU 的运行。在 Android 10 中,应用和游戏可以使用 Thermal API 监控设备变化情况,并在设备过热时采取措施,使设备恢复到正常温度。
共享内存 以 Android 10 为目标平台的应用无法直接使用 ashmem (/dev/ashmem),而必须通过 NDK 的 ASharedMemory 类访问共享内存。
此外,应用无法直接对现有 ashmem 文件描述符进行 IOCTL,而必须改为使用 NDK 的 ASharedMemory 类或 Android Java API 创建共享内存区域。这项变更可以提高使用共享内存时的安全性和稳健性,从而提高 Android 的整体性能和安全性。
隐私权变更 在 Android 10 中对隐私权又做了一次变更,具体变更可以看 Android 10 中的隐私权
前台服务类型 Android 10 引入了 foregroundServiceType XML 清单属性,为前台服务定义对应的服务类型。比如 dataSync 是指从网络下载文件;mediaPlayback 是指播放音乐、有声读完等。
Android 11 (API 30) 隐私设置 Android 11 引入了一些变更和限制来加强用户隐私保护,其中包括:
强制执行分区存储:对外部存储目录的访问仅限于应用专用目录,以及应用已创建的特定类型的媒体。 自动重置权限:如果用户几个月未与应用互动,系统会自动重置应用的敏感权限。 在后台访问位置信息的权限:用户必须转到系统设置,才能向应用授予在后台访问位置信息的权限。 软件包可见性:当应用查询设备上已安装应用的列表时,系统会过滤返回的列表。 增加 APk 签名方案 v4 Android 11 添加了对 APK 签名方案 v4 的支持。注意 targetSdkVersion 为 Android 11 的应用不支持 v1 签名的应用,需要签名版本在 v2 及以上。
无线调试支持 Android 11 支持通过 Android 调试桥 (adb) 以无线方式部署和调试应用。
apk 增量安装 我们使用 adb install –incremental 可以支持 apk 增量更新。需要注意 apk 增量需要 v4 签名方案支持。
NDK Thermal API native 版本的监控设备是否过热的 API,具体可以看 NDK Thermal
IME 新API Android 11 引入了新的 API 以改进输入法 (IME) 的转换,例如屏幕键盘。这些 API 可让我们更轻松地调整应用内容,并与 IME 的出现和消失以及状态和导航栏等其他元素保持同步。
Frame rate API Android 11 提供了一个 API,可让应用告知系统其预期帧速率,从而减少支持多个刷新率的设备上的抖动。
应用退出原因 Android 11 引入了 ActivityManager.getHistoricalProcessExitReasons() 方法,用于报告近期任何进程终止的原因。该方法可以用来收集崩溃诊断信息,例如进程终止是由于 ANR、内存问题还是其他原因所致。此外,我们还可以使用新的 setProcessStateSummary() 方法存储自定义状态信息,以便日后进行分析。
一次性权限 Android 11 允许用户授予应用一次性访问麦克风、摄像头或位置信息的权限。
ResourcesLoader 和 ResourcesProvider 在 Android 11(API 级别 30)中,ResourcesLoader 和 ResourcesProvider 是用于动态加载和管理资源的新 API。它们为开发者提供了更灵活的方式来加载和访问资源。
动态 intent 过滤器 Android 11 引入了 MIME 组,这是一个新的清单元素,可让应用在 intent 过滤器中声明一组动态的 MIME 类型,并在运行时以编程方式对其进行修改。
Android 12 (API 31) Material You 全新的设计语言,允许系统根据壁纸颜色自动生成主题色,并应用于系统 UI 和支持的应用。
生命周期变更 在 Android 12 中,root activity 中按下了 back 按钮,不会 finish 当前的 activity。而是会将该 activity 放到后台。
自动更新应用 在 Android 12,增加了 PackageInstaller#setRequireUserAction() 方法,该方法可让安装程序应用执行应用更新而无需用户确认操作。
前台服务启动限制 当在后台运行时,不再允许应用启动前台服务。
应用启动画面 API Android 12 引入了全新的应用启动画面 API ,可为所有应用启用可自定义的应用启动动画。
应用存储访问权限 现在,应用可以创建自定义 activity,让用户可以管理设备上的应用数据,并将此 activity 提供给文件管理器。具体可以看应用存储访问权限
游戏模式 Android 12 引入了一个新的游戏模式 ,可让用户优化游戏体验以提升性能或延长电池续航时间。
Android 13 (API 33) ART 优化 在 Android 13(API 级别 33)及更高版本中,ART 可大大加快在原生代码之间切换的速度,JNI 调用速度现在最高可提高 2.5 倍。我们还重新设计了运行时引用处理,使其大部分都为非阻塞处理,从而进一步减少了卡顿。此外,我们还可以使用 Reference.refersTo() 公共 API 更快地回收无法访问的对象。
开发者可降级权限 从 Android 13 开始,应用可以撤消未使用的运行时权限。
APK 签名方案 v3.1 Android 13 可支持 APK 签名方案 v3.1,此方案在现有的 APK 签名方案 v3 的基础上进行了改进,此方案解决了 APK 签名方案 v3 的一些已知问题。
可编程的着色器 从 Android 13 开始,系统支持可编程 RuntimeShader 对象,其行为通过 Android 图形着色语言 (AGSL) 定义。AGSL 与 GLSL 共用大部分语法,但可用于 Android 渲染引擎中以自定义 Android 画布中的绘制行为以及过滤 View 内容。 Android 在内部使用这些着色器来实现涟漪效果、模糊和拉伸滚动。通过 Android 13 及更高版本,我们可以为应用创建类似的高级效果。
照片选择器 用户可以更精细地选择与应用共享的照片和视频,而不是授予整个媒体库的访问权限。
Android 14 (API 34) 限制最低可安装目标的 API 级别 在 Android 14,用户无法安装 targetSdkVersion 低于 23 的应用。
对隐式 intent 的限制 对于以 Android 14(API 级别 34)或更高版本为目标平台的应用,Android 会限制应用向内部应用组件发送隐式 intent。详情看对隐式 intent 和待处理 intent 的限制
应用只能终止自己的后台进程 从 Android 14 开始,当您的应用调用 killBackgroundProcesses() 时,该 API 只能终止自己应用的后台进程。如果我们传入其他应用的包名,此方法将不会对该应用的后台进程产生任何影响
必须提供前台服务类型 如果应用以 Android 14(API 级别 34)或更高版本为目标平台,则必须为应用中的每个前台服务指定至少一个前台服务类型 。
屏幕截图检测 如果用户在应用 activity 可见时截取屏幕截图,屏幕截图检测API 会调用回调并显示消息框消息。
Android 15 (API 35) 支持 16 KB 页面大小 从 Android 15 开始,Android 系统支持配置为使用 16 KB 页面大小的开发设备。详细信息可以看支持 16 KB 页面大小
私密空间 私密空间是 Android 15 中推出的一项新功能,可让用户在设备上创建一个单独的空间,在额外的身份验证层保护下,防止敏感应用遭到窥探。
最低可安装目标API级别 在 Android 15中,用户无法安装 targetSdkVersion 低于 24 的应用。
ApplicationStartInfo API Android 15 上的 ApplicationStartInfo API 有助于深入了解应用启动,包括启动状态、在启动阶段所花的时间、在实例化 Application 类时应用的启动方式等。
详细的应用大小信息 Android 15 添加了 StorageStats.getAppBytesByDataType([type]) API,可让我们深入了解应用如何使用所有这些空间,包括 APK 文件分块、AOT 和加速相关代码、dex 元数据、库和引导式配置文件。详情可以看详细的应用大小信息
应用管理的性能分析 Android 15 包含 ProfilingManager 类,可让我们从应用中收集性能分析信息。详情可以看应用管理的性能分析
屏幕录制检测 Android 15 添加了屏幕录制检测 的支持,以检测是否正在录制应用。
Android 16 在Pixel设备上可以刷写最新的beta版本,从目前已经放出的消息来看,Android 16 有很多激动人心的新特性。
首先看看Android16的释放计划:
到25年第四季度会释放主要版本。
官方推介的新特性有如下几点:
相机和媒体 API 赋能创作者 Android 16 增强了对专业相机用户的支持,支持夜间模式场景检测、混合自动曝光和精确的色温调节。使用新的 Intent 操作捕捉动态照片比以往任何时候都更加轻松,并且我们正在持续改进 UltraHDR 图像,支持 HEIC 编码和 ISO 21496-1 草案标准中的新参数。对高级专业视频(APV) 编解码器的支持提升了 Android 在专业录制和后期制作工作流程中的地位,其感知无损的视频质量即使在多次解码/重新编码后也不会出现严重的视觉质量下降。
此外,Android 的照片选择器现在可以嵌入到您的视图层次结构中,用户将会喜欢搜索云媒体的功能。
更加一致、美观的应用程序 Android 16 引入了多项改进,旨在提升应用的一致性和视觉外观,为即将推出的Material 3 Expressive改进奠定基础。针对 Android 16 的应用将无法再选择关闭无边框显示,并且会忽略elegantTextHeight属性,以确保阿拉伯语、老挝语、缅甸语、泰米尔语、古吉拉特语、卡纳达语、马拉雅拉姆语、奥迪亚语、泰卢固语和泰语的间距合适。
自适应 Android 应用 随着 Android 应用如今可在各种设备上运行,以及大屏幕上更多窗口模式的出现,开发者应该构建能够适应任何屏幕和窗口尺寸(无论设备方向如何)的 Android 应用。对于以 Android 16(API 级别 36)为目标平台的应用,Android 16 改进了系统对方向、可调整大小和宽高比限制的管理方式。在最小宽度 >= 600dp 的屏幕上,这些限制将不再适用,应用将填满整个显示窗口。您应该检查您的应用,确保现有的界面能够无缝缩放,并在纵向和横向宽高比下正常运行。我们将提供框架、工具和库来提供帮助。
并排显示非自适应应用程序 UI,左侧显示文本“再见‘仅限移动’的应用程序”,右侧显示自适应应用程序 UI,文本“你好自适应应用程序”
您可以通过启用UNIVERSAL_RESIZABLE_BY_DEFAULT标志,在不使用应用兼容性框架的情况下测试这些替换。详细了解Android 16 中屏幕方向和可调整大小 API 的变更。
默认预测返回及更多 针对 Android 16 的应用将默认具有返回主屏幕、跨任务和跨活动的系统动画。此外,Android 16 将预测性返回导航扩展为三键导航,这意味着用户长按返回按钮后,在导航返回之前会看到上一屏幕的概览。
为了更轻松地获取返回主屏幕动画,Android 16 新增了对onBackInvokedCallback的支持,并添加了新的PRIORITY_SYSTEM_NAVIGATION_OBSERVER。Android 16 还添加了finishAndRemoveTaskCallback和moveTaskToBackCallback,用于通过预测返回实现自定义返回堆栈行为。
持续的进度通知 Android 16 引入了Notification.ProgressStyle ,它允许您创建以进度为中心的通知,这些通知可以使用点和段来指示用户旅程中的状态和里程碑。主要用例包括拼车、送货和导航。它是实时更新的基础,将在即将发布的 Android 16 更新中全面实现。
自定义 AGSL 图形效果 Android 16 添加了 RuntimeColorFilter 和 RuntimeXfermode,允许您在 AGSL 中创作诸如阈值、棕褐色和色相饱和度等复杂效果,并将它们应用于绘制调用。
帮助创建性能更好、更高效的应用程序和游戏 从帮助您了解应用性能的 API,到旨在提高效率的平台变更,Android 16 致力于确保您的应用拥有出色的性能。Android 16为ProfilingManager引入了系统触发的分析功能,确保在应用恢复有效生命周期后立即执行最多一次的ScheduleAtFixedRate执行,以提高效率;引入了hasArrSupport和getSuggestedFrameRate(int) 函数,使您的应用能够更轻松地利用自适应显示刷新率;并在SystemHealthManager中引入了getCpuHeadroom和getGpuHeadroom API 以及CpuHeadroomParams和GpuHeadroomParams函数,以便为游戏和资源密集型应用提供受支持设备上可用 GPU 和 CPU 资源的估算值。
JobScheduler 更新 Android 16 中的JobScheduler.getPendingJobReasons会返回作业待处理的多个原因,这些原因既包括您设置的显式约束,也包括系统设置的隐式约束。新的JobScheduler.getPendingJobReasonsHistory会返回最近待处理作业原因变更的列表,让您能够更好地调整应用在后台的运行方式。
Android 16 正在根据应用程序所在的应用程序待机存储桶、作业是否在应用程序处于顶部状态时开始执行以及作业是否在应用程序运行前台服务时执行来调整常规和加急作业运行时配额。
为了检测(然后减少)废弃作业,应用应使用系统为废弃作业分配的新STOP_REASON_TIMEOUT_ABANDONED作业停止原因,而不是STOP_REASON_TIMEOUT。
16KB 页面大小 Android 15 引入了对 16KB 页面大小的支持,以提升应用启动、系统启动和相机启动的性能,同时降低电池消耗。Android 16 新增了16 KB 页面大小兼容模式,结合新的Google Play 技术要求,使 Android 设备更接近于搭载这一重要变更。您可以使用最新版 Android Studio 中的16KB 页面大小检查和 APK 分析器来验证您的应用是否需要更新。
ART 内部变化 Android 16 包含 Android 运行时 (ART) 的最新更新,这些更新提升了 Android 运行时 (ART) 的性能并支持更多语言功能。这些改进也可通过 Google Play 系统更新应用于搭载 Android 12(API 级别 31)及更高版本的超过十亿台设备。依赖于内部非 SDK ART 结构的应用和库可能无法继续正常运行这些变更。
隐私和安全 Android 16 延续了我们提升安全性和保障用户隐私的使命。它改进了针对 Intent 重定向攻击的安全性,使MediaStore.getVersion在每个应用上都具有唯一性,添加了允许应用共享Android Keystore密钥的 API,整合了Android 隐私沙盒的最新版本,在配套设备配对流程中引入了新的行为以保护用户的位置隐私,并允许用户在照片选择器中轻松选择并限制对应用拥有的共享媒体的访问。
本地网络权限测试 Android 16 允许您的应用测试即将推出的本地网络权限功能,该功能需要您的应用获得 NEARBY_WIFI_DEVICES 权限。此变更将在未来的 Android 主要版本中强制执行。
为每个人打造的 Android Android 16 添加了一些功能,例如与兼容 LE Audio 助听器的Auracast 广播音频、辅助功能更改(例如使用TYPE_DURATION扩展TtsSpan )、 AccessibilityNodeInfo中基于列表的新 API 、使用setExpandedState改进对可扩展元素的支持、 用于不确定ProgressBar小部件的RANGE_TYPE_INDETERMINATE、 支持“部分检查”状态的AccessibilityNodeInfo getChecked和setChecked(int)方法、 setSupplementalDescription (以便您可以为ViewGroup提供文本而无需覆盖其子级的信息)以及setFieldRequired(以便应用程序可以告知辅助功能服务需要输入表单字段)。
轮廓文本以实现最大文本对比度 Android 16 引入了轮廓文本,取代了高对比度文本,它在文本周围绘制更大的对比区域,从而大大提高了可读性,同时还引入了新的AccessibilityManager API,允许您的应用检查或注册监听器以查看此模式是否已启用。
以下还有一些对于开发者需要关注的点
ProfilingManager 在 15 的时候 Android 添加了 ProfilingManager,让应用能够使用 Perfetto 请求收集性能分析数据,例如启动或 ANR 等情况,而从 Android 16 开始,ProfilingManager 现在提供了系统触发的分析。 现在 App 可以使用 ProfilingManager#addProfilingTriggers() 来注册接收需要的信息,包括用于基于 Activity 的冷启动的 onFullyDrawn 和 ANR。
val anrTrigger = ProfilingTrigger . Builder (
ProfilingTrigger . TRIGGER_TYPE_ANR
)
. setRateLimitingPeriodHours ( 1 )
. build ()
val startupTrigger : ProfilingTrigger = //...
mProfilingManager . addProfilingTriggers ( listOf ( anrTrigger , startupTrigger ))
ApplicationStartInfo 同样,在 15 中 Android 添加的 ApplicationStartInfo,用于支持应用查看进程启动的原因、启动类型、开始时间、限制和其他有用的诊断数据。
而 Android 16 添加了 getStartComponent 来区分触发启动的组件类型,从而帮助开发者优化应用的启动流程。
触觉反馈 从 Android 11 开始,系统就增加了对更复杂的触觉效果的支持,更高级的 actuators 可以通过设备定义的语义基元的 VibrationEffect.Compositions 来支持这些效果。 而 Android 16 添加了新的 haptic API ,可以让应用定义触感反馈效果的振幅和频率曲线,同时抽象出设备功能之间的差异:
VibratorEnvelopeEffectInfo :提供有关振动器硬件功能和限制的信息,如支持的最大控制点数、单个区段的最小和最大持续时间、最大总持续时间等 VibratorFrequencyProfile:描述不同振动频率下 Vibrator 的输出。
这些新 API 消除了 App 在开发时需要对设备特定功能的 if 判断,开发人员可以直接使用 API 去创建自定义触觉反馈效果。
JobScheduler Android 16 还引入了 JobScheduler#getPendingJobReasons(int jobId),它可以返回 Job 待处理的多个原因,比如开发者设置了显式约束条件和系统设置了隐式约束条件:
关于 Job Android 16 还引入了 JobScheduler#getPendingJobReasonsHistory(int jobId),从而支持返回最近约束更改的列表:
对于给定的 jobId,返回任务可能一直等待执行的原因的有限历史视图,返回的列表由 PendingJobReasonsInfo 组成,每个对象都包含一个自 epoch 以来的时间戳以及一个 ERROR(PendingJobReason constants/android.app.job.JobScheduler.PendingJobReason PendingJobReason constants) 表示
这些 API 调整,可以帮助开发者在调试 Job 时分析无法执行的原因,尤其是在看到某些任务的成功率降低或 Job 完成出现延迟问题时,可以更好地了解到某些 Job 是由于系统定义的约束还是由于显式设置的约束而未完成。
另外,从 Android 16 开始,Job 的执行会被优化调整,例如:
在应用对用户可见时启动,并在应用不可见后继续的 Job 将遵守 Job runtime 配额 与前台服务同时执行的 Job 将遵守 Job runtime 配额 配额(Quotas):简单来说,就是系统必须将执行时间分配给加急 Job,而执行时间不是无限的,相反每个应用都会收到一个执行时间配额,当应用使用其执行时间并达到其分配的配额时,在配额刷新之前,App 会无法再执行加速工作,这是 Android 有效地平衡应用 App 之间的资源策略,而限制前台执行时间的系统级配额决定了加急 Job 是否可以启动。
简单说就是,Android 16 会根据不同场景来调整常规和加速 Job 执行运行时配额,该优化调整会影响 WorkManager、JobScheduler 和 DownloadManager 调度的任务,要调试 Job 停止的原因,可以通过调用 WorkInfo.getStopReason 或则 JobParameters.getStopReason 来记录 Job 停止的原因。
最后,Android 16 完全弃用 JobInfo#setImportantWhileForeground ,这个人方法自 Android 12 (API 31) 开始已经弃用,从 Android 16 开始它将不再有效运行,并且 JobInfo#isImportantWhileForeground 方法从 Android 16 开始也将返回 false。
自适应刷新 Android 15 中引入的自适应刷新率 Adaptive refresh rate (ARR) ,从而支持硬件上的显示刷新率能够使用离散的 VSync 步骤适应内容帧速率,从而降低了功耗,同时消除了可能引起卡顿的模式切换。
但是尽管 Android 15 增加了对自适应刷新率的平台级支持,但它并没有为应用提供实际利用它的方法,而在 Android 16 DP2 在恢复 getSupportedRefreshRates() 的同时引入了 hasArrSupport() 和 getSuggestedFrameRate(int) ,从而让 App 可以更轻松地适配 ARR。
之前 getSupportedRefreshRates 在 **API level 23 的时候被 deprecated ** ,改成了 getSupportedModes ,现在它又复活了。
通过 getSuggestedFrameRate(int) 可以在给定描述性帧速率类别的情况下,获取显示器定义的帧速率:
float desiredMinRate = display . getSuggestedFrameRate ( FRAME_RATE_CATEGORY_NORMAL );
Surface . FrameRateParams params = new Surface . FrameRateParams . Builder ().
setDesiredRateRange ( desiredMinRate , Float . MAX ). build ();
surface . setFrameRate ( params );
在不需要快速渲染速率的动画可以使用 FRAME_RATE_CATEGORY_NORMAL 来获取建议帧速率, 然后建议的帧速率可以在 Surface.FrameRateParams.Builder.setDesiredRateRange 设置。
同时 RecyclerView 1.4 页在内部支持了 ARR(例如 fling 或者 smooth scroll 下),并且未来 ARR 支持会添加到更多 Jetpack 库中。
Photo picker Photo picker 是 Android 为用户提供了一种安全的媒体选择内置方式,它可以授予应用访问本地和云存储中所选图像和视频的权限,而不是让 App 访问到整个媒体库。 通过 Google 系统更新和 Google Play 服务组合使用模块化系统组件,它可支持到 Android 4.4(API 级别 19)。 而 Android 16 本次更新的预览版包含了新的 API,支持从云媒体提供商搜索 Android 照片选择器,照片选择器中的搜索功能未来也将适配推出。
Wifi 测距 在 Android 15 版本就增加了 Wi-Fi 测距的支持,这是一种可实现精确室内位置跟踪的定位技术,Wi-Fi 测距允许 <1m 精度,使其比使用信号强度测量的传统基于 Wi-Fi 的位置跟踪精确得多。
Wi-Fi 测距基于飞行时间而不是信号强度,因此更加精确。
而 Android 16 在采用 WiFi 6 的 802.11az 的受支持设备上,增加了对 WiFi 位置功能的安全功能支持,主要是应用能够将协议的更高精度、更强的可扩展性和动态调度与安全增强功能相结合,包括基于 AES-256 的加密和防止 MITM 攻击,例如通过 802.11az 与 Wi-Fi 6 标准集成解锁笔记本电脑或车门。
Predictive back 尽管 Android 15 默认启用系统预测性返回动画,但应用是否支持这些动画仍取决于应用本身。
而为了帮助 App 支持这些 API,Android 16 添加了新的 API,可帮助开发者在手势导航中启用预测性返回系统动画,例如返回主页动画,通过向新的 PRIORITY_SYSTEM_NAVIGATION_OBSERVER , App 可以在系统处理返回导航时接收常规的 onBackInvoked 调用,而不会影响正常的返回导航流程。
Android 16 还添加了 finishAndRemoveTaskCallback 和 moveTaskToBackCallback ,通过使用 OnBackInvokedDispatcher 注册这些回调,系统可以在调用返回手势时触发特定行为并播放相应的提前动画。
去年学习了整个Android平台的JNI实现流程以及基础类型,引用,多线程,核心指针和JavaVM的相关知识。
Android JNI开发
现在从架构层面,了解一下底层的运行,调用链路。
主要分析目标是 Android 平台。先简单回顾一下 JNI 的开发流程和动态库的生成流程。
首先,理解 JNI (Java Native Interface) 的核心作用至关重要。JNI 并不是一种编程语言,而是一套规范 (Specification) 。它定义了:
JVM (Java Virtual Machine) 如何调用 Native 代码: 包括函数命名约定、参数传递、返回值处理等。Native 代码如何与 JVM 交互: 比如创建 Java 对象、调用 Java 方法、访问 Java 字段、抛出 Java 异常等。数据类型映射: Java 类型(int, String, Object 等)与 C/C++ 类型(jint, jstring, jobject 等)之间的转换规则。这套规范保证了不同 JVM 实现(如 Android 的 ART/Dalvik)和不同操作系统(Linux/Windows/macOS)上的 Java 代码都能以相同的方式与 Native 代码交互。
so 动态库生成 一个典型的 JNI 项目模组结构是下面这样的:
现在很多原生C++项目都采用CMake工具来构建编译系统,android平台开发 JNI 也是。CMake 本身并不是一个编译工具,而是一个跨平台的、开源的自动化构建系统。它不直接编译你的代码,而是根据你的 CMakeLists.txt 文件来生成特定平台和编译工具(如 Makefiles、Ninja 或 Visual Studio 项目文件)的构建脚本。
想象一下,如果你的项目需要在 Windows、Linux、macOS 甚至 Android 上编译,每种平台可能有不同的编译器和构建工具。手动为每种环境编写构建脚本会非常复杂且容易出错。CMake 就是为了解决这个问题而生,它提供了一套统一的语法来描述你的项目。
CMakeLists.txt CMakeLists.txt 文件是什么呢?它是一个构建系统的配置文件。 形象地来概括,CMakeLists.txt 就是你告诉 CMake “我的项目长这样,你需要用这些源文件,链接这些库,编译成这种类型(可执行文件或库),并且用这些特殊的编译选项” 的说明书。它极大地简化了跨平台项目的构建管理。
它的主要作用包括 定义项目结构和属性 , 管理依赖和库 , 设置编译选项和宏 , 查找外部包和组件 , 配置和生成构建文件 , 定义安装规则 。
例如:
# CMake 最低版本要求
cmake_minimum_required ( VERSION 3.10.2)
# 定义项目名称
project ( "my_native_lib" )
# 查找 Android Log 库
find_library ( log-lib log)
# 添加一个共享库目标,命名为 "my_native_lib"
# 并指定它的源文件
add_library ( # 添加一个库
my_native_lib # 库的名称
SHARED # 共享库
src/main/cpp/native-lib.cpp ) # 源文件路径
# 链接日志库到你的目标库中
target_link_libraries ( # 指定需要链接的库
my_native_lib # 你的目标库
${ log-lib } ) # Android Log 库
# 可选:设置 C++ 标准
set ( CMAKE_CXX_STANDARD 17)
set ( CMAKE_CXX_STANDARD_REQUIRED TRUE)
# 可选:添加包含目录
target_include_directories ( my_native_lib PUBLIC
src/main/cpp/include)
在这个例子中:
project() 定义了项目的名称。find_library() 查找了 Android NDK 提供的 log 库。add_library() 定义了一个名为 my_native_lib 的共享库 ,并指定了它的源文件 native-lib.cpp。这是在 Android 上生成 .so 文件的关键。target_link_libraries() 将 log-lib 链接到 my_native_lib 中,这样你的 C++ 代码就可以使用 __android_log_print 等函数了。set(CMAKE_CXX_STANDARD 17) 设置了 C++ 编译标准为 C++17。构建流程 动态库的构建流程本质上是 C++ 代码编译和链接的特定于 Android 平台的实现,主要依赖于 Android NDK (Native Development Kit) 。NDK 是一套工具集,让你能够在 Android 平台上使用 C/C++ 等原生语言开发应用。它包含了下面这些组件:
Clang (LLVM): 用于编译 C/C++ 代码的编译器。Linker (ld): 链接器,用于生成 .so 文件。GCC (已逐渐被 Clang 替代): 另一种编译器。Standard C/C++ Libraries: 如 libc++ 或 gnustl (旧版本)。Android Specific APIs: 比如 android/log.h(用于日志输出)和 jni.h(用于 JNI 接口)。构建系统: 目前主流都是使用 CMake 。我们使用NDK来构建C++代码的目标是生成一个.so文件,这个文件可以在Android平台上被加载和调用。这个过程又分为哪些阶段?
C++ 代码编译 C++ 是一种编译型语言 ,这意味着你的源代码在执行之前必须经过一个或多个阶段的转换。这个过程通常包括以下几个主要步骤。
1. 预处理 (Preprocessing) 预处理器 (preprocessor) 会处理源代码中以 # 开头的指令,这些指令被称为预处理指令 。常见的预处理操作包括:
头文件包含 (#include <file> 或 #include "file"): 将指定文件的内容插入到当前文件中。这就像把多个代码片段拼接起来。宏替换 (#define): 将宏定义替换为对应的文本。例如,#define PI 3.14159 会将代码中所有的 PI 替换为 3.14159。条件编译 (#ifdef, #ifndef, #if, #else, #endif): 根据判断条件,选择性地编译或忽略代码块。这在针对不同平台或配置编译代码时非常有用。预处理阶段的输出是一个纯 C++ 源文件 ,其中所有的预处理指令都已经被处理完毕,宏也已经展开,并且包含了所有引用的头文件内容。
2. 编译 (Compilation) 预处理后的源文件(通常以 .i 或 .ii 结尾,但在实际开发中你可能很少直接看到)会被编译器 (compiler) 处理。编译器的主要任务是将 C++ 源代码翻译成汇编代码 (assembly code) 。
在这个阶段,编译器会执行以下工作:
词法分析 (Lexical Analysis): 将源代码分解成一系列的词法单元 (tokens) ,如关键字、标识符、运算符、常量等。语法分析 (Syntax Analysis): 根据 C++ 语法规则,将词法单元组织成一个抽象语法树 (Abstract Syntax Tree - AST) 。如果代码存在语法错误,编译器会在这里报错。语义分析 (Semantic Analysis): 检查代码的语义正确性,例如类型匹配、变量声明和初始化、函数调用是否正确等。中间代码生成 (Intermediate Code Generation): 将 AST 转换为一种更接近机器语言但仍然独立于具体机器的中间表示 (Intermediate Representation - IR) ,这有助于后续的优化。代码优化 (Code Optimization): 对中间代码进行各种优化,以提高程序的执行效率、减少代码大小。这可能包括死代码消除、常量折叠、循环优化等。目标代码生成 (Target Code Generation): 将优化后的中间代码转换成特定处理器架构的汇编代码 。编译阶段的输出是一个或多个汇编文件 (通常以 .s 结尾)。
3. 汇编 (Assembly) 汇编器 (assembler) 的作用是将汇编代码翻译成机器代码 (machine code) ,也就是由二进制指令组成的目标文件 (object file) 。目标文件通常以 .o (Linux/macOS) 或 .obj (Windows) 结尾。
目标文件包含:
编译后的机器指令。 数据(全局变量、静态变量)。 符号表:记录了程序中定义和引用的函数、变量等符号的信息。 调试信息(如果开启了调试选项)。 此时的目标文件是独立的编译单元,它可能包含对其他文件或库中定义的函数和变量的引用(这些引用被称为未解析的符号 )。
4. 链接 (Linking) 链接是整个编译过程的最后一个阶段,由链接器 (linker) 完成。链接器的主要任务是将一个或多个目标文件以及程序所需要的库文件组合在一起 ,生成一个可执行文件或一个共享库(如 .so 文件在 Android 上)。
链接器会完成以下工作:
符号解析 (Symbol Resolution): 解决目标文件中所有未解析的符号引用。例如,如果你的代码调用了 printf 函数,链接器会在标准库中找到 printf 的实现,并将这个引用解析到实际的函数地址。重定位 (Relocation): 调整代码和数据段的地址。因为每个目标文件都是独立编译的,它们内部的地址都是相对地址。链接器会将它们合并到一个统一的地址空间中,并修正所有需要调整的地址。库链接 (Library Linking): 静态链接 (Static Linking): 将所有需要的库代码直接复制到可执行文件中。优点是可执行文件独立,不依赖外部库;缺点是文件较大,且库更新时需要重新编译链接。动态链接 (Dynamic Linking) / 共享链接 (Shared Linking): 可执行文件只包含对共享库(如 .so 文件)的引用,而不是实际的代码。在程序运行时,操作系统的动态链接器/加载器 会加载这些共享库。优点是可执行文件较小,多个程序可以共享同一个库实例,节省内存,且库更新时无需重新编译程序;缺点是依赖外部库,如果库缺失或版本不兼容,程序可能无法运行。Android NDK 开发中通常使用动态链接生成 .so 文件。链接阶段的输出是一个可执行文件 (如 Linux 上的 a.out 或 Windows 上的 .exe 文件)或者一个共享库 (如 Linux/Android 上的 .so 文件,Windows 上的 .dll 文件)。
Gradle 构建过程 在 Android Studio 中,我们通常不需要手动调用 CMake 或 ndk-build。Android Gradle Plugin 会为你自动化这些任务。例如我们配置了:
android {
// ...
defaultConfig {
// ...
externalNativeBuild {
cmake {
// 指向 CMakeLists.txt 的路径
path file ( 'src/main/cpp/CMakeLists.txt' )
}
// 或者 ndkBuild { path file('src/main/cpp/Android.mk') }
}
ndk {
abiFilters 'armeabi-v7a' , 'arm64-v8a' , 'x86' // 指定需要构建的 ABI
}
}
// ...
}
当我们 Sync 项目时,Gradle 会检查 externalNativeBuild 配置。当你点击 “Build” 或 “Run” 时,Gradle 会执行下面这些操作:
根据 build.gradle 中配置的 ABI (abiFilters),为每个目标架构调用相应的 NDK 工具链。 调用 CMake 或 ndk-build: 你的 CMakeLists.txt 或 Android.mk 文件会被解析。编译 (Compilation): NDK 工具链中的 Clang 编译器将你的 C++ 源代码编译成对应架构的汇编代码,然后汇编成目标文件 (.o 文件)。链接 (Linking): NDK 工具链中的链接器将这些目标文件与 NDK 提供的系统库(如 liblog.so)和你的其他依赖库链接起来。最终,它会生成对应每个 ABI 的 .so 动态库文件libnative-lib.so)。打包到 APK: APK 文件本身是一个 ZIP 格式的归档文件。生成的 .so 文件会被 Gradle 打包到 APK 的特定目录下,通常是 lib/<ABI>/,例如 lib/arm64-v8a/libnative-lib.so。Java虚拟机如何运行的C++代码 JVM (或者说Android平台的Dalvik或者Art)本身并不能提供运行环境,直接 运行 C++ 代码。相反,它通过一套协调机制 来将执行权交给操作系统和底层的 CPU,由它们来执行 C++ 代码。这个协调机制其实就是 JNI (Java Native Interface) 。
JNI 的桥梁作用 JVM 并不理解 C++ 代码,它只运行字节码(Java 代码编译后的中间产物)。当你调用了一个 native 方法时,JVM 知道这个方法不是由 Java 实现的,而是由外部的本地代码提供。
JNI 规范了 Java 类型和 C++ 类型之间的映射(例如 int 对应 jint,String 对应 jstring),以及 Java 方法签名如何转换为 C++ 函数名。并且提供了一套 C 函数接口(通过 JNIEnv* 指针),允许 C++ 代码反过来操作 Java 对象、调用 Java 方法、访问 Java 字段等。
当你调用 System.loadLibrary("mylib"); 时,发生的事情远不止简单地把文件读进内存:
操作系统层面的加载 JVM 会请求操作系统(在 Android 上是 Linux 内核)的动态链接器 (Dynamic Linker) 来加载这个 .so 共享库文件。
动态链接器首先会在文件系统中找到 libmylib.so。然后将 .so 文件的内容 内存映射 (Memory Map) 到当前进程的虚拟地址空间。这并不是把整个文件一次性读入 RAM,而是建立一种映射关系,只有当程序真正访问到某个内存页时,才会从磁盘加载对应的页到物理内存。
映射完成后,执行解析符号。这是关键一步。.so 文件内部有一个符号表 (Symbol Table) ,记录了它所包含的函数(如 Java_com_example_MyClass_myNativeMethod)和变量的名称及其在文件内的相对地址。同时,它也记录了自身所依赖的外部函数(如 printf、__android_log_print 等)的名称。动态链接器会查找这些外部依赖,在其他已经加载的系统库(如 libc.so、liblog.so)中找到它们的实际内存地址,并更新 .so 库内部的重定位表 (Relocation Table) ,将对外部函数的引用替换为它们的实际地址。
最后,如果你的 .so 库中定义了 JNI_OnLoad 函数,动态链接器在加载并完成基本解析后,会通知 JVM 。JVM 随后会调用这个 JNI_OnLoad 函数。你可以在这里执行动态注册,将 Java 方法直接映射到 C++ 函数的内存地址,或者进行其他初始化工作。
Java 方法与 Native 函数的绑定 在调用 native 方法之前,JVM 需要知道这个方法对应的 C++ 函数的具体入口点(也就是它在内存中的地址)。
静态注册: 如果你没有使用 JNI_OnLoad 进行动态注册,那么当 JVM 第一次遇到一个 native 方法的调用时,它会:根据 JNI 的命名规则(Java_包名_类名_方法名)构造一个字符串。 在已经加载的 .so 库的符号表 中查找这个字符串对应的函数。 一旦找到,JVM 就会将这个 Java 方法与其对应的 C++ 函数的内存地址绑定 (Binding) 起来。这样,后续再次调用这个 Java 方法时,就可以直接跳转到那个 C++ 函数的地址,无需再次查找。 动态注册: 如果你在 JNI_OnLoad 中使用了 RegisterNatives,那么绑定工作在库加载时就已经完成了。JVM 会直接获得 Native 函数的地址,效率更高,且不依赖于严格的命名约定。JNI 调用过程 当 JVM 首次尝试调用一个 native 方法时,它需要知道这个 Java 方法对应的 Native 函数在 .so 库中的具体地址。这种寻址过程就是根据上文提到的符号表 来查找。
静态注册时,JVM 会根据 JNI 的命名约定 来查找 Native 函数。直接在已加载的 .so 库的符号表中查找符合命名规范的函数。这个查找过程在第一次调用该 Native 方法时发生,并将 Java 方法与 Native 函数的地址进行绑定 (Binding) 。后续再次调用时,就可以直接跳转到 Native 函数的地址,提高了效率。如果找不到对应的函数,会抛出 UnsatisfiedLinkError。
动态注册是通过 JNI_OnLoad 函数,具体的是 RegisterNatives JNI 函数手动将 Java 方法和 Native 函数进行关联。这种方式可以不遵循 JNI 的严格命名约定,Native 函数名可以更简洁。可以批量注册多个方法更高效。还有助于防止函数名过长导致某些旧系统(如 Windows)上的问题。
参数传递与栈帧 当 Java 代码调用 Native 方法时:
保存 Java 运行上下文: JVM 第一步会保存当前 Java 方法的执行上下文(如局部变量、操作数栈状态等)。JNIEnv 指针: JVM 会将一个 JNIEnv* 指针作为第一个参数传递给 Native 函数。这个指针提供了访问 JVM 功能的接口。JObject/JClass 参数: 对于非静态 Native 方法,jobject 参数代表调用该方法的 Java 对象的引用。 对于静态 Native 方法,jclass 参数代表调用该方法的 Java 类的引用。 参数转换: Java 基本类型(如 int, boolean)会直接映射到对应的 JNI 类型(jint, jboolean)。对于 Java 对象类型(如 String, Object),JNI 会传递一个 jobject 或其子类型的引用。这些引用是指向 JVM 内部 Java 对象的指针。切换栈帧: JVM 的执行流会从 Java 栈帧切换到 Native 栈帧。CPU 会开始执行 Native .so 文件中的机器码。Native 代码执行和返回 JVM 将执行流程跳转 到 Native C++ 函数在内存中的起始地址。此时,CPU 开始执行 .so 库中的 C++ 机器码。JVM 不再直接“运行”C++ 代码,而是将控制权交给了 CPU,由 CPU 直接执行预编译好的机器指令。
Native C++ 代码在运行时,可以直接使用 JNIEnv 指针来与 JVM 进行交互。例如:
env->NewStringUTF(): 从 C 字符串创建 Java String 对象。env->GetStringUTFChars(): 将 Java String 转换为 C 字符串。env->CallIntMethod(): 调用 Java 对象的某个 int 类型返回值的成员方法。env->ThrowNew(): 在 Java 层抛出异常。当 Native 函数执行完毕并通过 return 语句返回结果时。Native 函数返回的 C/C++ 类型结果会被 JNI 自动转换回对应的 Java 类型 。
然后要恢复 Java 上下文,执行流会从 Native 栈帧切换回 Java 栈帧 。如果 Native 代码中设置了待抛出的 Java 异常,JVM 会在返回后立即抛出该异常。如果无异常,Java 调用方会接收到 Native 方法的返回值,并继续其后续操作。
内存管理与垃圾回收 一个重要的底层细节是内存管理:
Java 堆: Java 对象存储在 Java 堆上,由 JVM 的垃圾回收器管理。Native 堆: C/C++ 代码可以通过 malloc/free 或 new/delete 在 Native 堆上分配内存。这部分内存不受 JVM 垃圾回收器的管理,需要 Native 代码自己负责释放,否则会导致内存泄漏。JNI 引用: 当 Native 代码获取到 Java 对象的引用时(jobject, jstring, jbyteArray 等),这些引用被称为 局部引用 (Local Reference) 。它们在 Native 方法返回后会自动被 JVM 释放。如果你需要在 Native 方法返回后继续持有这些引用,你需要将它们提升为 全局引用 (Global Reference) ,并手动管理其生命周期。背景 最近在做AI大模型对接的一些功能,调用完chat接口返回结果之后,发现豆包和Kimi等客户端都有语音播报功能,并且这些大厂经过一系列调优,可以实现很好听的音色和节奏停顿的效果。
那个人开发者可不可以在系统自带的免费语音助手的基础上做一个tts(Text To Speech)的播报呢?
调查发现Google已经有相关的接口了,并且尝试使用魅族20Pro手机成功实现了语音播报效果,记录一下使用过程。
TextSpeech TextSpeech 是Android平台的文字转语音的接口,可以将文本合成为语音,可以支持立即播放,或者存储为音频文件。
初始化实例 创建实例需要传入两个参数,一个Context,一个连接的监听器,监听器会在初始化完成后回调。
/**
* The constructor for the TextToSpeech class, using the default TTS engine.
* This will also initialize the associated TextToSpeech engine if it isn't already running.
*
* @param context
* The context this instance is running in.
* @param listener
* The {@link TextToSpeech.OnInitListener} that will be called when the
* TextToSpeech engine has initialized. In a case of a failure the listener
* may be called immediately, before TextToSpeech instance is fully constructed.
*/
public TextToSpeech ( Context context , OnInitListener listener ) {
this ( context , listener , null );
}
播放停止与释放 就播放功能来说,使用起来非常简单,只需要创建一个TextSpeech对象,然后调用speak方法即可。
方法签名:
public int speak ( final CharSequence text ,
final int queueMode ,
final Bundle params ,
final String utteranceId ) {
return runAction (( ITextToSpeechService service ) -> {
Uri utteranceUri = mUtterances . get ( text );
if ( utteranceUri != null ) {
return service . playAudio ( getCallerIdentity (), utteranceUri , queueMode ,
getParams ( params ), utteranceId );
} else {
return service . speak ( getCallerIdentity (), text , queueMode , getParams ( params ),
utteranceId );
}
}, ERROR , "speak" );
}
参数说明: text:要转换的文本 queueMode:播放模式,有三种:QUEUE_ADD、QUEUE_FLUSH、QUEUE_MODE_DEFAULT params:参数,包括语音的语言、音调、语速等 utteranceId:唯一标识,用于区分不同的语音
停止时调用该对象的 stop() 方法,使用完毕退出时,需要调用 shutdown() 方法来释放引擎所使用的原生资源。我猜会这里会占用系统的多媒体编解码器连接,使用完需要及时释放防止其他app播放多媒体资源出错。
工具类完整代码 使用object实现单例,全局共享,在viewmodel里初始化,给界面提供接口。
object SpeechUtils {
private lateinit var textToSpeech : TextToSpeech
private const val TAG = "SpeechUtils"
private const val TEST_IDENTIFIER = "test"
private const val TEST_HELLO = "Hi, How are you? I'm fine. Thank you. And you?"
private var isConnected = false
val ttsConnectedListener = TextToSpeech . OnInitListener { status ->
Log . d ( TAG , "OnInitListener status: $status" )
isConnected = status == TextToSpeech . SUCCESS
}
fun init () {
textToSpeech = TextToSpeech ( appContext , ttsConnectedListener )
}
fun speak ( text : String = TEST_HELLO , locale : Locale = Locale . US ) {
Log . d ( TAG , "==========>speak<=========" )
if ( isConnected ) {
textToSpeech . language = locale
textToSpeech . speak (
text ,
TextToSpeech . QUEUE_ADD ,
null ,
TEST_IDENTIFIER
)
} else {
Log . d ( TAG , "==========>TTS is not connected!<=========" )
}
}
fun stop () {
textToSpeech . stop ()
}
fun shutdown () {
textToSpeech . shutdown ()
}
}
Viewmodel代码:
class MainStateHolder (
private val retroService : RetroService ,
private val ktorClient : KtorClient ,
) : ViewModel () {
companion object {
const val TAG = "MainStateHolder"
const val TOKEN_KEY = "token"
const val USER_NAME_KEY = "user_name"
}
init {
SpeechUtils . init ()
}
// ...
fun speak ( text : String , locale : Locale ) {
SpeechUtils . speak ( text , locale )
}
fun stopSpeech (){
SpeechUtils . stop ()
}
override fun onCleared () {
super . onCleared ()
ktorClient . release ()
SpeechUtils . shutdown ()
}
}
界面使用时,服务器返回值时调用播放,页面取消组合时,调用stop停止。同时,加入LifeCycle感知,在Activity退到后台,也调用停止接口:
@Composable
fun MyServerPage (
mainStateHolder : MainStateHolder ,
lifecycleOwner : LifecycleOwner = LocalLifecycleOwner . current ,
onBackStack : () -> Unit ,
) {
BasePage ( "个人服务器测试" , onCickBack = onBackStack ) {
LaunchedEffect ( Unit ) {
mainStateHolder . getMyServerResponse ()
}
val myResponse = mainStateHolder . myServerResponseStateFlow . collectAsState (). value
LaunchedEffect ( myResponse ) {
if ( myResponse . isNotEmpty ()) {
mainStateHolder . speak ( myResponse , Locale . US )
}
}
Box (
modifier = Modifier . fillMaxSize (),
contentAlignment = androidx . compose . ui . Alignment . Center
) {
Text ( text = myResponse )
}
DisposableEffect ( lifecycleOwner ) {
Log . i ( "MyServerPage" , "MyServerPage ${lifecycleOwner.lifecycle.currentState}" )
val observer = LifecycleEventObserver { _ , event ->
if ( event == Lifecycle . Event . ON_STOP ) {
// 当 Activity 退到后台时,Lifecycle 会触发 ON_STOP 事件
mainStateHolder . stopSpeech ()
}
}
lifecycleOwner . lifecycle . addObserver ( observer )
onDispose {
mainStateHolder . stopSpeech ()
lifecycleOwner . lifecycle . removeObserver ( observer )
}
}
}
}
后续尝试使用付费版本的本地引擎,集成aar到本地进行调用,达到更好的播放效果。使用方式应该都是按照原生的接口设计。
官方文档 [Google官方JNI文档]
项目例程 [stepheneasyshot/JniDemo]
基本开发流程 Android Studio 编译原生库的默认构建工具是 CMake。由于很多现有项目都使用 ndk-build 构建工具包,因此 Android Studio 也支持 ndk-build。不过,如果您要创建新的原生库,则应使用 CMake。新的接口开发全部使用cmake来构建,相比之前的ndk-build的配置方式,使用cmake可以省略掉.h文件声明和android.mk文件来辅助构建,只需要一个CMakeList.txt即可。
开发流程:
Java/Kotlin代码里创建好需要的native方法,注意在Cpp文件中对方法名有明确要求。 package com.stephen.jnitest
object JniUtils {
fun init () {
System . loadLibrary ( "jni-test" )
}
external fun hello (): String
}
创建Native代码文件,即C/C++文件 #include <jni.h>
#include <string>
#include <android/log.h>
#define LOG_TAG "Stephen JNI TEST"
extern "C" JNIEXPORT jstring JNICALL
Java_com_stephen_jnitest_JniUtils_hello (
JNIEnv * env , jobject ) {
const char * hello = "Hello from C++" ;
__android_log_print ( ANDROID_LOG_DEBUG , LOG_TAG ,
"This is my first time using android log in C++" );
__android_log_print ( ANDROID_LOG_DEBUG , LOG_TAG , "Hello String: [%s]" , hello );
return env -> NewStringUTF ( hello );
}
创建CmakeLists.txt脚本文件 cmake_minimum_required(VERSION 3.18.1)
project("jni-test")
add_library(jni-test SHARED
jni-test.cpp)
# Include libraries needed for lib
target_link_libraries(jni-test
android
log)
在gradle里配置构建脚本的路径 android {
externalNativeBuild {
cmake {
path = file ( "src/main/cpp/CMakeLists.txt" )
}
}
}
文件结构如下:
以上是在一个android library里进行的开发,完成后可以打包aar对外提供。
CMakeList写法 Google原生的提示模板:
# Sets the minimum version of CMake required to build your native library.
# This ensures that a certain set of CMake features is available to
# your build.
cmake_minimum_required ( VERSION 3.4.1)
# Specifies a library name, specifies whether the library is STATIC or
# SHARED, and provides relative paths to the source code. You can
# define multiple libraries by adding multiple add_library() commands,
# and CMake builds them for you. When you build your app, Gradle
# automatically packages shared libraries with your APK.
add_library ( # Specifies the name of the library.
native-lib
# Sets the library as a shared library.
SHARED
# Provides a relative path to your source file(s).
src/main/cpp/native-lib.cpp )
第一 addLibrary 需要制定库的名称,第二可以选择配置为静态库还是动态库方式,第三是源文件。
添加原生依赖库 向 CMake 构建脚本添加 find_library() 命令以找到 NDK 库并将其路径存储为一个变量。您可以使用此变量在构建脚本的其他部分引用 NDK 库。 比如引用Android原生的日志库:
find_library ( # Defines the name of the path variable that stores the
# location of the NDK library.
log-lib
# Specifies the name of the NDK library that
# CMake needs to locate.
log )
# Links your native library against one or more other native libraries.
target_link_libraries ( # Specifies the target library.
native-lib
# Links the log library to the target library.
${ log-lib } )
也可以使用 add_library() ,直接添加原生代码当作依赖,以下命令可以指示 CMake 将 android_native_app_glue.c(负责管理 NativeActivity 生命周期事件和触控输入)构建至静态库,并将其与 native-lib 关联:
add_library ( app-glue
STATIC
${ ANDROID_NDK } /sources/android/native_app_glue/android_native_app_glue.c )
# You need to link static libraries against your shared native library.
target_link_libraries ( native-lib app-glue ${ log-lib } )
添加头文件 在Android Studio中使用CMake添加头文件,你需要在 CMakeLists.txt 文件中使用 include_directories() 指令。这个指令告诉 CMake 在编译时需要包含哪些目录来搜索头文件。
例如,如果你有一个头文件目录位于 app/src/main/cpp/include ,你可以在 CMakeLists.txt 中添加如下指令:
include_directories ( include)
这行代码会告诉CMake在编译时需要包含 app/src/main/cpp/include 目录下的所有头文件。
完整的CMakeLists.txt示例如下:
cmake_minimum_required ( VERSION 3.18.1)
project ( "terminal-channel" )
add_library ( terminal-channel SHARED
common.cpp
process.cpp
termExec.cpp)
include_directories ( include)
target_link_libraries ( terminal-channel
android
log)
# 添加预构建库
add_library ( imported-lib
SHARED
IMPORTED )
# 然后,您需要使用 set_target_properties() 命令指定库的路径:
add_library ( ...)
set_target_properties ( # Specifies the target library.
imported-lib
# Specifies the parameter you want to define.
PROPERTIES IMPORTED_LOCATION
# Provides the path to the library you want to import.
imported-lib/src/${ ANDROID_ABI } /libimported-lib.so )
Android ABI 不同的 Android 设备使用不同的 CPU,而不同的 CPU 支持不同的指令集。CPU 与指令集的每种组合都有专属的应用二进制接口 (ABI)。ABI 包含以下信息:
可使用的 CPU 指令集(和扩展指令集)。 运行时内存存储和加载的字节顺序。Android 始终是 little-endian。 在应用和系统之间传递数据的规范(包括对齐限制),以及系统调用函数时如何使用堆栈和寄存器。 可执行二进制文件(例如程序和共享库)的格式,以及它们支持的内容类型。Android 始终使用 ELF。如需了解详情,请参阅 ELF System V 应用二进制接口。 如何重整 C++ 名称。如需了解详情,请参阅 Generic/Itanium C++ ABI。 armeabi-v7a ,此 ABI 适用于 32 位 ARM CPU。它包括 Thumb-2 和 Neon。
arm64-v8a ,此 ABI 适用于 64 位 ARM CPU。
x86 ,此 ABI 适用于支持通常称为“x86”“i386”或“IA-32”的指令集的 CPU。
x86_64 ,此 ABI 适用于支持通常称为“x86-64”的指令集的 CPU。
gradle配置 默认情况下,Gradle(无论是通过 Android Studio 使用,还是从命令行使用)会针对所有非弃用 ABI 进行构建。要限制应用支持的 ABI 集,请使用 abiFilters。例如,要仅针对 64 位 ABI 进行构建,请在 build.gradle 中设置以下配置:
android {
defaultConfig {
ndk {
abiFilters 'arm64-v8a', 'x86_64'
}
}
}
Native方法声明解析 以之前的 ndk-build 的方式声明的头文件为例:
/* DO NOT EDIT THIS FILE - it is machine generated */
#include <jni.h>
/* Header for class HelloJNI */
#ifndef _Included_HelloJNI
#define _Included_HelloJNI
#ifdef __cplusplus
extern "C" {
#endif
/*
* Class: HelloJNI
* Method: sayHello
* Signature: ()V
*/
JNIEXPORT jstring JNICALL Java_HelloJNI_sayHello ( JNIEnv * , jobject );
#ifdef __cplusplus
}
#endif
#endif
extern “C” 是告诉 C++ 编译器以 C 的方式来编译这个函数,以方便其他 C 程序链接和访问该函数。
C 和 C++ 有着不同的命名协议,因为 C++ 支持函数重载,用了不同的命名协议来处理重载的函数。在 C 中函数是通过函数名来识别的,而在 C++ 中,由于存在函数的重载问题,函数的识别方式通过函数名,函数的返回类型,函数参数列表三者组合来完成的。
因此两个相同的函数,经过C,C++编绎后会产生完全不同的名字。
所以,如果把一个用 C 编绎器编绎的目标代码和一个用 C++ 编绎器编绎的目标代码进行链接,就会出现链接失败的错误。
JNIEnv :JNIEnv 内部提供了很多函数,方便我们进行 JNI 编程。jobject :指向 “this” 的 Java 对象jclass :如果 java 中的 native 函数是 static 的,那第二个参数是 jclass ,代表了 java 中的 Class 类。JNIEXPORT 、 JNICALL 两个宏在 linux 平台的定义如下:// 该声明的作用是保证在本动态库中声明的方法 , 能够在其他项目中可以被调用
#define JNIEXPORT __attribute__ ((visibility ("default")))
// 一个空定义
#define JNICALL
JNI_ONLOAD 原生库 您可以使用标准 API 从共享库加载原生代码 System.loadLibrary() 。
事实上,旧版 Android 的 PackageManager 中存在导致安装和使原生库更新不可靠。 ReLinker 项目提供了解决此问题和其他原生库加载问题的解决方法。
从静态类调用 System.loadLibrary(或 ReLinker.loadLibrary) 初始化函数。参数是 “未修饰” 是的库名称 因此,要加载 libfubar.so ,您需要传入 “fubar”。
如果您只有一个类具有原生方法,则调用 System.loadLibrary() 位于该类的静态初始化程序中。否则,您应该从 Application 进行该调用,这样您就知道始终会加载该库,并且始终会提前加载。运行时可以通过两种方式找到您的原生方法。您可以请使用 RegisterNatives 注册它们;也可以让运行时动态查询它们和dlsym。
RegisterNatives 的优势在于,您可以提前还可以检查这些符号是否存在导出除 JNI_OnLoad 之外的任何内容。这样做的好处是让运行时因为它需要编写的代码略少一些。
如需使用 RegisterNatives,请执行以下操作:
提供 JNIEXPORT jint JNI_OnLoad(JavaVM* vm, void* reserved) 函数。 在 JNI_OnLoad 中,使用 RegisterNatives 注册所有原生方法。 使用 -fvisibility=hidden 进行构建,以便仅使用您的 JNI_OnLoad 。这样可以生成更快、更小的代码,并避免 与加载到您的应用中的其他库发生冲突(但创建的堆栈轨迹没有多大用处) (如果您的应用在原生代码中崩溃)。
JNI_OnLoad方法 Java JNI 有两种加载方法,一种是通过 javah ,获取一组带签名函数,然后实现这些函数。这种方法很常用,也是官方推荐的方法。还有一种就是 JNI_OnLoad 方法。
当Android的VM(Virtual Machine)执行到C组件(即*so档)里的 System.loadLibrary() 函数时,首先会去执行C组件里的 JNI_OnLoad() 函数。它的用途有二:
告诉 安卓虚拟机 此 C 组件使用哪一个 JNI 版本。如果你的 *.so 里没有提供 JNI_OnLoad() 函数,VM会默认该 *.so 档是使用最老的 JNI 1.1 版本。由于新版的JNI做了许多扩充,如果需要使用JNI的新版功能,例如 JNI 1.4 的 java.nio.ByteBuffer ,就必须借由 JNI_OnLoad() 函数来告知虚拟机。 由于虚拟机执行到 System.loadLibrary() 函数时,就会立即调用 JNI_OnLoad() ,所以 C 组件的开发者可以通过 JNI_OnLoad() 来进行 C 组件内的初期值之设定。 JNI_OnLoad 方法的内容比较固定:
JNIEXPORT jint JNI_OnLoad ( JavaVM * vm , void * reserved ) {
JNIEnv * env ;
if ( vm -> GetEnv ( reinterpret_cast < void **> ( & env ), JNI_VERSION_1_6 ) != JNI_OK ) {
return JNI_ERR ;
}
// Find your class. JNI_OnLoad is called from the correct class loader context for this to work.
jclass c = env -> FindClass ( "com/example/app/package/MyClass" );
if ( c == nullptr ) return JNI_ERR ;
// Register your class' native methods.
static const JNINativeMethod methods [] = {
{ "nativeFoo" , "()V" , reinterpret_cast < void *> ( nativeFoo )},
{ "nativeBar" , "(Ljava/lang/String;I)Z" , reinterpret_cast < void *> ( nativeBar )},
};
int rc = env -> RegisterNatives ( c , methods , sizeof ( methods ) / sizeof ( JNINativeMethod ));
if ( rc != JNI_OK ) return rc ;
return JNI_VERSION_1_6 ;
}
数据类型 基础数据类型 Java 类型 JNI 类型 C/C++ 类型 boolean jboolean unsigned char byte jbyte signed char char jchar unsigned short short jshort signed short int jint int long jlong long float jfloat float double jdouble double
以上基础类型可以随意互相转换,直接使用。
Kotlin:
external fun add ( a : Int , b : Int ): Int
external fun calChar ( charater : Char ): Char
C++:
extern "C" JNIEXPORT jint JNICALL
Java_com_stephen_jnitest_JniUtils_add ( JNIEnv * env , jobject , jint a , jint b ) {
return a + b ;
}
extern "C" JNIEXPORT jchar JNICALL
Java_com_stephen_jnitest_JniUtils_calChar ( JNIEnv * env , jobject , jchar a ) {
return a + 1 ;
}
引用类型 jni.h 中定义的非基本数据类型称为引用类型。
Java 类型 JNI 引用类型 类型描述 java.lang.Object jobject 表示任何Java的对象 java.lang.String jstring Java的String字符串类型的对象 java.lang.Class jclass Java的Class类型对象 java.lang.Throwable jthrowable Java的Throwable类型 byte[] jbyteArray Java byte型数组 Object[] jobjectArray Java任何对象的数组 boolean[] jbooleanArray Java boolean型数组 char[] jcharArray Java char型数组 short[] jshortArray Java short型数组 int[] jintArray Java int型数组 long[] jlongArray Java long型数组 float[] jfloatArray Java float型数组 double[] jdoubleArray Java double型数组
这些数据类型在使用时需要互相转换。一般的 native 方法中主要做了这么几件事:
接收 JNI 类型的参数 参数类型转换,JNI 类型转换为 Native 类型 执行 Native 代码 创建一个 JNI 类型的返回对象,将结果拷贝到这个对象并返回结果 字符串 为了在 C/C++ 中使用 Java 字符串,需要先将 Java 字符串转换成 C 字符串。用 GetStringChars 函数可以将 Unicode 格式的 Java 字符串转换成 C 字符串,用 GetStringUTFChars 函数可以将 UTF-8 格式的 Java 字符串转换成 C 字符串。这些函数的第三个参数均为 isCopy,它让调用者确定返回的 C 字符串地址指向副本还是指向堆中的固定对象。
JNIEXPORT jstring JNICALL Java_HelloJNI_sayHello__Ljava_lang_String_2 ( JNIEnv * env , jobject jobj , jstring str ) {
//jstring -> char*
jboolean isCopy ;
//GetStringChars 用于 unicode 编码
//GetStringUTFChars 用于 utf-8 编码
const char * cStr = env -> GetStringUTFChars ( str , & isCopy );
if ( nullptr == cStr ) {
return nullptr ;
}
if ( JNI_TRUE == isCopy ) {
cout << "C 字符串是 java 字符串的一份拷贝" << endl ;
} else {
cout << "C 字符串指向 java 层的字符串" << endl ;
}
cout << "C/C++ 层接收到的字符串是 " << cStr << endl ;
//通过JNI GetStringChars 函数和 GetStringUTFChars 函数获得的C字符串在原生代码中
//使用完之后需要正确地释放,否则将会引起内存泄露。
env -> ReleaseStringUTFChars ( str , cStr );
string outString = "Hello, JNI" ;
// char* 转换为 jstring
return env -> NewStringUTF ( outString . c_str ());
}
其中,isCopy 是一个指向 jboolean 类型变量的指针。调用该函数时,JNI 实现会把是否复制的信息存储在 isCopy 指向的变量中。
isCopy的比对结果过为:
JNI_TRUE :意味着获取的 C 字符串是 Java 字符串的一份拷贝。这表明 JNI 实现分配了新的内存来存储 Java 字符串的副本,在原生代码中使用完这个 C 字符串后,必须调用 ReleaseStringUTFChars 函数释放内存,不然会造成内存泄漏。JNI_FALSE :表示获取的 C 字符串直接指向 Java 层的字符串,JNI 实现没有创建副本。虽然此时不需要释放额外的内存,但仍要调用 ReleaseStringUTFChars 函数,以此告知 JNI 实现原生代码已经用完该字符串isCopy 变量主要用于调试和性能分析。一般来说,在实际开发中,不管 isCopy 的值是什么,都要调用 ReleaseStringUTFChars 函数来确保资源被正确释放。
字符串的其他常用操作函数 GetStringUTFChars/ReleaseStringUTFChars
Java 默认使用 UTF-16 编码,而 C/C++ 默认使用 UTF-8 编码。
UTF-8:适合网络传输、存储包含大量 ASCII 字符的文本,兼容性好,节省空间。 UTF-16:适合在 Java、Windows 等内部使用 16 位字符表示的系统中处理字符串,处理 BMP 内字符简单高效。 GetStringUTFChars 可以把一个 jstring 指针(指向 JVM 内部的 UTF-16 字符序列)转换成一个 UTF-8 编码的 C 风格字符串。
// 参数说明:
// * this: JNIEnv 指针
// * string: jstring类型(Java 传递给本地代码的字符串指针)
// * isCopy: 它的取值可以是 JNI_TRUE (值为1)或者为 JNI_FALSE (值为0)。如果值为 JNI_TRUE,表示返回 JVM 内部源字符串的一份拷贝,并为新产生的字符串分配内存空间。如果值为 JNI_FALSE,表示返回 JVM 内部源字符串的指针,意味着可以通过指针修改源字符串的内容,不推荐这么做,因为这样做就打破了 Java 字符串不能修改的规定。但我们在开发当中,并不关心这个值是多少,通常情况下这个参数填 NULL 即可。
const char * ( * GetStringUTFChars )( JNIEnv * , jstring , jboolean * ); //C环境中的定义
const char * GetStringUTFChars ( jstring string , jboolean * isCopy ) //C++环境中的定义
{ return functions -> GetStringUTFChars ( this , string , isCopy ); }
调用完 GetStringUTFChars 之后不要忘记安全检查,因为 JVM 可能需要为新诞生的字符串分配内存空间,当内存空间不够分配的时候,会导致调用失败,失败后 GetStringUTFChars 会返回 NULL,并抛出一个 OutOfMemoryError 异常。
JNI的异常和 Java 中的异常处理流程是不一样的,Java 遇到异常如果没有捕获,程序会立即停止运行。而 JNI 遇到未决的异常不会改变程序的运行流程,也就是程序会继续往下走,这样后面针对这个字符串的所有操作都是非常危险的,因此,我们需要用 return 语句跳过后面的代码,并立即结束当前方法。
// 参数说明:
// this: JNIEnv 指针
// string: 指向一个 jstring 变量,即是要释放的本地字符串的来源。在当前环境下指向 Java 中传递过来的 String 字符串对应的 JNI 数据类型 jstring
// utf:将要释放的C/C++本地字符串。即我们调用GetStringUTFChars获取的数据的存储指针。
void ( * ReleaseStringUTFChars )( JNIEnv * , jstring , const char * ); //C中的定义
void ReleaseStringUTFChars ( jstring string , const char * utf ) //C++中的定义
{ functions -> ReleaseStringUTFChars ( this , string , utf ); }
ReleaseStringUTFChars 函数用于通知虚拟机 jstring 在 jvm 中对应的内存已经不使用了,可以清除了。
GetStringChars/ReleaseStringChars
GetStringChars 返回字符串 string 对应的 UTF-16 字符数组的指针。在内存不足时抛出 OutOfMemoryError 异常。 ReleaseStringChars 通知虚拟机平台释放 chars 所引用的相关资源,以免造成内存泄漏。参数 chars 是一个指针,可通过 GetStringChars() 从 string 获得。
const jchar * ( GetStringChars )( JNIEnv env , jstring string , jboolean * isCopy );
void ReleaseStringChars ( JNIEnv * env , jstring string , const jchar * chars );
NewStringUTF
利用C风格字符串创建一个新的 java.lang.String 字符串对象。这个新创建的字符串会自动转换成 Java 支持的 UTF-16 编码。在内存不足时抛出 OutOfMemoryError 异常。
// 参数说明
// this: JNIEnv 指针
// bytes: 指向一个char * 变量,即要返回给 Java 层的 C/C++ 中字符串。
jstring ( * NewStringUTF )( JNIEnv * , const char * ); //C环境中定义
jstring NewStringUTF ( const char * bytes ) //C++环境中的定义
{ return functions -> NewStringUTF ( this , bytes ); }
NewString
利用 UTF-16 字符数组构造新的 java.lang.String 对象。在内存不足时抛出 OutOfMemoryError 异常。
jstring ( NewString )( JNIEnv env , const jchar * unicodeChars , jsize size );
GetStringUTFLength
返回字符串的 UTF-8 编码的长度,即 C 风格字符串的长度。
jsize ( GetStringUTFLength )( JNIEnv env , jstring string );
GetStringLength
返回字符串的 UTF-16 编码的长度,即 Java 字符串长度
const jchar * ( GetStringChars )( JNIEnv env , jstring string , jboolean * isCopy );
GetStringCritical/ReleaseStringCritical
此前提到的 Get/ReleaseStringChars 和 Get/ReleaseStringUTFChars 这对函数返回的源字符串会后分配内存,如果有一个字符串内容相当大,有 1M 左右,而且只需要读取里面的内容打印出来,用这两对函数就有些不太合适了。
此时用 Get/ReleaseStringCritical 可直接返回源字符串的指针应该是一个比较合适的方式。不过这对函数有一个很大的限制,在这两个函数之间的本地代码不能调用任何会让线程阻塞或等待 JVM 中其它线程的本地函数或 JNI 函数。因为通过 GetStringCritical 得到的是一个指向 JVM 内部字符串的直接指针,获取这个直接指针后会导致暂停 GC 线程,当 GC 被暂停后,如果其它线程触发 GC 继续运行的话,都会导致阻塞调用者。所以在Get/ReleaseStringCritical 这对函数中间的任何本地代码都不可以执行导致阻塞的调用或为新对象在 JVM 中分配内存,否则,JVM 有可能死锁。
另外,一定要记住检查是否因为内存溢出而导致它的返回值为 NULL,因为 JVM 在执行 GetStringCritical 这个函数时,仍有发生数据复制的可能性,尤其是当 JVM 内部存储的数组不连续时,为了返回一个指向连续内存空间的指针,JVM 必须复制所有数据。
与 GetStringUTFChars 相同, GetStringCritical 也可能在内存不足时抛出 OutOfMemoryError 异常。
GetStringRegion/GetStringUTFRegion
分别表示获取 UTF-16 和 UTF-8 编码字符串指定范围内的内容。 这对函数会把源字符串复制到一个预先分配的缓冲区内。
JNIEXPORT jstring JNICALL Java_HelloJNI_sayHello__Ljava_lang_String_2 ( JNIEnv * env , jobject jobj , jstring str ) {
char buff [ 128 ];
jsize len = env -> GetStringUTFLength ( str ); // 获取 utf-8 字符串的长度
// 将虚拟机平台中的字符串以 utf-8 编码拷入C缓冲区,该函数内部不会分配内存空间
env -> GetStringUTFRegion ( str , 0 , len , buff );
}
小结 对于小字符串来说,GetStringRegion 和 GetStringUTFRegion 这两对函数是最佳选择,因为缓冲区可以被编译器提前分配,而且永远不会产生内存溢出的异常。当你需要处理一个字符串的一部分时,使用这对函数也是不错。因为它们提供了一个开始索引和子字符串的长度值。另外,复制少量字符串的消耗也是非常小的。 使用 GetStringCritical 和 ReleaseStringCritical 这对函数时,必须非常小心。一定要确保在持有一个由 GetStringCritical 获取到的指针时,本地代码不会在 JVM 内部分配新对象,或者做任何其它可能导致系统死锁的阻塞性调用。 获取 Unicode 字符串和长度,使用 GetStringChars 和 GetStringLength 函数。获取 UTF-8 字符串的长度,使用 GetStringUTFLength 函数。 创建 Unicode 字符串,使用NewString,创建UTF-8使用 NewStringUTF 函数。 通过 GetStringUTFChars、GetStringChars、GetStringCritical 获取字符串,这些函数内部会分配内存,必须调用相对应的 ReleaseXXXX 函数释放内存。 数组 JNIEXPORT jdoubleArray JNICALL Java_HelloJNI_sumAndAverage ( JNIEnv * env , jobject obj , jintArray inJNIArray ) {
//类型转换 jintArray -> jint*
jboolean isCopy ;
jint * inArray = env -> GetIntArrayElements ( inJNIArray , & isCopy );
if ( JNI_TRUE == isCopy ) {
cout << "C 层的数组是 java 层数组的一份拷贝" << endl ;
} else {
cout << "C 层的数组指向 java 层的数组" << endl ;
}
if ( nullptr == inArray ) return nullptr ;
//获取到数组长度
jsize length = env -> GetArrayLength ( inJNIArray );
jint sum = 0 ;
for ( int i = 0 ; i < length ; ++ i ) {
sum += inArray [ i ];
}
jdouble average = ( jdouble ) sum / length ;
//释放数组
env -> ReleaseIntArrayElements ( inJNIArray , inArray , 0 ); // release resource
//构造返回数据,outArray 是指针类型,需要 free 或者 delete 吗?要的
jdouble outArray [] = { sum , average };
jdoubleArray outJNIArray = env -> NewDoubleArray ( 2 );
if ( NULL == outJNIArray ) return NULL ;
//向 jdoubleArray 写入数据
env -> SetDoubleArrayRegion ( outJNIArray , 0 , 2 , outArray );
return outJNIArray ;
}
使用时需要特别注意item对象的创建与释放。
JNI 中的数组分为基本类型数组和对象数组,它们的处理方式是不一样的,基本类型数组中的所有元素都是 JNI 的基本数据类型,可以直接访问。而对象数组中的所有元素是一个类的实例或其它数组的引用 ,和字符串操作一样,不能直接访问 Java 传递给 JNI 层的数组,必须选择合适的 JNI 函数来访问和设置 Java 层的数组对象。
引用数组 一维数组
JNIEXPORT jobjectArray JNICALL Java_com_xxx_jni_JNIArrayManager_operateStringArrray
( JNIEnv * env , jobject object , jobjectArray objectArray_in )
{
//获取到长度信息
jsize size = env -> GetArrayLength ( objectArray_in );
/*******获取从JNI传过来的String数组数据**********/
for ( int i = 0 ; i < size ; i ++ )
{
jstring string_in = ( jstring ) env -> GetObjectArrayElement ( objectArray_in , i );
char * char_in = env -> GetStringUTFChars ( str , nullptr );
}
/***********从JNI返回String数组给Java层**************/
jclass clazz = env -> FindClass ( "java/lang/String" );
jobjectArray objectArray_out ;
const int len_out = 5 ;
objectArray_out = env -> NewObjectArray ( len_out , clazz , NULL );
char * char_out [] = { "Hello," , "world!" , "JNI" , "is" , "fun" };
jstring temp_string ;
for ( int i = 0 ; i < len_out ; i ++ )
{
temp_string = env -> NewStringUTF ( char_out [ i ]) ;
env -> SetObjectArrayElement ( objectArray_out , i , temp_string );
}
return objectArray_out ;
}
二维数组
JNIEXPORT jobjectArray JNICALL Java_com_xxx_jni_JNIArrayManager_operateTwoIntDimArray ( JNIEnv * env , jobject object , jobjectArray objectArray_in )
{
/********** 解析从Java得到的int型二维数组 **********/
int i , j ;
const int row = env -> GetArrayLength ( objectArray_in ); //获取二维数组的行数
jarray array = ( jarray ) env -> GetObjectArrayElement ( objectArray_in , 0 );
const int col = env -> GetArrayLength ( array ); //获取二维数组每行的列数
//根据行数和列数创建int型二维数组
jint intDimArrayIn [ row ][ col ];
for ( i = 0 ; i < row ; i ++ )
{
array = ( jintArray ) env -> GetObjectArrayElement ( objectArray_in , i );
//操作方式一,这种方法会申请natvie memory内存
jint * coldata = env -> GetIntArrayElements (( jintArray ) array , NULL );
for ( j = 0 ; j < col ; j ++ ) {
intDimArrayIn [ i ] [ j ] = coldata [ j ]; //取出JAVA类中int二维数组的数据,并赋值给JNI中的数组
}
//操作方式二,赋值,这种方法不会申请内存
// env->GetIntArrayRegion((jintArray)array, 0, col, (jint*)&intDimArrayIn[i]);
env -> ReleaseIntArrayElements (( jintArray ) array , coldata , 0 );
}
/**************创建一个int型二维数组返回给Java**************/
const int row_out = 2 ; //行数
const int col_out = 2 ; //列数
//获取数组的class
jclass clazz = env -> FindClass ( "[I" ); //一维数组的类
//新建object数组,里面是int[]
jobjectArray intDimArrayOut = env -> NewObjectArray ( row_out , clazz , NULL );
int tmp_array [ row_out ][ col_out ] = { { 0 , 1 }, { 2 , 3 } };
for ( i = 0 ; i < row_out ; i ++ )
{
jintArray intArray = env -> NewIntArray ( col_out );
env -> SetIntArrayRegion ( intArray , 0 , col_out , ( jint * ) & tmp_array [ i ]);
env -> SetObjectArrayElement ( intDimArrayOut , i , intArray );
}
return intDimArrayOut ;
}
GetArrayLength
jsize ( GetArrayLength )( JNIEnv env , jarray array );
返回数组中的元素个数
NewObjectArray
jobjectArray NewObjectArray ( JNIEnv * env , jsize length , jclass elementClass , jobject initialElement );
构建 JNI 引用类型的数组,它将保存类 elementClass 中的对象。所有元素初始值均设为 initialElement,一般使用 NULL 就好。如果系统内存不足,则抛出 OutOfMemoryError 异常。
GetObjectArrayElement和SetObjectArrayElement
jobject GetObjectArrayElement ( JNIEnv * env , jobjectArray array , jsize index )
返回 jobjectArray 数组的元素,通常是获取 JNI 引用类型数组元素。如果 index 不是数组中的有效下标,则抛出ArrayIndexOutOfBoundsException 异常。
void SetObjectArrayElement ( JNIEnv * env , jobjectArray array , jsize index , jobject value )
设置 jobjectArray 数组中 index 下标对象的值。如果 index 不是数组中的有效下标,则会抛出 ArrayIndexOutOfBoundsException 异常。如果 value 的类不是数组元素类的子类,则抛出 ArrayStoreException 异常。
New<PrimitiveType>Array 函数集
NativeTypeArray New<PrimitiveType>Array (JNIEnv* env, jsize size)
用于构造 JNI 基本类型数组对象。
在实际应用中把 PrimitiveType 替换为某个实际的基本类型数据类型,然后再将 NativeType 替换成对应的 JNI Native Type 即可,具体的:
函数名 返回类型
NewBooleanArray() jbooleanArray
NewByteArray() jbyteArray
NewCharArray() jcharArray
NewShortArray() jshorArray
NewIntArray() jintArray
NewLongArray() jlongArray
NewFloatArray() jfloatArray
NewDoubleArray() jdoubleArray
Get/ReleaseArrayElements函数集
NativeType* Get<PrimitiveType>ArrayElements(JNIEnv *env, NativeTypeArray array, jboolean *isCopy)
该函数用于将 JNI 数组类型转换为 JNI 基本数据类型数组,在实际使用过程中将 PrimitiveType 替换成某个实际的基本类型元素访问函数,然后再将NativeType替换成对应的 JNI Native Type 即可:
函数名 转换前类型 转换后类型
GetBooleanArrayElements() jbooleanArray jboolean*
GetByteArrayElements() jbyteArray jbyte*
GetCharArrayElements() jcharArray jchar*
GetShortArrayElements() jshortArray jshort*
GetIntArrayElements() jintArray jint*
GetLongArrayElements() jlongArray jlong*
GetFloatArrayElements() jfloatArray jfloat*
GetDoubleArrayElements() jdoubleArray jdouble*
void Release < PrimitiveType > ArrayElements ( JNIEnv * env , NativeTypeArray array , NativeType * elems , jint mode );
该函数用于通知 JVM,数组不再使用,可以清理先关内存了。在实际使用过程中将 PrimitiveType 替换成某个实际的基本类型元素访问函数,然后再将 NativeType 替换成对应的 JNI Native Type 即可:
函数名 NativeTypeArray NativeType
ReleaseBooleanArrayElements() jbooleanArray jboolean
ReleaseByteArrayElements() jbyteArray jbyte
ReleaseCharArrayElements() jcharArray jchar
ReleaseShortArrayElements() jshortArray jshort
ReleaseIntArrayElements() jintArray jint
ReleaseLongArrayElements() jlongArray jlong
ReleaseFloatArrayElements() jfloatArray jfloat
ReleaseDoubleArrayElements() jdoubleArray
jdoubleGet/Set<PrimitiveType>ArrayRegion
void Set < PrimitiveType > ArrayRegion ( JNIEnv * env , NativeTypeArray array , jsize start , jsize len , NativeType * buf );
该函数用于将基本类型数组某一区域复制到 JNI 数组类型中。在实际使用过程中将 PrimitiveType 替换成某个实际的基本类型元素访问函数,然后再将 NativeType 替换成对应的 JNI Native Type 即可:
函数名 NativeTypeArray NativeType
SetBooleanArrayRegion() jbooleanArray jboolean
SetByteArrayRegion() jbyteArray jbyte
SetCharArrayRegion() jcharArray jchar
SetShortArrayRegion() jshortArray jshort
SetIntArrayRegion() jintArray jint
SetLongArrayRegion() jlongArray jlong
SetFloatArrayRegion() jfloatArray jfloat
SetDoubleArrayRegion() jdoubleArray jdouble
防止 Native 内存泄漏 JNI 层作为 Java 层和 Native 层之间相交互的中间层,它兼具 Native 层和 Java 层的某些特性,尤其在对引用对象的创建和回收上。
和 C++ 里的 new 操作符可以创建一个对象类似,JNI 层可以利用 JNI NewObject 等函数创建一个 Java 意义的对象(引用型对象)。这个被 New 出来的对象是局部(Local) 型的引用对象。 JNI 层可通过 DeleteLocalRef 释放 Local 型的引用对象(等同于Java 层中设置持有这个对象的变量的值为 null)。如果不调用 DeleteLocalRef 的话,根据 JNI 规范,Local 型对象在 JNI 函数返回后,也会由虚拟机根据垃圾回收的逻辑进行标记和回收。 除了 Local 型对象外,JNI 层借助JNI Global 相关函数可以将一个 Local 型引用对象转换成一个全局(Global) 型对象。而 Global 型对象的回收只能先由程序显式地调用 Global 相关函数进行删除,然后,虚拟机才能借助垃圾回收机制回收它们。 引用类型针对的是除开基本类型的 JNI 类型,比如 jstring, jclass ,jobject 等。JNI 类型是 java 层与 c 层的中间类型,java 层与 c 层都需要管理他。我们可以将 JNI 引用类型理解为 Java 意义的对象。
JNI 类型根据使用的方式可分为:
局部引用 什么是局部引用? 通过 JNI 接口从 Java 传递下来或者通过 NewLocalRef 和各种 JNI 接口(FindClass、NewObject、GetObjectClass和NewCharArray等)创建的引用称为局部引用。
局部引用的特点? 在函数为执行完毕前,局部引用会阻止 GC 回收所引用的对象 局部引用不能在本地函数中跨函数使用,不能跨线程使用,当然也不能直接缓存起来使用 函数返回后(未返回局部引用的情况下),局部引用所引用的对象会被 JVM 自动释放,也可在函数结束前通过 DeleteLocalRef 函数手动释放 如果 c 函数返回了一个局部引用数据,在 java 层,该类型会转换为对应的 java 类型。当 java 层不存在该对象的引用时,gc 就会回收该对象 释放局部引用 局部引用在本地方法执行完会被自动回收,但是有些场景最好是我们手动回收一次。
JNI 会将创建的局部引用都存储在一个局部引用表中,如果这个表超过了最大容量限制,就会造成局部引用表溢出,使程序崩溃。经测试,Android上的 JNI 局部引用表最大数量是 512 个。当我们在实现一个本地方法时,可能需要创建大量的局部引用,如果没有及时释放,就有可能导致 JNI 局部引用表的溢出,所以,在不需要局部引用时就立即调用 DeleteLocalRef 手动删除。 在编写 JNI 工具函数时,工具函数在程序当中是公用的,被谁调用你是不知道的。其内部的局部引用在使用完成后应该立即释放,避免过多的内存占用。 如果你的本地函数不会返回。比如一个接收消息的函数,里面有一个死循环,用于等待别人发送消息过来 while(true) { if (有新的消息) { 处理之。。。。} else { 等待新的消息。。。}} 。如果在消息循环当中创建的引用你不显示删除,很快将会造成JVM局部引用表溢出。 局部引用使用完了就删除,而不是要等到函数结尾才释放,局部引用会阻止所引用的对象被 GC 回收。比如你写的一个本地函数中刚开始需要访问一个大对象,因此一开始就创建了一个对这个对象的引用,但在函数返回前会有一个大量的非常复杂的计算过程,而在这个计算过程当中是不需要前面创建的那个大对象的引用的。但是,在计算的过程当中,如果这个大对象的引用还没有被释放的话,会阻止 GC 回收这个对象,内存一直占用者,造成资源的浪费。所以这种情况下,在进行复杂计算之前就应该把引用给释放了,以免不必要的资源浪费。 言而总之,当一个局部引用不在使用后,立即将其释放,以避免不必要的内存浪费。 本地方法中局部引用的数量 JNI 的规范指出,JVM 要确保每个 Native 方法至少可以创建 16 个局部引用,经验表明,16 个局部引用已经足够平常的使用了。 但是,如果要与 JVM 中的对象进行复杂的交互计算,就需要创建更多的局部引用了,这时就需要使用 EnsureLocalCapacity 来确保可以创建指定数量的局部引用,如果创建成功返回 0 ,返回返回小于 0 ,如下代码示例:
// Use EnsureLocalCapacity
int len = 20 ;
if ( env -> EnsureLocalCapacity ( len ) < 0 ) {
// 创建失败,out of memory
}
for ( int i = 0 ; i < len ; ++ i ) {
jstring jstr = env -> GetObjectArrayElement ( arr , i );
// 处理 字符串
// 创建了足够多的局部引用,这里就不用删除了,显然占用更多的内存
}
确保可以创建了足够的局部引用数量,所以在循环处理局部引用时可以不进行删除了,但是显然会消耗更多的内存空间了。
循环中的局部引用,有更好的做法:
PushLocalFrame 与 PopLocalFrame 是两个配套使用的函数对。它们可以为局部引用创建一个指定数量内嵌的空间,在这个函数对之间的局部引用都会在这个空间内,直到释放后,所有的局部引用都会被释放掉,不用再担心每一个局部引用的释放问题了。
// Use PushLocalFrame & PopLocalFrame
for ( int i = 0 ; i < len ; ++ i ) {
if ( env -> PushLocalFrame ( len )) { // 创建指定数据的局部引用空间
//out ot memory
}
jstring jstr = env -> GetObjectArrayElement ( arr , i );
// 处理字符串
// 期间创建的局部引用,都会在 PushLocalFrame 创建的局部引用空间中
// 调用 PopLocalFrame 直接释放这个空间内的所有局部引用
env -> PopLocalFrame ( NULL );
}
使用 PushLocalFrame & PopLocalFrame 函数对,就可以在期间放心地处理局部引用,最后统一释放掉。
全局引用 全局引用可以跨方法、跨线程使用,直到它被手动释放才会失效。同局部引用一样,也会阻止它所引用的对象被 GC 回收。与局部引用不一样的是,函数执行完后,GC 也不会回收全局引用指向的对象。与局部引用创建方式不同的是,只能通过 NewGlobalRef 函数创建。
static jclass cls_string = NULL ;
if ( cls_string == NULL ) {
jclass local_cls_string = ( * env ) -> FindClass ( env , "java/lang/String" );
if ( cls_string == NULL ) {
return NULL ;
}
// 将java.lang.String类的Class引用缓存到全局引用当中
cls_string = ( * env ) -> NewGlobalRef ( env , local_cls_string );
// 删除局部引用
( * env ) -> DeleteLocalRef ( env , local_cls_string );
// 再次验证全局引用是否创建成功
if ( cls_string == NULL ) {
return NULL ;
}
}
当我们的本地代码不再需要一个全局引用时,应该马上调用 DeleteGlobalRef 来释放它。如果不手动调用这个函数,即使这个对象已经没用了,JVM 也不会回收这个全局引用所指向的对象。
弱全局引用 弱全局引用使用 NewGlobalWeakRef 创建,使用 DeleteGlobalWeakRef 释放。下面简称弱引用。与全局引用类似,弱引用可以跨方法、线程使用。但与全局引用很重要不同的一点是,弱引用不会阻止 GC 回收它引用的对象。
static jclass myCls2 = NULL ;
if ( myCls2 == NULL )
{
jclass myCls2Local = ( * env ) -> FindClass ( env , "mypkg/MyCls2" );
if ( myCls2Local == NULL )
{
return ; /* 没有找到mypkg/MyCls2这个类 */
}
myCls2 = NewWeakGlobalRef ( env , myCls2Local );
if ( myCls2 == NULL )
{
return ; /* 内存溢出 */
}
}
... /* 使用myCls2的引用 */
引用之间的比较 IsSameObject 用来判断两个引用是否指向相同的对象。还可以用 isSameObject 来比较弱全局引用所引用的对象是否被 GC 了,返回 JNI_TRUE 则表示回收了,JNI_FALSE 则表示未被回收。
env -> IsSameObject ( obj1 , obj2 ) // 比较两个引用是否指向相同的对象
env -> IsSameObject ( obj , NULL ) // 比较局部引用或者全局引用是否为 NULL
env -> IsSameObject ( wobj , NULL ) // 比较弱全局引用所引用对象是否被 GC 回收
一些疑问:如果 C 层返回给 java 层一个全局引用,这个全局引用何时可以被 GC 回收? 我认为不会被 GC 回收,造成内存泄漏。 所以 JNI 函数如果要返回一个对象,我们应该使用局部引用作为返回值。
描述符 描述符即 JVM 对类,数据,方法等,在Native层的标记方式。
类描述符 在 JNI 的 Native 方法中,我们要使用 Java 中的对象怎么办?即在 C/C++ 中怎么找到 Java 中的类,这就要使用到 JNI 开发中的类描述符了 JNI 提供的函数中有个 FindClass() 就是用来查找 Java 类的,其参数必须放入一个类描述符字符串,类描述符一般是类的完整名称(包名+类名) 一个 Java 类对应的描述符,就是类的全名,其中符号 . 要换成 / :
// 完整类名: java.lang.String
// 对应类描述符: java/lang/String
jclass intArrCls = env -> FindClass ( “ java / lang / String ” )
jclass clazz = FindClassOrDie ( env , "android/view/Surface" );
域描述符 域描述符是 JNI 中对 Java 数据类型的一种表示方法。在 JVM 虚拟机中,存储数据类型的名称时,是使用指定的描述符来存储,而不是我们习惯的 int,float 等。
虽然有类描述符,但是类描述符里并没有说明基本类型和数组类型如何表示,所以在 JNI 中就引入了域描述符的概念。
接着我们通过一个表格来了解域描述符的定义:
类型标识 Java数据类型 Z boolean B byte C char S short I int J long F float D double L包名/类名; 各种引用类型 V void [ 数组 方法 (参数)返回值
接着我们来看几个例子:
Java类型: java.lang.String
JNI 域描述符:Ljava/lang/String; //注意结尾有分号
Java类型: int[]
JNI域描述符: [I
Java类型: float[]
JNI域描述符: [F
Java类型: String[]
JNI域描述符: [Ljava/lang/String;
Java类型: Object[]
JNI域描述符: [Ljava/lang/Object;
Java类型: int[][]
JNI域描述符: [[I
Java类型: float[][]
JNI域描述符: [[F
方法描述符 方法描述符是 JVM 中对函数(方法)的标记方式,看几个例子就能基本掌握其命名特点了:
Java 方法 方法描述符
String fun() ()Ljava/lang/String;
int fun(int i, Object object) (ILjava/lang/Object;)I
void fun(byte[] bytes) ([B)V
int fun(byte data1, byte data2) (BB)I
void fun() ()V
JavaVM JavaVM(Java Virtual Machine)是 Java 程序的运行环境,负责执行 Java 字节码。
在 JNI 开发中,JavaVM 是一个关键的组件,它提供了许多与 Java 运行环境相关的功能,比如加载类、创建对象等。还有管理Java线程,调用Java方法,访问Java对象等。
JavaVM有以下特点:
JavaVM 是一个结构体,用于描述 Java 虚拟机。 一个 JVM 中只有一个 JavaVM 对象。在 Android 平台上,一个 Java 进程只能有一个 ART 虚拟机,也就是说一个进程只有一个 JavaVM 对象。 JavaVM 可以在进程中的各线程间共享。 JavaVM实例通常是应用启动时自动创建,在 JNI 开发中,通常需要先获取 JavaVM 接口指针。这可以在 JNI_OnLoad 函数中完成。在动态注册的方式中,JNI_OnLoad 是一个由 JNI 库提供的函数,当 Java 虚拟机加载本地库(包含 JNI 代码的库)时会调用这个函数。
#include <jni.h>
JNIEXPORT jint JNICALL JNI_OnLoad ( JavaVM * vm , void * reserved ) {
JNIEnv * env ;
// 验证版本
if ( vm -> GetEnv (( void ** ) & env , JNI_VERSION_1_6 ) != JNI_OK ) {
return - 1 ;
}
// 保存JavaVM指针,方便后续使用
static JavaVM * savedVm = vm ;
return JNI_VERSION_1_6 ;
}
也可以通过 JNIEnv 的函数获取到 JavaVM:
JavaVM * gJavaVM ;
JNIEXPORT jstring JNICALL Java_HelloJNI_sayHello ( JNIEnv * env , jobject obj )
{
env -> GetJavaVM ( & gJavaVM );
return ( * env ) -> NewStringUTF ( env , "Hello from JNI !" );
}
JNIEnv JNIEnv 即 Java Native Interface Environment,Java 本地编程接口环境。 JNIEnv 内部定义了很多函数用于简化我们的 JNI 编程。
JNI 把 Java 中的所有对象或者对象数组当作一个 C 指针传递到本地方法中,这个指针指向 JVM 中的内部数据结构(对象用jobject来表示,而对象数组用jobjectArray或者具体是基本类型数组),而内部的数据结构在内存中的存储方式是不可见的,我们只能从 JNIEnv 指针指向的函数表中选择合适的 JNI 函数来操作JVM 中的数据结构。
C 在 C 语言中, JNIEnv 是一个指向 JNINativeInterface_ 结构体的指针。 JNINativeInterface_ 结构体中定义了非常多的函数指针,这些函数用于简化我们的 JNI 编程。C 语言中,JNIEnv 中函数的使用方式如下:
//JNIEnv * env
// env 的实际类型是 JNINativeInterface_**
( * env ) -> NewStringUTF ( env , "Hello from JNI !" );
C++ 在 C++ 代码中,JNIEnv 是一个 JNIEnv_ 结构体。JNIEnv_ 结构体中同样定义了非常多的成员函数,这些函数用于简化我们的 JNI 编程。C++ 语言中,JNIEnv 中函数的使用方式如下:
//JNIEnv * env
// env 的实际类型是 JNIEnv_*
env -> NewstringUTF ( "Hello from JNI ! " );
可以将其看成每个线程的独立的工具类,方便进行一系列的操作,简化JNI编程。 使用时要区分单线程和多线程的场景。
单线程 可以直接通过JNI方法传入的参数拿到指针对象来使用:
// 第一个参数就是 JNIEnv
JNIEXPORT jstring JNICALL Java_HelloJNI_sayHello ( JNIEnv * env , jobject obj )
{
return ( * env ) -> NewStringUTF ( env , "Hello from JNI !" );
}
多线程 JNIEnv 是一个线程作用域的变量,不能跨线程传递,不同线程的 JNIEnv 彼此独立。多线程使用之前需要先声明一个指针,再将其和线程绑定,指向这个线程自己的JniEnv实例所在的位置。使用完毕之后再解绑定。
//定义全局变量
//JavaVM 是一个结构体,用于描述 Java 虚拟机,后面会讲
JavaVM * gJavaVM ;
JNIEXPORT jstring JNICALL Java_HelloJNI_sayHello ( JNIEnv * env , jobject obj )
{
//线程不允许共用env环境变量,但是JavaVM指针是整个jvm共用的,所以可以通过下面的方法保存JavaVM指针,在线程中使用
env -> GetJavaVM ( & gJavaVM );
return ( * env ) -> NewStringUTF ( env , "Hello from JNI !" );
}
//假设这是一个工具函数,可能被多个线程调用
void util_xxx ()
{
JNIEnv * env ;
//从全局的JavaVM中获取到环境变量
gJavaVM -> AttachCurrentThread ( & env , NULL );
//就可以使用 JNIEnv 了
//最后需要做清理操作
gJavaVM -> DetachCurrentThread ();
}
一些函数:
函数名 功能 FindClass 用于获取类 GetObjectClass 通过对象获取这个类 NewGlobalRef 创建 obj 参数所引用对象的新全局引用 NewObject 构造新 Java 对象 NewString 利用 Unicode 字符数组构造新的 java.lang.String 对象 NewStringUTF 利用 UTF-8 字符数组构造新的 java.lang.String 对象 New<Type>Array 创建类型为Type的数组对象 Get<Type>Field 获取类型为Type的字段 Set<Type>Field 设置类型为Type的字段的值 GetStatic<Type>Field 获取类型为Type的static的字段 SetStatic<Type>Field 设置类型为Type的static的字段的值 Call<Type>Method 调用返回类型为Type的方法 CallStatic<Type>Method 调用返回值类型为Type的static方法
相关的函数不止上面的这些,这些函数的介绍和使用方法。我们可以在开发过程中参考官方文档: Oracle官方JNI文档
Native 访问 Java 层 访问成员变量 访问一个类成员基本分为三步:
获取到类对应的 jclass 对象(对应于 Java 层的 Class 对象),jclss 是一个局部引用,使用完后记得使用 DeleteLocalRef 以避免局部引用表溢出。 获取到需要访问的类成员的 jfieldID,jfieldID 不是一个 JNI 引用类型,是一个普通指针,指针指向的内存又 JVM 管理,我们无需在使用完后执行 free 清理操作 根据被访问对象的类型,使用 GetxxxField 和 SetxxxField 来获得/设置成员变量的值 Java:
//定义一个被访问的类
public class TestJavaClass {
private String mString = "Hello JNI, this is normal string !" ;
private static int mStaticInt = 0 ;
}
//定义两个 native 方法
public native void accessJavaFiled ( TestJavaClass testJavaClass );
public native void accessStaticField ( TestJavaClass testJavaClass );
C++:
//访问成员变量
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_accessJavaFiled ( JNIEnv * env , jobject thiz , jobject test_java_class ) {
jclass clazz ;
jfieldID mString_fieldID ;
//获得 TestJavaClass 的 jclass 对象
// jclass 类型是一个局部引用
clazz = env -> GetObjectClass ( test_java_class );
if ( clazz == NULL ) {
return ;
}
//获得 mString 的 fieldID
mString_fieldID = env -> GetFieldID ( clazz , "mString" , "Ljava/lang/String;" );
if ( mString_fieldID == NULL ) {
return ;
}
//获得 mString 的值
jstring j_string = ( jstring ) env -> GetObjectField ( test_java_class , mString_fieldID );
//GetStringUTFChars 分配了内存,需要使用 ReleaseStringUTFChars 释放
const char * buf = env -> GetStringUTFChars ( j_string , NULL );
//修改 mString 的值
char * buf_out = "Hello Java, I am JNI!" ;
jstring temp = env -> NewStringUTF ( buf_out );
env -> SetObjectField ( test_java_class , mString_fieldID , temp );
//jfieldID 不是 JNI 引用类型,不用 DeleteLocalRef
// jfieldID 是一个指针类型,其内存的分配与回收由 JVM 负责,不需要我们去 free
//free(mString_fieldID);
//释放内存
env -> ReleaseStringUTFChars ( j_string , buf );
//释放局部引用表
env -> DeleteLocalRef ( j_string );
env -> DeleteLocalRef ( clazz );
}
//访问静态成员变量
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_accessStaticField ( JNIEnv * env , jobject thiz ,
jobject test_java_class ) {
jclass clazz ;
jfieldID mStaticIntFiledID ;
clazz = env -> GetObjectClass ( test_java_class );
if ( clazz == NULL ) {
return ;
}
mStaticIntFiledID = env -> GetStaticFieldID ( clazz , "mStaticInt" , "I" );
//获取静态成员
jint mInt = env -> GetStaticIntField ( clazz , mStaticIntFiledID );
//修改静态成员
env -> SetStaticIntField ( clazz , mStaticIntFiledID , 10086 );
env -> DeleteLocalRef ( clazz );
}
调用Java方法 Native 访问一个 Java 方法基本分为三步:
获取到类对应的 jclass 对象(对应于 Java 层的 Class 对象),jclss 是一个局部引用,使用完后记得使用 DeleteLocalRef 以避免局部引用表溢出。 获取到需要访问的方法的 jmethodID,jmethodID 不是一个 JNI 引用类型,是一个普通指针,指针指向的内存由 JVM 管理,我们无需在使用完后执行 free 清理操作 接着就可以调用 CallxxxMethod/CallStaticxxxMethod 来调用对于的方法,xxx 是方法的返回类型。 Java:
//等待被 native 层访问的 java 类
public class TestJavaClass {
//......
private void myMethod () {
Log . i ( "JNI" , "this is java myMethod" );
}
private static void myStaticMethod () {
Log . d ( "JNI" , "this is Java myStaticMethod" );
}
}
//本地方法
public native void accessJavaMethod ();
public native void accessStaticMethod ();
C++:
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_accessJavaMethod ( JNIEnv * env , jobject thiz ) {
//获取 TestJavaClass 对应的 jclass
jclass clazz = env -> FindClass ( "com/yuandaima/myjnidemo/TestJavaClass" );
if ( clazz == NULL ) {
return ;
}
//构造函数 id
jmethodID java_construct_method_id = env -> GetMethodID ( clazz , "<init>" , "()V" );
if ( java_construct_method_id == NULL ) {
return ;
}
//创建一个对象
jobject object_test = env -> NewObject ( clazz , java_construct_method_id );
if ( object_test == NULL ) {
return ;
}
//获得 methodid
jmethodID java_method_id = env -> GetMethodID ( clazz , "myMethod" , "()V" );
if ( java_method_id == NULL ) {
return ;
}
//调用 myMethod 方法
env -> CallVoidMethod ( object_test , java_method_id );
//清理临时引用吧
env -> DeleteLocalRef ( clazz );
env -> DeleteLocalRef ( object_test );
}
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_accessStaticMethod ( JNIEnv * env , jobject thiz ) {
jclass clazz = env -> FindClass ( "com/yuandaima/myjnidemo/TestJavaClass" );
if ( clazz == NULL ) {
return ;
}
jmethodID static_method_id = env -> GetStaticMethodID ( clazz , "myStaticMethod" , "()V" );
if ( NULL == static_method_id )
{
return ;
}
env -> CallStaticVoidMethod ( clazz , static_method_id );
env -> DeleteLocalRef ( clazz );
}
异常处理 JNIEnv 内部函数抛出的异常 很多 JNIEnv 中的函数都会抛出异常,处理方法大体上是一致的:
返回值与特殊值(一般是 NULL)比较,知晓函数是否发生异常 如果发生异常立即 return jvm 会将异常抛给 java 层,我们可以在 java 层通过 try catch 机制捕获异常 JAVA:
public native void exceptionTest ();
//调用
try {
exceptionTest ();
} catch ( Exception e ) {
e . printStackTrace ();
}
C++:
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_exceptionTest ( JNIEnv * env , jobject thiz ) {
//查找的类不存在,返回 NULL;
jclass clazz = env -> FindClass ( "com/yuandaima/myjnidemo/xxx" );
if ( clazz == NULL ) {
return ; //return 后,jvm 会向 java 层抛出 ClassNotFoundException
}
}
// result:
java . lang . ClassNotFoundException : Didn ' t find class "com.yuandaima.myjnidemo.xxx" Native 回调 Java 层方法,被回调的方法抛出异常
Native 回调 Java 层方法,被回调的方法抛出异常。这样情况下一般有两种解决办法:
Java 层 Try catch 本地方法,这是比较推荐的办法。 Native 层处理异常,异常处理如果和 native 层相关,可以采用这种方式Native层不处理异常,Java层来处理异常 java:
//执行这个方法会抛出异常
private static int exceptionMethod () {
return 20 / 0 ;
}
//native 方法,在 native 中,会调用到 exceptionMethod() 方法
public native void exceptionTest ();
// MainActivity中调用是加上try-catch:
//Java 层调用
try {
exceptionTest ();
} catch ( Exception e ) {
//这里处理异常
//一般是打 log 和弹 toast 通知用户
e . printStackTrace ();
}
C++:
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_exceptionTest ( JNIEnv * env , jobject thiz ) {
jclass clazz = env -> FindClass ( "com/yuandaima/myjnidemo/TestJavaClass" );
if ( clazz == NULL ) {
return ;
}
//调用 java 层会抛出异常的方法
jmethodID static_method_id = env -> GetStaticMethodID ( clazz , "exceptionMethod" , "()I" );
if ( NULL == static_method_id ) {
return ;
}
//直接调用,发生 ArithmeticException 异常,传回 Java 层
env -> CallStaticIntMethod ( clazz , static_method_id );
env -> DeleteLocalRef ( clazz );
}
Native来处理异常 有的异常需要在 Native 处理,这里又分为两类:
异常在 Native 层就处理完了 异常在 Native 层处理了,还需要返回给 Java 层,Java 层继续处理 java:
//执行这个方法会抛出异常
private static int exceptionMethod () {
return 20 / 0 ;
}
//native 方法,在 native 中,会调用到 exceptionMethod() 方法
public native void exceptionTest ();
//Java 层调用
try {
exceptionTest ();
} catch ( Exception e ) {
//这里处理异常
//一般是打 log 和弹 toast 通知用户
e . printStackTrace ();
}
C++:
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_exceptionTest ( JNIEnv * env , jobject thiz ) {
jthrowable mThrowable ;
jclass clazz = env -> FindClass ( "com/yuandaima/myjnidemo/TestJavaClass" );
if ( clazz == NULL ) {
return ;
}
jmethodID static_method_id = env -> GetStaticMethodID ( clazz , "exceptionMethod" , "()I" );
if ( NULL == static_method_id ) {
return ;
}
env -> CallStaticIntMethod ( clazz , static_method_id );
//检测是否有异常发生
if ( env -> ExceptionCheck ()) {
//获取到异常对象
mThrowable = env -> ExceptionOccurred ();
//这里就可以根据实际情况处理异常了
//.......
//打印异常信息堆栈
env -> ExceptionDescribe ();
//清除异常信息
//如果,异常还需要 Java 层处理,可以不调用 ExceptionClear,让异常传递给 Java 层
env -> ExceptionClear ();
//如果调用了 ExceptionClear 后,异常还需要 Java 层处理,我们可以抛出一个新的异常给 Java 层
jclass clazz_exception = env -> FindClass ( "java/lang/Exception" );
env -> ThrowNew ( clazz_exception , "JNI抛出的异常!" );
env -> DeleteLocalRef ( clazz_exception );
}
env -> DeleteLocalRef ( clazz );
env -> DeleteLocalRef ( mThrowable );
}
引用类型的内存分析 Java 程序使用的内存 从逻辑上可以分为两个部分:
Java Memory 就是我们的 Java 程序使用的内存,通常从逻辑上区分为栈和堆。方法中的局部变量通常存储在栈中,引用类型指向的对象一般存储在堆中。Java Memory 由 JVM 分配和管理,JVM 中通常会有一个 GC 线程,用于回收不再使用的内存。
Java 程序的执行依托于 JVM ,JVM 一般使用 C/C++ 代码编写,需要根据 Native 编程规范去操作内存。如:C/C++ 使用 malloc()/new 分配内存,需要手动使用 free()/delete 回收内存。这部分内存我们称为 Native Memory。
Java 中的对象对应的内存,由 JVM 来管理,他们都有自己的数据结构。当我们通过 JNI 将一个 Java 对象传递给 Native 程序时,Native 程序要操作这块内存时(即操作这个对象),就需要了解这个数据结构,显然这有点麻烦了,所以 JVM 的设计者在 JNIenv 中定义了很多函数(NewStringUTF,FindClass,NewObject 等)来帮你操作和构造这些对象。同时也提供了引用类型(jobject、jstring、jclass、jarray、jintArray等)来引用这些对象。
明确引用类型的范围 引用类型是指针,指向的是 Java 中的对象在 JVM 中对应的内存。引用类型的定义如下:
#ifdef __cplusplus
class _jobject {};
class _jclass : public _jobject {};
class _jthrowable : public _jobject {};
class _jstring : public _jobject {};
class _jarray : public _jobject {};
class _jbooleanArray : public _jarray {};
class _jbyteArray : public _jarray {};
class _jcharArray : public _jarray {};
class _jshortArray : public _jarray {};
class _jintArray : public _jarray {};
class _jlongArray : public _jarray {};
class _jfloatArray : public _jarray {};
class _jdoubleArray : public _jarray {};
class _jobjectArray : public _jarray {};
typedef _jobject * jobject ;
typedef _jclass * jclass ;
typedef _jthrowable * jthrowable ;
typedef _jstring * jstring ;
typedef _jarray * jarray ;
typedef _jbooleanArray * jbooleanArray ;
typedef _jbyteArray * jbyteArray ;
typedef _jcharArray * jcharArray ;
typedef _jshortArray * jshortArray ;
typedef _jintArray * jintArray ;
typedef _jlongArray * jlongArray ;
typedef _jfloatArray * jfloatArray ;
typedef _jdoubleArray * jdoubleArray ;
typedef _jobjectArray * jobjectArray ;
#else
struct _jobject ;
typedef struct _jobject * jobject ;
typedef jobject jclass ;
typedef jobject jthrowable ;
typedef jobject jstring ;
typedef jobject jarray ;
typedef jarray jbooleanArray ;
typedef jarray jbyteArray ;
typedef jarray jcharArray ;
typedef jarray jshortArray ;
typedef jarray jintArray ;
typedef jarray jlongArray ;
typedef jarray jfloatArray ;
typedef jarray jdoubleArray ;
typedef jarray jobjectArray ;
#endif
不是以上类型的指针就不是 JNI 引用类型,比如容易混淆的 jmethod jfield 都不是 JNI 引用类型。
JNI 引用类型是指针,但是和 C/C++ 中的普通指针不同,C/C++ 中的指针需要我们自己分配和回收内存(C/C++ 使用 malloc()/new 分配内存,需要手动使用 free()/delete 回收内存)。JNI 引用不需要我们分配和回收内存,这部分工作由 JVM 完成。我们额外需要做的工作是在 JNI 引用类型使用完后,将其从引用表中删除,防止引用表满了。
局部引用 通过 JNI 接口从 Java 传递下来或者通过 NewLocalRef 和各种 JNI 接口(FindClass、NewObject、GetObjectClass和NewCharArray等)创建的引用称为局部引用。
当从 Java 环境切换到 Native 环境时,JVM 分配一块内存用于创建一个 Local Reference Table,这个 Table 用来存放本次 Native Method 执行中创建的所有局部引用(Local Reference)。每当在 Native 代码中引用到一个 Java 对象时,JVM 就会在这个 Table 中创建一个 Local Reference。比如,我们调用 NewStringUTF() 在 Java Heap 中创建一个 String 对象后,在 Local Reference Table 中就会相应新增一个 Local Reference。
对于开发者来说,Local Reference Table 是不可见的,Local Reference Table 的内存不大,所能存放的 Local Reference 数量也是有限的(在 Android 中默认最大容量是512个)。在开发中应该及时使用 DeleteLocalRef() 删除不必要的 Local Reference,不然可能会出现溢出错误。
很多人会误将 JNI 中的 Local Reference 理解为 Native Code 的局部变量。这是错误的:
局部变量存储在线程堆栈中,而 Local Reference 存储在 Local Ref 表中。 局部变量在函数退栈后被删除,而 Local Reference 在调用 DeleteLocalRef() 后才会从 Local Ref 表中删除,并且失效,或者在整个 Native Method 执行结束后被删除。 可以在代码中直接访问局部变量,而 Local Reference 的内容无法在代码中直接访问,必须通过 JNI function 间接访问。JNI function 实现了对 Local Reference 的间接访问,JNI function 的内部实现依赖于具体 JVM。 全局引用 Global Reference 是通过 JNI 函数 NewGlobalRef() 和 DeleteGlobalRef() 来创建和删除的。Global Reference 具有全局性,可以在多个 Native Method 调用过程和多线程中使用。
使用 Global reference时,当 native code 不再需要访问 Global reference 时,应当调用 JNI 函数 DeleteGlobalRef() 删除 Global reference 和它引用的 Java 对象。否则 Global Reference 引用的 Java 对象将永远停留在 Java Heap 中,从而导致 Java Heap 的内存泄漏。
弱全局引用 弱全局引用使用 NewWeakGlobalRef() 和 DeleteWeakGlobalRef() 进行创建和删除,它与 Global Reference 的区别在于该类型的引用随时都可能被 GC 回收。
对于 Weak Global Reference 而言,可以通过 isSameObject() 将其与 NULL 比较,看看是否已经被回收了。如果返回 JNI_TRUE,则表示已经被回收了,需要重新初始化弱全局引用。
Weak Global Reference 的回收时机是不确定的,有可能在前一行代码判断它是可用的,后一行代码就被 GC 回收掉了。为了避免这类事情发生,JNI官方给出了正确的做法,通过 NewLocalRef() 获取 Weak Global Reference,避免被GC回收。
JNI性能优化 Java 程序中,调用一个 Native 方法相比调用一个 Java 方法要耗时很多,我们应该减少 JNI 方法的调用,同时一次 JNI 调用尽量完成更多的事情。对于过于耗时的 JNI 调用,应该放到后台线程调用。 Native 程序要访问 Java 对象的字段或调用它们的方法时,本机代码必须调用 FindClass()、GetFieldID()、GetStaticFieldID、GetMethodID() 和 GetStaticMethodID() 等方法,返回的 ID 不会在 JVM 进程的生存期内发生变化。但是,获取字段或方法的调用有时会需要在 JVM 中完成大量工作,因为字段和方法可能是从超类中继承而来的,这会让 JVM 向上遍历类层次结构来找到它们。为了提高性能,我们可以把这些 ID 缓存起来,用内存换性能。 缓存java字段,方法ID java:
public class TestJavaClass {
//......
private void myMethod () {
Log . i ( "JNI" , "this is java myMethod" );
}
//......
}
public native void cacheTest ();
C++:
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_cacheTest ( JNIEnv * env , jobject thiz ) {
jclass clazz = env -> FindClass ( "com/yuandaima/myjnidemo/TestJavaClass" );
if ( clazz == NULL ) {
return ;
}
static jmethodID java_construct_method_id = NULL ;
static jmethodID java_method_id = NULL ;
//实现缓存的目的,下次调用不用再获取 methodid 了
if ( java_construct_method_id == NULL ) {
//构造函数 id
java_construct_method_id = env -> GetMethodID ( clazz , "<init>" , "()V" );
if ( java_construct_method_id == NULL ) {
return ;
}
}
//调用构造函数,创建一个对象
jobject object_test = env -> NewObject ( clazz , java_construct_method_id );
if ( object_test == NULL ) {
return ;
}
//相同的手法,缓存 methodid
if ( java_method_id == NULL ) {
java_method_id = env -> GetMethodID ( clazz , "myMethod" , "()V" );
if ( java_method_id == NULL ) {
return ;
}
}
//调用 myMethod 方法
env -> CallVoidMethod ( object_test , java_method_id );
env -> DeleteLocalRef ( clazz );
env -> DeleteLocalRef ( object_test );
}
主要是通过一个全局变量保存 methodid,这样只有第一次调用 native 函数时,才会调用 GetMethodID 去获取,后面的调用都使用缓存起来的值了。这样就避免了不必要的调用,提升了性能。
静态初始化 java:
static {
System . loadLibrary ( "myjnidemo" );
initIDs ();
}
public static native void initIDs ();
C++:
//定义用于缓存的全局变量
static jmethodID java_construct_method_id2 = NULL ;
static jmethodID java_method_id2 = NULL ;
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_initIDs ( JNIEnv * env , jclass clazz ) {
jclass clazz2 = env -> FindClass ( "com/yuandaima/myjnidemo/TestJavaClass" );
if ( clazz == NULL ) {
return ;
}
//实现缓存的目的,下次调用不用再获取 methodid 了
if ( java_construct_method_id2 == NULL ) {
//构造函数 id
java_construct_method_id2 = env -> GetMethodID ( clazz2 , "<init>" , "()V" );
if ( java_construct_method_id2 == NULL ) {
return ;
}
}
if ( java_method_id2 == NULL ) {
java_method_id2 = env -> GetMethodID ( clazz2 , "myMethod" , "()V" );
if ( java_method_id2 == NULL ) {
return ;
}
}
}
手法和使用时缓存是一样的,只是缓存的时机变了。如果是动态注册的 JNI 还可以在 Onload 函数中来执行缓存操作。
多线程Demo JNI 环境下,进行多线程编程,有以下两点是需明确的:
JNIEnv 是一个线程作用域的变量,不能跨线程传递,每个线程都有自己的 JNIEnv 且彼此独立 局部引用不能在本地函数中跨函数使用,不能跨线程使用,当然也不能直接缓存起来使用 java:
public void javaCallback ( int count ) {
Log . e ( TAG , "onNativeCallBack : " + count );
}
public native void threadTest ();
C++:
static int count = 0 ;
JavaVM * gJavaVM = NULL ; //全局 JavaVM 变量
jobject gJavaObj = NULL ; //全局 Jobject 变量
jmethodID nativeCallback = NULL ; //全局的方法ID
//这里通过标志位来确定 两个线程的工作都完成了再执行 DeleteGlobalRef
//当然也可以通过加锁实现
bool main_finished = false ;
bool background_finished = false ;
static void * native_thread_exec ( void * arg ) {
LOGE ( TAG , "nativeThreadExec" );
LOGE ( TAG , "The pthread id : %d \n " , pthread_self ());
JNIEnv * env ;
//从全局的JavaVM中获取到环境变量
gJavaVM -> AttachCurrentThread ( & env , NULL );
//线程循环
for ( int i = 0 ; i < 5 ; i ++ ) {
usleep ( 2 );
//跨线程回调Java层函数
env -> CallVoidMethod ( gJavaObj , nativeCallback , count ++ );
}
gJavaVM -> DetachCurrentThread ();
background_finished = true ;
if ( main_finished && background_finished ) {
env -> DeleteGlobalRef ( gJavaObj );
LOGE ( TAG , "全局引用在子线程销毁" );
}
return (( void * ) 0 );
}
extern "C"
JNIEXPORT void JNICALL
Java_com_yuandaima_myjnidemo_MainActivity_threadTest ( JNIEnv * env , jobject thiz ) {
//创建全局引用,方便其他函数或线程使用
gJavaObj = env -> NewGlobalRef ( thiz );
jclass clazz = env -> GetObjectClass ( thiz );
nativeCallback = env -> GetMethodID ( clazz , "javaCallback" , "(I)V" );
//保存全局 JavaVM,注意 JavaVM 不是 JNI 引用类型
env -> GetJavaVM ( & gJavaVM );
pthread_t id ;
if ( pthread_create ( & id , NULL , native_thread_exec , NULL ) != 0 ) {
return ;
}
for ( int i = 0 ; i < 5 ; i ++ ) {
usleep ( 20 );
//跨线程回调Java层函数
env -> CallVoidMethod ( gJavaObj , nativeCallback , count ++ );
}
main_finished = true ;
if ( main_finished && background_finished && ! env -> IsSameObject ( gJavaObj , NULL )) {
env -> DeleteGlobalRef ( gJavaObj );
LOGE ( TAG , "全局引用在主线程销毁" );
}
}
示例代码中,我们的子线程需要使用主线程中的 jobject thiz,该变量是一个局部引用,不能赋值给一个全局变量然后跨线程跨函数使用,我们通过 NewGlobalRef 将局部引用装换为全局引用并保存在全局变量 jobject gJavaObj 中,在使用完成后我们需要使用 DeleteGlobalRef 来释放全局引用,因为多个线程执行顺序的不确定性,我们使用了标志位来确保两个线程所有的工作完成后再执行释放操作。
C++线程安全 Memory Order 为什么需要 Memory Order 如果不使用任何同步机制(例如 mutex 或 atomic),在多线程中读写同一个变量,那么,程序的结果是难以预料的。主要原因有一下几点:
简单的读写不是原子操作 CPU 可能会调整指令的执行顺序 在 CPU cache 的影响下,一个 CPU 执行了某个指令,不会立即被其它 CPU 看见 非原子操作给多线程编程带来的影响 原子操作说的是,一个操作的状态要么就是未执行,要么就是已完成,不会看见中间状态。
下面看一个非原子操作给多线程编程带来的影响:
int64_t i = 0; // global variable
Thread-1: Thread-2:
i++; std::cout << i;
C++ 并不保证 i++ 是原子操作。从汇编的角度看,读写内存的操作一般分为三步:
将内存单元读到 cpu 寄存器 修改寄存器中的值 将寄存器中的值回写入对应的内存单元 进一步,有的 CPU Architecture, 64 位数据(int64_t)在内存和寄存器之间的读写需要两条指令。
这就导致了 i++ 操作在 cpu 的角度是一个多步骤的操作。所以 Thread-2 读到的可能是一个中间状态。
指令的执行顺序调整给多线程编程带来的影响 为了优化程序的执行性能,编译器和 CPU 可能会调整指令的执行顺序。为阐述这一点,下面的例子中,让我们假设所有操作都是原子操作:
int x = 0; // global variable
int y = 0; // global variable
Thread-1: Thread-2:
x = 100; while (y != 200) {}
y = 200; std::cout << x;
如果 CPU 没有乱序执行指令,那么 Thread-2 将输出 100。然而,对于 Thread-1 来说,x = 100; 和 y = 200; 这两个语句之间没有依赖关系,因此,Thread-1 允许调整语句的执行顺序:
Thread-1:
y = 200;
x = 100;
在这种情况下,Thread-2 将输出 0 或 100。
CPU CACHE 对多线程程序的影响 CPU cache 也会影响到程序的行为。下面的例子中,假设从时间上来讲,A 操作先于 B 操作发生:
int x = 0; // global variable
Thread-1: Thread-2:
x = 100; // A std::cout << x; // B
尽管从时间上来讲,A 先于 B,但 CPU cache 的影响下,Thread-2 不能保证立即看到 A 操作的结果,所以 Thread-2 可能输出 0 或 100。
同步机制 对于 C++ 程序来说,解决以上问题的办法就是使用同步机制,最常见的同步机制就是 std::mutex和 std::atomic。从性能角度看,通常使用 std::atomic 会获得更好的性能。 C++ 提供了四种 memory ordering :
Relaxed ordering Release-Acquire ordering Release-Consume ordering Sequentially-consistent ordering Relaxed ordering 在这种模型下,std::atomic 的 load() 和 store() 都要带上 memory_order_relaxed 参数。Relaxed ordering 仅仅保证 load() 和 store() 是原子操作,除此之外,不提供任何跨线程的同步。 先看看一个简单的例子:
std::atomic<int> x = 0; // global variable
std::atomic<int> y = 0; // global variable
Thread-1: Thread-2:
//A // C
r1 = y.load(memory_order_relaxed); r2 = x.load(memory_order_relaxed);
//B // D
x.store(r1, memory_order_relaxed); y.store(42, memory_order_relaxed);
执行完上面的程序,可能出现 r1 == r2 == 42。理解这一点并不难,因为编译器允许调整 C 和 D 的执行顺序。如果程序的执行顺序是 D -> A -> B -> C,那么就会出现 r1 == r2 == 42。 如果某个操作只要求是原子操作,除此之外,不需要其它同步的保障,就可以使用 Relaxed ordering。程序计数器是一种典型的应用场景:
#include <cassert>
#include <vector>
#include <iostream>
#include <thread>
#include <atomic>
std :: atomic < int > cnt = { 0 };
void f ()
{
for ( int n = 0 ; n < 1000 ; ++ n ) {
cnt . fetch_add ( 1 , std :: memory_order_relaxed );
}
}
int main ()
{
std :: vector < std :: thread > v ;
for ( int n = 0 ; n < 10 ; ++ n ) {
v . emplace_back ( f );
}
for ( auto & t : v ) {
t . join ();
}
assert ( cnt == 10000 ); // never failed
return 0 ;
}
Release-Acquire ordering 在这种模型下,store() 使用 memory_order_release,而 load() 使用 memory_order_acquire。这种模型有两种效果,第一种是可以限制 CPU 指令的重排: 在 store() 之前的所有读写操作,不允许被移动到这个 store() 的后面。 在 load() 之后的所有读写操作,不允许被移动到这个 load() 的前面。 除此之外,还有另一种效果:假设 Thread-1 store() 的那个值,成功被 Thread-2 load() 到了,那么 Thread-1 在 store() 之前对内存的所有写入操作,此时对 Thread-2 来说,都是可见的。 下面的例子阐述了这种模型的原理:
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std :: atomic < bool > ready { false };
int data = 0 ;
void producer ()
{
data = 100 ; // A
ready . store ( true , std :: memory_order_release ); // B
}
void consumer ()
{
while ( ! ready . load ( std :: memory_order_acquire )){} // C
assert ( data == 100 ); // never failed // D
}
int main ()
{
std :: thread t1 ( producer );
std :: thread t2 ( consumer );
t1 . join ();
t2 . join ();
return 0 ;
}
让我们分析一下这个过程: 首先 A 不允许被移动到 B 的后面。 同样 D 也不允许被移动到 C 的前面。 当 C 从 while 循环中退出了,说明 C 读取到了 B store()的那个值,此时,Thread-2 保证能够看见 Thread-1 执行 B 之前的所有写入操作(也即是 A)。
Release-Consume ordering 在这种模型下,store() 使用 memory_order_release,而 load() 使用 memory_order_consume。这种模型有两种效果,第一种是可以限制 CPU 指令的重排: 在 store() 之前的与原子变量相关的所有读写操作,不允许被移动到这个 store() 的后面。 在 load() 之后的与原子变量相关的所有读写操作,不允许被移动到这个 load() 的前面。 除此之外,还有另一种效果:假设 Thread-1 store() 的那个值,成功被 Thread-2 load() 到了,那么 Thread-1 在 store() 之前对与原子变量相关的内存的所有写入操作,此时对 Thread-2 来说,都是可见的。 下面的例子阐述了这种模型的原理:
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std :: atomic < std :: string *> ptr ;
int data ;
void producer ()
{
std :: string * p = new std :: string ( "Hello" ); //A
data = 42 ;
//ptr依赖于p
ptr . store ( p , std :: memory_order_release ); //B
}
void consumer ()
{
std :: string * p2 ;
while ( ! ( p2 = ptr . load ( std :: memory_order_consume ))) //C
;
// never fires: *p2 carries dependency from ptr
assert ( * p2 == "Hello" ); //D
// may or may not fire: data does not carry dependency from ptr
assert ( data == 42 );
}
int main ()
{
std :: thread t1 ( producer );
std :: thread t2 ( consumer );
t1 . join (); t2 . join ();
}
让我们分析一下这个过程: 首先 A 不允许被移动到 B 的后面。 同样 D 也不允许被移动到 C 的前面。 data 与 ptr 无关,不会限制他的重排序 当 C 从 while 循环中退出了,说明 C 读取到了 B store()的那个值,此时,Thread-2 保证能够看见 Thread-1 执行 B 之前的与原子变量相关的所有写入操作(也即是 A)。
Sequentially-consistent ordering Sequentially-consistent ordering 是缺省设置,在 Release-Acquire ordering 限制的基础上,保证了所有设置了 memory_order_seq_cst 标志的原子操作按照代码的先后顺序执行。
常见问题解答:为什么我会收到 UnsatisfiedLinkError? 在处理原生代码时,经常可以看到如下所示的失败消息:
java.lang.UnsatisfiedLinkError: Library foo not found
在某些情况下,正如字面意思所说——找不到库。在 出现此库但无法被 dlopen 打开的其他情况,以及您可在异常的详情消息中找到失败详情。 您可能遇到“找不到库”异常的常见原因如下:
库不存在或应用无法访问。使用 adb shell ls -l,检查其是否存在 和权限。 库不是使用 NDK 构建的。这可能会导致 对设备上不存在的函数或库的依赖关系。 其他类的 UnsatisfiedLinkError 失败消息如下所示:
java.lang.UnsatisfiedLinkError: myfunc
at Foo.myfunc(Native Method)
at Foo.main(Foo.java:10)
在 logcat 中,您将看到以下内容:
W/dalvikvm( 880): No implementation found for native LFoo;.myfunc ()V
这意味着,运行时尝试查找匹配方法, 失败。造成此问题的一些常见原因如下:
库未加载。检查 logcat 输出, 库加载消息 名称或签名不匹配,因此找不到该方法。本次通常由以下原因引起:对于延迟方法查找,无法声明 C++ 函数 包含 extern "C" 和适当的可见性 (JNIEXPORT)。请注意,在投放 Ice Cream 之前, Sandwich 中,JNIEXPORT 宏不正确,因此请使用带有旧的jni.h将无法使用。 您可以使用 arm-eabi-nm 查看符号在库中显示的符号;如果它们 损坏(诸如_Z15Java_Foo_myfuncP7_JNIEnvP7_jclass之类的内容) 而不是 Java_Foo_myfunc),或者如果符号类型是 小写“t”而不是大写的“T”,则需要调整声明。 对于显式注册,在输入方法签名。请确保您传递到 与日志文件中的签名匹配。 记住 B 为 byte 和 Z 为 boolean 。签名中的类名称组成部分以 L 开头,以 ; 结尾,使用 / 分隔软件包 / 类名称,然后使用 $ 来分隔 内部类名称(比如 Ljava/util/Map$Entry;)。 使用 javah 自动生成 JNI 标头可能会有帮助可以避免一些问题。
常见问题解答:为什么 FindClass 找不到我的类? (以下建议的大部分内容同样适用于找不到方法的问题 包含 GetMethodID、GetStaticMethodID 或字段 使用 GetFieldID 或 GetStaticFieldID。) 确保类名称字符串的格式正确无误。JNI 类 名称以软件包名称开头,并用正斜线分隔 例如 java/lang/String。如果您要查找数组类, 您需要以适当数量的方括号开头还必须使用 L 封装类和 ; 这样的一个一维数组, String 为 [Ljava/lang/String;。 如果您要查找内部类,请使用 $ 而不是 . 。一般来说, 对 .class 文件使用 javap 是查找类的内部名称。
如果要启用代码缩减,请确保配置要保留的代码。正在配置适当的保留规则非常重要,因为代码压缩器可能会从别处移除类、方法 或仅通过 JNI 使用的字段。
如果类名称没有问题,则可能是因为您遇到了类加载器 问题。FindClass想要在与代码关联的类加载器。它会检查调用堆栈,如下所示:
Foo.myfunc(Native Method)
Foo.main(Foo.java:10)
最顶层的方法是 Foo.myfunc。FindClass 查找与 Foo 关联的 ClassLoader 对象 类并使用该类。
采用这种方法通常会完成您想要执行的操作。如果您 自行创建线程(可能通过调用 pthread_create) ,然后使用 AttachCurrentThread 附加该映像)。现在 不是来自应用的堆栈帧。 如果您从此线程调用 FindClass, JavaVM 将在“system”下启动类加载器,而不是 与您的应用关联,因此尝试查找特定于应用的类将失败。
您可以通过以下几种方法来解决此问题:
FindClass JNI_OnLoad,并缓存类引用以供日后使用 。执行过程中进行的任何 FindClass 调用 JNI_OnLoad 将使用与 调用 System.loadLibrary 的函数(这是 特殊规则,以方便执行库初始化)。 如果您的应用代码要加载库,请FindClass 将使用正确的类加载器。 将类的实例传递到 方法是声明原生方法接受 Class 参数 然后传入 Foo.class。 在某处缓存对 ClassLoader 对象的引用 然后直接发出 loadClass 调用。这需要 不费吹灰之力 常见问题解答:如何使用原生代码共享原始数据? 您可能会发现自己需要访问大量 来自受管理代码和原生代码的原始数据的缓冲区。常见示例包含对位图或声音样本的操纵。有两个基本方法。 您可以将数据存储在 byte[] 中。这样可让系统 通过托管代码进行访问。而在原生广告方面访问相应数据,而无需复制数据。在一些实现,GetByteArrayElements 和 GetPrimitiveArrayCritical 将返回指向 托管堆中的原始数据,但在其他情况下,系统会分配缓冲区 并复制数据 另一种方法是将数据存储在直接字节缓冲区中。这些可使用 java.nio.ByteBuffer.allocateDirect 创建,或 JNI NewDirectByteBuffer 函数。不同于普通 字节缓冲区,因此存储空间不会在托管堆上分配,并且可以 始终直接从原生代码中访问(获取 与 GetDirectBufferAddress 相关联)。取决于 已实现字节缓冲区访问,从托管代码访问数据可能会非常慢 选择使用哪种方法取决于以下两个因素:
大部分数据访问是通过使用 Java 编写的代码进行的吗 还是用 C/C++ 开发? 如果数据最终传递到系统 API,以 应该在其中吗?(例如,如果数据最终传递到函数,它接受一个 byte[] 值,直接 ByteBuffer 可能不太明智。) 如果这两种方法不分伯仲,请使用直接字节缓冲区。为他们提供的支持 直接内置在 JNI 中,性能应该会在未来版本中得到改进。 Pagination © 2024. All rights reserved. LICENSE | NOTICE | CHANGELOG
Powered by Hydejack v9.2.1